PyTorch学习笔记3——SOFTMAX回归模型
上一节的线性回归模型适用于输出为连续值的情景。但是在另一类情景中,模型输出可以是一个离散值,比如图像类别,这方面我们可以使用softmax回归在内的分类模型。
Softmax回归的输出单元由一个变成了多个,且引入softmax运算,使得输出更适合离散值预测与训练,通过学习softmax来介绍神经网络的分类模型。
3.1 分类问题
考虑一个简单的图像分类,其输入图像高和宽都是2像素,色彩为灰度(这样的像素由于是一个维度,可以用标量表示),分别把四个像素记为x1,x2,x3,x4。把标签狗、猫、鸡记为y1,y2,y3。
我们通常使用离散的数值来表示类别,比如y1=1,y2=2,y3=3
如此,⼀张图像的标签为1、2和3这3个数值中的⼀个。虽然我们仍然可以使⽤回归模型来进⾏建模,并将预测值就近定点化到1、2和3这3个离散值之⼀,但这种连续值到离散值的转化通常会影响到分类质量。因此我们⼀般使用更加适合离散值输出的模型来解决分类问题。
3.2.1 SOFTMAX 回归模型
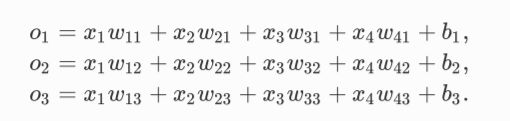
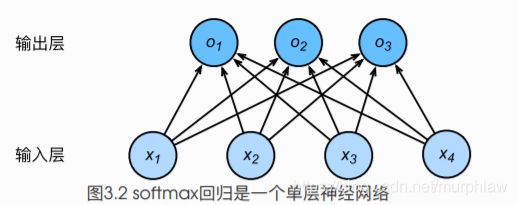
softmax运算符通过下式将输出值变换成值为正且和为1的概率分布

3.2.2 单样本分类矢量计算表达式

3.2.3 小批量样本分类的矢量计算表达式

3.2.4 交叉熵损失函数
交叉熵:适用于衡量两个概率分布的差异


交叉熵损失函数:


注意理解:
最小化交叉熵损失函数等价于最大化训练数据集的所有标签类别的联合预测概率
3.2.5 模型预测及评价
通常,我们把预测概率最大的类别作为输出类别,若它与真实标签一致,说明这次预测是正确的,我们使用准确率(accuracy)来评价模型表现,其等于正确预测数量与总预测数量之比
3.3 图像分类数据集
我们会应用Fashion-MNIST数据集
首先介绍torchvision数据包,其主要用于构建计算机视觉模型
torchvision主要有这几部分构成:
1.torchvision.datasets:一些加载数据的函数及常用数据集接口
2.torchvision.models:包含常用的模型结构,比如VGG,AlexNet,ResNet
3.torchvision.tranforms:常用的图片变换,例如裁剪,旋转
4.torchvision.utils:其它一些有用的方法
3.3.1获取数据集
先导入包,注意此处与原码不同,没有导入其自定义的包,之后所用函数将由自己编写
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import time
利用torchvision的torchvision来下载数据集,我们通过train来指定获取训练数据集或者测试数据集
另外,还指定了transform = transforms.ToTensor()使得所有数据转换为Tensor,若不转换,则返回照片是PIL格式。
tranforms.ToTensor() 将尺寸为(HWC)且数据位于(0,255)的PIL图片或者数据类型为np.uint8的Numpy数组转换为尺寸(CHW,即Channel * Height *Width)且数据类型为torch.float32且位于(0.0, 1.0)的Tensor
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=False, transform=transforms.ToTensor()) # 只用来评价模型表现,并不用于训练模型
上面的mnist_train和mnist_test都是torch.utils.data.Dataset 的子类,可以用len()来获取数据集大小
print(type(mnist_train))
print(len(mnist_train), '\n', len(mnist_test))
output:
<class 'torchvision.datasets.mnist.FashionMNIST'>
60000
10000
可以看出,训练集共有60,000样本,测试集有10,000样本,由于0~9共有十个类别,则每个类别的图像数分别是6000,1000
还可以利用下标查看一个具体样本
feature, label = mnist_train[0]
print(feature.shape, label) # Channel * Height *Width
output:
torch.Size([1, 28, 28]) 9
变量feature对应高和宽均为28像素的图像,注意,feature已经经过了transforms.ToTensor,故现在尺寸是CHW
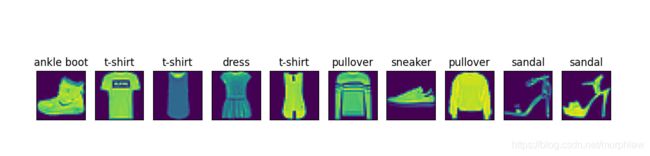
Fashion-MNIST包括了10个类别,分别为t-shirt(T恤)、trouser(裤⼦)、pullover(套衫)、dress(连⾐裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数可以将数值标签转成相应的⽂本标签。
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return[text_labels[int(i)] for i in labels]
定义在一行中画出多张图像和对应标签的函数:
def use_svg_display():
# 用矢量图表示
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
def show_fashion_mnist(images, labels):
# _表示我们不使用的变量
_, figs = plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.view(28, 28).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
现在来看一下训练和数据集前9个样本的图像内容和文本标签
X, y = [], []
for i in range(10):
X.append(mnist_train[i][0])
y.append(mnist_train[i][1])
show_fashion_mnist(X, get_fashion_mnist_labels(y))
output:
3.3.2 读取小批量
由于mnist_train是torch.utils.data.Dataset的子类,所以我们可以将其传入torch.utils.data.DataLoader来创建一个读取小批量数据样本的DataLoader实例
Pytorch的Dataloader中有一个功能是可以允许多进程来加速数据读取,这里我们通过参数num_workers来设置4个进程读取数据
batch_size = 256
if sys.platform.startswith('win'):
num_workers = 0
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
学习如何查看读取一遍数据所需要的时间
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
output:
4.57 sec
3.3.3 SOFTMAX的从零开始
由于这部分过于繁琐而基本操作可以之后简洁实现,故此处略过(看书即可,代码部分还是有不错的地方)
3.3.4 SOFTMAX的简洁实现
先导入包
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import time
from IPython import display
import numpy as np
import random
import sys
from torch import nn
from torch.nn import init
3.3.4.1 获取与读取数据
batch_size = 256
if sys.platform.startswith('win'):
num_workers = 0
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
3.3.4.2 定义和初始化模型
softmax回归的输出层是一个全连接层,所以我们用一个线性模块即可;
因为我们前面数据返回的每个batch样本x形状为(batch_size,1,28,28)所以我们要先用view()将x形状转换成(batch_size,784)才能送进全连接层
num_inputs = 784
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(LinearNet, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs)
def forward(self, x): # x shape:(batch, 1, 28, 28)
y = self.linear(x.view(x.shape[0], -1))
return y
net = LinearNet(num_inputs, num_outputs)
对x的形状变换这个功能自定义一个FlattenLayer,方便后面使用
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0], -1)
当然,根据本书第二版来说,上述步骤还是过于繁琐,可以轻松用以下代码实现:
softmax 回归的输出层是一个全连接层。因此,为了实现我们的模型,我们只需在 Sequential 中添加一个带有10个输出的全连接层。同样,在这里,Sequential 并不是必要的,但我们可能会形成这种习惯。因为在实现深度模型时,Sequential将无处不在。我们仍然以均值0和标准差0.01随机初始化权重。
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
在上一节中,分开定义softmax运算和交互熵损失函数可能会带来数值不稳定,PyTorch提供了一个包括softmax运算和交互熵损失计算的函数,它的数值稳定性更好
loss = nn.CrossEntropyLoss()
3.3.4.3 定义优化算法
我们使用学习率为0.1的小批量随机梯度下降作为优化算法
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
3.3.4.4 训练模型
此处与从零开始相同,由于涉及到自己的包导入,这里不再展示代码
之后预测过程也可自行完成
3.4 多层感知机(MLP)

容易得到,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络;
3.4.1 隐藏层
3.4.2 激活函数
引入非线性变换,作为下一个全连接层的输入;此非线性函数称之为激活函数
常见的有
RuLU函数

sigmoid函数

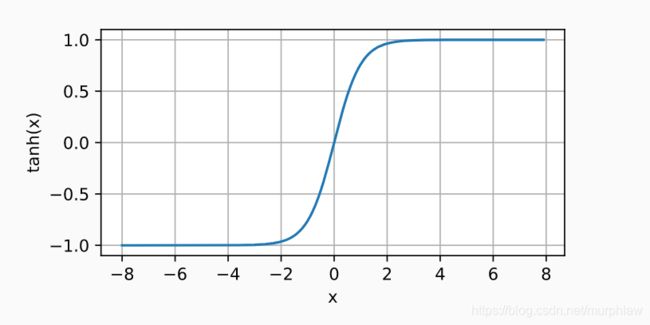
tanh函数
tanh函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。
3.4.3 网络定义
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
3.5 模型选择、欠拟合和过拟合
3.5.1 训练误差和泛化误差
训练误差(training error)是指,我们的模型在训练数据集上计算得到的误差。泛化误差(generalization error)是指,当我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望。
3.5.2 模型选择(model selection)
原则上,在我们确定所有的超参数之前,我们不应该用到测试集。如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险。那我们就麻烦大了。如果我们过拟合了训练数据,还有在测试数据上的评估来判断过拟合。但是如果我们过拟合了测试数据,我们又该怎么知道呢?
因此,我们决不能依靠测试数据进行模型选择。然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
在实际应用中,情况变得更加复杂。虽然理想情况下我们只会使用测试数据一次,以评估最好的模型或比较一些模型效果,但现实是,测试数据很少在使用一次后被丢弃。我们很少能有充足的数据来对每一轮实验采用全新测试集。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加一个验证数据集(validation dataset),也叫验证集(validation set)。
3.5.3 K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。这个问题的一个流行的解决方案是采用 K 折交叉验证。这里,原始训练数据被分成 K 个不重叠的子集。然后执行 K 次模型训练和验证,每次在 K−1 个子集上进行训练,并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。最后,通过对 K 次实验的结果取平均来估计训练和验证误差。
3.5.4 欠拟合和过拟合
underfitting: 模型无法得到较低的训练误差
overfitting: 模型的训练误差远小于测试误差
模型复杂度和数据集大小可能会导致这两种拟合问题
3.5.4.1 模型复杂度

高阶多项式函数比低阶多项式函数的复杂度更高,故更容易得到更低的训练误差,也更可能出现过拟合;如图所示:

3.5.4.2 训练数据集大小
训练数据集中的样本越少,我们就越有可能(且更严重地)遇到过拟合。随着训练数据量的增加,泛化误差通常会减小。此外,一般来说,更多的数据不会有什么坏处。对于固定的任务和数据分布,模型复杂性和数据集大小之间通常存在关系。给出更多的数据,我们可能会尝试拟合一个更复杂的模型。能够拟合更复杂的模型可能是有益的。如果没有足够的数据,简单的模型可能更有用。对于许多任务,深度学习只有在有数千个训练样本时才优于线性模型。
3.6 权重衰减
应对过拟合问题的常用方法:权重衰减(weight decay),等价于L2范数正则化,这里我们直接在构造优化器实例时通过weight_decay参数来指定权重衰减超参数。默认情况下,会对权重和偏差同时衰减,我们可以分别对权重和偏差构造优化器实例,从而只对权重衰减。
def fit_and_plot_pytorch(wd):
#对权重参数衰减
net = nn.Linear(num_inputs, 1)
nn.init.normal_(net.weight, mean=0, std=1)
nn.init.normal_(net.bias, mean=0, std=1)
optimizer_w = torch.optim.SGD(params=[net.weight], lr=lr, weight_decay=wd) # 对权重参数衰减
optimizer_b = torch.optim.SGD(params=[net.bias], lr=lr) # 不对偏差参数衰减
train_ls, test_ls =[], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y).mean()
optimizer_w.zero_grad()
optimizer_b.zero_grad()
l.backward()
#对两个优化器实例分别调用step函数,更新权重和偏差
optimizer_w.step()
optimizer_b.step()
train_ls.append(loss(net(train_features), train_labels).mean().item())
test_ls.append(loss(net(test_features), test_labels).mean().item())
3.7 丢弃法
除了权重衰减,还常用dropout来应对过拟合问题
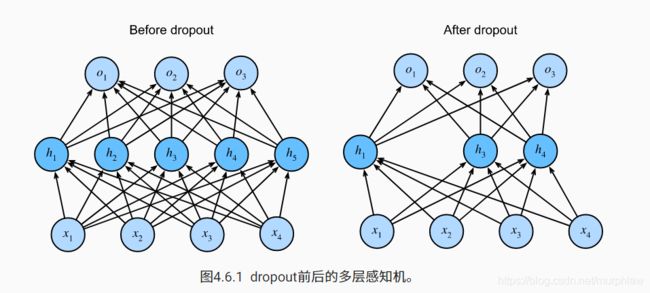
在pytorch中,我们只需要在全连接层后添加Dropout层并指定丢弃概率,当训练模型时,Dropout层将以指定的丢弃概率随机丢弃上一层的输出元素,在测试模型时,Dropout层并不发挥作用
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
或者可以利用
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(
nn.Flatten(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(num_hiddens2, 10)
)
print(net)
output:
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Dropout(p=0.2, inplace=False)
(4): Linear(in_features=256, out_features=256, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=256, out_features=10, bias=True)
)
3.8 正向传播和反向传播
正向传播沿着从输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
反向传播沿着从输出层到输入层的顺序,以此计算并存储神经网络中间变量和参数的梯度
3.9 数值稳定性和模型初始化
3.9.1 随机初始化模型参数
在线性回归中,我们使用了torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式,不过pytorch中nn.Module的模块参数都有较为合理的初始化策略,一般不需我们考虑
3.10 偏移
分布偏移
协变量偏移
标签偏移
概念偏移
许多情况下,训练集和测试集并不来自同一个分布。这就是所谓的分布偏移。
真实风险是从真实分布中抽取的所有数据的总体损失的预期。然而,这个数据总体通常是无法获得的。经验风险是训练数据的平均损失,用于近似真实风险。在实践中,我们进行经验风险最小化。
在相应的假设条件下,可以在测试时检测并纠正协变量偏移和标签偏移。在测试时,不考虑这种偏移可能会成为问题。
在某些情况下,环境可能会记住自动操作并以令人惊讶的方式做出响应。在构建模型时,我们必须考虑到这种可能性,并继续监控实时系统,并对我们的模型和环境以意想不到的方式纠缠在一起的可能性持开放态度。