【今日CV 计算机视觉论文速览 第130期】Thu, 13 Jun 2019
今日CS.CV 计算机视觉论文速览
Thu, 13 Jun 2019
Totally 39 papers
?上期速览✈更多精彩请移步主页

Interesting:
?LED2Netz照明条件估计的去雾和低光图像增强方法, 研究人员提出了一种基于环境光照估计的低光照图像去雾与细节提升算法。基于环境照明的估计,研究人员同时实现了大气光照估计、投射图估计和低光照提升三个任务。从FADE数据合成了雾图和低光图用于训练。结果表明这一算法对于图像细节提升和去雾具有十分优异的表现没有色差的晕轮。(from Chung-Ang University韩国中央大学)
网络主要进行了环境光照明(e illumination map)的估计,随后用于暗光增强和去雾,最后进行细节提升和优化:

一些结果的比较:

对于暗光增强的结果:
real world dataset:Fattal dataset [13]
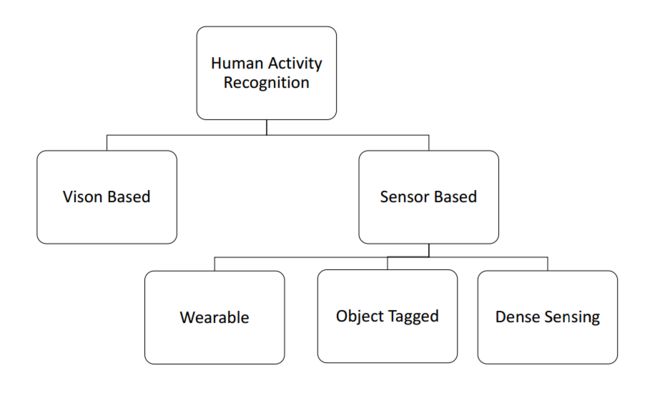
?人体行为识别综述,综述了不同的行为识别方法、设备和分类。基于行为、移动和交互的行为识别以及十个不同的子类别,并综述了各个领域的最新研究结果的度量标准 (from 悉尼Macquarie University)
识别技术的分类:
?全天候全气候室外光照估计, (from adobe)
code:http://lvsn.github.io/allweather
?压缩模型过拟合用于图像超分辨, (from SIAT-SenseTime Joint Lab 中科院深圳)
Daily Computer Vision Papers
| Presence-Only Geographical Priors for Fine-Grained Image Classification Authors Oisin Mac Aodha, Elijah Cole, Pietro Perona 单独的外观信息通常不足以准确区分细粒度的视觉类别。人类专家利用其他线索,例如拍摄给定图像的位置和时间,以便为最终决定提供信息。该上下文信息在许多在线图像集合中容易获得,但是现有的图像分类器仅仅关注于基于图像内容进行预测而未充分利用。 |
| LAEO-Net: revisiting people Looking At Each Other in videos Authors Manuel J. Marin Jimenez, Vicky Kalogeiton, Pablo Medina Suarez, Andrew Zisserman 捕捉人们的相互凝视对于理解和解释他们之间的社会互动至关重要。为此,本文解决了在视频序列中检测人们看彼此LAEO的问题。为此,我们提出了LAEO Net,这是一个新的深度CNN,用于确定视频中的LAEO。与之前的作品相比,LAEO Net将时空轨迹作为输入和整个轨道的原因。它由三个分支组成,一个用于每个角色的跟踪头部,另一个用于相对位置。此外,我们介绍了两个新的LAEO数据集UCO LAEO和AVA LAEO。彻底的实验评估证明了LAEONet成功确定两个人是否是LAEO的能力以及它发生的时间窗口。我们的模型在现有的TVHID LAEO视频数据集上实现了最先进的结果,明显优于以前的方法。最后,我们将LAEO Net应用于社交网络分析,我们根据他们LAEO的频率和持续时间自动推断出一对人之间的社会关系。 |
| Compressed Sensing MRI via a Multi-scale Dilated Residual Convolution Network Authors Yuxiang Dai, Peixian Zhuang 磁共振成像MRI重建是一个主动的反问题,可以通过传统的压缩感知CS MRI算法来解决,该算法在基于迭代优化的方式中利用MRI的稀疏性质。然而,基于迭代优化的CSMRI方法的两个主要缺点是耗时且在模型容量方面受限。同时,最近基于深度学习的CSMRI的一个主要挑战是模型性能和网络规模之间的权衡。为了解决上述问题,我们开发了一种新的多尺度扩张网络,用于MRI重建,具有高速和卓越的性能。与具有相同感受野的卷积核相比,扩散卷积减少了较小核的网络参数,并扩展了核的接收域以获得几乎相同的信息。为了保持丰富的特征,我们提供全局和局部残差学习,以提取更多的图像边缘和细节。然后我们利用连接层融合多尺度特征和残差学习,以便更好地重建。与几种非深度和深度学习CSMRI算法相比,该方法可以提供更好的重建精度和明显的视觉改进。此外,我们执行噪声设置以验证模型稳定性,然后在MRI超分辨率任务上扩展所提出的模型。 |
| **Handwritten Text Segmentation via End-to-End Learning of Convolutional Neural Network Authors Junho Jo, Hyung Il Koo, Jae Woong Soh, Nam Ik Cho 我们通过端到端训练卷积神经网络CNN来提出一种新的手写文本分割方法。许多传统方法通过提取连接的组件然后对它们进行分类来解决该问题。然而,当手写组件和机器印刷部件重叠时,这两步方法具有局限性。与传统方法不同,我们针对此问题开发了端到端深度CNN,不需要任何预处理步骤。由于没有针对此目标的公开数据集,并且像素明智的注释耗时且成本高,我们还提出了一种生成实际训练样本的数据合成算法。为了训练我们的网络,我们开发了基于交叉熵的损失函数来解决不平衡问题。合成图像和真实图像的实验结果表明了该方法的有效性。具体而言,所提出的网络仅针对合成图像进行了训练,然而在真实文档中删除手写文本将OCR性能从71.13提高到92.50,显示了我们的网络和合成图像的泛化性能。 |
| Towards Real-Time Head Pose Estimation: Exploring Parameter-Reduced Residual Networks on In-the-wild Datasets Authors Ines Rieger, Thomas Hauenstein, Sebastian Hettenkofer, Jens Uwe Garbas 头部姿势是人体交流的关键组成部分,因此是人机交互的决定性因素。实时头部姿势估计在人类机器人交互或驾驶员辅助系统的背景下是至关重要的。用于头部姿势估计的最有希望的方法基于卷积神经网络CNN。然而,CNN模型通常太复杂而无法实现实时性能。为了应对这一挑战,我们探索了一个受欢迎的CNN子组,剩余网络ResNets并对其进行修改以减少参数数量。 ResNets针对不同的图像尺寸进行了修改,包括低分辨率图像和不同数量的图层。他们接受野生数据集的培训,以确保真实世界的适用性。因此,我们证明可以在减少参数数量的同时保持ResNets的性能。修改后的ResNets实现了最先进的精确度,并为实时适用性提供了快速推理。 |
| Tackling Partial Domain Adaptation with Self-Supervision Authors Silvia Bucci, Antonio D Innocente, Tatiana Tommasi 域适应方法已经显示出减少视域之间的边际分布差异的有希望的结果。它们允许训练可靠的模型,这些模型适用于不同性质的照片,绘画等数据集,但是当域不共享相同的标签空间时,它们仍然很难。在部分域适配设置中,其中目标仅覆盖源类的子集,在不引起负转移的情况下减小域间隙是具有挑战性的。许多解决方案只是通过添加启发式样本加权策略来保持标准域自适应技术。在这项工作中,我们展示了如何从补丁的空间协同定位获得的自监控信号如何定义支持适应的辅助任务,而不管跨域的确切标签共享条件。我们构建了最近的一项工作,该工作引入了用于领域泛化的拼图游戏任务,我们描述了如何重新构建部分领域适应的这种方法,并且我们展示了它如何在与它们结合时增强现有的自适应解决方案。获得的三个数据集的实验结果支持了我们的方法的有效性。 |
| Vispi: Automatic Visual Perception and Interpretation of Chest X-rays Authors Xin Li, Rui Cao, Dongxiao Zhu 医学成像包含用于提供诊断和治疗决策的基本信息。检查视觉感知和解释图像以生成报告是放射科医师的繁琐临床程序,其中自动化预期将大大减少工作量。尽管自然图像字幕的快速发展,计算机辅助医学图像视觉感知和解释仍然是一项具有挑战性的任务,主要是由于缺乏高质量的注释图像报告对和量身定制的生成模型,足以提取和利用局部语义特征,特别是那些与异常有关。为了应对这些挑战,我们提出了一种自动医学图像解释系统Vispi,该系统首先通过视觉支持对常见胸部疾病进行分类和定位,然后通过细致的LSTM模型生成报告,对图像进行注释。通过分析开放的IU X射线数据集,我们使用自动性能评估指标ROUGE和CIDEr证明了Vispi在疾病分类,本地化和报告生成方面的卓越性能。 |
| Boosting Few-Shot Visual Learning with Self-Supervision Authors Spyros Gidaris, Andrei Bursuc, Nikos Komodakis, Patrick P rez, Matthieu Cord 少数镜头学习和自我监督学习解决了同一问题的不同方面如何训练具有很少或没有标记数据的模型。很少有镜头学习的目的是优化方法和模型,可以有效地学习识别低数据体系中的模式。自我监督学习的重点是未标记的数据,并调查监测信号以提供高容量的深度神经网络。在这项工作中,我们利用这两个领域的互补性,并提出一种通过自我监督改善少数镜头学习的方法。我们使用自我监督作为一些镜头学习管道中的辅助任务,使特征提取器能够学习更丰富和更可转移的视觉表示,同时仍然使用少量注释样本。通过自我监督,我们的方法可以自然地扩展到在少数镜头设置中使用来自其他数据集的各种未标记数据。我们报告了一系列架构,数据集和自我监督技术的持续改进。 |
| Evaluation of Dataflow through layers of Deep Neural Networks in Classification and Regression Problems Authors Ahmad Kalhor, Mohsen Saffar, Melika Kheirieh, Somayyeh Hoseinipoor, Babak N. Araabi University of Tehran, College of Engineering, School of Electrical and Computer Engineering, Tehran, Iran 本文介绍了两个简单有效的指标来评估输入数据和流经前馈深度神经网络层的数据。对于分类问题,数据流空间中目标标签的分离率被解释为表明设计层在改善网络泛化方面的性能的关键因素。根据所解释的概念,提出了基于无形距离的评估指标。类似地,对于回归问题,数据流空间中目标输出的平滑率被解释为表示设计层在改善网络泛化方面的性能的关键因素。根据所解释的平滑概念,针对回归问题提出了基于无形距离的平滑度指数。为了更严格地考虑分离和平滑的概念,引入了它们的扩展版本,并且通过将回归问题解释为分类问题,表明分离和平滑度指数是相关的。通过四个案例研究,显示了使用引入指数的利润。在第一个案例研究中,对于分类和回归问题,一些已知输入数据集的挑战性分别通过提出的分离和平滑度指数进行比较。在第二个案例研究中,数据流的质量通过Cifar10和Cifar100分类中的两个预先训练的VGG 16网络层进行评估。在第三个案例研究中,表明正确的分类率和分离指数几乎相同,特别是在锯齿指数增加时。在最后一个案例研究中,通过使用所提出的平滑度指数逐层比较两个用于预测波士顿房价的多层神经网络。 |
| Recognizing Manipulation Actions from State-Transformations Authors Nachwa Aboubakr, James L. Crowley, Remi Ronfard 操纵动作将对象从初始状态转换为最终状态。在本文中,我们报告使用对象状态转换作为识别操作动作的手段。我们的方法受到直觉的启发,即对象状态在视觉上比静止帧的动作更明显,因此提供与空间时间动作识别互补的信息。我们首先定义一个状态转换矩阵,将动作标签映射到前置状态和后置状态。从每个关键帧,我们学习对象及其状态的外观模型。然后可以从状态转移矩阵识别操纵动作。我们报告了EPIC厨房行动识别挑战的结果。 |
| High Accuracy Classification of White Blood Cells using TSLDA Classifier and Covariance Features Authors Hamed Talebi, Amin Ranjbar, Alireza Davoudi, Hamed Gholami, Mohammad Bagher Menhaj 近几十年来,通过应用工程工具在医学科学的不同领域创建自动化流程是一个高度发展的领域。在这种背景下,许多医学图像处理和分析研究人员在人工智能中使用有价值的方法,这可以减少必要的人力,同时提高结果的准确性。在各种医学图像中,血液显微图像在心力衰竭诊断中起重要作用,例如,血癌。血癌诊断中的突出成分是白细胞WBC,由于其在显微图像中的一般特征,有时难以识别和分类任务,例如不均匀的颜色照度,不同的形状,尺寸和纹理。此外,骨髓图像中与红细胞相邻的重叠WBC被识别为分类部分中的错误的原因。在本文中,我们努力通过Na ve Bayes聚类方法在医学图像中分割各个部分,并在下一阶段通过TSLDA分类器进行分割,TSLDA分类器由从协方差描述符结果98.02准确度获得的特征提供。看来这个结果在WBC识别中是令人愉快的。 |
| LED2Net: Deep Illumination-aware Dehazing with Low-light and Detail Enhancement Authors Guisik Kim, Junseok Kwon 我们提出了一种基于照明图的新型去雾和低光增强方法,该方法由卷积神经网络CNN精确估计。在本文中,照明图被用作三个不同任务的组件,即大气光估计,透射图估计和弱光增强。为了基于视网膜理论同时训练CNN用于去雾和低光增强,我们从来自FADE数据集的正常模糊图像合成了许多低光和模糊图像。此外,我们使用细节增强进一步改善网络。实验结果表明,我们的方法在数量上和质量上都优于theart算法的最新状态。特别是,我们的无雾图像呈现鲜艳的色彩,增强了可见度,没有光晕效果或颜色失真。 |
| ***Pose from Shape: Deep Pose Estimation for Arbitrary 3D Objects Authors Yang Xiao, Xuchong Qiu, Pierre Alain Langlois, Mathieu Aubry, Renaud Marlet 大多数深度姿态估计方法需要针对特定对象实例或类别进行训练。在这项工作中,我们提出了一种完全通用的深度姿态估计方法,该方法不要求网络在相关类别上进行训练,也不要求类别中的对象具有规范姿势。我们相信这是设计机器人系统的关键步骤,该机器人系统可以与不属于预定义类别的野外新对象进行交互。我们的主要观点是通过表示目标对象的3D形状来动态地调整姿势估计。更确切地说,我们训练卷积神经网络,其将测试图像和3D模型作为输入,并输出相对于3D模型的输入图像中的对象的相对3D姿势。我们证明了我们的方法提高了标准基准的监督类别姿态估计的性能,即Pascal3D,ObjectNet3D和Pix3D,我们提供的结果优于现有技术。更重要的是,我们通过在LINEMOD数据集以及ImageNet上的动物等自然实体上提供结果,表明我们的网络训练了来自ShapeNet的日常人造物体,无需对全新类型的3D物体进行任何额外培训。 |
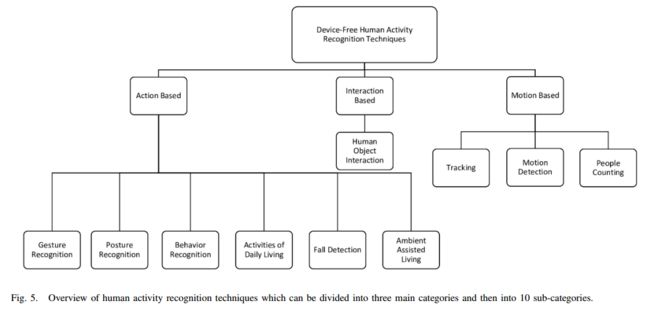
| Different Approaches for Human Activity Recognition: A Survey Authors Zawar Hussain, Michael Sheng, Wei Emma Zhang 近年来,人类活动识别因其在健康,安全和监视,娱乐和智能环境等各个领域的应用而变得越来越重要。在人类活动识别方面已经做了大量工作,研究人员利用不同的方法,如可穿戴,物体标记和无设备,来识别人类活动。在本文中,我们对2010年至2018年期间在人类活动识别的各个领域开展的工作进行了全面调查,主要关注无设备解决方案。无设备方法变得非常流行,因为主体不需要携带任何东西,相反,环境被标记有设备以捕获所需信息。我们提出了一种新的分类法,用于对在活动识别领域进行的研究工作进行分类,并将现有文献分为基于行动,基于运动和基于交互的三个子领域。我们进一步将这些领域划分为十个不同的子主题,并介绍这些子主题的最新研究工作。与之前仅关注一种活动的调查不同,据我们所知,我们涵盖了活动识别中的所有子领域,并对这些子领域的最新研究工作进行了比较。具体来说,我们讨论了所提出工作的关键属性和设计方法。然后,我们基于10个重要指标提供广泛的分析,为读者提供人类活动识别的不同子领域的最新技术和趋势的完整概述。最后,我们讨论了开放式研究问题,并提供了人类活动识别领域的未来研究方向。 |
| Indoor image representation by high-level semantic features Authors Chiranjibi Sitaula, Yong Xiang, Yushu Zhang, Xuequan Lu, Sunil Aryal 室内图像特征提取是图像处理,模式识别,机器人等多个领域的基本问题。然而,基于像素,颜色,形状对象部分或图像上的对象提取特征的大多数现有特征提取方法在描述语义信息(例如,对象关联)方面具有有限的能力。因此,这些技术涉及不期望的分类性能。为了解决这个问题,我们提出了高级语义特征的概念,并设计了四个步骤来提取它们。具体来说,我们首先通过提取图像中的原始对象来构造对象模式字典,然后从对象模式字典中检索和提取语义对象。我们最终基于计算的概率和del参数提取我们的高级语义特征。在三个公开可用的数据集MIT 67,Scene15和NYU V1上的实验表明,我们的特征提取方法优于用于室内图像分类的最先进的特征提取方法,因为我们的特征的维度低于那些方法。 |
| ***DeepSquare: Boosting the Learning Power of Deep Convolutional Neural Networks with Elementwise Square Operators Authors Sheng Chen, Xu Wang, Chao Chen, Yifan Lu, Xijin Zhang, Linfu Wen 能够显着提高学习能力的现代神经网络模块通常会给原始神经网络增加太多的计算复杂性。在本文中,我们追求非常有效的神经网络模块,它可以显着提高深度卷积神经网络的学习能力,而且额外的计算成本可以忽略不计。我们首先在理论上和实验上都提出元素方形算子有可能增强神经网络的学习能力。然后,我们设计了四种带有元素方形算子的轻量级模块,命名为Square Pooling,Square Softmin,Square Excitation和Square Encoding。我们将四个轻量级模块添加到Resnet18,Resnet50和ShuffleNetV2,以便在ImageNet 2012数据集的实验中获得更好的性能。实验结果表明,我们的模块可以为基本卷积神经网络模型带来显着的精度提升。我们的轻量级模块的性能甚至可以与许多复杂的模块相媲美,例如双线性池,挤压和激励以及Gather Excite。我们的高效模块特别适用于移动型号。例如,当配备单个Square Pooling模块时,ImageNet 2012上ShuffleNetV2 0.5x的前1个分类精度绝对提高1.45,没有额外的参数和可忽略的推理时间开销。 |
| CDPM: Convolutional Deformable Part Models for Person Re-identification Authors Kan Wang, Changxing Ding, Stephen J. Maybank, Dacheng Tao 部分级别表示对于健壮的人员识别至关重要。由于行人检测中的错误,对于身体部位通常存在严重的错误对齐问题,这降低了部件表示的质量。为了解决这个问题,我们提出了一种名为Convolutional Deformable Part Models CDPM的新模型。 CDPM通过将复杂的零件对齐过程分离为两个更简单的步骤来工作。首先,垂直对准步骤借助多任务学习模型检测垂直方向上的每个部分。其次,基于自我关注的水平细化步骤抑制每个检测到的身体部位周围的背景信息。由于这两个步骤是正交和顺序执行的,因此部分对齐的难度显着降低。在测试阶段,CDPM能够精确对准柔性身体部位,而无需任何外部信息。广泛的实验结果证明了CDPM对零件对齐的有效性。最令人印象深刻的是,CDPM在三个大型数据集市场1501,DukeMTMC ReID和CUHK03上实现了最先进的性能。 |
| Synthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-based CT Image Augmentation for Object Detection Authors Changhee Han, Yoshiro Kitamura, Akira Kudo, Akimichi Ichinose, Leonardo Rundo, Yujiro Furukawa, Kazuki Umemoto, Hideki Nakayama, Yuanzhong Li 准确的计算机辅助诊断,依靠大规模注释的病理图像,可以减轻忽视诊断的风险。不幸的是,在医学成像中,大多数可用数据集都是小碎片。为了解决这个问题,作为数据增强DA方法,3D条件生成对抗网络GAN可以将期望的真实多样化3D图像合成为附加训练数据。然而,对于基于一般边界框的3D对象检测,不存在基于3D条件GAN的DA方法,而与严格的3D分割不同,它可以以医生最小的注释成本来定位疾病区域。此外,由于病变位置大小衰减不同,因此基于GAN的进一步DA性能需要多种条件。因此,我们建议3D多条件GAN MCGAN生成逼真的多样化32 x 32 x 32结节,这些结节自然放置在肺部计算机断层扫描图像上,以提高3D物体检测的灵敏度。我们的MCGAN采用两个鉴别器来调节上下文鉴别器学习将真实与合成结节分类为具有噪声盒居中环境的对,结节鉴别器试图将具有大小衰减条件的真实与合成结节分类。结果表明,基于三维卷积神经网络的检测可以在固定的假阳性率下在任何结节大小衰减下实现更高的灵敏度,并且克服了MCGAN生成的真实结节的医疗数据缺乏,甚至专家医生也无法将它们与视觉图灵中的真实区分开来。测试。 |
| **Hand Orientation Estimation in Probability Density Form Authors Kazuaki Kondo, Daisuke Deguchi, Atsushi Shimada 手部定位是理解手部行为并随后支持人类活动所必需的基本特征。在本文中,我们提出了一种估计概率密度形式的手方向的新方法。它可以解决直接角度表示中的循环性问题,并且可以基于不同的特征集成多个预测。我们验证了所提方法的性能以及使用我们的数据集的集成示例,该数据集捕获了协作组的工作。 |
| Pay Attention to Convolution Filters: Towards Fast and Accurate Fine-Grained Transfer Learning Authors Xiangxi Mo, Ruizhe Cheng, Tianyi Fang 我们提出了一种有效的转移学习方法,用于使ImageNet预训练的卷积神经网络CNN适应细粒度图像分类任务。传统的转移学习方法通常面临训练时间和准确性之间的权衡。通过将注意模块添加到预训练网络的每个卷积滤波器,我们能够在端到端流水线中对每个卷积信号的重要性进行排序和调整。在本报告中,我们展示了我们的方法可以在几个时期内使预先测试的ResNet50适应细粒度转移学习任务,并且实现高于传统转移学习方法的准确性,并接近从头开始训练的模型。我们的模型还提供可解释的结果,因为卷积信号的等级显示利用和放大哪些卷积通道以获得更好的分类结果,以及哪些信号应被视为特定转移学习任务的噪声,可以将其修剪为更低型号尺寸。 |
| Semi-Supervised Exploration in Image Retrieval Authors Cheng Chang, Himanshu Rai, Satya Krishna Gorti, Junwei Ma, Chundi Liu, Guangwei Yu, Maksims Volkovs 我们提出了我们的Landmark图像检索挑战2019的解决方案。这一挑战基于大型Google标志性数据集V2 9。目标是为每个提供的查询图像检索包含相同地标的所有数据库图像。我们的解决方案是全局和本地模型的组合,以形成初始KNN图。然后,我们使用最近提出的图形遍历方法EGT 1的新扩展,称为半监督EGT,以细化图形并检索更好的候选者。 |
| Recurrent U-Net for Resource-Constrained Segmentation Authors Wei Wang, Kaicheng Yu, Joachim Hugonot, Pascal Fua, Mathieu Salzmann 现有技术的分割方法依赖于非常深的网络,这些网络在没有非常大的训练数据集的情况下并不总是容易训练,并且在标准GPU上运行往往相对较慢。在本文中,我们介绍了一种新颖的循环U Net架构,它保留了原始U Net的紧凑性,同时大大提高了其性能,使其在几个基准测试中表现优于最新技术水平。我们将展示其在多个任务中的有效性,包括手部分割,视网膜血管分割和道路分割。我们还引入了用于手部分割的大规模数据集。 |
| **Inferring 3D Shapes from Image Collections using Adversarial Networks Authors Matheus Gadelha, Aartika Rai, Subhransu Maji, Rui Wang 我们研究了在三维形状下学习概率分布的问题,给出了从未知视点获取的多个对象的二维视图。我们的方法称为投影生成对抗网络PrGAN训练3D形状的深度生成模型,其投影或渲染与所提供的2D分布的分布相匹配。通过添加可微分投影模块,我们可以在学习阶段推断出潜在的3D形状分布,而无需访问任何明确的3D或视点注释。我们展示了我们的方法可以生成与直接在3D数据上训练的GAN相当的3D形状。适用于多种形状类别,包括椅子,飞机和汽车。实验还表明,二维形状在几何和视点上的解缠结表示导致二维形状的良好生成模型。我们模型的关键优势在于它可以估计3D形状,视点,并以完全无监督的方式从输入图像生成新颖的视图。我们进一步研究如何在训练时获得诸如深度,视点或部分分割等附加信息的情况下如何改进生成模型。为此,我们提出了新的可微分投影算子,可供PrGAN用于学习更好的3D生成模型。我们的实验表明,我们的方法可以成功地利用额外的视觉线索来创建更多样化和准确的形状。 |
| All-Weather Deep Outdoor Lighting Estimation Authors Jinsong Zhang, Kalyan Sunkavalli, Yannick Hold Geoffroy, Sunil Hadap, Jonathan Eisenmann, Jean Fran ois Lalonde 我们提出了一种神经网络,可以从单个LDR图像预测HDR室外照明。我们工作的核心是在任何天气条件下从LDR全景图准确学习HDR照明的方法。我们通过在合成图像和真实图像的组合上训练另一个CNN来获得这一点,以作为LDR全景图的输入,并回归Lalonde Matthews室外照明模型的参数。训练该模型使得它重建天空的外观,并且b渲染由该照明点亮的物体的外观。我们使用该网络标记具有照明参数的LDR全景图的大规模数据集,并使用它们来训练我们的单图像户外照明估计网络。我们通过大量实验证明,我们的全景和单幅图像网络都优于现有技术,与以前的工作不同,能够处理从晴天到阴天的天气状况。 |
| Compressive Hyperspherical Energy Minimization Authors Rongmei Lin, Weiyang Liu, Zhen Liu, Chen Feng, Zhiding Yu, James M. Rehg, Li Xiong, Le Song 最近关于最小超球面能量MHE的研究已经证明了它在规范神经网络和改进它们的推广方面的潜力。 MHE的灵感来自物理学中的汤姆逊问题,其中单个球体上的多个推进电子的分布可以通过最小化一些势能来建模。尽管具有实际效果,但MHE受到局部最小值的影响,因为它们的数量在高维度上急剧增加,从而限制了MHE释放其在改善网络泛化方面的全部潜力。为了解决这个问题,我们提出压缩最小超球面能CoMHE作为神经网络的替代正则化。具体而言,CoMHE利用投影映射来降低神经元的维数并最小化它们的超球面能量。根据投影矩阵的不同结构,我们提出了随机投影CoMHE和角度保持CoMHE两个主要变量。此外,我们提供理论见解来证明其有效性。我们表明,CoMHE在综合实验中始终优于MHE,并展示了其在各种任务中的多样化应用,如图像识别和点云识别。 |
| Visual Relationships as Functions: Enabling Few-Shot Scene Graph Prediction Authors Apoorva Dornadula, Austin Narcomey, Ranjay Krishna, Michael Bernstein, Li Fei Fei 在视觉场景中对对象组和谓词进行分类的场景图预测需要大量的训练数据。然而,长尾关系的分布可能是这种方法的障碍,因为它们只能在带有足够标签的一小组谓词上进行训练。我们引入了第一个场景图预测模型,它支持很少的谓词镜头学习,使场景图方法能够推广到一组新的谓词。首先,我们引入一个新的谓词模型作为对象特征或图像位置进行操作的函数。接下来,我们定义一个场景图模型,其中这些函数在新的图卷积框架中被训练为消息传递协议。我们使用频繁出现的谓词训练框架,并表明我们的方法优于那些在召回50时使用相同数量的监督1.78并且与其他场景图模型相同的方法。接下来,我们提取由训练的谓词函数生成的对象表示,以在罕见的谓词上训练几个镜头谓词分类器,其中只有1个标记示例。与强大的基线相比,例如从现有技术表现形式的转移学习,我们通过4.16回忆1显示改进的5镜头表现。最后,我们展示我们的谓词函数生成可解释的可视化,启用第一个可解释的场景图模型。 |
| Task-Aware Deep Sampling for Feature Generation Authors Xin Wang, Fisher Yu, Trevor Darrell, Joseph E. Gonzalez 基于过去的经验,人类想象新颖物体的各种外观的能力对于基于少数例子快速学习新颖的视觉概念是至关重要的。赋予具有类似能力的机器可以为新的视觉概念生成特征分布,这是对高效模型概括进行抽样的关键。在这项工作中,我们提出了一种适用于零点设置中的特征生成的新型发生器架构。我们引入任务感知深度采样TDS,其在发生器中逐层注入任务感知噪声,与现有浅采样SS方案相反,其中随机噪声仅在发生器的输入层处被采样一次。我们提出了一种样本有效学习模型,其由TDS生成器,鉴别器和分类器(例如,软最大分类器)组成。我们发现我们的模型在组合零射击学习基准上实现了最先进的结果,并且以更快的收敛速度改进了传统零射击学习中的既定基准。 |
| Edge-Direct Visual Odometry Authors Kevin Christensen, Martial Hebert 在本文中,我们提出了一种边缘直接视觉测距算法,该算法有效地利用边缘像素来找到最小化图像之间光度误差的相对姿势。利用边缘像素的先前工作将边缘视为特征,并采用各种技术来匹配边缘线或像素,这增加了不必要的复杂性。直接方法通常对所有像素强度进行操作,这被证明是高度冗余的。相比之下,我们的方法建立在直接视觉测距方法的基础之上,自然而它不仅比直接密集方法更有效,因为我们使用一小部分像素进行迭代,但也更准确。我们通过仅从一个图像中提取边缘来实现高精度和高效率,并且利用鲁棒的高斯牛顿来最小化这些边缘像素的光度误差。这同时找到参考图像中的边缘像素,以及最小化光度误差的相对相机姿势。我们测试各种边缘检测器,包括学习边缘,并确定该方法的最佳边缘检测器是使用自动阈值处理的Canny边缘检测算法。我们强调了边缘直接方法和直接密集方法之间的关键差异,特别是更高级别的图像金字塔如何导致显着的混叠效应并导致不正确的解决方案收敛。我们通过实验证明,减少边缘像素的光度误差也会降低所有像素的光度误差,我们通过消融研究显示通过优化边缘像素获得的精度提高。我们在RGB D TUM基准测试中评估我们的方法,在此基础上我们实现了最先进的性能。 |
| Weakly-supervised Compositional FeatureAggregation for Few-shot Recognition Authors Ping Hu, Ximeng Sun, Kate Saenko, Stan Sclaroff 从一些例子中学习是机器学习的一项具有挑战性的任务。虽然最近已经对这个问题取得了进展,但是大多数现有方法忽略了视觉概念表示中的组合性,例如对象是由部分构建的或由语义属性组成,这是人类从少量示例中轻松学习的能力的关键。为了增强具有组合性的少数镜头学习模型,在本文中,我们提出了简单而强大的组合特征聚合CFA模块作为深度网络的弱监督正则化。给定从输入中提取的深度特征图,我们的CFA模块首先将特征空间解开为不相交的语义子空间,这些子空间模拟不同的属性,然后双线性地聚合每个子空间内的局部特征。 CFA明确地使用语义和空间组合来规范表示,以产生用于少数镜头识别任务的辨别表示。此外,我们的方法在训练过程中不需要对属性和对象部分进行任何监督,因此可以方便地插入到现有模型中进行端到端优化,同时保持模型大小和计算成本几乎相同。对少数镜头图像分类和动作识别任务的广泛实验表明,我们的方法相对于最近的现有技术方法提供了实质性的改进。 |
| Suppressing Model Overfitting for Image Super-Resolution Networks Authors Ruicheng Feng, Jinjin Gu, Yu Qiao, Chao Dong 大型深度网络在单图像超分辨率SISR中表现出竞争性,涉及大量数据。然而,在现实世界场景中,由于可访问的训练对有限,大型模型表现出不合适的行为,例如过度拟合和记忆。为了抑制模型过度拟合并进一步享受大模型容量的优点,我们彻底研究了提供额外训练数据对的通用方法。特别是,我们引入了一个简单的学习原理MixUp来训练网络对样本对的插值,这鼓励网络支持训练样本之间的线性行为。此外,我们提出了一种具有学习退化的数据合成方法,使模型能够使用具有更高内容多样性的超高质量图像。该策略证明可以成功地减少数据偏差。通过将这些组件MixUp和合成训练数据相结合,可以在非常有限的数据样本下训练大型模型而不会过度拟合,并获得令人满意的泛化性能。我们的方法在NTIRE2019 Real SR Challenge中获得第二名。 |
| Differential Imaging Forensics Authors Aur lien Bourquard, Jeff Yan 我们介绍了一些基于差分成像的新取证,其中通过光与场景的微妙相互作用(例如暗淡反射)创建的一类新的视觉证据可以通过比较分析从附加图像中进行计算提取和放大。在类似条件下获得的参考基线图像。这种差异成像取证DIF的范例使得法医检查员第一次能够检索在图像或视频镜头中容易获得的所述视觉证据,但是否则对于人类观察者来说仍然是微弱的甚至是不可见的。我们通过实践实验证明了我们方法的相关性和有效性。我们还展示了DIF提供了一种检测伪造图像和视频剪辑的新方法,包括深度伪造。 |
| Continual and Multi-Task Architecture Search Authors Ramakanth Pasunuru, Mohit Bansal 架构搜索是自动学习最适合给定任务的神经模型或细胞结构的过程。最近,该方法使用称为Efficient Neural Architecture Search ENAS的权重共享策略,在合理的训练速度下,在语言建模和图像分类方面表现出了有希望的性能改进。在我们的工作中,我们首先介绍一种新颖的连续架构搜索CAS方法,以便在几个任务的顺序训练期间不断演化模型参数,而不会通过块稀疏性和正交性约束损失先前学习的任务的性能,从而实现终身学习。接下来,我们探索一种基于ENAS的多任务架构搜索MAS方法,用于找到通过联合控制器奖励在多个任务中表现良好的统一单细胞结构,因此允许更广泛地将细胞结构知识转移到看不见的新任务。我们凭经验证明了我们的顺序连续学习和基于并行多任务学习的架构搜索方法对不同句子对分类任务GLUE和基于多模式生成的视频字幕任务的有效性。此外,我们提出了几个关于学习细胞结构的消融和分析。 |
| Manifold Graph with Learned Prototypes for Semi-Supervised Image Classification Authors Chia Wen Kuo, Chih Yao Ma, Jia Bin Huang, Zsolt Kira 半监督学习方法的最新进展依赖于使用在标记数据伪标记上训练的模型估计未标记数据的类别,并使用未标记数据用于各种基于一致性的正则化。在这项工作中,我们建议另外明确地利用数据流形的结构,该结构基于在特征空间内的图像实例上构建的流形图。具体而言,我们提出了一种基于图形网络的体系结构,它以端到端的方式联合优化特征提取,图形连接以及特征传播和聚合到未标记数据。此外,我们提出了一种新颖的原型生成器,用于生成各种原型,紧凑地代表每个类别,支持特征传播。为了评估我们的方法,我们首先提供了一个强大的基线,它结合了两个基于一致性的正则化器,这些正则化器已经实现了最先进的结果,特别是标签更少然后,我们表明,当与这些损失相结合时,所提出的方法有助于将信息从生成的原型传播到图像数据,以进一步改善结果。我们在半监督基准测试中提供了广泛的定性和定量实验结果,证明了我们的设计所带来的改进,并表明我们的方法与使用单一模型和与集合方法相当的现有方法相比,实现了最先进的性能。具体来说,我们在SVHN上的错误率为3.35,在CIFAR 10上为8.27,在CIFAR 100上的错误率为33.97。由于标签少得多,我们的显着优势超过了现有技术水平,平均有39个相对误差减少。 |
| Stereoscopic Omnidirectional Image Quality Assessment Based on Predictive Coding Theory Authors Zhibo Chen, Jiahua Xu, Chaoyi Lin, Wei Zhou 立体全方位图像的客观质量评估是一个具有挑战性的问题,因为它受到多个方面的影响,如投影变形,视野FoV范围,双目视觉,视觉舒适度等。现有研究表明经典的2D或3D图像质量评估IQA指标不能很好地表现立体全方位图像。然而,很少有研究工作集中在评估全方位图像的感知视觉质量,特别是对于立体全方位图像。在本文中,基于人类视觉系统HVS的预测编码理论,我们提出了一种立体全方位图像质量评估器SOIQE,以应对3D 360度图像的特征。基于SOIQE预测编码理论的双目竞争模块和多视图融合模块涉及两个模块。在双目竞争模块中,我们引入预测编码理论来模拟高层次模式之间的竞争,并计算相似性和竞争优势,以获得视口图像的质量分数。此外,我们开发了多视图融合模块,借助于内容权重和位置权重来聚合视口图像的质量分数。建议的SOIQE是一个参数模型,没有必要的回归学习,这确保了它的可解释性和泛化性能。我们发布的立体全方位图像质量评估数据库SOLID的实验结果表明,我们提出的SOIQE方法优于现有技术指标。此外,我们还验证了每个提议的模块在公共立体图像数据集和全景图像数据集上的有效性。 |
| eSLAM: An Energy-Efficient Accelerator for Real-Time ORB-SLAM on FPGA Platform Authors Runze Liu, Jianlei Yang, Yiran Chen, Weisheng Zhao 同时本地化和映射SLAM是自主导航的关键任务。然而,由于SLAM算法的计算复杂性,很难在低功耗平台上实现实时实现。我们提出了一种节能架构,用于实时ORB定向FAST和基于旋转简介的可视SLAM系统,加速最耗时在FPGA平台上进行特征提取和匹配的阶段。此外,原始ORB描述符模式被改造为旋转对称方式,更加硬件友好。进一步利用包括重新调度和并行化的优化来提高吞吐量并减少存储器占用。与TUM数据集上的Intel i7和ARM Cortex A9 CPU相比,我们的FPGA实现分别实现了高达3倍和31倍的帧速率提升,以及高达71倍和25倍的能效提升。 |
| Non-Parametric Calibration for Classification Authors Jonathan Wenger, Hedvig Kjellstr m, Rudolph Triebel 分类方法的许多应用不仅需要高精度,而且还需要对预测不确定性的可靠估计。然而,虽然许多当前的分类框架,特别是深度神经网络架构,在准确性方面提供了非常好的结果,但是它们倾向于低估它们的预测不确定性。在本文中,我们提出了一种方法,它可以校正一般分类器的置信度输出,使其接近正确分类的真实概率。与现有方法相比,该分类器校准基于使用潜在高斯过程的非参数表示并且专门设计用于多类分类。它可以应用于输出置信度估计的任何分类方法,并且不限于神经网络。我们还提供了关于分类器的过度和不足以及其与校准的关系的理论分析。在实验中,我们展示了我们的方法在不同的分类器和基准数据集中的普遍强大的性能,与现有的分类器校准技术相比。 |
| Adaptive Navigation Scheme for Optimal Deep-Sea Localization Using Multimodal Perception Cues Authors Arturo Gomez Chavez, Qingwen Xu, Christian A. Mueller, S ren Schwertfeger, Andreas Birk 水下机器人干预需要高水平的安全性和可靠性。要解决的一个主要挑战是强大而准确地获取本地化估算,因为这是实现更复杂任务的先决条件,例如:浮动操纵和映射。商业运营中的现有技术导航,例如石油天然气生产OGP,依赖于昂贵的仪器。这些可以通过视觉导航方法部分地替换或辅助,尤其是在设备部署具有高成本和风险的深海场景中。我们的工作提出了一种多模式方法,它适应陆地机器人技术的最新方法,即密集点云生成与平面表示和配准相结合,以提高水下定位性能。提出了一种两阶段导航方案,其初始生成工作空间的粗略概率图,其用于从第二阶段中的计算点云和平面过滤噪声。此外,引入了自适应决策方法,其确定将哪些感知提示结合到定位滤波器中以优化准确性和计算性能。我们首先在模拟中研究我们的方法,然后使用OGP监测和维护方案中的现场试验数据进行验证。 |
| Using Small Proxy Datasets to Accelerate Hyperparameter Search Authors Sam Shleifer, Eric Prokop 机器学习工作流程中最大的瓶颈之一是等待模型训练。根据可用的计算资源,可能需要数天到数周才能在具有许多类(如ImageNet)的大型数据集上训练神经网络。对于试验新算法方法的研究人员来说,这是不切实际的耗时且成本高昂的。我们的目标是生成较小的代理数据集,其中实验运行成本更低,但结果与完整数据集上的实验结果高度相关。我们使用从示例或类中随机抽样来生成这些代理数据集,仅对最简单或最难的示例进行培训,并对数据蒸馏生成的合成示例进行培训。我们将这些技术与更广泛使用的完整数据集训练基线进行比较,以获得更少的时期。对于每个代理策略,我们估计代理质量的三个度量可以通过代理数据集上的实验结果来解释实验结果在完整数据集上的多少方差。 |
| Joint 3D Localization and Classification of Space Debris using a Multispectral Rotating Point Spread Function Authors Chao Wang, Grey Ballard, Robert Plemmons, Sudhakar Prasad 我们使用多光谱旋转点扩散函数RPSF考虑了未解决的空间碎片的联合三维3D定位和材料分类的问题。 RPSF的使用允许人们从由单个2D传感器阵列获取的旋转图像估计点源的3D位置,因为每个源图像关于其x,y位置的旋转量取决于其轴向距离z。使用多光谱图像,每个光谱带有一个RPSF,我们不仅可以定位空间碎片的3D位置,还可以对其材料成分进行分类。我们提出了一种实现联合定位和分类的三阶段方法。在阶段1中,我们采用用于定位的优化方案,其中假设每种材料的光谱特征是均匀的,这显着提高了效率并且产生比单个光谱带更好的定位结果。在阶段2中,我们通过交替方法估计光谱特征并细化定位结果。我们在最后阶段处理分类。考虑了泊松噪声和高斯噪声模型,并讨论了各自的实现。使用来自NASA的多光谱数据的数值测试显示了我们的三阶段方法的效率,并说明了在单个频带上使用多个频带的点源定位和光谱分类的改进。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com