pytorch学习笔记(一):Dataset和DataLoader
参考:https://blog.csdn.net/zw__chen/article/details/82806900
一、DataLoader
1、DataLoader 是 torch 给你用来包装你的数据的工具. 所以你要将自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中.
2、Dataset是一个抽象类,不能实例化,要先继承。DataLoader可以直接实例化
3、Dataset有内置数据集:
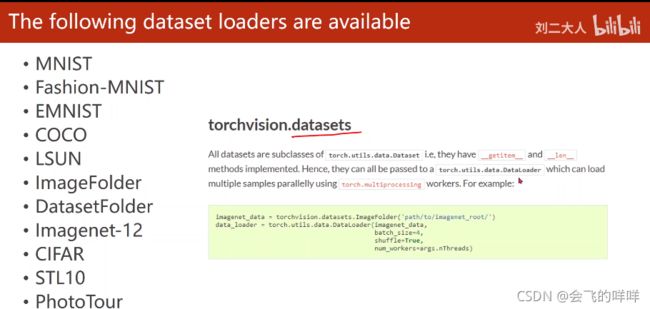
这些内置数据集有对应的__getitem__()和__len__()方法
二、内置数据集的使用
比如:MNIST数据集
# 可以选择是否将数据集下载到本地。要把数据转化成tensor,DataLoader才能处理
train_data = torchvision.datasets.MNIST(
root = './mnist', train = True,
transform = torchvision.transforms.ToTensor(),
download = True
)
test_data = torchvision.datasets.MNIST(
root = './mnist', train = False,
transform = torchvision.transforms.ToTensor(),
download = True
)
train_loader = Data.DataLoader(dataset=train_data, batch_size=50, shuffle=True)
test_loader = Data.DataLoader(dataset=test_data, batch_size=50, shuffle=False)
三、DataLoader加载非内置数据集
如果要使用其他数据集,需要继承Dataset类,并对以上两个方法进行重写
本文使用Titanic数据集:https://www.kaggle.com/c/titanic/data
把数据集下载到当前代码的同级目录下【读取csv数据集时,可以用np.loadtxt或pd.read_csv,loadtxt要指定分割符,且引号中的逗号也可能被识别成分隔符,所以这里我用的是read_csv】
1、基本包的导入
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
2、继承Dataset抽象类,并重写__getitem__()和__len__()
# TitanicDataset类名可以随便起,后面继承的Dataset不可以随便修改
class TitanicDataset(Dataset):
# 构造函数
def __init__(self,xy_data):
# axis=1,表示是按列名删除(列名就是刚刚的第一行)
# 因为原数据集中有字符串等,为了等下转tensor方便,直接把这些数据删掉
# 我们本节的目的是为了学习DataLoader的使用而不是利用数据进行后续分析
self.x_data = xy_data.drop(['PassengerId','Survived','Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)
self.y_data = xy_data[['Survived']]
# 这里的x_data、y_data要处理成tensor格式
# 能转成tensor格式的数据有int、float、bool
# 这部分转tensor好像有点累赘,欢迎补充交流
self.x_train = np.array(self.x_train)
self.y_train = np.array(self.y_train)
# self.x_train = self.x_train.astype(float)
#self.y_train = self.y_train.astype(float)
self.x_train = torch.Tensor(self.x_train.astype(float))
self.y_train = torch.Tensor(self.y_train.astype(float))
# shape[0]是从纵向角度看,代表行数
self.len = self.xy_data.shape[0]
# 按索引取出对应元素
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
#
def __len__(self):
return self.len
看一下数据集格式:
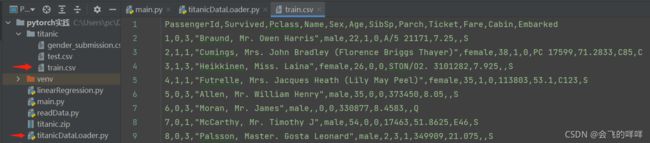
3、实例化
# 把第一行作为表头,实际读取的数据不包括第一行
xy_train = pd.read_csv('titanic/train.csv',header=0)
xy_test = pd.read_csv('titanic/train.csv',header=0)
# 因为这里train、test是分成两个文件,但是TitanicDataset是可复用的,
# 所以把不同的数据传入TitanicDataset,而不是在该类中读取数据
titanic_train = TitanicDataset(xy_train)
titanic_test = TitanicDataset(xy_test)
# 训练时,一般打乱数据;但测试时不打乱;batch_size自己设置
train_loader = DataLoader(dataset=titanic_train,batch_size=32,shuffle=True)
test_loader = DataLoader(dataset=titanic_train,batch_size=32,shuffle=False)
4、从DataLoader中读取出来
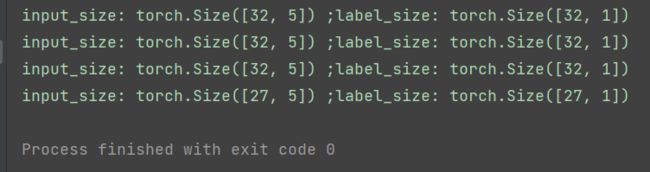
# 891个样本,每个batch有32个样本,分为28个epoch
for epoch in range(28):
print("epoch:",epoch)
for i,data in enumerate(train_loader):
inputs, labels = data
print("input_size:",inputs.data.size(),";label_size:",labels.data.size())
# train: 891*5 test: 891*1
enumerate可以获取索引、元素
输出结果:
四、TensorDataset
看到另外一种使用DataLoader的方法好像更加简便
参考:https://www.pytorchtutorial.com/3-5-data-loader/
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducible
BATCH_SIZE = 5 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)
# 先转换成 torch 能识别的 Dataset
# TensorDataset是对tensor进行打包,data_tensor、target_tensor都是tensor格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有!整套!数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# 假设这里就是你训练的地方...
# 打出来一些数据
print(\'Epoch: \', epoch, \'| Step: \', step, \'| batch x: \',
batch_x.numpy(), \'| batch y: \', batch_y.numpy())
"""
Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1.] | batch y: [ 5. 4. 9. 8. 10.]
Epoch: 0 | Step: 1 | batch x: [ 9. 10. 4. 8. 5.] | batch y: [ 2. 1. 7. 3. 6.]
Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10.] | batch y: [ 8. 7. 9. 2. 1.]
Epoch: 1 | Step: 1 | batch x: [ 1. 7. 8. 5. 6.] | batch y: [ 10. 4. 3. 6. 5.]
Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7.] | batch y: [ 8. 2. 9. 5. 4.]
Epoch: 2 | Step: 1 | batch x: [ 10. 4. 8. 1. 5.] | batch y: [ 1. 7. 3. 10. 6.]
"""