一文开启监督学习之旅
1. 监督学习简介
近年来,机器学习已经成为最热门的研究领域之一,机器学习通常可以分为监督学习和无监督学习。本文主要介绍监督学习,可以在博文《无监督学习》中详细了解主流无监督学习算法。
在给出正式的定义之前,我们考虑以下示例:假设存在一组人物图片,每张图片都有一个关于图中人物性别的标签,我们就可以将这些数据输入监督算法中,并使用输入变量(图片像素)来计算目标变量(图片中人物性别),更正式地说:
监督学习是指基于标记的训练数据构建机器学习模型的过程。在监督学习中,每个数据样本都是由输入变量和所需目标变量组成的元组。例如,机器学习中常用的 Iris 数据集,该数据集包含描述鸢尾花卉的特征,其包含以下特征:
- Sepal Length (花萼长度)
- Sepal Width (花萼宽度)
- Petal Length (花瓣长度)
- Petal Width (花瓣宽度)
监督学习的目标是预测鸢尾花卉属于 (Setosa, Versicolour, Virginica) 三个种类中的哪一类。
本节我们将介绍主流监督学习算法——对数据进行分类和回归。当然,监督学习还包含更多应用,例如目标检测、图像分割等,但是,这些应用都是分类和回归算法的高级变体应用,不在本文的介绍范围内。
2. 分类算法
2.1 分类算法基本概念
分类过程是一种用于将数据归为固定数量的类别的技术,在机器学习中,分类用于识别新数据点所属的类别。基于包含数据样本和相应标签的训练数据集构建分类模型。例如,假设我们要确定给定图像中包含的动物是猫还是狗,我们将构建一个训练数据集,其中包含两个类别:猫和狗。然后我们将根据可用的训练样本训练模型(训练阶段),然后将训练后的模型用于推测模型未见过的图片属于猫或狗(测试或推理阶段)。
一个性能优秀的分类系统可以很容易地检索数据,分类广泛用于人脸识别、垃圾邮件识别、推荐系统等。一个好的数据分类算法会自动生成正确的标准,将给定的数据分成给定数量的类别。为了获取优异的分类结果,通常需要足够多的样本用于训练分类模型,以便它可以学习到正确的分类标准。如果样本数量不足,算法将对训练数据过拟合,这意味着它将在未知数据上表现不佳,这是机器学习领域普遍存在的问题。
2.2 数据预处理
我们可以将原始数据视为机器学习算法的原料,但就像我们不能将原料直接放入机器中而必须使用电力一样,机器学习算法通常需要数据在训练开始之前进行预处理,为了准备数据以供机器学习算法学习,必须对数据进行预处理并转换为正确的格式。我们,首先介绍机器学习中常用的数据预处理方法。
为了介绍数据预处理相关技术,我们首先构造一些示例数据:
import numpy as np
from sklearn import preprocessing
input_data = np.array([[1.2, 2.5, 5.4, -8.1, 0.1],
[-5.2, 5.9, 5.4, 0.2, 4.5],
[4.5, 3.5, 4.2, 8.0, 6.4],
[-1.1, -1.5, -2.4, -6.6, -3.5],
[2.1, 6.3, 5.6, -1.1, -7.5]])
接下来,我们将要介绍经典的数据预处理技术,包括:二值化,均值移除,数据缩放,数据归一化等。
2.2.1 二值化
二值化 (Binarization) 用于将数值转换为布尔值,使用 Scikit-learn 内置方法 Binarizer 可以完成数据的二值化。接下来,我们以 4.5 作为阈值对输入数据进行二值化:
data_binarized = preprocessing.Binarizer(threshold=4.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)
运行代码,可以得到以下输出:
Binarized data:
[[0. 0. 1. 0. 0.]
[0. 1. 1. 0. 0.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 0. 0.]
[0. 1. 1. 0. 0.]]
可以看到的,所有高于 4.5 的值都变为 1,而其余的值则变为 0。
2.2.2 均值移除
均值移除 (mean removal) 是机器学习中常用的预处理技术,其通过在特征向量中减去平均值来得到新的特征向量,这样每个特征都以零为中心,从而消除了特征向量中特征的偏差。我们首先打印输入数据的平均值和标准差:
# 计算输入数据的平均值和标准差
print("\nMean Removal Before:")
print("Mean =", input_data.mean(axis=0))
print("Std deviation =", input_data.std(axis=0))
接下来,我们对输入数据执行均值移除:
data_scaled = preprocessing.scale(input_data)
print("\nMean Removal After:")
print("Mean =", data_scaled.mean(axis=0))
print("Std deviation =", data_scaled.std(axis=0))
运行以上代码,可以得到以下输出结果:
Mean Removal Before:
Mean = [ 0.3 3.34 3.64 -1.52 0. ]
Std deviation = [3.28329103 2.80969749 3.06045748 5.70732862 5.0935253 ]
Mean Removal After:
Mean = [-2.22044605e-17 8.88178420e-17 1.99840144e-16 -4.16333634e-17
0.00000000e+00]
Std deviation = [1. 1. 1. 1. 1.]
可以看出,预处理后的特征向量平均值非常接近 0,而标准差为 1。
2.2.3 数据缩放
假设我们正在使用具有与房屋价格相关特征的数据集,目标是预测这些房屋的价格,但这些特征的数值范围差别较大。例如,房屋的面积通常为在数百之上,而房间的数量通常仅数个。因此我们需要对这些特征进行处理,以赋予每个特征的大致相同的权重大致,使得离群值不会对结果产生较大干扰。其中一种方法是重新调整所有特征,使它们落在一个较小的范围内,例如 0 到 1 之间。MinMaxScaler 算法是实现这一目标的最有效方法,算法的公式如下:
n e w ( x i ) = x i − m a x ( x ) m a x ( x ) − m i n ( x ) new(x_i)=\frac {x_i - max(x)} {max(x)-min(x)} new(xi)=max(x)−min(x)xi−max(x)
其中 m a x ( x ) max(x) max(x) 是变量的最大值, m i n ( x ) min(x) min(x) 是最小值, x i x_i xi 表示 x x x 中的第 i i i 个元素。
在特征向量中,每个特征的值可以在很大范围的随机值之间变化。因此,对这些特征进行缩放,以便为机器学习算法的对训练数据集进行同等重要程度的考量十分重要。任何特征都不应该仅仅因为测量上单位属性的不同而有所区别。使用 Scikit-learn 实现数据缩放,如下所示:
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0, 1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print("\nMin max scaled data:\n", data_scaled_minmax)
运行以上代码,得到输出结果如下所示:
Min max scaled data:
[[0.65979381 0.51282051 0.975 0. 0.54676259]
[0. 0.94871795 0.975 0.51552795 0.86330935]
[1. 0.64102564 0.825 1. 1. ]
[0.42268041 0. 0. 0.0931677 0.28776978]
[0.75257732 1. 1. 0.43478261 0. ]]
可以看到,每一列数据都被缩放,以便每列的最大值为 1,每列数据表示数据样本的一类特征,以上输入数据中,每个数据样本包含 5 列,即每个数据样本含有 5 个特征。
2.2.4 数据归一化
归一化 (normalization) 是另一类常用数据预处理技术,它与数据缩放非常相似,它们都会对数据进行变换,但在数据缩放中,会更改变量的值范围,而在归一化中,会更改数据分布的形状。为了使机器学习模型更好的学习,特征值最好符合正态分布。但现实中的数据分布并非如此。
我们使用归一化来修改特征向量中的值,以便可以在同一分布上训练模型。在机器学习中,我们可以使用许多不同形式的归一化。一些最常见的归一化修改这些特征值以使它们总和为 1。L1 归一化指的是最小绝对偏差,其工作原理是确保每个数据样本(每行数据)的绝对值之和为 1。L2 归一化指的是最小二乘,通过确保每个数据样本(每行数据)的平方和为 1。
通常,L1 归一化技术比 L2 归一化技术更具鲁棒性,L1 归一化技术可以抵抗数据中的异常值。如果我们希望在计算过程中忽略它们这些异常值,则 L1 归一化通常是最佳选择;而如果在我们需要解决的问题中,异常值较为重要,那么 L2 归一化可能会成为更好的选择。使用 Scikit-learn 实现 L1 和 L2 归一化:
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l1)
print("\nL2 normalized data:\n", data_normalized_l2)
运行以上代码,可以得到以下输出:
L1 normalized data:
[[ 0.06936416 0.14450867 0.31213873 -0.46820809 0.00578035]
[-0.24528302 0.27830189 0.25471698 0.00943396 0.21226415]
[ 0.16917293 0.13157895 0.15789474 0.30075188 0.2406015 ]
[-0.07284768 -0.09933775 -0.1589404 -0.43708609 -0.23178808]
[ 0.09292035 0.27876106 0.24778761 -0.04867257 -0.33185841]]
L2 normalized data:
[[ 0.1185449 0.24696854 0.53345205 -0.80017808 0.00987874]
[-0.49289653 0.55924799 0.51185409 0.01895756 0.42654507]
[ 0.36133216 0.28103612 0.33724335 0.64236828 0.51389462]
[-0.13640673 -0.18600918 -0.29761469 -0.8184404 -0.43402142]
[ 0.18214788 0.54644365 0.48572769 -0.0954108 -0.65052815]]
2.2.5 标签编码
上述预处理技术都是针对输入数据特征,而标签编码 (label encoding) 是对目标标签进行处理的技术。在分类任务中,我们通常会处理很多标签,这些标签可以是文字、数字或其他形式,但许多机器学习算法需要数字作为输入。因此,如果它们已经是数字,则可以直接用于训练;但通常情况并非如此,标签通常是单词,因为单词更容易被人类理解。训练数据用单词作为标签,以便后续可以反向映射输出文字标签。要将单词标签转换为数字,可以使用 Scikit-learn 中的标签编码器 LabelEncoder。标签编码是指将单词标签转换为数字的过程,使得算法能够对其进行处理。接下里,我们使用 Scikit-learn 实现标签编码:
首先,导入所需包,并定义一些标签:
import numpy as np
from sklearn import preprocessing
labels = ['apple', 'orange', 'banana', 'orange', 'banana', 'lemon', 'pear', 'mango']
创建标签编码器对象并对其进行训练:
encoder = preprocessing.LabelEncoder()
encoder.fit(labels)
打印单词和数字之间的映射:
print("\nLabel mapping:")
for i, item in enumerate(encoder.classes_):
print(item, '-->', i)
接下来,我们对随机标签进行编码:
test_labels = ['orange', 'apple', 'mango']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
print("Encoded values =", list(encoded_values))
最后,我们解码一组随机数字,将其映射为相应的单词标签:
encoded_values = [2, 1, 0, 4]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)
print("Decoded labels =", list(decoded_list))
运行以上代码,可以得到以下输出:
Label mapping:
apple --> 0
banana --> 1
lemon --> 2
mango --> 3
orange --> 4
pear --> 5
Labels = ['orange', 'apple', 'mango']
Encoded values = [4, 0, 3]
Encoded values = [2, 1, 0, 4]
Decoded labels = ['lemon', 'banana', 'apple', 'orange']
2.3 逻辑回归分类器
逻辑回归 (logistic regression) 是用于解释输入变量和输出变量之间关系的技术,回归可用于对连续值进行预测,但逻辑回归是用于进行离散预测的算法,例如预测数据样本为真或假等。假设输入变量间是独立的,输出变量称为因变量,因变量只包含一组固定的值,这些值对应于分类问题中的类别。
我们的目标是通过使用逻辑函数估计概率来识别自变量和因变量之间的关系。本节中,我们使用 sigmoid 作为逻辑函数,在逻辑回归模型中使用 sigmoid 函数具有以下优势:
- 值域在
0和1之间 - 导数更容易计算
- 可以将非线性引入模型
接下来,我们使用逻辑回归构建分类器。
首先,导入所需包,并定义二维特征向量和相应的标签作为模型输入数据集:
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
x = np.array([[3.1, 7.2],
[4, 6.7],
[2.9, 8],
[5.1, 4.5],
[6, 5],
[5.6, 5],
[3.3, 0.4],
[3.9, 0.9],
[2.8, 1],
[0.5, 3.4],
[1, 4],
[0.6, 4.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
使用以上带有标签的数据训练分类器,创建逻辑回归分类器对象:
classifier = linear_model.LogisticRegression(solver='liblinear', C=1)
使用定义的数据训练分类器:
classifier.fit(x, y)
通过查看分类边界来可视化分类器的性能,首先定义可视化函数 visualize_classifier,该函数将分类器对象、输入数据和标签作为输入参数,并定义了画布的尺寸,在函数中使用分类器,根据输入数据的不同类别绘制所有数据点,并绘制分类器得到的决策边界:
def visualize_classifier(classifier, x, y):
min_x, max_x = x[:, 0].min() - 1.0, x[:, 0].max() + 1.0
min_y, max_y = x[:, 1].min() - 1.0, x[:, 1].max() + 1.0
mesh_step_size = 0.01
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size), np.arange(min_y, max_y, mesh_step_size))
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap=plt.cm.ocean)
plt.scatter(x[:, 0], x[:, 1], c=y, s=75, edgecolors='black', linewidth=1, cmap=plt.cm.Paired)
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(x[:, 0].min() - 1), int(x[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(x[:, 1].min() - 1), int(x[:, 1].max() + 1), 1.0)))
plt.show()
传入相应参数,调用定义的可视化函数 visualize_classifier:
visualize_classifier(classifier, x, y)
执行以上代码,可以看到分类器的决策边界如下图所示:
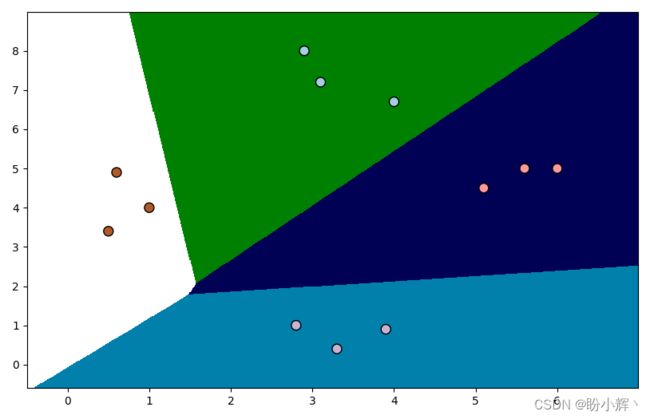
通过将 LogisticRegression 对象中 C 的值修改为 100,可以得到更加准确的决策边界:
classifier = linear_model.LogisticRegression(solver='liblinear', C=100)
classifier.fit(x, y)
visualize_classifier(classifier, x, y)
决策边界更加准确的原因是使用参数 C 可以对错误分类施加一定的惩罚,因此算法对训练数据会进行更多的微调,但如果你 C 值过大,算法将出现过拟合情况,泛化能力将大幅降低。
如果将 C 设置为 100 运行代码,可以得到以下决策边界,与 C=1 时绘制的决策边界相比较,可以看到 C=100 时决策边界更加准确:
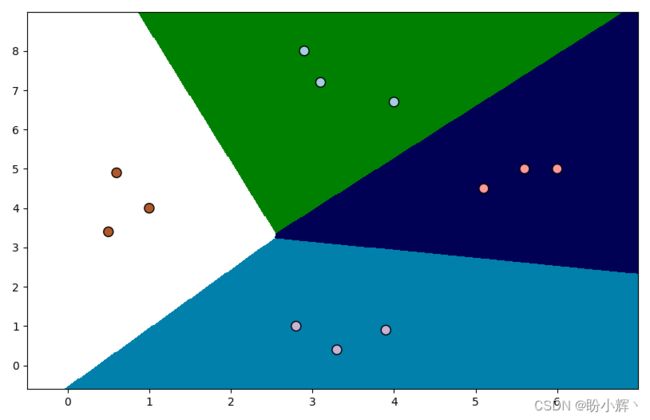
2.4 混淆矩阵
混淆矩阵 (confusion matrix) 是用于描述分类器性能的图表,矩阵中的每一行代表预测类中的实例,每一列代表实际类中的实例。我们很容易通过该矩阵判断模型错误标记的类别,可以看到有多少样本被正确分类或错误分类。
在构建混淆矩阵过程中,我们首先了解以下关键指标,我们以输出为 0 或 1 的二分类为例:
- 真阳性 (
True Positives,TP):模型预测输出为1,真实标签也是1的样本 - 真阴性 (
True Negatives,TN):模型预测输出为0,真实标签也是0的样本 - 假阳性 (
False Positives,FP):模型预测输出为1,而真实标签为0的样本,这也称为I类错误 - 假阴性 (
False Negatives,FN):模型预测输出为0,而真实标签为1的样本,这也称为II型错误
根据不同问题,我们可能需要不同的评价标准用于优化算法,可能是降低 I 类错误率,也可能是降低 I 类错误率。例如,在生物识别系统中,避免降低 I 类错误率非常重要,因为此类错误可能会造成敏感信息的泄露。接下来,我们利用 Scikit-learn 学习如何创建混淆矩阵。
首先,导入所需包,并模拟创建真实标签和预测标签数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
true_labels = [2, 0, 0, 2, 4, 2, 1, 0, 3, 3, 3, 5, 5]
pred_labels = [2, 1, 0, 2, 4, 5, 1, 0, 1, 3, 3, 2, 5]
使用上述定义的标签创建混淆矩阵:
confusion_mat = confusion_matrix(true_labels, pred_labels)
可视化混淆矩阵:
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.hot)
plt.title('Confusion matrix')
plt.colorbar()
ticks = np.arange(6)
plt.xticks(ticks, ticks)
plt.yticks(ticks, ticks)
plt.ylabel('True labels')
plt.xlabel('Predicted labels')
plt.show()
在前面的可视化代码中,ticks 变量表示标签中类别的数量。在以上示例中,我们假设有 6 个不同的标签。我们创建类别名称,并打印不同类别中的性能指标,观察模型在每个类别中的性能表现:
targets = ['Class-0', 'Class-1', 'Class-2', 'Class-3', 'Class-4', 'Class-5']
print('\n', classification_report(true_labels, pred_labels, target_names=targets))
运行代码,可以看到以下结果:
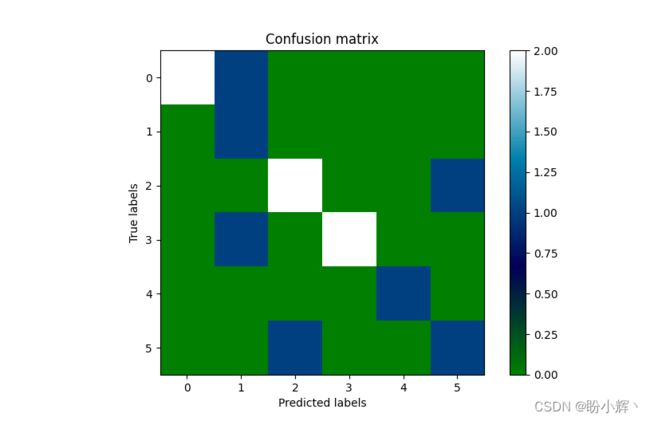
在上图中,白色表示较高的值,而绿色表示较低的值,如图像右侧的图例所示。在理想情况下,对角线中的正方形将全部为白色,而其他所有内容均为绿色,这表明模型的准确率达到了 100%。
打印出的不同类别输出报告应如下所示:
precision recall f1-score support
Class-0 1.00 0.67 0.80 3
Class-1 0.33 1.00 0.50 1
Class-2 0.67 0.67 0.67 3
Class-3 1.00 0.67 0.80 3
Class-4 1.00 1.00 1.00 1
Class-5 0.50 0.50 0.50 2
accuracy 0.69 13
macro avg 0.75 0.75 0.71 13
weighted avg 0.79 0.69 0.72 13
如上图所示,准确率为 69%,同时也可以看到每个类别的宏平均 (macro avg) 和加权平均 (weighted avg),可以将宏平均视为所有样本中的平均值,而加权平均则考虑了样本在整个数据集中的占比,可以看到平均精度为 75%,平均召回率为 75%。
2.5 支持向量机
支持向量机 (Support Vector Machine, SVM) 是使用类之间的分离超平面定义的分类器。这个超平面是一个 N 维平面。给定标记的训练数据进行二分类,SVM 的目的是找到将训练数据分为两类的最佳超平面,可以很容易的将 SVM 扩展到 N 分类问题。
我们考虑一个具有 2 个类别的数据集,且数据仅有两个特征,我们只需要处理二维平面上的点和线。这比高维空间中的向量和超平面更容易可视化。当然,这是 SVM 问题的简化版本,但使用具有两个特征的二分类问题有利于理解 SVM:
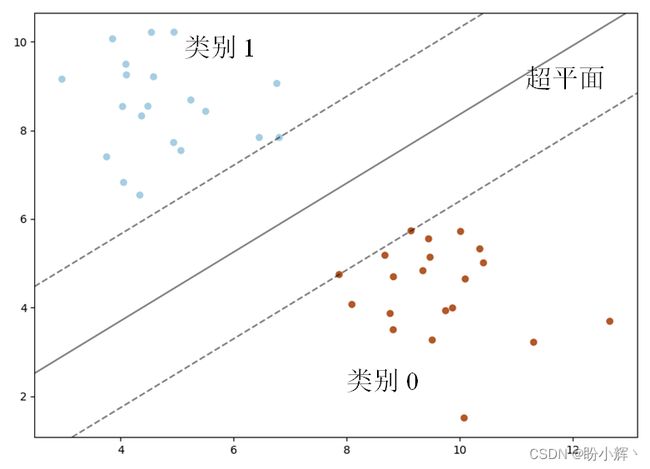
数据集中具有两个类别,我们希望找到最优的超平面来分离这两类点。但是,我们应该如何定义最优呢?在上图中,实线代表最好的超平面,虽然我们可以绘制许多不同的线来分隔两类点,但这条实线才是最好的分隔线,因为它使每个点与分隔线的距离最大化,虚线上的点称为支持向量。两条虚线之间的垂直距离称为最大边距。
接下来,我们构建支持向量机算法对收入数据进行分类,根据数据集中的 14 个属性来预测给定样本人物的收入等级。我们的目标是预测每年的收入是高于还是低于 50000 美元。因此,这是一个二分类问题。我们使用人口普查收入数据集。该数据集中,每个数据样本都是单词和数值的混合,我们不能使用原始格式的数据,因为计算机只能处理数值数据。因此,我们需要结合使用标签编码器和原始数值数据来构建有效的分类器。接下来,我们使用 Scikit-learn 算法实现 SVM,对 adult.data 数据集进行分类。
实现,导入以下所需包:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.svm import LinearSVC
from sklearn.multiclass import OneVsOneClassifier
from sklearn.model_selection import train_test_split, cross_val_score
加载数据集文件 adult.data,此文件包含收入详细信息以及相关特征:
input_file = 'adult.data'
为了从文件中加载数据,我们需要对其进行预处理以使用 SVM 模型进行分类,为了简单起见,每个类别,我们仅使用 25000 个数据样本:
x = []
y = []
count_class1 = 0
count_class2 = 0
max_datapoints = 25000
使用 with 语法打开文件,并读取文件内容:
with open(input_file, 'r') as f:
for line in f.readlines():
if count_class1 >= max_datapoints and count_class2 >= max_datapoints:
break
if '?' in line:
continue
文件中的每一行都以逗号分隔,所以我们需要相应地进行拆分,每行中的最后一个元素表示标签。根据该标签,我们为每个数据样本分配一个类别:
data = line[:-1].split(', ')
if data[-1] == '<=50K' and count_class1 < max_datapoints:
x.append(data)
count_class1 += 1
if data[-1] == '>50K' and count_class2 < max_datapoints:
x.append(data)
count_class2 += 1
将列表转换为 numpy 数组,以便它可以用作 sklearn 函数的输入:
x = np.array(x)
如果数据特征是字符串,则需要对其进行编码,如果它是一个数字,则保持原样。需要注意的是,我们最终会得到多个标签编码器,我们记录所有编码器:
label_encoder = []
x_encoded = np.empty(x.shape)
for i,item in enumerate(x[0]):
if item.isdigit():
x_encoded[:, i] = x[:, i]
else:
label_encoder.append(preprocessing.LabelEncoder())
x_encoded[:, i] = label_encoder[-1].fit_transform(x[:, i])
x = x_encoded[:, :-1].astype(int)
y = x_encoded[:, -1].astype(int)
使用线性核创建 SVM 分类器:
classifier = OneVsOneClassifier(LinearSVC())
训练分类器:
classifier.fit(x, y)
使用 train_test_split 分割数据集,进行交叉验证以进行训练和测试,然后预测训练数据的输出:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
classifier = OneVsOneClassifier(LinearSVC())
classifier.fit(x_train, y_train)
y_test_pred = classifier.predict(x_test)
计算分类器的 F1 分数:
f1 = cross_val_score(classifier, x, y, scoring='f1_weighted', cv=3)
print("F1 score: " + str(round(100*f1.mean(), 2)) + "%")
训练分类器后,我们获取随机输入数据样本并预测输出,定义一个随机数据样本:
input_data = ['37', 'Private', '215646', 'HS-grad', '9', 'Never-married', 'Handlers-cleaners', 'Not-in-family', 'White', 'Male', '0', '0', '40', 'United-States']
在执行预测之前,还需要使用之前创建的标签编码器对数据点进行编码:
input_data_encoded = [-1] * len(input_data)
count = 0
for i, item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform([input_data[i]]))
count += 1
input_data_encoded = np.array(input_data_encoded)
最后,使用训练完成的分类器预测输出:
predicted_class = classifier.predict([input_data_encoded])
print(label_encoder[-1].inverse_transform(predicted_class)[0])
运行以上代码,可以得到以下输出,其中第一行是训练后模型的 F1 分数,第二行是模型对随机构建的输入数据的预测结果:
F1 score: 69.99%
<=50K
3. 回归算法
3.1 回归算法基本概念
回归 (regression) 是估计输入和输出变量之间关系的过程,回归的输出变量是连续实数,具有无限的输出可能。这与分类相反,分类的输出类别的数量是固定的。
在回归中,假设输出变量依赖于输入变量,我们的目标是查看数据间的相关性。输入变量称为自变量,也称为预测变量,输出变量称为因变量,也称为标准变量。输入变量不必相互独立;实际上,在很多情况下输入变量之间存在相关性。回归分析能够帮助我们理解输入变量变化时,输出变量的值如何变化。
在线性回归中,我们假设输入和输出之间的关系是线性的,但有时,线性回归不足以解释输入和输出之间的关系。因此,我们可以使用多项式回归来解释输入和输出之间的关系。多项式回归在计算上更复杂,但精度更高。回归经常用于预测价格、天气变化等。
3.2 单变量回归
接下来,我们使用 Scikit-learn 实现单变量回归模型。首先导入以下所需包:
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
然后,构建输入数据,并拆分为输入变量和目标变量:
data = [[-0.86,4.38],[2.58,6.97],[4.17,7.01],[2.6,5.44],[5.13,6.45],
[3.23,5.49],[-0.26,4.25],[2.76,5.94],[0.47,4.8],[-3.9,2.7],
[0.27,3.26],[2.88,6.48],[-0.54,4.08],[-4.39,0.09],[-1.12,2.74],
[2.09,5.8],[-5.78,0.16],[1.77,4.97],[-7.91,-2.26],[4.86,5.75],
[-2.17,3.33],[1.38,5.26],[0.54,4.43],[3.12,6.6],[-2.19,3.77],
[-0.33,2.4],[-1.21,2.98],[-4.52,0.29],[-0.46,2.47],[-1.13,4.08],
[4.61,8.97],[0.31,3.94],[0.25,3.46],[-2.67,2.46],[-4.66,1.14],
[-0.2,4.31],[-0.52,1.97],[1.24,4.83],[-2.53,3.12],[-0.34,4.97],
[5.74,8.65],[-0.34,3.59],[0.99,3.66],[5.01,7.54],[-2.38,1.52],
[-0.56,4.55],[-1.01,3.23],[0.47,4.39],[4.81,7.04],[2.38,4.46],
[-3.32,2.41],[-3.86,1.11],[-1.41,3.23],[6.04,7.46],[4.18,5.71],
[-0.78,3.59],[-2.2,2.93],[0.76,4.16],[2.02,6.43],[0.42,4.92]]
data = np.array(data)
x = data[:, :-1]
y = data[:, -1]
将其拆分为训练和测试数据集:
num_training = int(0.8 * len(x))
num_test = len(x) - num_training
x_train, y_train = x[:num_training], y[:num_training]
x_test, y_test = x[num_training:], y[num_training:]
创建一个线性回归器对象并使用训练数据对其进行训练:
regressor = linear_model.LinearRegression()
regressor.fit(x_train, y_train)
使用训练模型预测测试数据集的输出:
y_test_pred = regressor.predict(x_test)
绘制模型拟合结果:
plt.scatter(x_test, y_test, color='green')
plt.plot(x_test, y_test_pred, color='blue', linewidth=4)
plt.show()
通过比较真实目标输出与模型预测输出来计算线性回归器的性能指标:
print("Linear regressor performance:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
执行以上代码,可以观察得到的回归线:
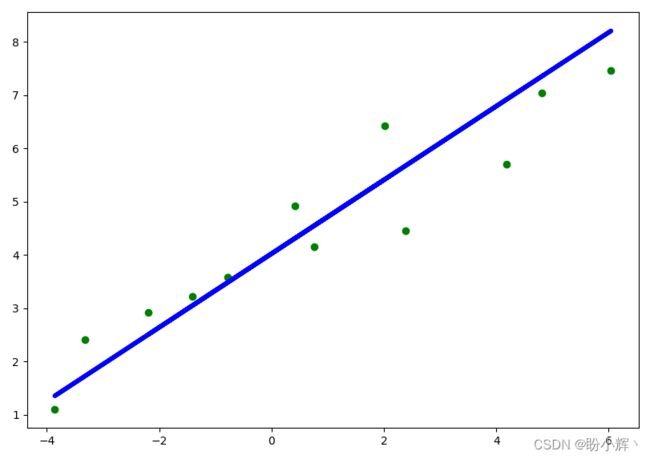
并得到以下关于线性回归模型性能的输出:
Linear regressor performance:
Mean absolute error = 0.59
Mean squared error = 0.49
Median absolute error = 0.51
Explain variance score = 0.86
R2 score = 0.86
New mean absolute error = 0.59
接下来,我们介绍上述评价模型性能的指标。平均绝对误差 (Mean Absolute Error, MAE) 是绝对误差的平均值:
∣ e ∣ = ∑ i = 0 N ∣ p i − y i ∣ N |e|=\frac {\sum ^N _{i=0}|p_i-y_i|} N ∣e∣=N∑i=0N∣pi−yi∣
其中 p i p_i pi 是预测值, y i y_i yi 是实际值, N N N 表示数据样本数。
均方误差 (Mean Squared Error, MSE) 是误差平方的平均值,即预测值与实际值之间方差的均值。MSE 几乎总是严格为正的,值越接近零越好。
可解释变异 (Explained Variation) 用于测量模型能解释数据集中变异的比例。通常,变异被量化为方差。也可以使用更具体的术语解释方差。除可解解变异外,总变异的剩余部分被称为未解释变异 (Unexplained Variation) 或残差 (Residual)。
判定系数 (Coefficient of Determination) 或 R2 分数用于分析一个变量的差异如何可以通过第二个变量的差异来解释。
3.3 多变量回归
在学习了如何为单变量构建回归模型后,我们将处理多维数据。
首先,导入所需包,构建数据集,并将其划分为输入和输出数据:
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
from sklearn.preprocessing import PolynomialFeatures
data = [[2.06,3.48,7.21,15.69],[6.37,3.01,7.27,15.34],[1.18,1.2,5.42,0.66],[7.37,3.81,-1.95,38.37],[6.16,1.39,7.39,9.96],
[4.49,5.74,6.05,23.4],[7.35,2.49,5.4,24.15],[7.7,3.39,6.62,24.89],[3.87,3.67,1.81,30.23],[5.61,6.14,1.42,41.2],
[7.66,6.29,5.66,41.35],[1.97,6.33,2.91,29.32],[1.19,4.72,2.67,22.85],[3.52,2.05,0.23,21.27],[6.69,0.89,4.5,15.88],
[-1.34,5.89,3.26,14.21],[4.44,6.41,2.86,35.16],[6.32,0.83,8.06,3.9],[1.9,3.43,3.03,12.64],[7.42,4.78,0.69,33.7],
[1.46,7.97,0.65,39.08],[3.53,1.94,5.78,6.83],[6.52,5.01,5.95,33.47],[5.42,8.23,3.42,36.05],[-4.19,3.75,3.79,4.67],
[5.48,6.83,4.34,26.12],[4.28,3.79,4.82,24.09],[7.98,7.89,6.66,34.73],[6.07,5.88,3.44,35.51],[1.2,4.63,4.18,27.5],
[6.96,8.73,2.11,49.47],[4.74,5.92,-0.62,27.05],[9.49,3.35,2.0,35.34],[3.08,4.72,3.61,31.82],[3.82,4.94,2.74,18.7],
[1.59,1.43,7.5,-0.38],[6.06,3.34,0.37,41.75],[-0.1,8.11,3.49,41.74],[8.83,5.85,9.41,32.11],[3.96,5.17,8.43,16.86],
[3.62,3.14,2.86,14.41],[4.56,1.21,3.2,17.82],[2.35,2.71,0.18,20.97],[4.96,3.51,4.28,26.3],[2.78,2.61,4.09,9.05],
[4.69,4.31,11.15,15.33],[2.49,7.88,4.67,32.85],[2.3,4.67,6.27,19.93],[6.95,6.53,3.12,42.34],[4.8,1.95,7.62,3.61],
[3.04,-0.63,2.79,6.86],[2.56,5.33,0.4,26.98],[7.24,3.34,3.3,35.39],[5.39,4.39,3.03,34.44],[3.61,4.13,0.08,34.27],
[2.82,4.97,1.6,36.07],[5.52,4.57,5.86,31.25],[4.74,1.67,1.57,19.96],[4.17,7.02,4.9,33.83],[3.33,6.04,1.75,28.35],
[-3.01,4.91,3.53,7.12],[5.68,4.43,3.87,25.25],[7.56,3.57,7.14,26.46],[3.59,3.94,5.62,10.66],[7.35,1.33,-0.83,20.06],
[10.54,1.21,-3.88,39.58],[-2.54,3.84,-0.17,19.96],[3.37,3.64,1.9,27.79],[1.24,7.16,4.26,23.84],[2.06,1.89,11.31,-3.76],
[5.27,6.23,5.18,27.42],[2.39,6.0,4.56,23.15],[6.19,7.64,3.48,39.55],[7.5,4.81,2.3,32.17],[2.27,0.78,3.24,11.3],
[5.63,8.3,1.87,49.68],[3.22,8.11,3.52,40.24],[5.34,8.75,1.79,49.52],[4.46,2.54,7.35,8.87],[1.64,9.51,2.39,47.47],
[0.19,2.81,2.77,8.83],[7.11,5.74,-0.45,47.21],[2.48,4.41,2.58,25.95],[6.52,6.46,7.17,27.29],[0.32,0.49,4.88,-7.36],
[2.95,5.83,5.16,32.78],[6.95,7.54,2.26,42.04],[5.87,5.76,0.85,41.51],[6.75,0.95,2.78,16.42],[1.02,2.89,5.71,6.23],
[5.3,5.06,3.96,35.7],[5.5,3.55,4.69,21.35],[4.22,2.71,3.16,13.48],[4.59,3.57,3.49,17.21],[4.83,2.11,4.86,14.97],
[3.75,3.8,6.16,14.47],[6.27,4.05,2.65,30.69],[2.63,8.5,7.27,31.27],[4.29,9.55,3.09,47.26],[2.11,7.07,0.57,32.2]]
data = np.array(data)
x = data[:, :-1]
y = data[:, -1]
将数据拆分为训练和测试:
num_training = int(0.8 * len(x))
num_test = len(x) - num_training
x_train, y_train = x[:num_training], y[:num_training]
x_test, y_test = x[num_training:], y[num_training:]
创建并训练线性回归模型:
linear_regressor = linear_model.LinearRegression()
linear_regressor.fit(x_train, y_train)
预测测试数据集的输出:
y_test_pred = linear_regressor.predict(x_test)
打印模型性能指标:
print("Linear Regressor performance:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explained variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
创建一个 5 次多项式回归器。在训练数据集上训练回归器。并构建一个样本数据点,执行预测:
polynomial = PolynomialFeatures(degree=5)
x_train_transformed = polynomial.fit_transform(x_train)
datapoint = [[7.75, 6.35, 5.56]]
poly_datapoint = polynomial.fit_transform(datapoint)
创建线性回归器对象并执行多项式拟合。分别使用线性和多项式回归器执行预测以查看它们之间的性能差异:
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(x_train_transformed, y_train)
print("\nLinear regression:\n", linear_regressor.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))
运行以上代码,输出如下所示:
Linear Regressor performance:
Mean absolute error = 3.42
Mean squared error = 16.4
Median absolute error = 3.12
Explained variance score = 0.92
R2 score = 0.92
Linear regression:
[36.46892628]
Polynomial regression:
[40.25900316]
可以看到,多项式回归的预测值更接近真实值,因此多项式回归模型能够做出更好的预测。
总结
在本节中,我们了解了监督学习的两种主要场景:分类和回归,我们学习了数据分类问题并构建分类模型,了解了多种数据预处理技术,其中还包括标签编码。我们还学习了使用逻辑回归构建分类器,了解了如何构建混淆矩阵。还介绍了如何使用支持向量机构建分类模型。在回归任务中,我们了解了如何将线性和多项式回归用于单变量和多变量数据。
系列链接
使用Scikit-learn开启机器学习之旅
一文开启深度学习之旅
一文开启计算机视觉之旅
一文开启自然语言处理之旅
一文开启无监督学习之旅