作者:章北海
我们的线上特征数据服务DataService,为了解决使用线程池模型导致机器cpu利用率不高,长尾请求延迟不线性(p99、p999出现J型曲线)的问题。在利用Disruptor替换线程池之后取得不错的性能结果。本文主要是简单的介绍一下对Disruptor的个人理解以及落地的结果。
背景
Disruptor是一个高性能的处理并发问题的框架,由LMAX(一个英国做金融交易的公司)设计开发用于自己金融交易系统建设。之后开源被很多知名的开源库使用,例如前段时间爆发漏洞的Log4j。
其中Log4j2使用Disruptor来优化多线程模式下的日志落盘性能,Log4j2做了一个测试使用:同步模式(Sync)、Async(ArrayBlockingQueue)、ALL_ASYNC(Disruptor)分别进行压测,得到如下测试结论:https://logging.apache.org/lo...
Disruptor模式的吞吐能力是JDK ArrayBlockQueue的12倍,是同步模式的68倍。
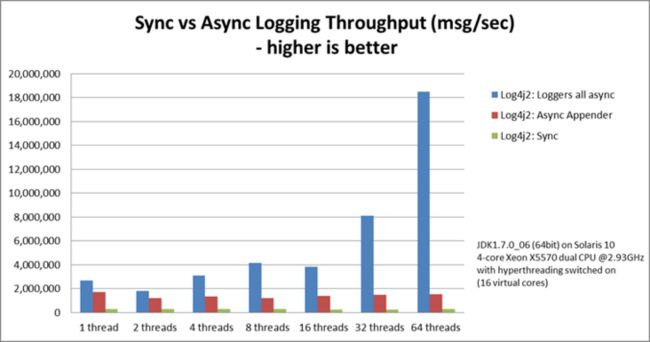
响应时间P99指标Disruptor模式比BlockQueue也更加优秀,尤其是开启了Garbage-free等优化参数之后。

通过log4j的例子看来,disruptor可以让你的系统在达到更高吞吐的同时带来更加稳定且低的响应时间。
那么为什么disruptor可以带来这些收益而jdk的线程池模式又有什么问题呢?
Disruptor介绍
LMAX是一个金融交易公司,他们的交易中有大量的生产者消费者模型业务逻辑,很自然他们将生产者产出的数据放到队列中(eg. ArrayBlockingQueue)然后开启多个消费者线程进行并发消费。
然后他们测试了一把数据在队列中传递的性能跟访问磁盘(RAID、SSD)差不多,当业务逻辑需数据要多个队列在不同的业务Stage之间传递数据时,多个串行的队列开销是不可忍受的,然后他们开始分析为什么JDK的队列会有这么严重的性能问题。
BolckQueue的问题
为什么使用BlockQueue会有这么剧烈的差别,以Java的ArrayBlockingqueue为例。底层实现其实是一个数组,在入队、出队的时候通过重入锁来保证并发情况下的队列数据的线程安全。
/**
* ArrayBlockQueue的入队实现
*/
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
checkNotNull(e);
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 全局锁
lock.lockInterruptibly();
try {
while (count == items.length) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
/**
* ArrayBlockQueue的出队实现
*/
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
/**
* Inserts element at current put position, advances, and signals.
* Call only when holding lock.
*/
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
/**
* Extracts element at current take position, advances, and signals.
* Call only when holding lock.
*/
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}可以看到ArrayBlockQueue是由一个ReentrantLock在读写时进行互斥保护,这样做会导致两个问题:
- 数据的出队、入队会互斥,不管是什么特点的应用都会频繁的引起锁碰撞。
ReentrantLock本身每次加锁可能会引起多个cas操作,而每个Cas锁操作的代价没有想象中的那么小。
- 锁状态变更触发cas操作。
- 锁竞争失败之后进入竞争队列会触发cas。
- 当持有锁线程释放之后通过Condition同步,唤醒竞争线程之后,唤醒线程出队还会导致Cas操作。
为了验证这个猜想LMAX又跑了一个测试,验证各种Lock的开销到底有多大。
他们的测试Case是将一个int64一直累加一亿次,区别只是使用单个线程、单个线程加锁(synchronize、cas)、还是多个线程加锁(synchronize、cas)。
得到的测试结果如下:https://lmax-exchange.github....,The%20Cost%20of%20Locks,-Locks%20provide%20mutual
- 当单个线程无锁执行时只需要300ms就可以完成。
- 当单个线程加锁(实际没有竞争)执行时,就需要10s。
- 单个线程使用CAS执行时比互斥锁表现好一点。
- 当线程越多,不管是互斥锁还是CAS测试Case执行的耗时越来越大。
- volatile修饰符跟CAS表现在数量级上差不多。
| Method | Time (ms) |
|---|---|
| Single thread | 300 |
| Single thread with lock | 10,000 |
| Two threads with lock | 224,000 |
| Single thread with CAS | 5,700 |
| Two threads with CAS | 30,000 |
| Single thread with volatile write | 4,700 |
这样看起来锁还有CAS操作的开销比想象中的高很多,那么具体为什么会有这么大的性能开销。
在并发环境中(在Java生态)锁的实现有两种:synchronize、cas,下面分别分析两种锁的开销。
Synchronize开销
jdk关于synchronize的介绍:https://wiki.openjdk.java.net...
在java中互斥锁就体现在synchronize关键字修饰的代码块中(synchronize在锁升级中会使用Mutex实现的,对于Linux就是pthread_mutex_t)。

内核仲裁
当synchronize关键字修饰的代码块被多个线程竞争时就需要进行用户态、内核态切换,需要系统内核仲裁竞争资源的归属,这种切换的代价是非常昂贵的(保存和恢复一些寄存器、内存数据等进程上下文数据)。
缓存污染

现在CPU都有多个核心,由于核心的计算能力远远高于内存的IO能力。为了调和处理核心跟内存的速度差异,引入了cpu缓存。当核心执行运算时如果需要内存数据先从L1缓存中获取、如果没命中就从L2缓存获取如果一直没命中就从主从中load。
当发生线程上下文切换,切换走的线程就会让出CPU让另外的线程去执行他的逻辑,而他刚刚从主存中load进来的数据就会被新的线程污染。下次他竞争成功,还是需要再次从主从中load数据,竞争会加剧缓存污染进一步影响系统性能。
从CPU到 大约需要的CPU周期 大约需要的时间 主存 - 约60-80ns QPI 总线传输(between sockets, not drawn) - 约20ns L3 cache 约40-45 cycles 约15ns L2 cache 约10 cycles 约3ns L1 cache 约3-4 cycles 约1ns 寄存器 1 cycle - 伪共享
互斥锁还会引发本身没有加锁的变量被迫互斥的问题。
CPU缓存管理的基本但是是缓存行,当cpu需要从主存中load数据时会按照缓存行的大小将对应位置的内存块一起load进去。当cpu修改内存中的数据时,也是直接修改缓存中的数据,有缓存一致性协议保证将缓存中的变动刷到内存中。
看下面这个例子:
class Eg { private int a; private int b; public void synchronize incr_a(){ a++; } public void incr_b(){ b++; } }这个对象中a、b两个字段很大概率被分配到相邻的内存中,当cpu触发缓存load时这块内存很可能会被一起加载到同一个缓存行。
当一个线程调用incr_a的同时另外一个线程调用incr_b方法时,由于incr_a被互斥锁保护导致持有a、b两个变量的缓存行也被互斥锁保护起来,这样虽然incr_b没有显示的互斥锁但实际上也被锁住了,这个现象被成为伪共享。
额外的CAS开销
在Synchronize在内部维护了count计数、对象头中有持有线程的id等变量,当线程多次进入竞争块时需要通过CAS操作去更改count计数、对象头中的线程id,所以synchronize本身还会有cas的开销。
CAS的开销
CAS是现代处理器支持的一个原子指令(例如: lock cmpxchg x86),具体的含义是当变更的变量原始值符合期望就直接更新,不符合期望就失败。
在Java中各种AutoXX类就是对CAS指令的封装,其中java的重入锁(ReentrantLock)的实现原理就是一个CAS操作。
对应Cas本身的开销问题这里可以考虑这样的一个例子:

假设位于两个核心的两个线程同时CAS一个变量a,当线程1CAS成功时将数据变更写入到缓存A中。那么这个时候线程2怎么能够感知到变量a现在的值已经发生了变更,本次CAS操作需要失败呢。
这里就需要缓存一致性协议来进行保障,需要在CAS变量的变更前后插入内存屏障来保障变量在多个核心中的可见性,这也是java volatile关键字的真实含义。
所以在最开始的那个例子中,cas操作跟volatile变量的性能表现差不多的原因,就是两者都需要进行缓存同步。
这里我们需要认识到,cas操作虽然比互斥锁性能更好但是也不是完全没有开销的。当大量的cas操作失败重试导致大量的缓存失效有时候会引发更为严重的问题。
具体的缓存一致性以及内存屏障的细节可以参考这个文章:http://www.rdrop.com/users/pa...
Disruptor的优化
LMAX在大量的测试跟深入分析之后,正视锁的开销,按照他们的业务抽象出了一套通用的可以做到无锁的并发处理框架。
组件说明
在详细介绍Disruptor之前先简单的对Disruptor的核心抽象进行说明。

| 抽象组件 | 说明 |
|---|---|
| Ring Buffer | 环形队列,用于存放生产者、消费者之间流转的事件数据 |
| Sequence | 一个自增序列,用于生产者、消费者之间存放可以被(发布、消费)的队列游标,可以简单认为是一个AutomicLong的自定义实现。 |
| Sequencer | 持有生产者、消费者的Sequence,是用于协调两边的并发问题,是Disruptor的核心组件。 |
| Sequence Barrier | 由Sequencer创建用于消费者可以跟踪到上游生产者的情况,获取可消费的事件。 |
| Wait Strategy | 用于消费者等待可消费事件时的策略,有很多实现策略。 |
| Event | 业务事件 |
| Event Processor | 业务事件消费程序,可以认为是物理线程的抽象 |
| Event Handler | 真实的业务处理逻辑,每个Processor持有一个 |
| Producer | 生产者 |
数据生产
数据的生产非常简单,有两种情况:
单生产者
单生产者的情况下,向RingBuffer中生产数据是没有任何竞争的,唯一需要注意的点是需要关注消费者的消费能力,不要覆盖了最慢的消费者未消费的数据。
为了达到这个目的,需要通过Sequencer来观察最慢的消费者的消费进度,代码如下,可以看到只有一次volatile操作全程不会有任何锁:
// 申请n个可用于发布的slot public long next(int n) { if (n < 1) { throw new IllegalArgumentException("n must be > 0"); } long nextValue = this.nextValue; long nextSequence = nextValue + n; long wrapPoint = nextSequence - bufferSize; long cachedGatingSequence = this.cachedValue; if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) { // 一次 volatile 操作 cursor.setVolatile(nextValue); // StoreLoad fence long minSequence; while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))){ // 当最慢的消费者进度低于当前需要申请的slot时,尝试唤醒消费者(唤醒策略不同表现不同,很多策略根本不会阻塞会一直spin) waitStrategy.signalAllWhenBlocking(); // park 1 纳秒继续尝试 LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin? } // 申请成功 this.cachedValue = minSequence; } this.nextValue = nextSequence; return nextSequence; }
多生产者
多生产者比较复杂的点是生产者线程之前有写竞争,需要CAS来进行协调。也就是生产者的Seq需要额外进行一个CAS操作、全程无锁,申请代码如下:
// 申请n个可发布的slot public long next(int n) { if (n < 1) { throw new IllegalArgumentException("n must be > 0"); } long current; long next; do { current = cursor.get(); next = current + n; long wrapPoint = next - bufferSize; long cachedGatingSequence = gatingSequenceCache.get(); if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) { long gatingSequence = Util.getMinimumSequence(gatingSequences, current); if (wrapPoint > gatingSequence){ // 当最慢的消费者进度低于当前需要申请的slot时,尝试唤醒消费者(唤醒策略不同表现不同,很多策略根本不会阻塞会一直spin) waitStrategy.signalAllWhenBlocking(); LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy? continue; } gatingSequenceCache.set(gatingSequence); } else if (cursor.compareAndSet(current, next)){ // 通过自旋 + cas去协调多个生产者的 break; } } while (true); return next; }虽然相比单生产者仅仅多了一个CAS操作,但是Disruptr的核心作者一直强调为了更高的吞吐以及跟稳定的延迟,单生产者的设计原则是非常有必要的,否则随着吞吐的升高长尾的请求会出现不线性的延迟增长。
具体作者的文章见:https://mechanical-sympathy.b...
数据消费
不管是单生产者、还是多生产者数据的消费都是不受影响的。Disruptor支持开启多个Processor(也就是线程),每个Processor使用类似while true的模式拉取可消费的事件进行处理。
这样的跟线程池模式的好处是避免线程创建、销毁、上下文切换代理的性能损失(缓存污染……)。
对于多个消费者之间的竞争关系通过Sequence Barrier这个抽象组件进行协调,代码见下,可以看到除等待策略可能有策略是锁实现、其他步骤全程无锁。
while (true){
try
{
// if previous sequence was processed - fetch the next sequence and set
// that we have successfully processed the previous sequence
// typically, this will be true
// this prevents the sequence getting too far forward if an exception
// is thrown from the WorkHandler
if (processedSequence)
{
processedSequence = false;
do
{
nextSequence = workSequence.get() + 1L;
// 一次 Store/Store barrier
sequence.set(nextSequence - 1L);
}
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));
// 通过自旋 + cas协调消费者进度
}
if (cachedAvailableSequence >= nextSequence){
// 批量申请slot进度高于当前进度,直接消费
event = ringBuffer.get(nextSequence);
workHandler.onEvent(event);
processedSequence = true;
}
else{
// 无消息可消费是更具不同的策略进行等待(可以阻塞、可以自旋、可以阻塞+超时……)
cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
catch (final TimeoutException e){
notifyTimeout(sequence.get());
}
catch (final AlertException ex){
if (!running.get())
{
break;
}
}
catch (final Throwable ex){
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, nextSequence, event);
processedSequence = true;
}
}可以看到最核心的生产者、消费者并发协调实现是waitStrategy,框架本身支持多种waitStrategy。
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | synchronized | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋(while true) | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + parkNanos | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | synchronized + 有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
对于以上的多种策略其实可以分为两类:
可以燃烧CPU性能,以极限高吞吐、低延迟为目标的
- YieldingWaitStrategy,不断的自旋Yield
- BusySpinWaitStrategy,不断的while true
- PhasedBackoffWaitStrategy,可以支持自定义的策略
对极限性能要求不高
- SleepingWaitStrategy,对主线程影响很小例如Log4j实现
- BlockingWaitStrategy
- TimeoutBlockingWaitStrategy
其他优化
伪共享处理
前面提到的伪共享导致的误锁以及被误杀的cpu缓存问题,也有简单的解决办法。
一般的Cache Line大小在64字节左右,然后Disruptor在非常重要的字段前后加了很多额外的无用字段。可以让这一个字段占满一整个缓存行,这样就可以避免未共享导致的误杀。

内存预分配
在Disruptor中事件对象在ringBuffer中支持预分配,在新事件到来的时候可以将关键的信息复制到预分配的结构上。避免大量事件对象代来的GC问题。
批量申请Slot
多生产、多消费者存在竞争的时候可以批量的申请多个可消费、可发布的slot,进一步减少竞争带来的CAS开销。
实际应用
在我们的特征服务系统中使用Disruptor代替原先jdk的线程池,取得了非常不错的性能结果。
测试说明
压测机器配置
配置项 配置值 机器 物理机 系统 CentOS Linux release 7.3.1611 (Core) 内存 256G内存 cpu 40核 测试Case
- 通过异步客户端访问特征服务随机查询若干特征,特征存储在(Redis、Tair、Hbase)三种外部存储中。
- 特征服务在物理机上部署单个节点。
- 测试线程池、Disruptor两个处理队列的吞吐能力、响应延迟分布。
测试结果
压测流量还是从5w/s开始逐步提高压力直到10w/s

响应时间
在同样吞吐的情况下,disruptor比线程池模式更加问题,长尾响应更少。

超时率:
超时率也是开启Disruptor之后更加稳定

参考资料
- Disruptor用户手册:https://lmax-exchange.github....
- DIsruptor technical paper :https://lmax-exchange.github....
- 但生产者模式论述:https://mechanical-sympathy.b...
- Why Memory Bairriers:http://www.rdrop.com/users/pa...
- Log4j2 Asynchronous Loggers for Low-Latency Logging: https://logging.apache.org/lo...
本文发布自网易云音乐技术团队,文章未经授权禁止任何形式的转载。我们常年招收各类技术岗位,如果你准备换工作,又恰好喜欢云音乐,那就加入我们 grp.music-fe(at)corp.netease.com!