浅析卷积神经网络
一、简要介绍
谈到深度学习,不得不说的就是卷积神经网络了,近年来,无论是在图像识别、语音识别领域,还是在目标检测、语义分割领域,卷积神经网络都大放异彩,向我们展现出它独特的魅力。卷积神经网络 (Convolutional Neural Networks,CNN)是一类包含卷积运算且具有深度结构的前馈神经网络,它是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。卷积神经网络它最重要的特性在于"局部连接"(或局部感知)与"权值共享"。
-
局部连接
所谓局部连接,是指卷积层的节点只与前一层的部分节点相连接,只用来学习部分特征 ;
图像中的某一块区域中,像素之间的相关性与像素之间的距离相关,距离近的像素间相关性强,距离远相关性就较弱;
相邻的像素结合起来表达一个特征,距离较远的像素之间影响较小 ;
随着层数的增加,feature map里的点映射到原图中的感受视野会逐渐增大 ;

从图中我们可以看到第n+1层的每个节点只与第n层的3个节点相邻,而并非是与第n层的5个节点全部相连,这样原本需要5x3=15个权值参数,现在却只需要3x3个权值参数,足足减少了40%的参数量。这种局部连接的方式大幅减少了参数数量,加快了学习速率,同时也在一定程度上减少了过拟合的可能。
-
权值共享
权值共享是卷积神经网络的另外一个主要特征,通俗的说,权值共享是指整张图片共享一个卷积核内的参数,比如一个3x3的卷积核,其内的9个参数被整张图片所共享,卷积核的参数不会因图像区域的不同而发生改变

在上面这张图中,采用局部连接的方式,需要 4x3=12个参数,而加上了权值共享的方法后,现在仅仅需要3个权值,更进一步地减少了参数数量。
二、整体描述
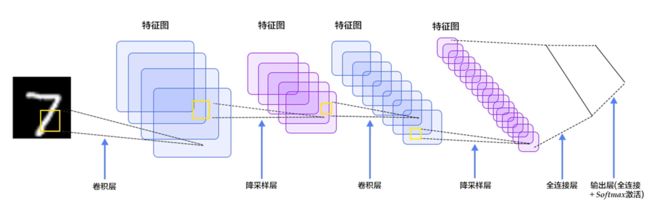
如图所示,一个完整的卷积神经网络由若干卷积层、池化层(下采样层)、全连接层组成,其中卷积层用于提取图像的底层特征,池化层主要用于特征降维减少参数量,以及防止过拟合。

可以看到,在卷积层Conv的后面还有一层,叫做激活层,为什么还要加激活层呢?这是因为卷积运算属于线性运算,而单纯的线性运算形成的线性模型的表达能力往往是不够的,所以我们引入激活函数来添加非线性的因素
三、各层网络结构
1、输入层
输入到卷积神经网络中的图像是具有 [宽x高x深] 尺寸的图像,它是像素值构成的矩阵。示例:输入 [32x32x3] ,第一个32表示图像的宽度,第二个32表示图像的高度,3表示图像有三个通道,分别为R、G、B通道,一般彩色图片具有三个通道,而黑白图片只有一个通道

2、卷积层
人的大脑在识别图片的过程中,并不是一下子将整张图片同时识别,而是对图片中每一个局部特征先进行局部感知,然后对局部进行综合操作,从而得到全部信息,卷积操作就是进行局部感知的过程。
卷积是从图像中提取信息的第一层,它的目标是提取输入数据的特征。先来看一张图:

左边部分是原始的图像,中间的是卷积核,也叫滤波器,它在原始图像上一点点滑动,一共滑动了9次,得到右边的特征图 feature map,对于一个 mxn 大小的卷积核,

其对一原图像 X 进行卷积运算的过程为:卷积核 W 中的每个权值分别于所覆盖到的原图像 X 中对应的像素 x 相乘
然后再对它们进行求和,计算公式为:

对于一张图像来说,一个完整的卷积过程为:卷积核以一定的步长 stride 滑动,并对所覆盖的区域进行卷积运算得到每一个 z 值,直至遍历完整张图像。
步长 stride
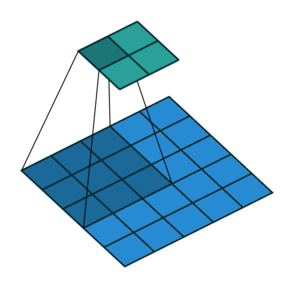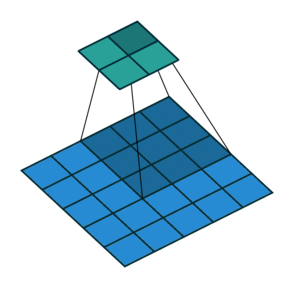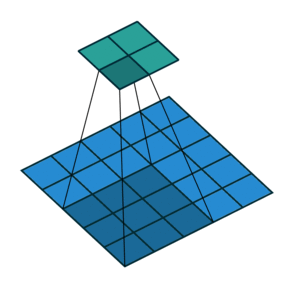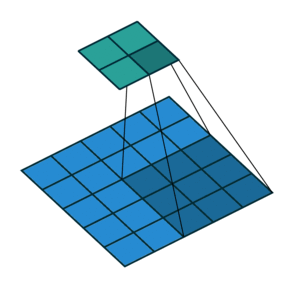
卷积核在原始图像中每次滑动的距离就叫做步长,stride = 1 表示卷积核每次滑动一个像素的距离,是最基本的单步滑动,它是标准的卷积模式。下面这张图中步长 stride 为 2
填充 padding
我们会发现,在卷积核进行卷积操作的过程中,边缘尤其是四个角处的像素被光顾到的次数较少,而中间的某些像素每次都会被卷积核光顾到,这就有可能造成图像边缘信息的丢失。为了解决这个问题,人们使用额外的"0像素"对图像边缘进行填充,这样在滑动时,卷积核可以允许原始边缘像素作为其中心,从而有效的提取到原始图像的边缘信息。

卷积的计算公式
怎么计算输出的 feature map 图像的尺寸呢?
-
输入图片的尺寸:一般用 n x n 表示输入的 image 的大小
-
卷积核的大小: 一般用 f x f 表示卷积核的尺寸
-
填充 padding: 一般用 p 表示填充大小
-
步长 stride: 一般用 s 表示步长大小
-
输出图片的尺寸:一般用 o 来表示
如果已知 n、f、p、s ,则可以求 o ,计算公式为 :
其中 是向下取整符号,当结果不是整数时则进行向下取整
3、池化层
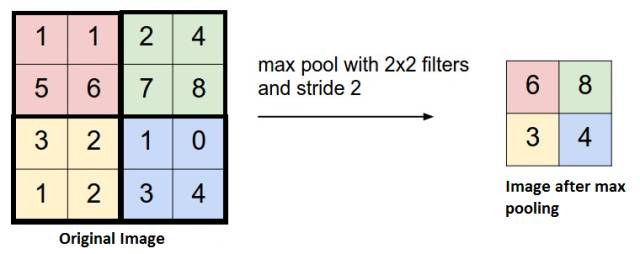
在通过卷积获得图像特征以后,下一步我们希望对图片进行分类,理论上讲,我们可以用所有提取到的特征取训练分类器,但是这时会使计算机面临巨大计算量的挑战,因为通常我们所输入图片的尺寸是比较大的。为了解决这个问题,人们在处理大图像时,人们对图像中不同区域的特征进行聚合统计,例如人们可以用一个区域特征的最大值或者平均值去代表这个区域的特征,就相当于从这个区域中选择一个代表,而这种聚合的操作就叫做池化
( pooling )
池化,也叫做下采样或者降采样,主要用于特征降维、减少参数数量、防止过拟合,同时提高模型的容错性。它主要分为最大池化 ( Max pooling ) 和平均池化 ( Average pooing ) 两种。
池化操作其实和卷积差不多,来看下面这个动图
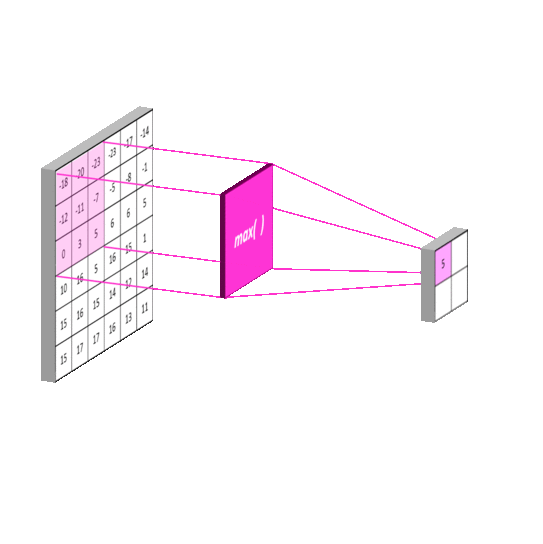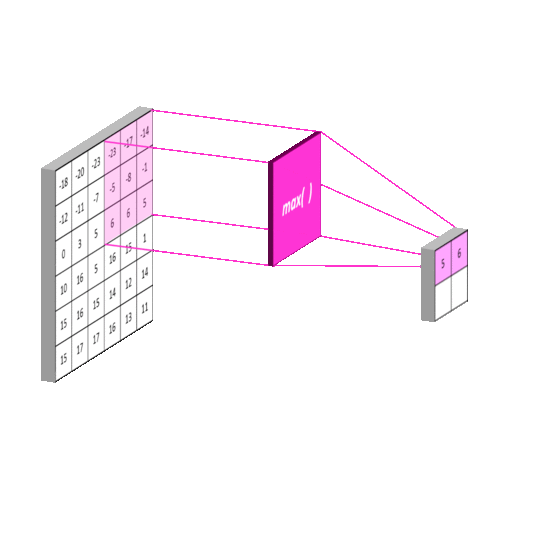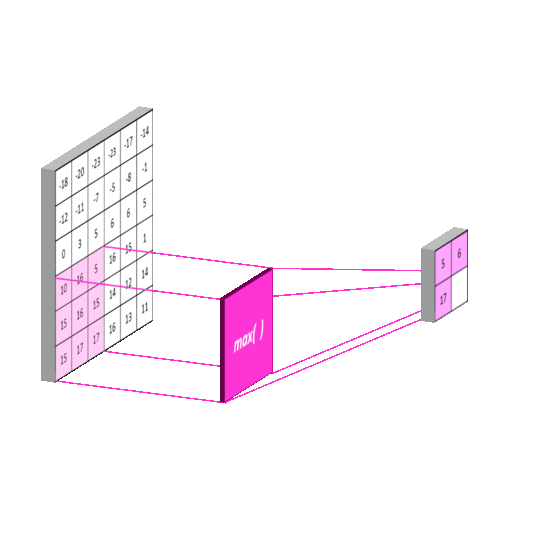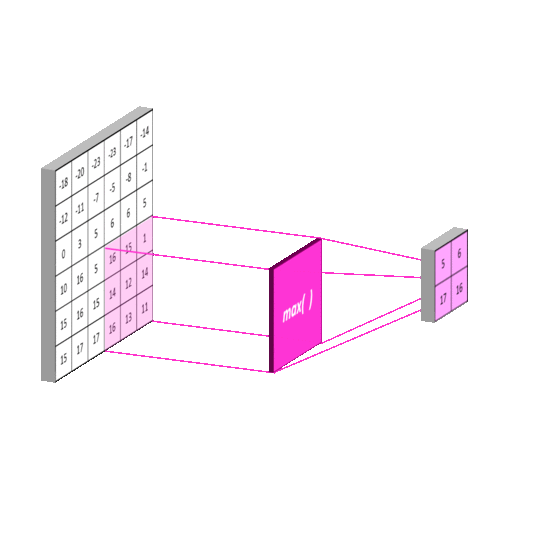
池化有3个重要特性:
- 不同于卷积,池化没有要学习的参
- 池化运算后图像的宽度和高度被压缩,但是通道数不变
- 降低了数据特征,扩大了卷积核的感受视野
4、全连接层 FC
全连接层被称为 FC 层,卷积池化操作提取到的时图像的局部特征,全连接则是把之前提取到的局部特征通过权值矩阵,组装成完成的图,进而起到分类的作用。通俗的来说,全连接要做的,就是对之前的所有操作进行一个总结,通过对特征图进行维度上的改变,来得到每个分类类别对应的概率值,从而进行分类。
全连接操作

(1)原始图片为 9X9 的黑白图片,经过一系列卷积、激活、池化操作后,得到3张尺寸被压缩为 3x3 的 feature map ,将得到的特征图展平变为一维向量
(2)将展平后得到的向量喂入全连接层中,在全连接层中有一个非常重要的分类函数,叫 softmax,它输出的是每个类别对应的概率。比如:[0.5,0.03,0.89,0.97,0.42,0.15] 就表示有6个类别,并且属于第四个类别的概率值0.97最大,因此判定属于第四个类别。经分类函数处理之后,我们可以得到原始图像属于各个类别的概率,从而对图像进行分类。

四、图解CNN
例如:判断图片中的动物是不是猫

1、特征提取(卷积、激活函数、池化)

2、分类识别(全连接)

红色的神经元表示这个特征被找到了(激活了),同一层的其他神经元,要么猫的特征不明显,要么没找到。
当我们把这些找到的特征组合在一起,发现最符合要求的是猫,完成识别!