TensorFlow Lite:针对边缘端的机器学习模型优化
近年来,倾向于开发更复杂的深度学习模型从而提高模型的准确性,但这也导致了模型计算资源消耗和广泛可用性的问题,因为我们不能在资源受限的设备(如移动设备和嵌入式设备)上使用如此巨大的模型。这是否意味我们必须使用更轻量化的模型,即使精度有所下降?是否有可能在智能手机或树莓派(Raspberry Pi)甚至微控制器等设备上部署这些复杂的模型呢?
使用TensorFlow Lite优化模型是这些问题的答案。这篇博文将全面介绍TF Lite。您将学习各种支持的模型优化,并分析优化后的模型在边缘设备上的性能。本博客是TensorFlow Lite系列的第一篇。
1. TensorFlow Lite
TensorFlow Lite(缩写TF Lite)是一个开源的跨平台框架,通过使模型运行在移动、嵌入式和物联网设备上,提供设备端的机器学习。
有两种方法可以生成TensorFlow Lite模型:
- 将TensorFlow模型转换为TensorFlow Lite模型。
- 从头开始创建TensorFlow Lite模型。
我们将主要关注将TensorFlow模型转换为TensorFlow Lite模型。
2. TensorFlow Lite的优势

使用TensorFlow Lite模型进行设备上机器学习的优点:
- 低延迟:由于在边缘端进行推断,由于不需要从服务器往返,因此延迟很低。
- 数据隐私:由于模型在边缘端推理,数据不跨网络进行共享。因此,个人信息不会离开设备,解决任何有关数据隐私的问题。
- 网络连接:由于不需要互联网连接,所以不存在网络连接问题。
- 模型大小:TensorFlow Lite模型是轻量级的,特别合适边缘端。
- 低功耗:高效推理和和不需要网络连接,从而具有低功耗的特点。
3.将TensorFlow模型转换为TensorFlow Lite模型

TF Lite Converter将TensorFlow模型转换为TF Lite模型。TF Lite模型以一种特殊的高效可移植格式表示,这种格式称为FlatBuffers,具有.tflite文件扩展名。相比于TensorFlow的 protocol buffer 模型格式具有多个优势,比如减小了模型大小和更快的推理速度,它使TF Lite能够在计算和内存资源有限的设备上高效地执行。
优化模型有几种方法。TF Lite目前只支持量化技术,不需要任何外部库/依赖。目前TFLite支持的量化类型有:
- 1.Float-16 量化
- Integer 量化
- Dynamic Range 量化
在深入研究这些技术并获得转换后的TF Lite模型之前,让我们首先训练一个基础模型。下载代码
4. Base Model Training
我们训练一个简单的图像分类器,将图像分类为猫或狗,将这个作为一个基础模型。我们将优化这个模型,并将结果与使用不同技术进行比较。
导入库
# Importing necessary libraries and packages.
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_datasets as tfds
from tensorflow.keras.models import Model
import tensorflow_model_optimization as tfmot
from tensorflow.keras.layers import Dropout, Dense, BatchNormalization
%load_ext tensorboard
4.1准备数据集
我们可以直接从TensorFlow数据集(tfds)导入数据集。在这里,我们将数据集划分为训练集、验证集和测试集,分割比例为0.7:0.2:0.1。as_supervised参数保持True,因为我们需要图像的标签进行分类。
# Loading the CatvsDog dataset.
(train_ds, val_ds, test_ds), info = tfds.load('cats_vs_dogs', split=['train[:70%]', 'train[70%:90%]', 'train[90%:]'], shuffle_files=True, as_supervised=True, with_info=True)
我们看一看tfds.info()中提供的数据集信息。数据集有两个类,分别是“猫”和“狗”,有16283、4653、2326张训练、验证和测试图像。
# Obtaining dataset information.
print("Number of Classes: " + str(info.features['label'].num_classes))
print("Classes : " + str(info.features['label'].names))
NUM_TRAIN_IMAGES = tf.data.experimental.cardinality(train_ds).numpy()
print("Training Images: " + str(NUM_TRAIN_IMAGES))
NUM_VAL_IMAGES = tf.data.experimental.cardinality(val_ds).numpy()
print("Validation Images: " + str(NUM_VAL_IMAGES))
NUM_TEST_IMAGES = tf.data.experimental.cardinality(test_ds).numpy()
print("Testing Images: " + str(NUM_TEST_IMAGES))
Output:
Number of Classes: 2
Classes : ['cat', 'dog']
Training Images: 16283
Validation Images: 4653
Testing Images: 2326
函数tfds.visualization.show_examples()显示图像及其对应的标签。当我们想要在一行代码中可视化一些图像时,它非常方便!
# Visualizing the training dataset.
vis = tfds.visualization.show_examples(train_ds, info)

设置16作为批大小,224×224作为图像大小,以便能够有效地处理数据集。为了准备数据集,已经相应地调整了图像的大小。
# Defining batch-size and input image size.
batch_size = 16
img_size = [224, 224]# Resizing images in the dataset.
train_ds = train_ds.map(lambda x, y: (tf.image.resize(x, img_size), y))
val_ds = val_ds.map(lambda x, y: (tf.image.resize(x, img_size), y))
让我们确保使用buffered prefetching来从磁盘生成数据。预取与训练步骤的预处理和模型执行重叠。这样做可以减少训练的步骤时间和提取数据所需的时间。
train_ds = train_ds.cache().batch(batch_size).prefetch(buffer_size=10)
val_ds = val_ds.cache().batch(batch_size).prefetch(buffer_size=10)
test_ds = test_ds.cache().batch(batch_size).prefetch(buffer_size=10)
为了将图像提供给TF Lite模型,我们需要提取测试图像及其标签。我们将把它们存储到变量中,并将它们提供给TF Lite进行评估。
# Extracting and saving test images and labels from the test dataset.
test_images = []
test_labels = []
for image, label in test_ds.take(len(test_ds)).unbatch():
test_images.append(image)
test_labels.append(label)
4.2加载模型
为了进行图像分类,我们选择了在imagenet数据集上预先训练的EfiicientNet B0模型。effecentnets是最先进的图像分类模型。它的表现明显优于其他ConvNets。
让我们从tf.keras.applications()中导入模型。最后一层通过设置include_top = False来移除。我们已经设置了输入图像的大小为224×224像素,并保持池化层为GlobalMaxPooling2D。让我们加载模型并解冻所有层,使它们可训练。
# Defining the model architecture.
efnet = tf.keras.applications.EfficientNetB0(include_top = False, weights ='imagenet', input_shape = (224, 224, 3), pooling = 'max')# Unfreezing all the layers of the model.
for layer in efnet.layers:
set_trainable = True
添加一个全连接层给预训练模型并训练它。这一层为推理层。并添加Dropout和BatchNormalization以减少过拟合。
# Adding Dense, BatchNormalization and Dropout layers to the base model.
x = Dense(512, activation='relu')(efnet.output)
x = BatchNormalization()(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.2)(x)
predictions = Dense(2, activation='softmax')(x)
4.3模型的编译
我们准备编译模型。我们使用初始学习率为0.0001的Adam Optimizer,sparse categorical cross-entropy作为损失函数,精度作为度量特征。编译之后,我们查看模型。
# Defining the input and output layers of the model.
model = Model(inputs=efnet.input, outputs=predictions)
# Compiling the model.
model.compile(optimizer=tf.keras.optimizers.Adam(0.0001), loss =tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics = ["accuracy"])
# Obtaining the model summary.
model.summary()
Output:
=====================================================================Total params: 4,740,453
Trainable params: 4,697,406
Non-trainable params: 43,047
我们使用 Model Saving Callback和 Reduce LR Callback.
- 模型
Saving Callback以最佳的验证精度保存模型 - 如果验证损失连续3次保持不变,则Reduce LR Callback将学习率降低0.1倍。
# Defining file path of the saved model.
filepath = '/content/model.h5'
# Defining Model Save Callback and Reduce Learning Rate Callback.
model_save = tf.keras.callbacks.ModelCheckpoint(
filepath,
monitor="val_accuracy",
verbose=0,
save_best_only=True,
save_weights_only=False,
mode="max",
save_freq="epoch")
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='loss', factor=0.1, patience=3, verbose=1, min_delta=5*1e-3,min_lr =5*1e-9,)
callback = [model_save, reduce_lr]
4.4 模型的训练
调用方法model.fit()来训练模型并对模型进行15个epoch的训练。
# Training the model for 15 epochs.
model.fit(train_ds, epochs=15, steps_per_epoch=(len(train_ds)//batch_size), validation_data=val_ds, validation_steps=(len(val_ds)//batch_size), shuffle=False, callbacks=callback)
4.5评估模型
完成训练,检查模型在测试集中的性能。
# Evaluating the model on the test dataset.
_, baseline_model_accuracy = model.evaluate(test_ds, verbose=0)
print('Baseline test accuracy:', baseline_model_accuracy*100)
Output:
Baseline test accuracy: 98.53 %
5. 使用TF Lite进行训练后量化
量化的工作原理是降低用于表示模型参数的数字的精度,默认情况下这些参数是32位浮点数。量化可以获得更小的模型和更快的计算。以下量化类型在TensorFlow Lite中可用:

我们逐个探索不同类型的量化并比较它们的性能。
5.1 Float-16量化
在Float-16量化中,权值被转换为16位浮点值。这导致了模型尺寸的2倍减少。模型大小有了显著的减少,并使得对延迟和准确性的最小影响。
# Passing the Keras model to the TF Lite Converter.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# Using float-16 quantization.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
# Converting the model.
tflite_fp16_model = converter.convert()
# Saving the model.
with open('/content/fp_16_model.tflite', 'wb') as f:
f.write(tflite_fp16_model)
我们已经将Float 16量化传递给了 converter.target_spec.supported_type来指定量化的类型。为了获得模型精度,定义了evaluate()函数,它接受tflite模型并返回模型精度。
#Function for evaluating TF Lite Model over Test Images
def evaluate(interpreter):
prediction= []
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
input_format = interpreter.get_output_details()[0]['dtype']
for i, test_image in enumerate(test_images):
if i % 100 == 0:
print('Evaluated on {n} results so far.'.format(n=i))
test_image = np.expand_dims(test_image, axis=0).astype(input_format)
interpreter.set_tensor(input_index, test_image)
# Run inference.
interpreter.invoke()
output = interpreter.tensor(output_index)
predicted_label = np.argmax(output()[0])
prediction.append(predicted_label)
print('\n')
# Comparing prediction results with ground truth labels to calculate accuracy.
prediction = np.array(prediction)
accuracy = (prediction == test_labels).mean()
return accuracy
在测试集中查看通过FP-16量化TF Lite模型性能。
# Passing the FP-16 TF Lite model to the interpreter.
interpreter = tf.lite.Interpreter('/content/fp_16_model.tflite')
# Allocating tensors.
interpreter.allocate_tensors()
# Evaluating the model on the test dataset.
test_accuracy = evaluate(interpreter)
print('Float 16 Quantized TFLite Model Test Accuracy:', test_accuracy*100)
print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
Output:
Float 16 Quantized TFLite Model Test Accuracy: 98.58 %
Baseline Keras Model Test Accuracy: 98.53 %
5.2 Dynamic Range 量化
在Dynamic Range 量化中,权重被转换为8位精度。Dynamic Range 量化实现了模型尺寸的4倍减少。模型大小有了显著的减少,并确保对延迟和准确性的最小影响。
# Passing the baseline Keras model to the TF Lite Converter.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# Using the Dynamic Range Quantization.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# Converting the model
tflite_quant_model = converter.convert()
# Saving the model.
with open('/content/dynamic_quant_model.tflite', 'wb') as f:
f.write(tflite_quant_model)
我们在测试数据集中评估这个TF Lite模型。
# Passing the Dynamic Range Quantized TF Lite model to the Interpreter.
interpreter = tf.lite.Interpreter('/content/dynamic_quant_model.tflite')
# Allocating tensors.
interpreter.allocate_tensors()
# Evaluating the model on the test images.
test_accuracy = evaluate(interpreter)
print('Dynamically Quantized TFLite Model Test Accuracy:', test_accuracy*100)print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
Output:
Dynamically Quantized TFLite Model Test Accuracy: 98.15 %
Baseline Keras Model Test Accuracy: 98.53 %
5.3 Integer量化
Integer量化是一种优化策略,它将32位浮点数(如权值和激活输出)转换为最接近的8位定点数。这导致了一个更小的模型和更快的推理速度,这对低功耗设备,如微控制器非常有价值
Integer量化需要一个代表性的数据集,也就是训练数据集中的一些图像,才能进行转换。
# Passing the baseline Keras model to the TF Lite Converter.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# Defining the representative dataset from training images.
def representative_data_gen():
for input_value in tf.data.Dataset.from_tensor_slices(test_images).take(100):
yield [input_value]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
# Using Integer Quantization.
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# Setting the input and output tensors to uint8.
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
# Converting the model.
int_quant_model = converter.convert()
# Saving the Integer Quantized TF Lite model.
with open('/content/int_quant_model.tflite', 'wb') as f:
f.write(int_quant_model)
评估测试数据集上获得的Integer Quantized TF Lite模型。
# Passing the Integer Quantized TF Lite model to the Interpreter.
interpreter = tf.lite.Interpreter('/content/int_quant_model.tflite')
# Allocating tensors.
interpreter.allocate_tensors()
# Evaluating the model on the test images.
test_accuracy = evaluate(interpreter)
print('Integer Quantized TFLite Model Test Accuracy:', test_accuracy*100)
print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
Output:
Integer Quantized TFLite Model Test Accuracy: 92.82 %
Baseline Keras Model Test Accuracy: 98.53 %
6. TF Lite模型在树莓派上的性能评价
所有转换后的TF Lite模型的性能都在拥有4GB RAM的树莓派4上进行了评估。以下是性能结果。
6.1 测试精度

FP-16量化模型的精度略有提高,而 dynamic range量化模型的精度略有下降。在Interger量化模型的情况下,可以观察到一个非常大的降幅(~6%)。
6.2 Model 大小
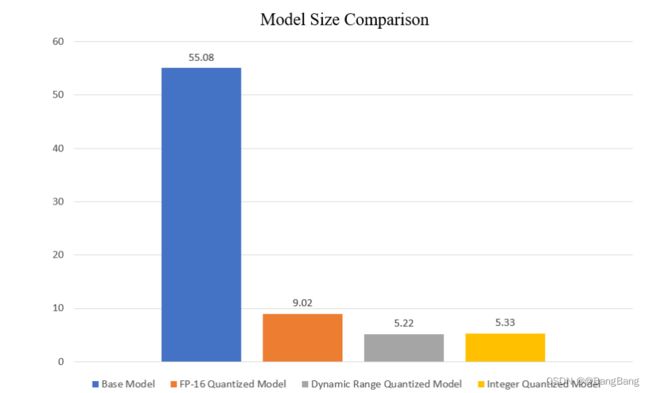
dynamic range范围和Interger量化模型中,模型尺寸惊人地减少了10倍。在FP-16量化模型的情况下,模型尺寸减少了6倍。
6.3推理时间

从测试数据集中随机选取100幅图像,检查TF Lite模型的推断时间。所提到的推理时间是一个模型对100幅图像进行推理所花费的平均时间。
FP-16量化模型和dynamic range量化模型的推理速度比基准模型快2.5倍。而Interger量化模型的推理速度快3.5倍。
下载代码