Pandas学习笔记
一、Pandas
1.介绍与安装
关系型、标记型数据的数据分析工具;以numpy为基础,借助其在计算方面高性能的优势,还基于matplotlib进行画图。
Pandas优点:
- 增加图表可读性,将数组显示为表格,使得图表更加直观
- 更加方便的数据处理
- 读取文件更加方便
- 将matplotlib和numpy进行封装
安装
windows:
升级 pip:
python3 -m pip install -U pip
安装 pandas库:(Ubuntu一样)
pip install pandas
下载完成后可以在Python文件中
import pandas as pd # 导入pandas一般使用别名 pd代替 print(pd.__version__)来测试是否安装成功
2.Pandas数据结构
- Series:一维数据结构
- Dataframe:二维的表格型数据结构
- MultiIndex(老版本叫Panel ):三维的数据结构
(1)Series:一维数据结构
Series是一个类似于一维数组的数据结构,由数据和索引两部分构成。
①创建Series
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
data:传入的数据,可以是ndarray、list等index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。dtype:数据的类型
import pandas as pd
import numpy as np
# 1.通过已有数据创建,指定内容,默认索引,即从0开始
pd.Series(np.arange(3))
# 0 0
# 1 1
# 2 2
# dtype: int32
# 2.通过已有数据创建,指定内容,指定索引
pd.Series(np.arange(3),[1,3,4])
# 1 0
# 3 1
# 4 2
# dtype: int32
# 3.通过字典创建数据,这样索引就会被设置为key值
pd.Series({'name':'小明','gender':'男','age':'20'})
# name 小明
# gender 男
# age 20
# dtype: object # object:python对象
②index和values属性
想要查看索引或者其值时,可以使用index和values属性
a=pd.Series({'name':'小明','gender':'男','age':'20'})
a.index
# Index(['name', 'gender', 'age'], dtype='object')
a.values
# array(['小明', '男', '20'], dtype=object)
(2)DataFrame:二维的表格型数据结构
DataFrame既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index
- 列索引,表名不同列,纵向索引,叫columns
①创建DataFrame
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
import pandas as pd
# 创建成绩,取值范围0-100,生成3行5列
score=np.random.randint(0, 100, (3, 6))
index_label=['小王','小张','小明']
columns_label=['语文','数学','英语','政治','历史','地理']
pd.DataFrame(data=score,index=index_label,columns=columns_label)
②属性
.shape:数组形状.index:行索引值.columns:列索引值.values:array的值,即将二维数组所有数据打印.T:转置head():显示前n行,默认显示全部tail():显示后n行,默认显示全部
score=np.random.randint(0, 100, (3, 6))
index_label=['小王','小张','小明']
columns_label=['语文','数学','英语','政治','历史','地理']
a=pd.DataFrame(data=score,index=index_label,columns=columns_label)
# 查看数组形状
a.shape
# (3, 6)
# 查看行索引
a.index
# Index(['小王', '小张', '小明'], dtype='object')
# 查看列索引
a.columns
# Index(['语文', '数学', '英语', '政治', '历史', '地理'], dtype='object')
# 查看array的值
a.values
# array([[ 2, 98, 76, 81, 87, 14],
# [28, 82, 9, 43, 29, 0],
# [16, 29, 17, 83, 76, 20]])
# 转置
a.T
# 小王 小张 小明
# 语文 21 5 72
# 数学 98 86 89
# 英语 60 53 68
# 政治 26 63 6
# 历史 78 26 8
# 地理 9 46 0
# 显示部分行
# 显示前n行
a.head(1)
# 语文 数学 英语 政治 历史 地理
# 小王 91 50 56 79 9 74
# 显示后n行
a.tail(1)
# 语文 数学 英语 政治 历史 地理
# 小明 91 50 56 79 9 74
③索引修改
stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu
# 错误修改方式
data.index[3] = '学生_3'
注意:要修改索引必须全部都修改
④重设索引—reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,而是在原来列索引前新建一列;如果为True,则是删除原来的索引值
⑤将某列设置为新的索引—set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop: boolean, default True.当做新的索引,删除原来的列,False则保留原来的列
若keys值设置多个,则表示多个索引,那么就会变为一个具有MultiIndex的DataFrame。
(3)MultiIndex(老版本叫Panel ):三维的数据结构
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。 类似ndarray中的三维数组。
①创建pd.MultiIndex.from_arrays(levels,names)
pd.MultiIndex.from_arrays(levels,names)
# MultiIndex(levels,names)
②属性
levels:每个level的元组值names:levels的名称
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
a=pd.MultiIndex.from_arrays(arrays, names=('number', 'color'))
a
# MultiIndex([(1, 'red'),
# (1, 'blue'),
# (2, 'red'),
# (2, 'blue')],
# names=['number', 'color'])
a.levels
# FrozenList([[1, 2], ['blue', 'red']])
# FrozenList(['number', 'color'])
二、操作与运算
1.基本操作
(1)索引
- 直接索引—先列后行
- loc—先行后列,需要通过索引的字符串进行获取
- iloc—先行后列,通过下标进行索引
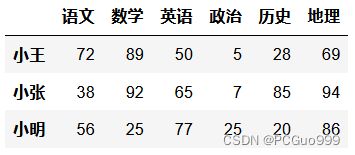
score=np.random.randint(0, 100, (3, 6))
index_label=['小王','小张','小明']
columns_label=['语文','数学','英语','政治','历史','地理']
a=pd.DataFrame(data=score,index=index_label,columns=columns_label)
# 1.获取'语文'列'小张'和'小王'行的数据
a['语文']['小王':'小张']
# 小王 72
# 小张 38
# Name: 语文, dtype: int32
# 2.获取'小张'和'小王'行'语文'列的数据
a.loc['小王':'小张']['语文']
# 小王 72
# 小张 38
# Name: 语文, dtype: int32
# 3.获取前三行前三列的数据
a.iloc[:3, :3]
# 语文 数学 英语
# 小王 72 89 50
# 小张 38 92 65
# 小明 56 25 77
# 4获取第一行到第三行语文、数学、英语的成绩(同3相同)
a.loc[a.index[0:3],['语文','数学','英语']]
a.iloc[0:3,a.columns.get_indexer(['语文','数学','英语'])]
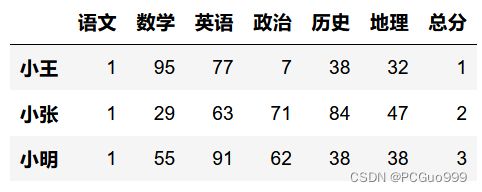
(2)赋值
对DataFrame当中的某一列进行重新赋值
若该列不存在,则会在所有列最后面新建该列并赋值
# 将'语文'列所有值都赋值1
a['语文']=1
# 因为没有‘总分’列,所以会在所有列后新建一列并复制
a['总分']=[1,2,3]
a
(3)排序
排序可以对索引排序,也可以对内容进行排序
①Series排序
Series排序时,只有一列,不需要参数
.sort_index():对索引进行排序.sort_values(ascending=True):对内容值进行排序
a=pd.Series([1,3,5,2,4,6],index=[6,5,4,3,2,1])
b=a.sort_index()
b
# 1 6
# 2 4
# 3 2
# 4 5
# 5 3
# 6 1
# dtype: int64
a=pd.Series([1,3,5,2,4,6],index=[6,5,4,3,2,1])
b=a.sort_values()
b
# 6 1
# 3 2
# 5 3
# 2 4
# 4 5
# 1 6
# dtype: int64
②DataFrame排序
.sort_index(ascending=True,inplace=True):对索引进行排序ascending:False:降序、True:升序,默认升序inplace:是否是对原数据进行操作,True则会改变原数据,默认False,需要新建变量保存
.sort_values(by=, ascending=True):对内容值进行排序by:指定排序参考的键ascending:False:降序、True:升序,默认升序
score=np.array([[98, 89, 33],
[90, 28, 66],
[52, 32, 79],
[92, 58, 81]])
index_label=np.array(['No._%d'%i for i in range(0,4)])
# 即index的值为No.0,No.1,No.2,No.3
columns_label=np.array(['语文','数学','英语'])
a=pd.DataFrame(score,index_label,columns_label)
# 以index进行排名
a.sort_index(ascending=False)
# 语文 数学 英语
# No._3 98 89 33
# No._2 90 28 66
# No._1 52 32 79
# No._0 92 58 81
# 以'语文'分数进行排名
a.sort_values('语文')
# 语文 数学 英语
# No._2 52 32 79
# No._1 90 28 66
# No._3 92 58 81
# No._0 98 89 33
2.DataFrame运算
score=np.array([[50, 50, 50],
[90, 28, 66],
[52, 32, 79],
[92, 58, 81]])
index_label=np.array(['No._%d'%i for i in range(0,4)])
# 即index的值为No.4,No.3,No.2,No.1
columns_label=np.array(['语文','数学','英语'])
a=pd.DataFrame(score,index_label,columns_label)
(1)算术运算—add(),sub()
# 所有人的语文分数加上自己的数学分数
a['语文'].add(a['数学'])
# No._0 100
# No._1 118
# No._2 84
# No._3 150
# dtype: int32
# 所有人语文分数减2分
a['语文'].sub(2)
# No._0 48
# No._1 88
# No._2 50
# No._3 90
# Name: 语文, dtype: int32
(2)逻辑运算
①a[判断语句].head()
②a.query(判断语句).head()
③a[a[判断语句].isin(values)]
使用逻辑运算可以直接进行判断,但是若想输出筛选为True的数据,则需要a[判断语句].head(),但是为了使得更加方便简单,可以使用a.query(查询字符串).head(),若判断是否为一组数据中的一个,则可以使用a[a[判断语句].isin(values)]
# 判断语文成绩及格的
a['语文']>60
# No._0 False
# No._1 True
# No._2 False
# No._3 True
# Name: 语文, dtype: bool
a[a['语文']>60].head()
a.query('语文>60').head()
# 语文 数学 英语
# No._1 90 28 66
# No._3 92 58 81
# 判断语文成绩在50-80之间
(a['语文']>50)&(a['语文']<80)
# No._0 False
# No._1 False
# No._2 True
# No._3 False
# Name: 语文, dtype: bool
a[(a['语文']>50)&(a['语文']<80)].head()
a.query('语文>50&语文<80').head()
# 语文 数学 英语
# No._2 52 32 79
# 判断是否有人分数为[50,52,90]
a[a['语文'].isin([50,52,90])].head()
# 语文 数学 英语
# No._0 50 50 50
# No._1 90 28 66
# No._2 52 32 79
(3)统计运算
通过统计运算,可以得出比如min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)等等结果
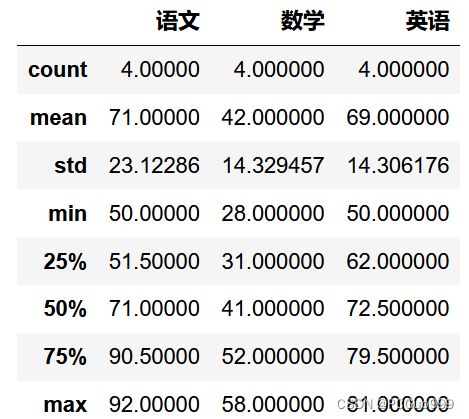
①综合统计函数—对象.describe()
describe(): 综合统计函数,可以同时返回数据中的数据量、均值、标准差、最小值、最大值,以及25%、50%、75%分位数。
②统计函数
| 函数 | 作用 |
|---|---|
.count() |
数量 |
.sum() |
所有数据的和 |
.mean() |
数据的平均值 |
.min() |
最小值 |
.max() |
最大值 |
.mode() |
众数 |
.median() |
中位数 |
.abs() |
绝对值 |
.std() |
标准差 |
.var() |
方差 |
.idxmax() |
最大值索引 |
.idxmin() |
最小值索引 |
对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
③累积统计函数
| 函数 | 作用 |
|---|---|
.cumsum() |
计算前n个数的和 |
.cummax() |
计算前n个数的最大值 |
.cummin() |
计算前n个数的最小值 |
.cumprod() |
计算前n个数的积 |
④自定义运算—apply(func, axis=0)
func:自定义函数axis=0:默认是列,axis=1为行进行运算
a[['数学', '英语']].apply(lambda x: x.max() - x.min(), axis=0)
# 数学 30
# 英语 31
# dtype: int32
三、Pandas画图
1.Series画图—pandas.Series.plot()
# 加入数据,创建DataFrame数组
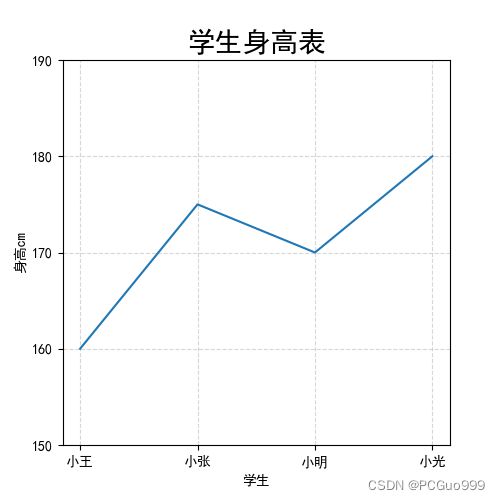
score=np.array([160, 175, 170,180])
index_label=['小王','小张','小明','小光']
a=pd.Series(data=score,index=index_label)
# 创建画布
plt.figure(figsize=(5,5), dpi=100)
# 绘制图像
a.plot()
# 设置x轴y轴刻度
plt.xticks(range(0,len(index_label)),index_label)
plt.yticks(range(150,200,10))
# 添加x轴、y轴描述信息及标题
plt.xlabel('学生')
plt.ylabel('身高cm')
plt.title('学生身高表', fontsize=20)
# 添加网格
plt.grid(True, linestyle='--', alpha=0.5)
# 保存图片到指定路径
plt.savefig("./images/学生身高表.png")
# 显示图像
plt.show()
2.DataFrame画图—pandas.DataFrame.plot()
Index值为x轴,数值为y轴,columns值为图像名
# 加入数据,创建DataFrame数组
score=np.array([[60, 60, 60],
[90, 28, 66],
[52, 32, 79],
[92, 58, 81]])
index_label=['小王','小张','小明','小光']
columns_label=['语文','数学','英语']
a=pd.DataFrame(data=score,index=index_label,columns=columns_label)
b=a.T
# 创建画布
plt.figure(figsize=(5,5), dpi=100)
# 绘制图像
b.plot()
# 设置x轴y轴刻度
plt.xticks(range(0,len(columns_label)),columns_label)
plt.yticks(range(0,101,10))
# 添加x轴、y轴描述信息及标题
plt.xlabel('科目')
plt.ylabel('分数')
plt.title('学生成绩表', fontsize=20)
# 添加网格
plt.grid(True, linestyle='--', alpha=0.5)
# 保存图片到指定路径
plt.savefig("./images/学生成绩表.png")
# 显示图像
plt.show()

四、文件读取与存储
因为数据量,数据大多存储在文件中,Pandas支持IO操作,Pandas的API支持很多常见的文件格式,比如:CSV、HDF5、SQL、JSON、XLS
API:应用程序编程接口
是一些预先定义的函数,可以让开发人员无需访问源码和了解其运行过程即可使用
1.CSV
(1)读取文件—read_csv
pandas.read_csv(filepath_or_buffer, sep =',', usecols )
-
filepath_or_buffer:文件路径
-
sep :分隔符,默认用","隔开
Student_score_test.csv:
,语文,数学,英语
小王,60,60,60
小张,90,28,66
小明,52,32,79
小光,92,58,81 -
usecols:指定读取的列名,列表形式
# 读取文件,并且指定只获取'语文', '数学'列数据
data = pd.read_csv("./data/Student_score.csv", usecols=['语文', '数学','英语'])
data
# 语文 数学 英语
# 0 60 60 60
# 1 90 28 66
# 2 52 32 79
# 3 92 58 81
(2)保存读取的文件—to_csv
DataFrame.to_csv(path_or_buf=None, sep=',’, columns=None, header=True, index=True, mode='w', encoding=None)
- path_or_buf :文件路径
- sep :分隔符,默认用","隔开
- columns :选择需要的列索引
- header :boolean or list of string, default True,是否写进列索引值
- index:是否写进行索引
- mode:‘w’:重写, ‘a’ 追加
# 选取2行数据保存到Student_score_test.csv文件中,便于观察
data[:10].to_csv("./data/Student_score_test.csv", columns=['语文', '数学'])
# Student_score_test.csv:
# ,语文,数学,英语
# 0,60,60,60
# 1,90,28,66
# 2,52,32,79
# 3,92,58,81
# 将语文=100,数学=100,英语=100追加到Student_score_test.csv文件
a=pd.DataFrame(data=[[100,100,100]],index=[4],columns=['语文','数学','英语'])
a.to_csv("./data/Student_score_test.csv",header=False,mode='a')
# Student_score_test.csv:
# ,语文,数学,英语
# 0,60,60,60
# 1,90,28,66
# 2,52,32,79
# 3,92,58,81
# 4,100,100,100
2.HDF5
read_hdf与to_hdf
-
pandas.read_hdf(path_or_buf,key =None,** kwargs) -
DataFrame.to_hdf(path_or_buf, key, **kwargs)-
path_or_buffer:文件路径
-
key:读取的键
-
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
注意:优先选择使用HDF5文件存储
HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
使用压缩可以提磁盘利用率,节省空间
HDF5还是跨平台的,可以轻松迁移到hadoop 上面
3.JSON
JSON是我们常用的一种数据交换格式,在前后端的交互经常用到,也会在存储的时候选择这种格式。
read_json与to_json
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)
-
path_or_buf:文件路径或者json格式的字符串。 -
orient: 存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}-
split: dict like {index -> [index], columns -> [columns], data -> [values]}有索引,列字段和数据构成的json格式。key名称只能是index,columns和data。'{"index":[],"columns":[],"data":[]}' -
records: list like [{column -> value}, … , {column -> value}]成员为字典的列表。records 以
columns:values的形式输出 -
index: dict like {index -> {column -> value}}以索引为key,以列字段构成的字典为键值 -
columns: dict like {column -> {index -> value}}这种处理的就是以列为键,对应一个值字典的对象。这个字典对象以索引为键,以值为键值构成的json字符串。 -
values: 一个嵌套的列表
-
-
lines: boolean, default False- 按照每行读取json对象
-
typ: default ‘frame’, 指定转换成的对象类型series或者dataframe
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
lines:一个对象存储为一行
五、高级处理
1.缺失值处理
当该数据并无数据时,需要使用缺失值进行标记,并对这些缺失值进行处理
获取缺失值的标记方式有NaN或者其他标记方式)
(1)判断数据中是否有NaN:
pd.isnull(df) # 是否存在NaN
pd.nitnull(df) # 是否不存在NaN
# 读取学生表信息
data=pd.read_csv("./data/Student_score.csv")
# Unnamed: 0 语文 数学 英语
# 0 0 60 60 60.0
# 1 1 90 28 66.0
# 2 2 52 32 79.0
# 3 3 92 58 NaN
# 4 4 100 100 100.0
pd.notnull(data)
# Unnamed: 0 语文 数学 英语
# 0 True True True True
# 1 True True True True
# 2 True True True True
# 3 True True True False
# 4 True True True True
(2)若存在缺失值
①NaN:.dropna(axis='rows')、.fillna(value,inplace=True)
# 1.删除缺失值,不会修改原数据,需要变量保存
.dropna(axis='rows')
# 2.替换缺失值,value:替换成的值,inplace:是否修改原数据
.fillna(value,inplace=True)
# 不修改原数据删除有NaN的数据
data.dropna()
# Unnamed: 0 语文 数学 英语
# 0 0 60 60 60.0
# 1 1 90 28 66.0
# 2 2 52 32 79.0
# 4 4 100 100 100.0
# 修改原数据删除有NaN的数据
data.fillna(0,inplace=True)
data
# Unnamed: 0 语文 数学 英语
# 0 0 60 60 60.0
# 1 1 90 28 66.0
# 2 2 52 32 79.0
# 3 3 92 58 0.0
# 4 4 100 100 100.0
②如果缺失值没有使用NaN标记,则先将标记替换为np.nan,然后继续处理
比如标记为’?',若使用read_csv时会报错解决办法:
# 全局取消证书验证
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 1.先替换‘?’为np.nan,to_replace:替换前的值,value:替换后的值
data = data.replace(to_replace='?', value=np.nan)
# 2.再进行缺失值处理
# 删除
data = data.dropna()
2.数据离散化
(1)介绍
连续属性离散化的目的是为了简化数据结构,减少连续属性值的个数。离散化方法经常作为数据挖掘的工具。
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
举个栗子:分数区间为0-100,为了简化数据,可以将分数分为优良差,0-59为差,60-79为良,80-100为优,这样就可以将之前数量庞大的表格变为只有三列的数据
(2)过程
①读取数据
data = pd.read_csv("./data/Student_score.csv")
score= data['语文']
# 0 60
# 1 90
# 2 50
# 3 75
# Name: 语文, dtype: int64
②将数据进行分组
pd.qcut(data, q):- 对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
series.value_counts():统计分组次数pd.cut(data, bins):自定义区间分组,bins是区间
# 自行分组
qcut = pd.qcut(score, 3)
# 0 (49.999, 60.0]
# 1 (75.0, 90.0]
# 2 (49.999, 60.0]
# 3 (60.0, 75.0]
# Name: 语文, dtype: category
# Categories (3, interval[float64, right]): [(49.999, 60.0] < (60.0, 75.0] < (75.0, 90.0]]
# 计算分到每个组数据个数
qcut.value_counts()
# (49.999, 60.0] 2
# (60.0, 75.0] 1
# (75.0, 90.0] 1
# Name: 语文, dtype: int64
# 自定义区间分组
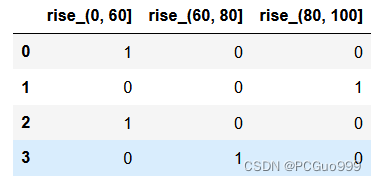
bins=[0,60,80,100]
cut = pd.cut(score, bins)
# 0 (0, 60]
# 1 (80, 100]
# 2 (0, 60]
# 3 (60, 80]
# Name: 语文, dtype: category
# Categories (3, interval[int64, right]): [(0, 60] < (60, 80] < (80, 100]]
③分组数据转成one-hot编码
one-hot编码:把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为独热编码。
pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字
# 得出one-hot编码矩阵
dummies = pd.get_dummies(cut, prefix="rise")
3.合并
如果数据由多张表组成,那么有时候需要将不同的内容合并在一起分析
(1)pd.concat([data1, data2], axis=1)0列1行
data=[[1,2,3],[4,5,6],[7,8,9]]
index=['N0.%d'%i for i in range(0,3)]
columns=['语文','数学','英语']
a=pd.DataFrame(data=data,index=index,columns=columns)
# 语文 数学 英语
# N0.0 1 2 3
# N0.1 4 5 6
# N0.2 7 8 9
data2=[[10,20,30],[40,50,60],[70,80,90]]
index2=['N0.%d'%i for i in range(3,6)]
columns2=['语文','数学','英语']
b=pd.DataFrame(data=data2,index=index2,columns=columns2)
# 语文 数学 英语
# N0.3 10 20 30
# N0.4 40 50 60
# N0.5 70 80 90
# 合并,按列合并
pd.concat([a,b],axis=0)
# 合并,按行合并
pd.concat([a,b],axis=1)
按列合并: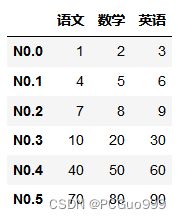 按行合并:
按行合并: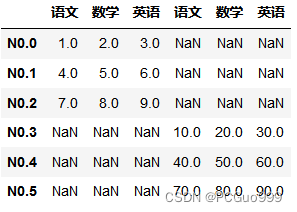
(2)pd.merge(left, right, how='inner', on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrameright: 另一个DataFrameon: 连接的键的依据是哪几个how:按照什么方式连接- left左连接
- right右连接
- outer外连接
- inner内连接(默认)
data=[[1,2,3],[4,5,6],[7,8,9]]
index=['N0.%d'%i for i in range(0,3)]
columns=['语文','数学','英语']
a=pd.DataFrame(data=data,index=index,columns=columns)
# 语文 数学 英语
# N0.0 1 2 3
# N0.1 4 5 6
# N0.2 7 8 9
data2=[[1,2,3],[40,50,60],[70,80,90]]
index2=['N0.%d'%i for i in range(3,6)]
columns2=['语文','政治','历史']
b=pd.DataFrame(data=data2,index=index2,columns=columns2)
# 语文 政治 历史
# N0.3 1 2 3
# N0.4 40 50 60
# N0.5 70 80 90
左连接:将左表全部显示,右表进行合并,若没有的用NaN
pd.merge(a,b,how='left')

右连接:将右表全部显示,左表进行合并,若没有的用NaN
pd.merge(a,b,how='right')
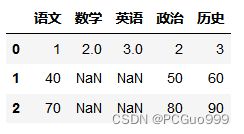
外连接:将两表都显示,没有的NaN
pd.merge(a,b,how='outer')
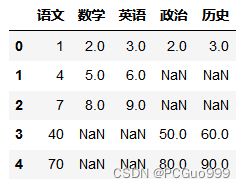
内连接:双方只显示相同的,只有
pd.merge(a,b)

4.交叉表与透视表
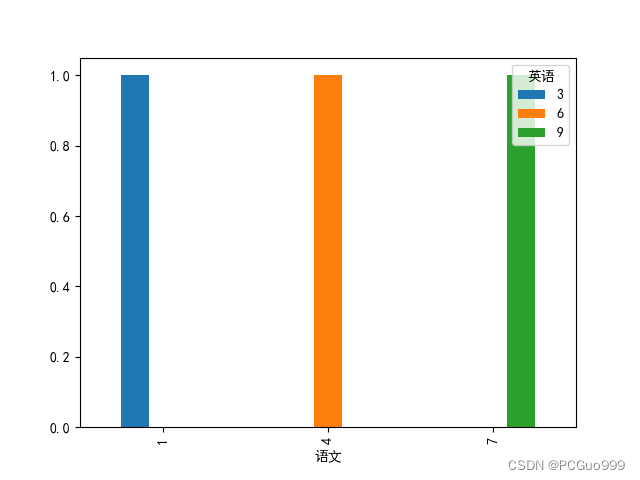
(1)交叉表:
交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表),即是计算次数的
pd.crosstab(value1, value2)
data=[[1,2,3],[4,5,6],[7,8,9]]
index=['N0.%d'%i for i in range(0,3)]
columns=['语文','数学','英语']
a=pd.DataFrame(data=data,index=index,columns=columns)
c=pd.crosstab(a['语文'],a['英语'])
c.plot.bar()
plt.savefig('./images/透视表.png')
plt.show()
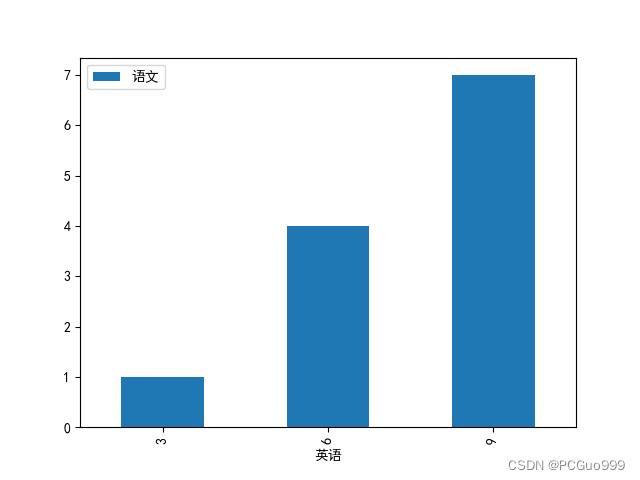
(2)透视表:
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数。即指定某一列对另一列的比例关系
data.pivot_table([], index=[])
data为DataFrame
data=[[1,2,3],[4,5,6],[7,8,9]]
index=['N0.%d'%i for i in range(0,3)]
columns=['语文','数学','英语']
a=pd.DataFrame(data=data,index=index,columns=columns)
c=a.pivot_table(['语文'],index='英语')
c.plot.bar()
plt.show()
5.分组与聚合
data.groupby(key, as_index=False)----data为DataFrame
- key:分组的列数据,可以多个
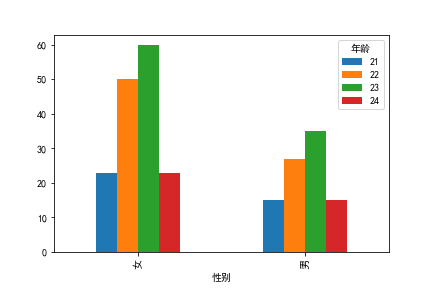
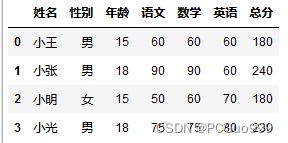
# 查看性别和年龄对语文成绩的影响
# 获取数据
data=pd.read_csv('./data/Student.csv')
# 分组聚合,按照性别分组
count=data.groupby(['性别']).count()
# 分组聚合,按照性别和年龄分组
count=data.groupby(['性别','年龄']).count()
# 画图显示,与语文成绩对比
count['语文'].plotbar()
plt.show()
五、总结测试
提取考研复试分数表信息,并查询相应信息
1.导入包以及读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置显示中文字体
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 查看性别和年龄对语文成绩的影响
# 获取数据
data=pd.read_csv('./data/Student.csv')
2.查看各科平均分
# 查看各科平均分
data[['政治','英语','数学','专业课','总分']].mean()
# 政治 68.209677
# 英语 68.383065
# 数学 114.879032
# 专业课 125.004032
# 总分 376.475806
# dtype: float64
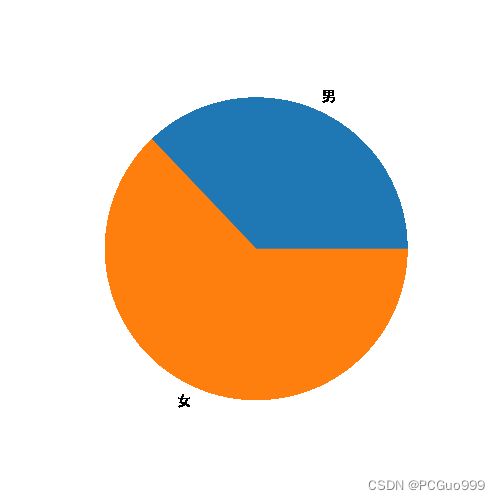
3.查看男生和女生比例
man=len(data[data['性别']=='男'])/len(data)
woman=len(data[data['性别']=='女'])/len(data)
num=[man,woman]
plt.figure(figsize=(5,5), dpi=100)
plt.pie(num,labels=['男','女'])
plt.savefig('./images/男女比例饼图.png')
plt.show()
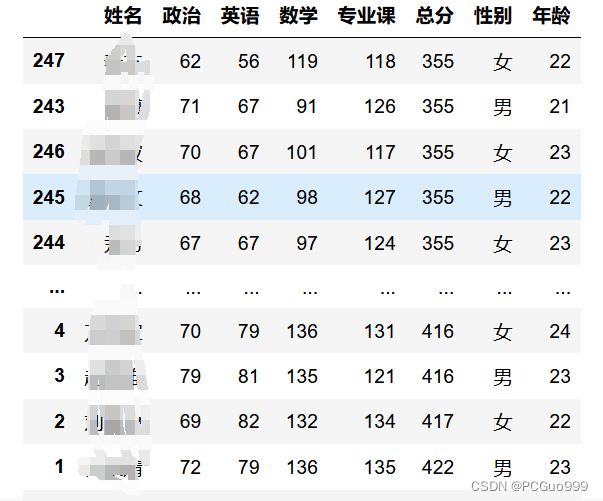
4.对数据按总分进行排序
data.sort_values(by='总分')
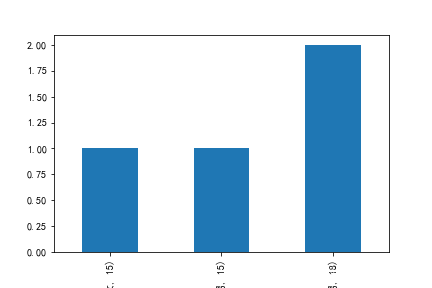
5.按年龄进行分组并与性别对比
c=pd.crosstab(data['性别'],data['年龄'])
c.plot.bar()
plt.savefig('./images/年龄与性别对比.png')
plt.show()