马氏距离(Mahalanobis Distance)
目录
1 简单理解协方差的物理意义
2 什么是马氏距离
3 马氏距离实际意义
4 马氏距离的推导
4.1 马氏距离的步骤
4.2 马氏距离的推导过程
5 马氏距离的问题
6 马氏距离的优点
7 欧氏距离和马氏距离之间的区别和联系
马氏距离(Mahalanobis Distance)是度量学习中一种常用的距离指标,同欧氏距离、曼哈顿距离、汉明距离等一样被用作评定数据之间的相似度指标。但却可以应对高维线性分布的数据中各维度间非独立同分布的问题。
1 简单理解协方差的物理意义
(1)正相关
在概率论中,两个随机变量 X 与 Y 之间相互关系,大致有下列3种情况:
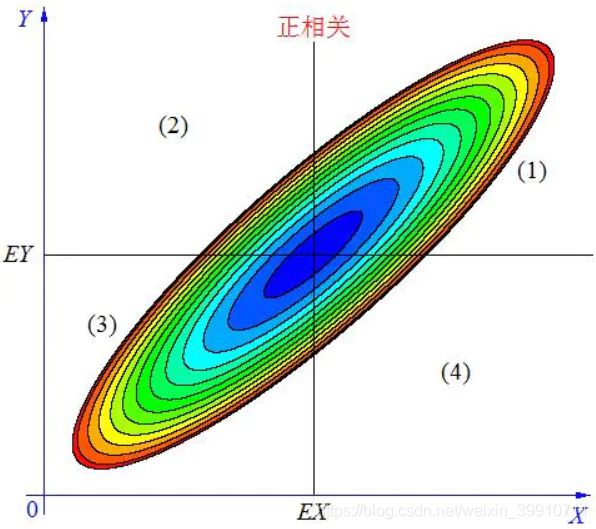
当 X, Y 的联合分布像上图那样时,我们可以看出,大致上有: X 越大 Y 也越大, X 越小 Y 也越小,这种情况,我们称为“正相关”。
(2)负相关
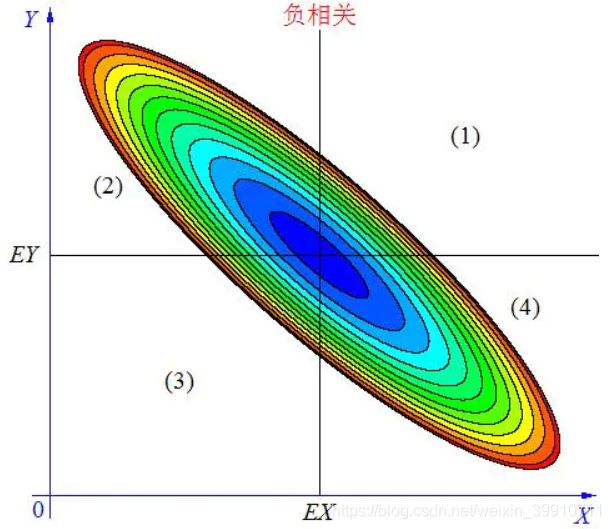
当X, Y 的联合分布像上图那样时,我们可以看出,大致上有:X 越大 Y 反而越小,X 越小 Y 反而越大,这种情况,我们称为“负相关”。
(3)不相关
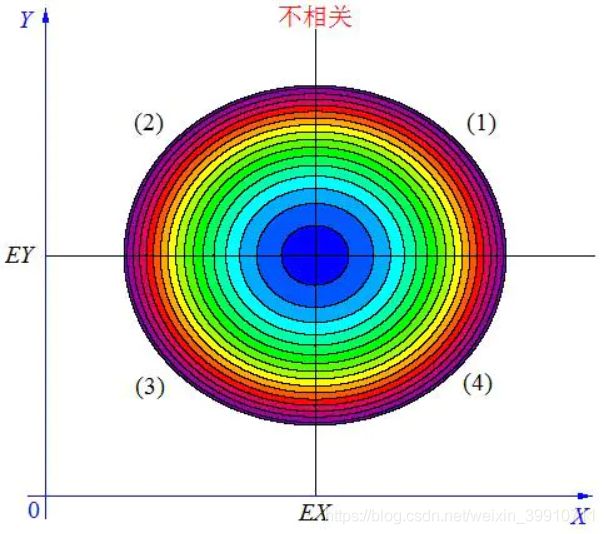
当X, Y 的联合分布像上图那样时,我们可以看出:既不是 X 越大 Y 也越大,也不是 X 越大 Y 反而越小,这种情况我们称为“不相关”。
怎样将这3种相关情况,用一个简单的数字表达出来呢?
- 在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
- 在图中的区域(2)中,有 X
0 ,所以(X-EX)(Y-EY)<0; - 在图中的区域(3)中,有 X
0; - 在图中的区域(4)中,有 X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
当X 与Y 正相关时,它们的分布大部分在区域(1)和(3)中,小部分在区域(2)和(4)中,所以平均来说,有E(X-EX)(Y-EY)>0 。
当 X与 Y负相关时,它们的分布大部分在区域(2)和(4)中,小部分在区域(1)和(3)中,所以平均来说,有E(X-EX)(Y-EY)<0。
当 X与 Y不相关时,它们在区域(1)和(3)中的分布,与在区域(2)和(4)中的分布几乎一样多,所以平均来说,有E(X-EX)(Y-EY)=0。
所以,我们可以定义一个表示X, Y 相互关系的数字特征,也就是协方差
cov(X, Y) = E(X-EX)(Y-EY)。
- 当 cov(X, Y)>0时,表明X与Y 正相关;
- 当 cov(X, Y)<0时,表明X与Y负相关;
- 当 cov(X, Y)=0时,表明X与Y不相关。
这就是协方差的意义。
在介绍马氏距离之前,我们先来看如下几个概念:
-
方差:方差是标准差的平方,而标准差的意义是数据集中各个点到均值点距离的平均值。反应的是数据的离散程度。
-
协方差: 标准差与方差是描述一维数据的,当存在多维数据时,我们通常需要知道每个维数的变量中间是否存在关联。协方差就是衡量多维数据集中,变量之间相关性的统计量。比如说,一个人的身高与他的体重的关系,这就需要用协方差来衡量。如果两个变量之间的协方差为正值,则这两个变量之间存在正相关,若为负值,则为负相关。
-
协方差矩阵: 当变量多了,超过两个变量了。那么,就用协方差矩阵来衡量这么多变量之间的相关性。假设 X 是以 n 个随机变数(其中的每个随机变数是也是一个向量,当然是一个行向量)组成的列向量:
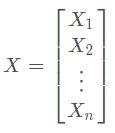
其中,![]() 是第i个元素的期望值,即
是第i个元素的期望值,即![]() 。协方差矩阵的第 i, j 项(第 i, j 项是一个协方差)被定义为如下形式:
。协方差矩阵的第 i, j 项(第 i, j 项是一个协方差)被定义为如下形式:

即:
矩阵中的第 ( i , j ) 个元素是 ![]() 与
与 ![]() 的协方差。
的协方差。
2 什么是马氏距离
马氏距离(Mahalanobis Distance)是由马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。马氏距离(Mahalanobis Distance)是一种距离的度量,可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。
对于一个均值为![]() ,协方差矩阵为Σ的多变量矢量
,协方差矩阵为Σ的多变量矢量![]() ,其马氏距离(单个数据点的马氏距离)为:
,其马氏距离(单个数据点的马氏距离)为:
![]()
马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为Σ的随机变量X与Y的差异程度,数据点x, y之间的马氏距离:
![]()
其中Σ是多维随机变量的协方差矩阵,μ为样本均值,如果协方差矩阵是单位向量,也就是各维度独立同分布,马氏距离就变成了欧氏距离。如果协方差矩阵为对角阵,其也可称为正规化的马氏距离。
其中σi是xi的标准差。
3 马氏距离实际意义
那么马氏距离就能能干什么?它比欧氏距离好在哪里?
欧式距离近就一定相似?
先举个比较常用的例子,身高和体重,这两个变量拥有不同的单位标准,也就是有不同的scale。比如身高用毫米计算,而体重用千克计算,显然差10mm的身高与差10kg的体重是完全不同的。但在普通的欧氏距离中,这将会算作相同的差距。
归一化后欧氏距离近就一定相似?
当然我们可以先做归一化来消除这种维度间scale不同的问题,但是样本分布也会影响分类。
举个一维的栗子,现在有两个类别,统一单位,第一个类别均值为0,方差为0.1,第二个类别均值为5,方差为5。那么一个值为2的点属于第一类的概率大还是第二类的概率大?距离上说应该是第一类,但是直觉上显然是第二类,因为第一类不太可能到达2这个位置。
所以,在一个方差较小的维度下很小的差别就有可能成为离群点。就像下图一样,A与B相对于原点的距离是相同的。但是由于样本总体沿着横轴分布,所以B点更有可能是这个样本中的点,而A则更有可能是离群点。
算上维度的方差就够了?
还有一个问题——如果维度间不独立同分布,样本点一定与欧氏距离近的样本点同类的概率更大吗?
可以看到样本基本服从f(x) = x的线性分布,A与B相对于原点的距离依旧相等,显然A更像是一个离群点
即使数据已经经过了标准化,也不会改变A B与原点间距离大小的相互关系。所以要本质上解决这个问题,就要针对主成分分析中的主成分来进行标准化。
4 马氏距离的推导
4.1 马氏距离的步骤
计算样本数据的马氏距离分为两个步骤:
1、坐标旋转
2、数据压缩
- 坐标旋转的目标:使旋转后的各个维度之间线性无关,所以该旋转过程就是主成分分析的过程。
- 数据压缩的目标:将不同的维度上的数据压缩成为方差都是1的的数据集。
首先我们先看个二维的例子。
此例的数据重心为原点,P1,P2到原点的欧氏距离相同,但点P2在y轴上相对原点有较大的变异,而点P1在x轴上相对原点有较小的变异。所以P1点距原点的直观距离是比P2点的小的。
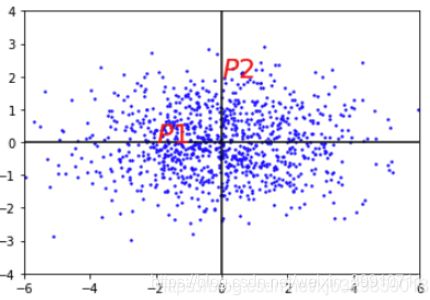
马氏距离就是解决这个问题,它将直观距离和欧式距离统一。为了做到这一点, 它先将数据不同维度上的方差统一(即各维度上的方差相同),此时的欧式距离就是直观距离。
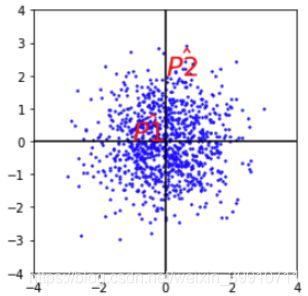
如图:统一方差后的图,P1’到原点的距离小于P2’。P1’到原点的欧式距离和P2’的相同。以上所说的直观距离就是马氏距离 。但是,如果不同维度之间具有相关性,则压缩的效果就不好了。如下图只在横向和纵向上压缩,则达不到上图的压缩效果。

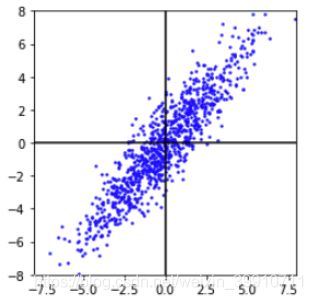
所以在F1方向和F2方向上压缩数据才能达到较好的效果。所以需要将原始数据在XY坐标系中的坐标 表示在F坐标系中。然后再分别沿着坐标轴压缩数据。
4.2 马氏距离的推导过程
有一个原始的多维样本数据Xn×m(m列,n行):
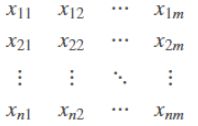
其中每一行表示一个测试样本(共n个);Xi表示样本的第i个维度(共m个) ![]() ,以上多维样本数据记为X=(X1,X2⋯Xm)。样本的总体均值为
,以上多维样本数据记为X=(X1,X2⋯Xm)。样本的总体均值为 ![]() 。其协方差为:
。其协方差为:
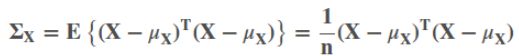
协方差矩阵表示样本数据各维度之间的关系的。其中n是样本的数量
假设将原始数据集 X, 通过坐标旋转矩阵 U 旋转到新的坐标系统中,得到一个新的数据集F。(其实X和F表示的是同一组样本数据集,只是由于其坐标值不同,为了易于区分用了两个字母表示)
![]()
新数据集F的均值记为μF = μF1, μF2⋯ μFm , μF = Uμx
由于将数据集旋转后数据的不同维度之间是相互独立的,所以新数据集F的协方差矩阵![]() 应该为对角阵(除对角线元素外,其余元素均为0)。
应该为对角阵(除对角线元素外,其余元素均为0)。
由于:

所以:
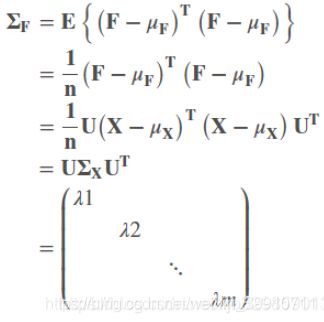
其中sqrt(λi)就是第 i 个维度的方差。
由于Σx是实对角阵,所以U是一个正交矩阵 ![]() 。
。
以上是准备知识,下面推导一个样本点x=(x1,x2⋯xm)到重心μX=(μX1,μX2⋯μXm)的马氏距离。等价于求点 f=(f1,f2⋯fm) 压缩后的坐标值到数据重心压缩后的坐标值 μF=(μF1,μF2⋯μFm)的欧式距离。
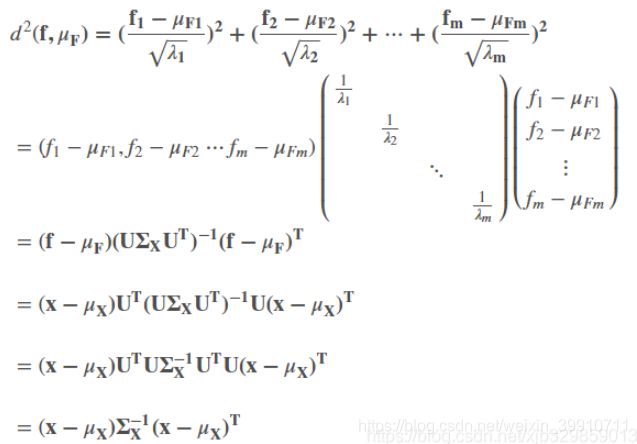
这就是马氏距离的的计算公式了。
如果x是列向量
d2 = ( x − μx )T Σ-1X ( x − μx )
如果并把上文的重心 μx = ( μx1, μx2⋯ μxm) 改为任意一个样本点y,则可以得到x和y两个样本点之间的马氏距离公式为:
d2 = ( x − y )TΣ-1x ( x − y )
5 马氏距离的问题
-
协方差矩阵必须满秩
里面有求逆矩阵的过程,不满秩不行,要求数据要有原维度个特征值,如果没有可以考虑先进行PCA,这种情况下PCA不会损失信息。
-
不能处理非线性流形(manifold)上的问题
只对线性空间有效,如果要处理流形,只能在局部定义,可以用来建立KNN图。
6 马氏距离的优点

7 欧氏距离和马氏距离之间的区别和联系




参考资料:
马氏距离ppt: 马氏距离 - 百度文库
度量学习中的马氏距离:度量学习中的马氏距离 - 简书
马氏距离(Mahalanobis Distence):马氏距离(Mahalanobis Distence) [python] - CoyoteWaltz - 博客园
马氏距离和欧式距离详解:马氏距离和欧式距离详解_From Zero to Hero-CSDN博客_欧式距离
马氏距离——直观理解与公式推导:马氏距离——直观理解与公式推导 - 知乎
马氏距离详解:马氏距离详解_xjb329859013的博客-CSDN博客_马氏距离公式
马氏距离(Mahalanobis Distance):马氏距离(Mahalanobis Distance) | Ph0en1x Notebook