基于AI的恶意软件分析技术(3)
一篇综述:用于检测和分类恶意软件的机器学习的兴起:研究的发展、趋势和挑战
阅读The rise of machine learning for detection and classification of malware: Research developments, trends and challenges翻译&笔记
原文:https://www.sciencedirect.com/science/article/pii/S1084804519303868
摘要:安全分析师和恶意软件开发者之间的斗争是一场永无止境的战斗,随着创新的增长,恶意软件的复杂性也在迅速变化。由于机器学习技术能够跟上恶意软件的发展,目前最先进的研究集中在恶意软件检测的机器学习技术的开发和应用上。这项调查的目的是提供一个系统和详细的概述机器学习技术的恶意软件检测,尤其是深度学习技术。本文的主要贡献是:(1)全面描述了传统机器学习工作流中用于恶意软件检测和分类的方法和功能;(2)探讨了传统机器学习的挑战和局限性;(3)分析了该领域的最新趋势和发展,特别强调了深度学习方法。此外,(4)介绍了最新技术的研究问题和尚未解决的挑战;(5)讨论了新的研究方向。 该调查有助于研究人员了解恶意软件检测领域以及科学界为解决该问题而探索的新发展和研究方向。
关键字:恶意软件检测、特征工程、AI、多模态学习
1、介绍
简要回顾一下恶意软件的历史提醒我们,自从计算机诞生以来,恶意软件威胁就一直伴随着我们。最早记录的病毒出现在20世纪70年代。它被称为爬行虫,是一个实验性的自我复制程序,它将自身复制到远程系统,并显示信息:“我是爬行虫,如果可以,抓住我。”。后来,在80年代初,出现了Elk Cloner,一种针对Apply II计算机的引导区病毒。从这些简单的开始,一个巨大的行业诞生了,从那时起,打击恶意软件的斗争从未停止过。从表面上看,这场斗争是一场永无止境的周期性军备竞赛:随着安全分析师和研究人员提高防御能力,恶意软件开发人员不断创新,寻找新的感染载体,并增强他们的混淆技术。由于技术进步带来的机遇,恶意软件威胁继续纵向(即数量和数量)和横向(即类型和功能)扩展。互联网、社交网络、智能手机、物联网设备等使智能复杂恶意软件的创建成为可能。近年来,勒索软件和加密挖掘恶意软件成为最多产的类型,Cerber和Locky在全球各地持有计算机索要赎金,而Cryptoloot则在受害者不知情的情况下利用受害者的计算能力挖掘加密软件。尽管针对计算机系统的恶意软件仍然在生态系统中占主导地位,但移动和物联网恶意软件仍在上升。根据赛门铁克(Symantec)(Corporation,2018)的数据,2017年移动恶意软件变种增加了54%,而物联网攻击增加了600%,Mirai僵尸网络及其变种成为历史上最强大的DDoS攻击的载体(Kolias等人,2017)。
为了跟上恶意软件的发展,安全分析师和研究人员需要不断提高他们的网络防御能力。一个基本要素是端点保护。Endpoint protection提供一套安全程序,包括但不限于防火墙、URL过滤、电子邮件保护、反垃圾邮件和沙箱。具体来说,反恶意软件提供了最后一层防御。AV引擎负责防止、检测和删除安装在终端设备上的恶意软件。传统上,AV解决方案依赖于基于签名和基于启发式的方法。签名是唯一标识特定恶意软件的算法或哈希,而启发式是专家在分析恶意软件行为后确定的一组规则。然而,这两种方法都要求在定义这些规则和启发式之前对恶意软件进行分析。恶意软件分析的目标是提供有关给定软件的特征、用途和行为的信息。有两种类型的分析:(1)静态分析和(2)动态分析。一方面,静态分析涉及在不执行的情况下检查可执行文件。另一方面,动态分析涉及通过运行可执行文件来检查其行为。这两种类型的分析都有各自的优势和局限性,它们相互补充。静态分析速度更快,但如果使用代码混淆技术成功隐藏恶意软件,它可能会逃避检测。相反,代码混淆技术和多态恶意软件在监视和分析程序的运行时执行时几乎无法逃避动态分析。然而,传统的恶意软件检测和分析无法跟上新的攻击和变种。组织面临着每天应对数百万次袭击的艰巨挑战。此外,组织也面临网络安全技能和人才短缺的问题(关于第44届总统网络安全等,2010年)。已识别的问题为机器学习提供了一个独特的机会,因为机器学习能够处理大量数据,从而显著影响和改变网络安全格局(Fraley et al.,2017)。
在过去十年中,机器学习在包括网络安全在内的许多领域引发了根本性的转变。网络安全专家普遍认为,人工智能驱动的反恶意软件工具将有助于检测现代恶意软件攻击并改进扫描引擎。这一信念的证据是过去几年发表的大量关于利用机器学习的恶意软件检测技术的研究。据谷歌学者1称,2018年发表的研究论文数量为7720篇,比2015年增加95%,比2010年增加476%。研究数量的增加是多种因素共同作用的结果,包括但不限于公开标记的恶意软件源的增加、价格下降的同时计算能力的提高,以及机器学习领域的发展。机器学习领域在计算机视觉和语音识别等广泛任务上取得了突破和成功。根据分析的类型,传统的机器学习方法可以分为两大类:静态方法和动态方法。它们之间的主要区别在于,静态方法从恶意软件的静态分析中提取特征,而动态方法从动态分析中提取特征。第三组被定义为混合方法,可以考虑。混合方法结合了静态和动态分析的各个方面。此外,神经网络在从各个领域的原始输入中学习特征方面表现得更出色。机器学习用于网络安全的最新趋势正在复制神经网络在恶意软件领域的成功。例如,Raff等人(2018a)和Krˇcál等人(2018)提议建立一个卷积神经网络来确定
PE可执行文件本身的原始字节的恶意。神经网络方法背后的动机是建立不依赖专家领域知识来定义鉴别特征的检测系统。
鉴于人工智能工具在检测恶意软件方面的影响越来越大,考虑到最近的研究,并探索传统静态和动态方法的细节,需要进行新的文献综述。有一些研究讨论了恶意软件检测方法,但我们认为这是不完整的。(读者请参阅第2节)。为了补充所调查的论文并减少文献中的一些缺陷,本文系统地回顾了传统的和最先进的机器学习技术用于恶意软件检测和分类,特别强调了从可移植可执行文件中提取的信息(特征)的类型。本文提供了恶意软件分析的基本背景,并简要描述了剖析恶意软件的过程和工具。关于更完整的描述,请参考Ligh等人(2010);西科尔斯基和霍宁(2012);蒙纳帕(2018)。本综述旨在帮助可能有兴趣将机器学习应用于恶意软件分析过程自动化的安全分析师对当前使用的方法和新趋势有一个大致的了解。本文对三种主要方法进行了分类:(1)静态方法。此外,本文还详细介绍了基于神经网络的恶意软件检测和分类方法,并根据输入在输入神经网络之前的预处理方式进行了分类,还简要介绍了多模态学习方法。本文最后讨论了该领域研究人员面临的研究问题和挑战,包括评估方法性能的开放和公共基准的可用性、恶意软件领域的概念漂移问题、增量学习、对抗性学习以及类不平衡问题。
本次调查的组织方式如下。第2节提供了在文献中被调查的研究的总结。第3节描述了恶意软件分析的背景。第4节提供了对恶意软件检测的静态和动态方法的系统描述,并概述了对手头任务的最具鉴别性的特征。第5节详细介绍了基于神经的方法。第6节介绍了多模态方法和混合方法。在第7节中,讨论了新的挑战和恶意软件检测问题的全面分析。最后,第8节总结了本次调查的总结语。
2、相关工作
本节总结了文献中被调查的研究,并讨论了它的一些缺陷。表1总结了文献中调查的主要贡献。接下来,我们将对每个调查进行简要描述,以及我们在工作中试图减轻它们的缺陷。
Shabtai等人(2009)通过报告文献中使用的一些特征类型和特征选择技术,为使用机器学习算法的恶意软件检测提供了分类。他们主要关注特征选择技术(增益比、Fisher评分、文档频率和分层特征选择)和分类算法(人工神经网络、贝叶斯网络、朴素贝叶斯、K-最近邻等)。此外,他们还回顾了集成算法如何用于组合一组分类器。Bazrafshan等人(2013)确定了检测恶意软件的三种主要方法:(1)基于签名的方法,(2)基于启发式的方法和基于行为的方法。此外,他们还调查了恶意软件检测的一些特征,并讨论了恶意软件用来逃避检测的隐藏技术。尽管如此,上述研究并未考虑动态或混合方法。Souri等人(2018年)将恶意软件检测方法分为两类:(1)基于特征的方法和(2)基于行为的方法。然而,该调查既没有回顾最新的深度学习方法,也没有对用于恶意软件检测和分类的数据挖掘技术中使用的特征类型进行分类。Ucci等人(2019)根据以下内容对方法进行分类:(i)他们试图解决的目标任务是什么,(ii)从可移植可执行文件(PE)中提取的特征类型是什么,以及(iii)他们使用的机器学习算法是什么。尽管调查提供了特征分类法的完整描述,但并未概述新的研究趋势,尤其是深度学习和多模式方法。Ye等人(2017)介绍了用于恶意软件检测的传统机器学习方法,包括特征提取、特征选择和分类步骤。然而,诸如文件的熵或结构熵之类的重要特性,以及诸如网络活动、操作码和API跟踪之类的一些动态特性都缺失了。此外,深度学习方法或多模式恶意软件检测方法在过去几年中一直是热门话题,但并未涵盖。最后,Razak等人(2016年)对恶意软件进行了文献计量分析。它按国家、机构或与恶意软件相关的作者分析出版物。尽管如此,本文并未对恶意软件检测器所使用的功能进行描述,也未考虑该领域的最新技术。
鉴于上述被调查论文的局限性,本研究对传统的和最先进的机器学习技术进行恶意软件检测和分类进行了系统的回顾。本文将传统方法分为(1)静态方法和(2)动态方法两类,根据从可执行文件中提取的信息类型或特征类型对方法进行分类。它通过探索结合不同模式或类型的信息的各种方法,扩展了被调查的论文,并分析了最先进的深度学习方法,这些方法根据输入到系统中的原始数据的性质进行分组。本文最后讨论了研究所面临的问题和挑战,包括但不限于概念漂移、对抗性学习和阶级不平衡问题。

表1被调查论文的贡献一览表。✓表示调查试图涵盖的信息,但它不一定提供对主题的详细描述
3.背景
本节概述了分析针对Windows操作系统的恶意软件的分析类型、技术和工具,该操作系统是迄今为止世界上使用最多的操作系统。首先,我们描述了便携式可执行文件的格式。然后,我们提供了一个对恶意软件分析的基本方法的描述,并给出了一个用于检查恶意软件的最常用工具的列表。最后,我们介绍恶意软件的分类和简要概述它的演变。
3.1.便携式可执行文件格式
便携式可执行文件(PE)格式是一种用于可执行文件、对象代码、单位代码、FON字体文件和其他文件的文件格式。PE32格式代表32位的便携式可执行文件,而PE32+代表64位格式的便携式可执行文件。
便携式可执行文件封装了Windows操作系统管理可执行代码所需的信息。这包括用于链接的动态库引用、API导出和导入表、资源管理数据和构成威胁的本地存储数据。PE文件由许多标题和部分组成,这些部分告诉动态链接器如何将文件映射到内存中。见图1。PE头包含有关可执行文件的信息,如节数、“PE可选头”的大小、文件的特征等。2它还包含导入地址表(IAT),这是应用程序在调用不同模块中的函数时使用的一个查找表。此外,便携式可执行文件具有包含可执行文件的代码和数据的各种部分,包括但不限于以下内容:
- 这个数据段本节用于声明在运行时不发生更改的初始化数据或常量。
- 这个bss部分。本节用于声明变量,并包含未初始化的数据
- 这个电文段本节保留了该程序的实际代码。
- 这个rsrc部分。本节包含了该程序的所有资源。
- 这个rdata部分。本节保存调试目录,存储在文件中的各种类型调试信息的类型、大小和位置
- 这个idata部分。本节包含有关程序从dll导入的函数和数据的信息。
- 这个edata部分。本节包含PE文件为其他程序导出的函数和数据的列表
- 这个Reloc部分。本节包含一个基本的重新定位表。基本重定位是对指令或初始化变量值的调整,如果加载器不能加载链接器假设的文件,则需要该值。
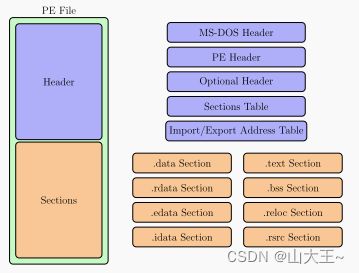
图1。便携式可执行文件格式。
关于PE文件格式的更多信息可以在微软提供的文档中找到。3
3.2.恶意软件分类法
恶意软件,也被称为恶意软件,是任何专门设计用来破坏、破坏或获得未经授权访问计算机系统或网络的软件。根据目的和扩散系统,恶意软件可以分为不同的,而不是相互排斥的类别。
- 恶意广告软件恶意软件设计为自动生成在线广告。这种类型的恶意软件通过在用户界面或屏幕上显示广告,为其开发者创造了收入。
- 秘密的计算机软件,设计用来绕过系统的安全机制,安装在计算机上允许攻击者访问的。
- 肤蝇的幼虫创建用来自动执行特定操作的软件,如DDoS攻击或分发其他恶意软件。机器人是僵尸网络的一部分,僵尸网络是一个由相互连接的设备组成的网络,它使用命令和控制(C&C)软件进行控制。
- 下载程序。一个下载程序的目的是下载和安装额外的恶意程序。
- 启动器。启动器是一种计算机程序,被设计用来秘密启动其他恶意程序。
- 勒索软件。恶意软件,通过加密文件或锁定系统来限制用户访问计算机系统的赎金。
- 根套件。恶意软件旨在隐藏其他恶意程序的存在的恶意软件
- 间谍软件未经许可从受害者的计算机上监视和收集敏感信息的计算机软件。例如,包括键记录器、密码雕刻器和嗅探器。
- 特洛伊木马。木马是一种恶意软件,它伪装成合法的软件,欺骗用户在他们的系统上下载和安装恶意软件。
- 病毒。可以从其他设备传播到其他设备的恶意软件。
- 蠕虫。一种利用操作系统的漏洞进行传播的病毒。蠕虫和病毒之间的主要区别是,蠕虫具有独立地自我复制和传播的能力,而病毒则依赖于人类的活动。
3.3.恶意软件分析
分析恶意软件以了解它是如何工作的,确定其功能、来源和潜在影响的过程被称为恶意软件分析。随着数以百万计的新恶意程序的出现,以及以前检测到的程序的突变版本,安全分析师遇到的恶意软件总数在过去几年中一直在增长。4因此,恶意软件分析对任何响应安全事件的业务和基础设施都至关重要。
恶意软件分析有两种基本方法:(1)静态分析和(2)动态分析。一方面,静态分析涉及到检查恶意软件而不运行它。另一方面,动态分析涉及到运行恶意软件。第3.3.1节和第3.3.2节提供了对这两种方法的深入描述。
3.3.1.静态分析
静态分析包括检查可执行文件的代码或结构,而不执行它。这种分析可以确认一个文件是否具有恶意性,提供关于其功能的信息,还可以用于生成一组简单的签名。例如,用于唯一识别恶意程序的最常见的方法是哈希。也就是说,一个哈希程序产生一个唯一的哈希,一种识别程序的指纹。两个最流行的哈希函数分别是消息摘要算法5(MD5)和安全哈希算法1(SHA-1)。最常见的静态分析方法是:
- 查找字符或字符串的序列。搜索程序的字符串是获得有关其功能的提示的最简单的方法。从二进制文件中提取的字符串可以包含对可执行文件修改或访问的文件路径的引用、程序访问的url、域名、IP地址、攻击命令、加载的Windows动态链接库(dll)的名称、注册表项等等。实用程序工具字符串5可用于搜索ASCII或Unicode字符串,而忽略可执行文件中的上下文和格式化。
- 收集可执行文件的链接库和函数,以及头文件中包含的文件的元数据。这些数据提供了关于许多程序通用的代码库和功能的信息,程序员链接这些程序,以便它们不需要重新实现某个功能。这些Windows函数的名称可以让我们了解可执行文件的是什么。实用程序依赖Walker6是微软的免费程序,用于列出导入和导出的PE文件函数。
- 分析PE文件头和部分。PE文件头提供的信息不仅仅是导入。它们包含关于文件本身的元数据,例如文件的实际部分。检索此信息的一种方法是使用PEView工具。7
- 正在搜索已打包/加密的代码。恶意软件编写者通常使用包装和加密来使他们的文件更难分析。与合法程序相比,被打包或加密的软件程序通常包含很少的字符串和更高的熵。检测打包文件的一种方法是使用PEiD程序8
- 分解程序,即将机器码翻译成汇编语言。这个反向工程过程将可执行文件加载到一个反汇编程序中,以发现程序的功能。拆卸PE可执行文件最相关的软件程序是IDAPro、9Radare210和Ghidra。11
3.3.2.动态分析
动态分析包括执行程序和监视其在系统上的行为。这通常在静态分析达到死角时执行,无论是由于混淆还是由于耗尽了可用的静态分析技术。与静态分析不同,它跟踪由程序执行的真实操作。但是,分析必须在一个安全的环境中运行,以免使系统暴露于不必要的风险之中,因为系统既是运行分析工具的机器,也是网络上的其他机器。为此目的,将设置专用的物理机或虚拟机。
物理机器必须建立在有空气漏洞的网络上,这是一个隔离的网络,其中机器与互联网或任何其他网络断开连接,以防止恶意软件的传播。物理机器的主要缺点是这种没有互联网连接的情况,因为许多恶意程序依赖于互联网连接来进行更新、命令和控制以及其他功能。
第二种选择是设置虚拟机来执行动态分析。虚拟机模拟计算机系统并提供物理计算机的功能。虚拟机中运行的操作系统与主机操作系统保持隔离,因此,虚拟机上运行的恶意软件不会损害主机操作系统。VMware Workstation12和Oracle VM VirtualBox 13是可供分析师使用的一些虚拟机解决方案。此外,还有几种基于沙盒技术的一体化软件产品,可用于执行基本的动态分析。最著名的是布谷鸟沙盒,14,一个开源的自动恶意软件分析系统。这个模块化的沙盒提供了跟踪API调用、分析网络流量或执行内存分析的功能。此外,还有一系列实用程序可用于动态分析恶意软件,并对某些功能执行高级和特定的监控。ProcessMonitor,15或procmon,是Windows的一个工具,用于监视特定的注册表、文件系统、网络、进程和线程活动。Process Explorer 16显示有关哪些句柄和DLL进程被打开或加载到操作系统中的信息。Regshot17是一个注册表比较实用程序,允许拍摄和比较注册表的快照。NetCat18是一种网络实用工具,可用于监控网络上的数据传输。Wireshark19是一个开源嗅探器,它允许捕获数据包,拦截和记录网络流量。另一个不可或缺的软件工具是调试器。调试器用于检查另一个程序的执行情况。它们提供程序运行时的动态视图。恶意软件分析人员选择的主要调试器是OllyDbg20,这是一个免费的×86调试器,有许多插件可以扩展其功能。
使用虚拟化和沙箱进行恶意软件分析的风险在于,一些恶意软件可以在虚拟机或沙箱中运行时检测到,随后,它们的执行方式与在物理机器中执行方式不同,从而使恶意软件分析人员的工作更加困难。此外,即使你采取了所有可能的预防措施,在分析恶意软件时也总是存在一些风险。不时地在虚拟化工具中发现漏洞,使攻击者能够利用其一些特性,如共享文件夹特性。
3.4 恶意软件进化
恶意软件的多样性、复杂性和可用性对保护网络和计算机系统免受攻击构成了巨大挑战。恶意软件不断演变,迫使安全分析师和研究人员通过改进网络防御来跟上步伐。由于使用多态和变形技术来逃避检测并隐藏其真正目的,恶意软件的扩散有所增加。多态恶意软件使用多态引擎变异代码,同时保持原始功能完好无损。打包和加密是隐藏代码的两种最常见的方法。打包器通过一层或多层压缩来隐藏程序的真实代码。然后,在运行时,解包例程恢复内存中的原始代码并执行它。加密人员对恶意软件或其部分代码进行加密和操作,使研究人员更难分析该程序。加密程序包含用于加密和解密恶意代码的存根。变质恶意软件在传播时会将其代码重写为等效代码。恶意软件作者可能使用多种转换技术,包括但不限于寄存器重命名、代码置换、代码扩展、代码收缩和垃圾代码插入。上述技术的结合导致了恶意软件数量的快速增长,使得恶意软件案件的法医调查耗时、成本高昂且更加困难。
传统的防病毒解决方案依赖于基于特征码和启发式/行为方法,存在一些问题。签名是一种独特的特征或一组特征,可以唯一地区分可执行文件,如指纹。然而,基于签名的方法无法检测未知的恶意软件变体。为了应对这些挑战,安全分析人员提出了基于行为的检测,它分析文件的特征和行为,以确定它是否确实是恶意软件,尽管扫描和分析可能需要一些时间。为了克服传统防病毒引擎之前的缺陷,并跟上新的攻击和变种,研究人员开始采用机器学习来补充他们的解决方案,因为机器学习非常适合处理大量数据。
4.传统的机器学习方法
在过去的十年里,机器学习解决方案的研究和部署有所增加,以解决恶意软件检测和分类的任务。如果没有最近的三项事态发展,机器学习方法就不可能取得成功和巩固:
- 第一个开发是标记恶意软件源的增加,这意味着,标记恶意软件第一次不仅可用于安全社区,而且也可用于研究社区。这些提要的大小范围从有限的高质量样本,如微软(Ronen等人,2018)为大数据创新者收集反恶意软件预测挑战提供的样本,到大量的恶意软件,如动物园(YuvalNativ,2015)或病毒s共享(2011)。
- 第二个发展是,计算能力迅速增长,同时也变得更便宜,更接近大多数研究人员的预算。因此,它允许研究人员加快迭代训练过程,并使更大、更复杂的模型适应不断增长的数据。
- 第三,在过去的几十年里,机器学习领域以越来越快的速度发展,在计算机视觉、语音识别和自然语言处理等广泛任务的准确性和可扩展性方面取得了突破性的成功。
在机器学习中,工作流是一个迭代过程,涉及收集可用数据、清理和准备数据、构建模型、验证和部署到生产中。见图2。传统机器学习方法的数据准备过程不是处理原始恶意软件,而是对可执行文件进行预处理,以提取一组提供软件抽象视图的功能。然后,这些特征被用来训练一个模型来解决手头的任务。由于恶意软件功能的多样性,不仅要检测恶意软件,而且要区分不同类型的恶意软件,以便更好地了解它们的功能。用于检测或分类恶意软件的机器学习解决方案之间的主要区别在于所实现的系统返回的输出。一方面,恶意软件检测系统输出一个值y=f(x),范围从0到1,表示可执行文件的恶意。另一方面,分类系统输出属于每个输出类或族的给定可执行文件的概率y∈ ℝN、 其中N表示不同族的数量。5.

图2。机器学习的工作流程。

图3。传统M.L.所使用的特征的分类法。方法
图3提供了这些特征的分类法。因此,特性的类型可以分为两组,如恶意软件分析方法的类型:(1)静态特性和(2)动态特性。下面分别是每个特性类型。
4.1.静态特征
静态特征是从一个程序片段中提取的,而不涉及其执行。在Windows便携式可执行文件中,静态特性基本上来自两个信息来源,即可执行文件的二进制内容,或者是在反编译和分解二进制可执行文件后获得的汇编语言源文件。另一方面,在安卓系统的应用程序中,这些功能是通过拆卸APK来提取的。要提取某些给定软件的汇编语言源代码,您可以使用您所选择的反汇编器工具。对于Windows,你可以使用IDAPro或Radare2。表2和表3总结了所审查的静态方法。下面是图3中对每种静态特性类型的描述。
4.1.1.字符串分析
字符串分析是指提取可执行文件或程序中的每个可打印的字符串。字符串是指一系列字符。搜索字符串是获取有关程序功能的线索的最简单的方法。在这些字符串中可以找到的信息可以是,例如,程序连接到的url、文件位置或由程序访问/修改的文件的文件位置或文件路径、应用程序菜单的名称等。名为“字符串”的实用程序可用于搜索ASCII和Unicode字符串,忽略上下文和格式。
虽然有研究使用字符串分析来检测恶意软件(Konopisky,2018年2;Lee等人,2011),字符串分析通常与其他静态或动态技术一起使用,以减少其缺陷。(Ye等人,2008a)。开发了一个恶意软件检测系统,基于从API执行调用和语义中反映攻击者意图和目标的字符串中提取的可解释字符串。该系统由一个为每个PE文件提取可解释字符串的解析器和一个带装包的SVM集成组成。在金山杀毒实验室收集的数据集上,对该系统的性能进行了评估。
4.1.2.字节和 N-Grams操作码
为恶意软件检测和分类的最常见的特征类型是n-gram。n-gram是给定文本序列中n个项的连续序列。n-克兰斯可以从代表恶意软件的二进制内容的字节序列和从汇编语言的源代码中提取出来。通过将一个文件视为一个字节序列,通过查看每n个连续字节的唯一组合作为一个单个特征来提取字节n-克。另一方面,也可以从汇编语言的源代码中提取汇编语言指令的顺序。在这种情况下,只保留指令的助记符,即。“ADD”、“MUL”、“PUSH”等。因此,操作码或助记符n-克是指每n个连续操作码的唯一组合作为一个单独的特征。
Moskovitch et al. (2008)提出了一种基于文本分类技术的恶意软件分类方法。首先,他们从训练数据中提取出所有的n-gram,n的范围从3到6。其次,他们根据自己的文档频率(DF)评分选择了前5500个特征,然后应用Fisher评分特征选择技术。然后,利用得到的特征作为输入,他们训练了各种算法,如人工神经网络(ANN)、支持向量机(SVM)、朴素贝叶斯(NB)和决策树(DT)。
Jain and Meena (2011) 提出了一种从已知的恶意样本中提取n字节n-gram特征,n范围从1到8的方法,以协助未知可执行文件的分类。由于唯一的n-gram的数量非常大,他们使用了一种称为类文档频率的技术来减少特征空间。最后,利用朴素贝叶斯、基于实例的学习者、决策树、成人森林和随机森林等不同的分类器建立了不同的n-gram模型
Fouana等人(2017)提出了一种计算训练样本中每个字节ng信息增益的方法,并选择以最大为特征的Kng作为特征。然后,他们分别计算了来自恶意软件和良性样本的特征向量的每个属性的平均值。最后,根据未知样本的特征向量与两类平均向量的相似性,将新软件划分为两类之一。
Santos等人(2013)提出了一种基于操作码序列出现频率及其相关性的恶意软件检测技术。每个程序都被表示为一个特征的向量,其中每个特征对应于一个不同的1-g或2-g。为了减少2g特征的数量,他们应用信息增益来选择前1000个特征。他们的方法在17000个恶意程序和1000个良性程序上进行了验证,结果表明,以皮尔逊VII为核的支持向量机分类器获得了更高的精度。
Shabtai等人(2012)提出了一个基于操作码n-gram特征的恶意软件检测框架,n的范围为1到6。他们进行了一系列广泛的实验:(1)确定最好的术语表示,无论是术语频率(TF)或术语频率逆文档频率,(2)确定n-gram大小,(3)找到最优K前n克和特征选择方法,和(4)评估各种机器学习算法的性能。
Hu等人(2013)提出了MutantX-S,这是一种基于从拆卸过程后获得的恶意软件的汇编语言源码中提取的操作码N-gram特征的聚类方法。MutantXS通过应用哈希技巧和近距离线性聚类算法,提高了处理大量具有高维特征的恶意软件的可伸缩性。该算法不处理大量数据,而是只对原型进行凝聚层次聚类。
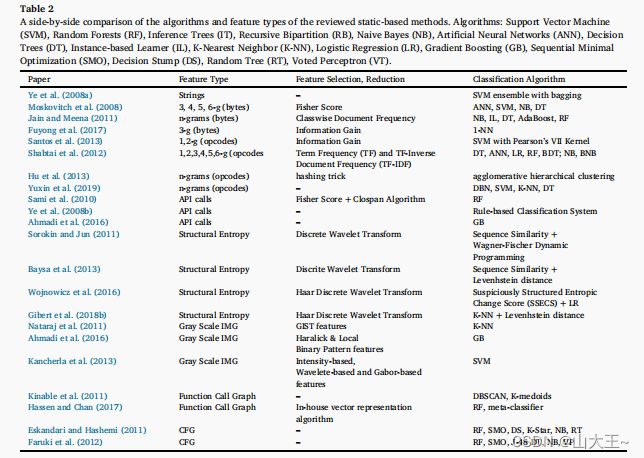
表2 A所回顾的基于静态的方法的算法和特征类型的并排比较。算法:支持向量机(SVM)、随机森林(RF)、推理树(IT)、递归二分区(RB)、朴素贝叶斯(NB)、人工神经网络(ANN)、决策树(DT)、基于实例的学习者(IL)、K最近邻(K-NN)、Logistic回归(LR)、梯度提升(GB)、序列最小优化(SMO)、决策树(DS)、随机树(RT)、投票感知器(VT)。
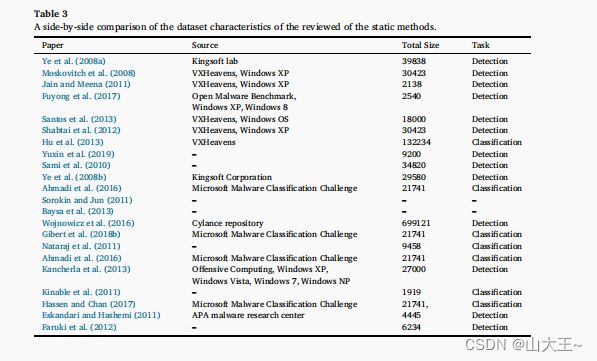
表3 并排比较的数据集特征的静态方法。
另外,Yusin等人(2019)使用深度信念网络(DBN)作为自动编码器来减少输入特征向量的维数。因此,在学习完成后,DBN的最后一个隐藏层输出一个作为输入传递的N-gram向量的新的表示或编码。通过使用未标记数据训练DBN,其分类精度优于k-最近邻、支持向量机和决策树算法。
尽管n-gram方法成功地检测到了恶意软件,但它们仍有一些值得一提的问题。首先,详尽地枚举所有的n个克是不切实际的,而且在计算上也是禁止的。当特征数大于样本数时,估计模型参数可能会导致维数的诅咒。因此,必须采用特征选择和缩减技术。其次,研究人员(Raffetal.,2018b)得出结论,字节n克似乎主要从可执行文件中的字符串内容,特别是从PE头的项目中学习。由于有数百万个潜在的n克(对于一个较大的n克),特征选择技术倾向于选择那些足够频繁出现的特征作为特征。这鼓励了选择主要由字符串和填充物组成的低熵特征。第三,无论学习到什么n-克,我们在对新样本进行分类时都必须获得精确的匹配。因此,任何微小的变化都会使该特性不会发生,因此,也不会影响我们的模型。因此,这种泛化的缺乏是过拟合的一个潜在来源。
4.1.3.API函数调用
应用程序编程接口(API)及其函数调用被认为是非常有区别性的特性。文献表明,API函数调用可以用于建模程序的行为。本质上,API函数和系统调用与操作系统提供的服务有关,如网络、安全、文件管理等。由于软件在没有使用API函数的情况下没有其他方式访问系统资源,因此对特定API函数的调用提供了表示恶意软件行为的关键信息。
Sami等人(2010)提出了一个基于API调用的使用情况来分类PE文件的三步框架。首先,他们分析了便携式可执行文件,并提取了导入的API调用的列表。其次,他们使用clospan算法减少了特征向量(Yanetal.,2003)。最后,利用特征子集使用随机森林学习模型。
Ye等人(2008b)提出了一种基于规则的恶意软件分类系统。该系统由三个主要组件组成:(1)PE解析器、(2)OOA(面向目标的关联)规则生成器和(3)恶意软件检测模块。PE解析器负责解析可执行文件,并提取相应的API函数的静态执行调用。然后,这些调用被用作PE文件的签名,并存储在签名数据库中。然后,应用OOA算法生成存储在规则数据库中的类关联规则。最后,将特性调用和规则传递给恶意软件检测模块,以确定一个文件是良性的还是恶意的。
Ahmadi等人(2016)使用794个API函数调用的子集的频率,从对近500K个恶意软件样本的分析中提取,构建一个多模态系统,将恶意软件划分为家族。第6节提供了对他们的研究的完整描述
4.1.4.熵
恶意软件作者经常使用各种模糊技术来隐藏可执行文件的恶意目的。最常用的两种是压缩和加密,它们用于在静态分析中隐藏恶意段。因此,能够检测可执行文件中是否存在加密或压缩的代码段是信息安全行业非常感兴趣的问题。为此,人们采用了熵分析,因为带有经过压缩或加密的代码段的文件往往比本机代码具有更高的熵。在信息论的背景下,字节序列的熵反映了它的统计变化。尤其是,零熵意味着相同的特征已经在分析的片段中重复。这种行为可以在“填充”的代码块中观察到。相反,高熵值表明区块完全由不同的值组成。例如,Lyda et al.(2007)分析了由纯文本文件、原生文件、压缩文件和加密可执行文件组成的文件库,发现可执行文件的平均熵分别为5.09、6.80和7.17。
因此,以往的研究使用了高平均熵来检测加密和压缩的存在。然而,当恶意代码以一种复杂的方式隐藏时,可能很难通过这种简单的熵统计来检测。减少文件熵的一种常见方法是填充“nop”指令。然而,具有加密、压缩、原生或填充段的文件往往具有独特和独特的熵水平。因此,研究人员(Sorokin和6月,2011)开始分析所谓的结构熵的文件,表示恶意软件的字节序列作为流的熵值,每个值表示熵的数量在一小块代码在一个特定的位置(见图4)。特别是,Sorokin和Jun(2011)比较了一个未知文件的结构熵与训练数据集之间的相似性来检测恶意软件。
Baysa等人(2013)扩展了之前的工作来检测变质恶意软件。他们应用小波分析来确定熵值有显著变化的区域。然后,他们使用莱文什坦距离比较了两个文件之间的相似性。因此,给定一个未知的软件片段,它将被归类为与训练集中最相似的样本对应的类。
Wojnowicz等人(2016)开发了一种方法,可以自动量化文件的结构熵的变化使其可疑的程度。这个分数是通过两步计算的:(1)他们计算了可执行文件的结构熵的基于小波的能谱;(2)他们在第j个分辨率水平上匹配各种逻辑回归模型,产生一组beta系数来加权每个分辨率能量的强度对文件的恶意概率。
4.1.5.恶意软件表示为灰度图像
一种有趣的恶意软件可视化方法首先被引入。
Nataraj等人(2011),他将恶意软件的二进制内容可视化为一个灰度图像。这是通过将图像中的每个字节解释为一个像素来实现的,其中的值范围从0到255(0:黑色,255:白色)。然后,生成的数组被重新组织为一个二维数组。
图5显示了来自两个恶意软件家族的样本,以灰度图像表示。您可以观察到,给定家族的样本的图像表示非常相似,但与属于不同家族的图像不同。这种视觉上的相似性是通过重用代码来创建新的二进制文件而产生的结果。因此,如果重复使用旧的样本来实现新的二进制文件,那么所得到的样本将是相似的。在大多数情况下,通过将一个可执行文件表示为灰度图像,就可以检测到属于同一家族的样本之间的微小变化。
这种视觉相似性已经被不同的作者用来检测和分类恶意软件。特别是,Nataraj等人(2011)从恶意软件的二进制内容的灰度表示中提取了GIST特征。最后,以欧氏距离为度量,利用K-最近邻算法(K-NN)将一个新的可执行文件分类为一个族或另一个族。Ahmadi等人(2016)提取了Haralick和局部二元模式特征,以便使用增强树分类器对恶意软件进行分类。
Kancherla等人(2013)提取了三组特征:(1)基于强度的特征,(2)基于小波的特征,(3)基于Gabor的特征。特别是,他们提取了平均强度、方差、模式、偏度、峰度以及强度值为0和255的像素数。关于基于小波的特征,他们使用Daubechies小波(也称为db4)进行了三级小波分解,得到了一组近似系数和三组详细系数。从这些系数中提取的特征包括均值、方差、最大值和最小值。最后,为了提取基于Gabor的特征,他们将Gabor滤波器(输入与Gabor函数的卷积)应用于图像。在15000个恶意样本和12000个良性样本的数据集上评估了支持向量机作为学习算法的性能,其中70%用于训练,30%用于测试。
软件的灰度图像表示存在一些与图像生成方式直接相关的缺点。首先,二进制文件不是二维图像,通过这样转换它们,您可以引入不必要的先验。首先,要构造一个图像,你需要选择一个图像宽度,它添加一个新的超参数来调整。请注意,选择宽度会根据二进制的大小决定图像的高度。其次,它赋予不同行像素之间不存在的空间相关性,这可能不是真的。
此外,与大多数静态特性一样,它也存在代码混淆技术的问题。特别是,加密和压缩等技术可能会完全改变二进制程序的字节结构,因此,基于这种表示方式的方法将无法正确地对其类进行分类。这可以在属于自动运行的样本的灰度表示中观察到。K和Yuner。来自MalImg数据集的一个家族(Nataraj等人,2011年),由于两者都被UPX封隔器压缩,它们几乎相等。
4.1.6.函数调用图
函数调用图(FCG)是一个有向图,其顶点表示组成软件程序的函数,而边表示函数调用。一个顶点由以下两种类型的函数之一表示:
- 本地函数,由程序员实现,以执行特定的任务。
- 外部功能:由操作操作系统提供。或系统库和外部库。
该图的一个特殊性是,只有局部函数可以调用外部函数,而不是相反。函数调用图是由拆汇编文件的静态分析生成的。为了提取WindowsPE可执行文件的FCG,可以使用IDAPro或Radare2。
Kinable等人(2011)提出了一种基于函数调用图之间结构相似性的集群恶意软件的方法。他们研究了k-medoids和基于密度的空间聚类与噪声应用(DBSCAN)算法的性能。通过图匹配的成对图相似度得分计算调用图之间的比较。该实验是在一个包含来自1050个不同恶意软件家族的194,675个样本的数据集上进行的。
Hassen和Chan(2017)提出了一种基于函数聚类提取函数调用图向量表示的方法。系统的第一个模块提取FCG,并用函数名为外部函数标记顶点。内部函数的原始名称不会被保留,相反,每个内部函数都表示为该函数实现的指令序列。然后,将生成的FCG传递给下一个模块,对本地函数进行聚类,并用它们的聚类id重新标记。最后,使用基于函数的Minhash签名的函数聚类将图形表示转换为特征向量。
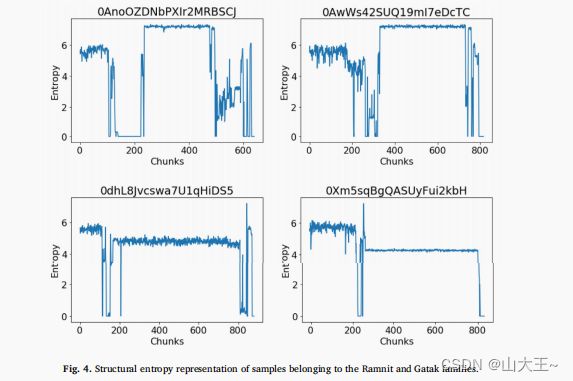
图4。属于拉姆尼特和加塔克家族的样本的结构熵表示。

图5。属于拉姆尼特和棒棒糖家族的恶意软件样本的二进制内容的灰度表示。
4.1.7.控制流程图
控制流图(CFG)是一个有向图,其中节点表示基本块,边表示控制流路径。基本块是具有入口点(执行的第一指令)和退出点(执行的最后一条指令)的程序指令的线性序列。CFG是在程序执行过程中可以遍历的所有路径的表示。
Eskandari and Hashemi (2011)提出了一种通过他们的控制流图来检测变质恶意软件的方法。该系统由三个组成部分组成。首先,将拆解PE文件。其次,对程序集文件应用预处理算法,生成包含API调用的CFG。然后,将得到的稀疏图转换为一个向量表示。第三,系统使用分类算法对CFG进行标签。分别对系统的2140个和2305个良性和恶意PE可执行文件进行了性能评估,采用随机森林分类器获得了最佳结果,准确率为97%。
Faruki等人(2012)提出了一种生成API调用ngram的方法,以检测来自恶意软件的CFG中的恶意代码。在他们的工作中,可执行文件的抽象是由所进行的API调用来表示。这些API调用随后使用n-gram分析转换为特征向量,n的范围为1到4。然后,使用各种算法进行分类,包括随机森林、序列挖掘优化、J-48决策树、朴素贝叶斯和投票感知器。以API4-g特征向量为输入,随机森林分类器效果最好。
4.2.动态特性
动态特征是从运行时恶意软件的执行中提取的特征。动态分析涉及在恶意软件运行时监控恶意软件(并观察实际执行的指令序列或触发的API函数序列),或在恶意软件执行后检查系统。文件和注册表值的创建和修改。表4和表5汇总了所审查的动态方法。下面介绍了通过动态分析提取的最常见信息和特征。方法根据其输入数据分为四组。第4.2.1节介绍了从恶意软件的内存、寄存器和CPU使用情况中提取特征的方法。第4.2.2节包括从可执行文件的运行时跟踪中提取功能的方法。第4.2.3节总结了从恶意软件的网络活动中提取特征的方法。最后,第4.2.4节介绍了处理恶意软件API调用跟踪的方法。
4.2.1.内存和寄存器的使用情况
计算机程序的行为可以用运行时的内存内容的值来表示。换句话说,在计算机程序运行时存储在不同寄存器中的值可以区分良性程序和恶意程序。
Ghiasi等人(2012)提出了一种基于恶意软件行为相似性的方法。首先,他们监视恶意软件的运行时行为,并在调用API之前和之后存储每个连接的API调用的寄存器值。随后,他们追踪了寄存器值的分布和变化,并为EAX、EBX、EDX、EDI、ESI和EBP寄存器的每个值创建了一个向量。在匹配阶段,计算一个新文件和整个训练文件之间的相似性得分。然后,将新文件设置为训练集中相似性得分最高的文件的标签。
Ghiasi等人(2015)基于二进制行为以不同方式影响寄存器值的假设,提出了一种查找运行时行为相似性的方法。在他们的工作中,记录运行时行为,并连接来自公共dll的一些API调用。该系统分析内存内容和寄存器值,以建立两个文件之间的相似性得分。当一个新文件输入系统时,将计算该文件与原型之间的最高相似度得分。原型是作为整个数据集的代表性样本的小的文件集,它在成对的距离分析中提供了一个可接受的近似。然后,如果这两个文件达到了相似度的最小阈值,则它们是相似的。
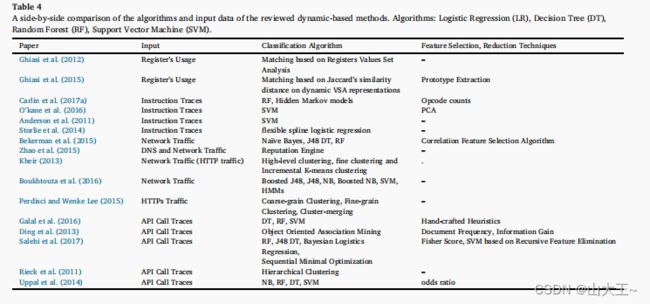
表4:基于动态的方法的算法和输入数据的并排比较。算法:Logistic回归(LR)、决策树(DT)、随机森林(RF)、支持向量机(SVM)。
4.2.2.指令跟踪
动态指令跟踪是在程序执行过程中调用的处理器指令序列。与静态指令跟踪相反,动态跟踪是在执行时排序的,而静态跟踪是在在二进制文件中出现时排序的。动态跟踪是对程序行为的一种更健壮的度量方法,因为代码打包器和加密器可能会混淆和阻碍代码指令的静态分析。
Carlin等人(2017a)提出了一种在虚拟机上执行动态分析的方法,以从良性和恶意的可执行文件中提取程序运行时跟踪。他们通过测试两种算法来分析用于检测恶意软件的操作码序列:(1)随机森林分类器对所有基于计数的数据进行分类,(2)隐马尔可夫模型对基于操作码序列中的时间关系的数据进行分类。Carlinetal.,2017b,不是基于操作码计数建立一个分类系统,而是执行了n-克兰姆分析,其中n=1……3,以增强特征集。他们的方法使用高达32K的操作码序列来检测恶意软件,准确率为99.01%。
O‘kane等人(2016)分析了恶意运行时跟踪,以确定(1)构建软件恶意的稳健指标所需的最优操作码集,并确定(2)程序执行的最佳持续时间,以准确分类良性和恶意软件。该方法在程序执行过程中提取的操作码密度直方图上使用了一个支持向量机来检测恶意软件。
Anderson等人(2011)介绍了一种恶意软件检测方法,该方法基于分析使用从执行目标可执行文件中收集的指令跟踪构建的图。这些图表示马尔可夫链,其中的顶点是指令,而转移概率是由轨迹中包含的数据估计的。利用高斯核和谱核等图核的组合,计算了指令迹图之间的相似性矩阵。最后,将得到的相似矩阵输入给支持向量机进行分类。
Storlie等人(2014)提出了一种基于动态收集的指令跟踪分析的恶意软件检测系统。指令跟踪是从沙箱环境中执行恶意软件中收集的,这是以太恶意软件分析框架的修改版本(Dinaburgetal.,2008)。每个指令轨迹都用一个马尔可夫链结构表示,其中每个转移矩阵P都有一些行被建模为狄利克雷向量。然后,使用灵活的样条逻辑回归模型确定程序的恶意性。
4.2.3.网络流量
检测网络上的恶意流量可以唯一地提供对恶意程序行为的具体见解。一旦恶意软件感染了主机,它可能会与外部服务器建立通信,以获得对受害者执行的命令,或下载更新、其他恶意软件,或泄露用户/设备的私人和敏感信息。因此,对进出网络的网络流量、网络内的流量和主机活动的监控,为检测恶意行为提供了有用的信息。文献中的方法在几个抽象级别上提取事件,从原始数据包到网络流,详细的协议解码,如HTTP和DNS请求,到基于主机的事件和元数据,如IP地址、端口和数据包计数。
Bekerman等人(2015)提出了一种通过分析网络流量来检测恶意软件的系统。在他们的工作中,他们从分析互联网、传输和应用层上的网络流量中提取了972个行为特征。然后,使用相关特征选择算法(Hall,1999)。然后,利用得到的特征来测试三种不同的分类算法,包括朴素贝叶斯、决策树(J48)和随机森林。
Zhao等人(2015)提出了一种基于恶意DNS和流量分析的APT恶意软件感染检测系统。该系统由两个主要组件组成:(1)恶意DNS检测器和(2)恶意网络流量分析器。一方面,恶意DNS检测器提取了14个表明APT恶意软件和C&C域的特征。另一方面,网络流量分析器结合了基于签名的系统和基于异常的系统,该系统基于Snort的VRT规则集(Snort,2015)的规则的准确性检测感染,以及在协议和应用程序级别发生的异常。然后,用J48决策树对威胁进行分类。
Kheir(2013)提出了一种基于恶意软件HTTP流量中的用户代理异常来建立检测签名的系统方法。首先,他们在HTTP流量中提取用户代理报头字段。然后,他们执行了一个初始的高级集群步骤,以对可能具有类似模式的用户代理进行分组。然后,他们对每一组用户代理应用了第二个聚类步骤,以将那些可以用一组公共签名来描述的代理分组在一起。最后,采用增量K-means聚类方法对在同一集群中共享相似模式序列的用户代理进行重新分组。然后,令牌子序列算法进一步提取这些共享模式,并构建令牌序列列表,这些序列被转换为使用web代理应用于网络或应用层的签名。
Boukhtuta等人(2016年)提出了一种基于DPI和流压缩头的恶意软件检测和分类系统。他们的方法在沙箱中执行恶意软件3分钟,以产生具有代表性的恶意流量。然后,从流量中提取双向流特征,如前向和后向数据包的数量、前向数据包的最大和最小到达时间、数据包大小等。所得特征作为以下分类算法的输入:Boost J48、J48、Naïve Bayes、Boost Naïve Bayes和SVMs,检测到流量是否恶意。一旦流量被定义为恶意,隐马尔可夫模型创建了非确定性模型,该模型使用一组45个特征(包括数据包总数、中间值、平均值和到达时间的第一个四分位数等)来描述恶意软件系列。