Python爬虫——Scrapy通用爬虫
大家好,我是霖hero
除了钱,大家还比较喜欢什么?当然是全能、万能和通用的人或事物啦,例如:全能、什么都会的员工、万能钥匙、通用爬虫等等。今天我们学习Scrapy通用爬虫,利用Scrapy通用爬虫来获取美食杰网站。
Scrapy通用爬虫
创建Scrapy项目
Spider爬虫模板
CrawlSpider
创建crawl模板爬虫
定义rules规则
定义字段
提取数据
通用配置抽取
配置文件quotes.json
rules.py规则文件
启动爬虫run.py
spider爬虫初始化及获取配置
控制翻页数
实战演练
修改rules.py规则
修改quotes.json配置
修改next.py翻页
结果展示
Scrapy通用爬虫
创建Scrapy项目
Scrapy爬虫和Scrapy通用爬虫都是通过以下执行命令来创建Scrapy项目,没什么不同,命令如下所示:
Scrapy startproject Scrapy项目名Spider爬虫模板
在创建spider爬虫前,我们先看看有什么可用的爬虫模板,执行命令如下所示:
scrapy genspider -l运行结果如下图所示:

其中:
-
basic是我们之前创建Spider的时候,默认使用的爬虫模板,也就是普通的爬虫模板;
-
crawl模板是最常用于抓取常规网站的爬虫模板,通过指定一些爬取规则来实现页面的提取,很多情况下这个模板的爬取就足够通用;
-
csvfeed模板是Scrapy最简单的爬虫模板,主要用于解析 CSV 文件,它是以行为单位来进行迭代,每迭代一行调用一次 parse_row() 方法;
-
xmlfeed模板主要用于处理RSS订阅信息,RSS是一种信息聚合技术,可以让信息的发布和共享更为高效和便捷。
接下来我们主要是讲解最常用的爬虫模板——crawl模板,其他模板我们会在往后的文章里讲解,敬请期待!!!
CrawlSpider
在使用crawl模板前,我们先要了解一下CrawlSpider。
CrawlSpider是Scrapy提供的一个通用Spider,继承自Spider类,除了拥有Spider类的所有方法和属性,它还提供了rules属性和parse_start_url()方法。
其中:
-
rules是包含一个或多个Rule对象的列表,我们可以指定一些爬取规则来实现页面的提取;
-
parse_start_url()是一个可重写的方法,当start_urls里对应的Request得到的Response时,该方法被调用。
创建crawl模板爬虫
crawl模板的通用爬虫通过执行以下命令来创建,以Quotes to Scrape网站为例子,该网站是一个著名作家名言的网站,命令如下所示:
scrapy genspider -t 模板类型 <爬虫名字> <允许爬取的域名>
scrapy genspider -t crawl quotes quotes.toscrape.com当然,我们可以把命令中的crawl改为xmlfeed或者csvfeed,这样就会生成其他类型的爬虫,成功创建后,在spiders文件夹中多了一个quotes.py文件,该文件正是我们创建的spider爬虫,其内容如下所示:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class QuotesSpider(CrawlSpider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item其中:
-
class QuotesSpider()是自定义spider类,继承自CrawlSpider
-
name是定义此爬虫名称的字符串,每个项目唯一的名字,用来区分不同的Spider,启动爬虫时使用scrapy crawl +该爬虫名字;
-
allowed_domains是允许爬取的域名,防止爬虫爬到其他网站;
-
start_urls是最开始爬取的url;
-
rules是爬取规则属性,是一个包含多个Rule对象的列表,该Rule主要用来确定当前页面中的哪些链接需要继续爬取、哪些页面的爬取结果需要哪个方法来解析等。
-
parse_item()方法是负责解析返回响应、提取数据或进一步生成要处理的请求。
注意:不能修改这个方法的名字,且不能定义parse()方法!!!
在创建Crawl模板的Spider爬虫时,Rule中只展示了最常用的参数,其完整参数如下所示:
Rule(LinkExtractor(allow=r'Items/', deny=(), allowed_domains=(), deny_domains=(), restrict_xpaths=()), callback='parse_item', follow=True, cb_kwargs=None, process_links=None, process_request=None)Rule常见的参数如下:
-
LinkExtractor是一个链接提取对象,它定义了如何从每个已爬取的页面中提取链接并用于生成一个requests对象;
-
callback是一个可调用对象或字符,和之前定义requests的callback作用一样,
-
指定链接提取器提取的每个链接交给哪个解析函数去处理;
-
follow是一个布尔值,它指定是否从使用此规则提取的每个响应中跟踪链接,当callback为None时,follow默认为True,否则为False;
-
cb_kwargs是字典,其包含了传递给回调用函数的参数;
-
process_links指定处理函数,从LinkExtractor中获取到链接列表时,该函数将会被调用,主要用于过滤url;
-
process_request指定哪个函数将会被调用,该规则提取到每个request时都会调用该函数,主要用于过滤request。
LinkExtractor常用的参数如下:
-
allow:满足括号中正则表达式的URL会被提取,如果为空,则全部匹配;
-
deny:满足括号中正则表达式的URL不会被提取,优先级高于allow;
-
allow_domains:会被提取的链接的domains;
-
deny_domains:不会被提取的链接的domains;
-
restrict_xpaths:使用xpath表达式来规则URL地址的范围。
定义rules规则
定义rules规则,也就是确定被提取的URL链接及其范围。
首先我们定义翻页的rules规则,进入名人名言网站并打开开发者工具,如下图所示:
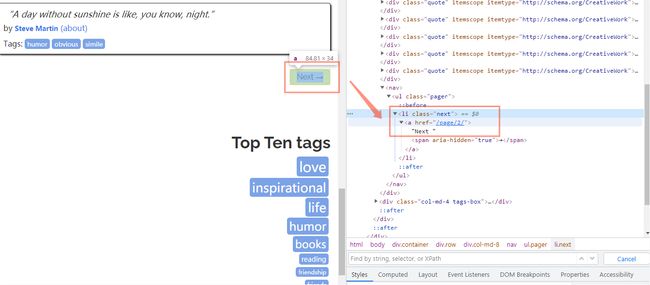
由图可知,翻页的URL存放在
Rule(LinkExtractor(allow=r'/page/\d+', restrict_xpaths='//li[@class="next"]'),follow=True),由于我们在翻页的页面中,没有需要提取的数据,所以这里没有callback参数,所以需要加上follow=True。
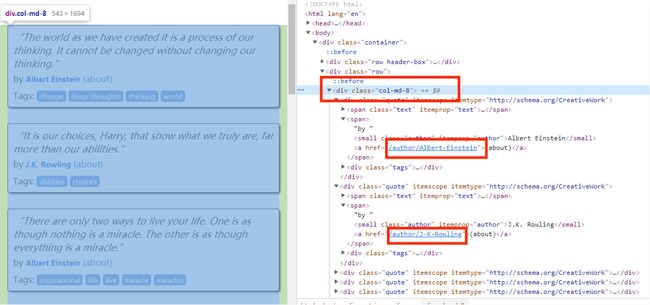
由图可以知,
rules = (
Rule(LinkExtractor(allow=r'/author/\w+',restrict_xpaths='/html/body/div[1]/div[2]/div[1]'), callback='parse_item'),
)由于在链接提取对象有我们需要提前的数据,所以这里需要写callback参数,不需要写follow参数。
定义字段
在提取数据之前,我们先在items.py文件中定义字段,具体代码如下所示:
import scrapy
class Test2Item(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()作为演示,我们只定义一个字段提取作者名,感兴趣的小伙伴可以定义多个字段提取不同的数据。
提取数据
定义了rules规则后,我们接下来尝试在parse_item()方法中提取响应的数据,具体代码如下所示:
from test2.items import Test2Item
def parse_item(self, response):
item = Test2Item()
item['name']=response.xpath('//h3[@class="author-title"]/text()').extract_first()
return item首先我们导入Test2Item,实例化Test2Item,作为演示,我们只提取作者名,感兴趣的可以提取其他数据。
Item Loader模块
提取响应数据,我们还可以使用Item Loader模块,其模块提供了一种便捷的机制来帮助我们方便的提取Item数据,让我们的数据提取变得更加规则化,其语法规则为:
变量名=ItemLoader(item={}, response=())
变量名.add_选择器('数据字段名', '选择器规则')
return 变量名.load_item()其中:
-
item是对象;
-
response是网页的响应数据;
-
add_选择器:其可以为add_xpath、add_css、add_value()
上面的提取数据代码可以修改为如下代码,具体代码如下所示:
from test2.items import Test2Item
from scrapy.loader import ItemLoader
def parse_item(self, response):
loader=ItemLoader(item=Test2Item(),response=response)
loader.add_xpath('name','//h3[@class="author-title"]/text()')
return loader.load_item()首先我们导入Test2Item和ItemLoader模块,并实例化ItemLoader和Test2Item,最后通过return loader.load_item()将数据返回给引擎。
这种提取方法比较规则化,我们可以把一些参数和规则单独提取出来做成配置文件或者存储到数据库,及可实现可配置化。
在settings.py文件中启动引擎,并在pipelines.py文件中打印输出,运行结果如下:
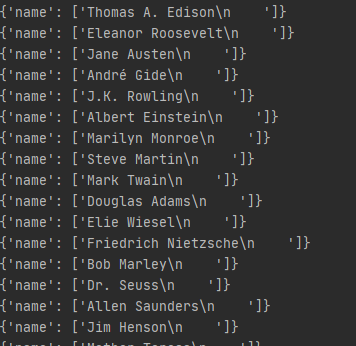
通用配置抽取
有人可能说,就这?就一个Rule规则就实现了通用?等等,别急!!!
在我们爬虫代码中,很多代码都是重复的,例如变量、方法名几乎都是一致的,那么我们可以把完全不同的地方抽离出来,做成可配置文件。
我们新建一个crawl通用爬虫,执行代码如下所示:
scrapy genspider -t crawl currency quotes.toscrape.com在刚才创建的crawl通用爬虫中,我们来思考一下哪些数据可以抽离出来做成可配置文件?没错,里面所有东西都可以做成配置文件。
配置文件quotes.json
首先我们创建一个名为configs的文件夹来存放我们的配置文件,然后创建名为quotes.json的文件来把刚才创建的crawl通用爬虫里面的内容都写入在文件中,具体代码如下所示:
{
"settings": {
"USER_AGENT":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
},
"spider":"currency",
"allowed_domains": ["quotes.toscrape.com"],
"start_urls": ["http://quotes.toscrape.com/"],
"rules": "quotes_rule",
"item": {
"class": "Test2Item",
"loader": "ItemLoader",
"attrs": {
"name": [
{
"method": "xpath",
"args": [
"/html/body/div[1]/div[2]/h3/text()"
]
}
]
}
}
}首先我们把settings.py文件中的User-Agent配置先写入到文件中,再把爬虫名、爬虫爬取的网站域名、最先爬取的URL链接以及rules规则写入到文件中,最后把提取数据的方法写入到文件中,其中:
-
item:保存抓取数据的容器;
-
class:是我们items.py文件中的类,用来定义数据字段;
-
loader:是填充容器的机制,也就是上面所讲的规范提取数据的ItemLoader模块;
-
attrs:表示提取数据内容;
-
name:是items.py文件中,定义的字段,也就是我们要提取的作者名字;
-
method:数据提取的方法,我们这里选用了xpath提取;
-
args:表示提取数据的规则、表达式;
rules.py规则文件
有人可能问,rules规则这么简单?当然,rules不会那么简单,这里我们新建一个rules.py文件来存放Rule规则,具体代码如下所示:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
rules = {
'quotes_rule':(Rule(LinkExtractor(allow=r'/author/\w+',restrict_xpaths='/html/body/div[1]/div[2]/div[1]'), callback='parse_item'),
Rule(LinkExtractor(allow=r'/page/\d+', restrict_xpaths='//li[@class="next"]'),follow=True),)
}这里我们把rules规则已字典的形式来保存,以便我们获取rules里面的值。
我们创建了配置文件,当然要把配置的文件读取出来了,所以我们新建了一个名为Read_configs.py的文件来读取数据,具体代码如下所示:
from os.path import realpath,dirname
import json
def get_config(name):
path = dirname(realpath(__file__)) + '/configs/' + name + '.json'
with open(path, 'r', encoding='utf-8')as f:
return json.loads(f.read())启动爬虫run.py
创建读取文件后,接下来要创建一个启动Spider爬虫的文件,我们把它命名为run.py,具体代码如下所示:
import sys
from scrapy.utils.project import get_project_settings
from test2.Read_configs import get_config
from scrapy.crawler import CrawlerProcess
def run():
name=sys.argv[1]
custom_settings=get_config(name)
spider=custom_settings.get('spider','currency')
project_settings=get_project_settings()
settings=dict(project_settings.copy())
settings.update(custom_settings.get('settings'))
process=CrawlerProcess(settings)
process.crawl(spider,**{'name':name})
process.start()
if __name__=='__main__':
run()首先我们导入一些模块和库,再获取命令行的参数并赋值为name,通过刚才在Read_configs.py所创建的get_config()将配置文件quotes.json读取保存下来,再通过get()方法把Spider爬虫名获取下来并存放在spider变量中,通过get_project_settings()方法来获取Scrapy项目中的settings.py配置并调用dict()方法把配置变为字典的格式保存在settings变量中,再调用update()方法更新custom_settings变量的数据内容,最后实例化CrawlerProcess,并调用crawl()和start()方法启动爬虫。
spider爬虫初始化及获取配置
在启动爬虫前,首先我们要初始化爬虫数据并通过parse_item()方法获取属性配置,具体代码如下所示:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from test2.Read_configs import get_config
from test2.rules import rules
from test2 import next
from test2.items import Test2Item
from scrapy.loader import ItemLoader
class CurrencySpider(CrawlSpider):
name = 'currency'
def __init__(self,name,*args,**kwargs):
config=get_config(name)
self.config=config
self.allowed_domains=config.get('allowed_domains')
self.start_urls=config.get('start_urls')
self.rules=rules.get(config.get('rules'))
super(CurrencySpider, self).__init__(*args,**kwargs)
def parse_item(self, response):
item=self.config.get('item')
cls=eval(item.get('class'))()
loader=eval(item.get('loader'))(cls,response=response)
for key,value in item.get('attrs').items():
for extractor in value:
if extractor.get('method')=='xpath':
loader.add_xpath(key,*extractor.get('args'))
return loader.load_item()首先我们重新定义init()方法,把allowed_domains、start_urls和rules等属性赋予值,再通过编写parse_item方法来动态获取属性配置从而提取数据,首先使用get()方法来获取item配置信息,在使用eval()方法来获取返回get()中的值。最后通过for循环来获取数据并返回给引擎。
这里我们的pipeline.py文件只是简单地打印数据,其内容如下:
class Test2Pipeline:
def process_item(self, item, spider):
print(item)最后执行以下命令来运行爬虫:
run.py quotes运行结果如下所示:
控制翻页数
那么问题来了,假如翻页数有几千页呢,我们不可能每次都要从第一页爬到最后一页的吧,怎样要提取指定页面的数据呢
这时,我们的start_urls可以在quotes.json文件中改为:
"start_urls": {
"type": "dynamic",
"method": "next",
"args": [
1,2
]
},其中,type是start_urls类型,method是调用的方法,args是开始页和结束页的页码,大家可以根据需求来获取想要的页面。
注意把rules.py文件中以下代码删除,要不然不能实现爬取指定页数:
Rule(LinkExtractor(allow=r'/page/\d+', restrict_xpaths='//li[@class="next"]'),follow=True),)除了修改start_urls,我们还需要创建实现method调用的方法,这里我们上面我们定义的方法是next,所以我们新建一个next.py文件,其具体代码为:
def next(start,end):
for page in range(start,end+1):
yield 'https://www.meishij.net/fenlei/xiafancai/p'+str(page)+'/'再在currency.py文件中加以下代码来获取start_urls的值:
from test2 import next
start_urls=config.get('start_urls')
self.start_urls=list(eval('next.'+start_urls.get('method'))(*start_urls.get('args',[])))这样我们就实现了指定页面的爬取。
这样,一个scrapy通用爬虫就做好了,对了,为了防止大家弄乱了文件位置,导致程序报错,贴心的我们把项目目录截图了下来,如下图所示:

那么贴心,赶紧评论、点赞加收藏走一波。
当我们想用刚才创建的通用爬虫时,只要修改quotes.json、next.py、rules.py中的部分代码即可。
有人可能觉得,我靠,弄一个Scrapy通用爬虫要写那么多.py文件,我还是老老实实写Scrapy普通的爬虫算了。
接下来我们通过实战演练,展示写了一个Scrapy通用爬虫对以后的网站爬取有多么地方便。
实战演练
现在我们来实战测试一下Scrapy通用爬虫的方便性,测试的网站为美食杰的下饭菜。
修改rules.py规则
我们先修改rules规则:
我们先进入美食杰网站并打开开发者模式,如下图所示:

由图可知,
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
rules = {
'quotes_rule':(Rule(LinkExtractor(allow=r'https://www.meishij.net/zuofa/\w+\.html',restrict_xpaths='//div[@class="list_s2"]'), callback='parse_item'),)
}修改quotes.json配置
点击具体做法的URL链接并打开开发者模式,如下图所示:

菜品名存放在
//h1[@class="recipe_title"]/text()
//h1[@class="recipe_title"]/text()那么我们quotes.json文件中的args改为如下代码:
"attrs": {
"name": [
{
"method": "xpath",
"args": [
"//h1[@class=\"recipe_title\"]/text()"
]
}
]
}因为不同的网站,其域名也不一样,所以我们要将域名修改为美食杰的域名,其代码修改为如下代码:
"allowed_domains": ["www.meishij.net"],修改next.py翻页
首先经过简单的查找,美食杰的下饭菜前几页的URL链接为:
https://www.meishij.net/fenlei/xiafancai/p1/
https://www.meishij.net/fenlei/xiafancai/p2/
https://www.meishij.net/fenlei/xiafancai/p3/很明显链接最后面的数字是翻页的重要参数,所以我们可以把next.py文件修改为:
def next(start,end):
for page in range(start,end+1):
yield 'https://www.meishij.net/fenlei/xiafancai/p'+str(page)+'/'好了,全部代码已经修改完毕了。
结果展示
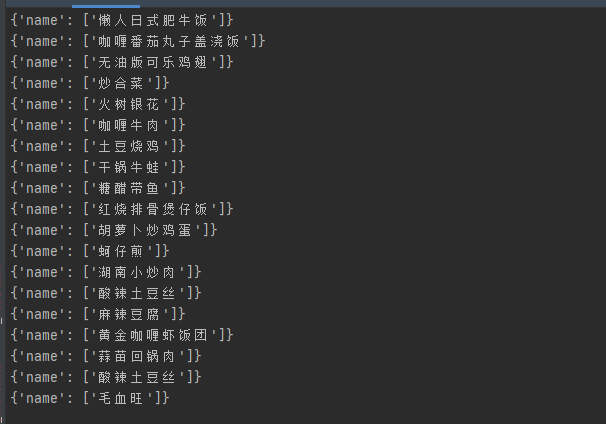
从结果上看,我们只是简单地修改了Scrapy项目中的一些代码,就实现了对其他网站的数据爬虫,你们懂的,赶紧把文章点赞收藏做一个Scrapy通用爬虫来方便自己以后爬取一些简单网站的数据。
好了,Scrapy通用爬虫就讲解到这里了,感谢观看!!!