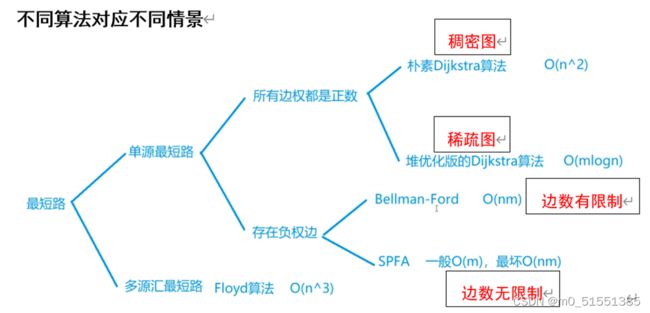
各种最短路问题的常用算法模板
1、所有最短路算法
2、最短路问题的关键
实际做题时的关键是如何定义点和边,使问题变成最短路问题。
3、边权都>0的最短路
3.1 朴素版dijkstra算法
不能有负权边。
#include3.2 堆优化版dijkstra算法
就是用优先队列优化了 “寻找当前未确定最短距离的点中到源点距离最短” 的过程,原来寻找是遍历n个点,用O(n)的时间。现在只需O(1)的时间即可找到。
#include4、有负权边的最短路
如果有负权回路,最短路不一定存在。
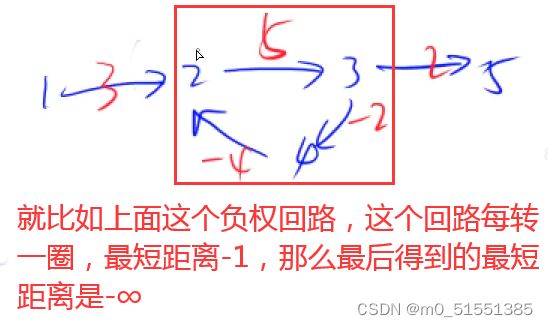
转无穷多圈
4.1 对边的数量有限制:Bellman-Ford算法
Bellman-ford算法可以检测负环,但是一般不用它检测。
#include思考:
拷贝dist数组的目的是 保证每次更新所有边的最短路时,都是用上一次 只扩展了一条边得到的dist,防止在遍历所有边时发生串联更新。
注意:
更新dist的时候使用的下标是哪个?使用的数组又是哪个??这两块在写代码的时候很容易错。
4.2 对变数无限制 PSFA算法
本算法非常的常用,正权图也能用。
只要没有负环,就能用该算法。
#include思考:
为什么bellmam-ford算法最后判断时写成 if(dist[n] > 0x3f3f3f3f / 2) 而spfa算法写成 if(dist[n] == 0x3f3f3f3f) ??
答:
对于bellman-ford算法: dist[n] = 0x3f3f3f3f 表示起点到中间没有通路,但可能有其他的点和终点是连着的。而bellman-ford算法会遍历图中的所有边,所以,如果终点有边连着(但起点到不了终点),终点的dist[n]会被更新为0x3f3f3f3f + 边权,这个值会比0x3f3f3f3f小一点点,所以判断的时候不能判断 == 。
对于spfa算法:spfa只会遍历由起点能更新到的点,起点到不了的点根本不会更新,所以,如果起点到不了重点的话,终点的dist根本不会更新,所以直接判断 == 即可。
注意:
spfa是bellman-ford算法的优化,后者傻傻的遍历图中的所有边,而spfa只会遍历可由起点更新到的点。
4.3 用 spfa 算法判断图中 是否有负环
#include思考①:
1、为什么不需要初始化dist数组为+∞?这样不会对后面更新dist产生影响吗??
2、为什么开始时所有点都要入队?
答:
这两个问题可以一起理解。我们在原图的基础上加入一个虚拟源点,单向指向所有节点且到所有点距离为0。开始时,初始化dist为+∞,并将虚拟源点加入队列中,然后进行spfa算法的第一次迭代。由于虚拟源点到每个点都有边,所以所有点的dist都会更新为0,并将所有点插入队列中,此时就等价于上面的spfa算法了。
开始将所有点入队的根本原因是 处理不连通的情况。即,负环和起点是不连着的,所以只通过起点根本无法遍历到负环,所以要将所有点入队。无向连通图不需要建虚拟源点了,有向图除非强连通,否则不能保证从1号点能到达其他所有点, 也应建立虚拟源点。
如果只是求源点可以到达的负环的话,只将源点入队即可。
从另外一个角度理解不初始化dist数组。如果图中存在负环,则dist一定会更新无穷次,所以不初始化dist也没关系。这样看来,不管dist数组的初值是多少,都是可以的。因为只要有负环存在,就必然有某些点的距离是负无穷,所以不管距离被初始化成何值,都一定严格大于负无穷,所以一定会被无限更新。
思考②:
dist全初始化为0后,只有负权边才会使dist变小,所以cnt从第一次出现负权边时开始统计,他统计了该负权边延伸的最大长度,当负环第一次出现时,cnt等于负环上的节点数,该节点数小于等于n,之后cnt会一直增加到-∞,但我们的代码不会让他增长到-∞,此处只需给出最小的判环结束条件即可,无负环最极限的条件是存在 cnt == n - 1 ,即cnt >= n时一定存在负环。
5、多源汇最短路———Floyd算法
可以处理有负权边的图,但是不能有负权回路
#include