《大数据概论》第二章自学报告
目录
数据科学的学科地位
数据科学的定义
学科定位
统计学
与数据科学的关系
统计学知识分类
行为目的与思维方式角度
方法论角度
机器学习
与数据科学的关系
常用知识
(1)基于实例学习
(2)概念学习
(3)决策树学习
(4)人工神经网络学习
(5)贝叶斯学习
(6)遗传算法
(7)分析学习
(8)增强学习
机器学习在数据科学中的应用
数据科学视角下的机器学习
数据可视化
定义
在数据科学中的重要地位
数据科学的学科地位
数据科学的定义
数据科学是一个研究领域,涉及通过使用各种科学方法,算法和过程从大量数据中提取见解。它可以帮助你从原始数据中发现隐藏的模式。数据科学其实是一个跨学科领域,允许您从结构化或非结构化数据中提取知识。使你能够将业务问题转换为研究项目,然后将其转换回实用的解决方案。
早期数据科学的统筹和应用范围主要是数学、数据学、黑客,后期与数据挖 掘相辅相成扩展到人工智能和大数据等。
学科定位
(1)“数学与统计学知识”是数据科学的主要理论基础之一
(2)“黑客精神与技能”是数据科学家的主要精神追求和技能要求——大胆创新,喜欢挑战,追求完美和不断改进。
(3)“领域实务知识”是对数据科学家的特殊要求——不仅需要掌握数学与统计知识以及具备黑客精神与技能,而且还需要精通某一领域的实务知识与经验。
统计学
与数据科学的关系
统计学是数据科学的主要理论基础之一。数据科学的理论、方法、技术和工具往往来源于统计学。统计学家在数据科学的发展中做出过突出贡献。例如,数据科学领域常用的工具之一R 语言就是统计学家发明的语言。
统计学知识分类
行为目的与思维方式角度

统计描述:采用图表或数学方法描述数据的统计特征,如分布状态,数值特征等。
推断统计:通过”样本“对”总体“进行推断分析。常用参数估计与假设检验。
| 推断方法 | 含义 | 分类 |
| 参数估计 | 根据从总体中抽取的随机样本来估计总体分布中未知参数的过程 | 点估计与区间估计 |
| 假设检验 | 先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。 | 参数假设检验,非参数假设检验 |
方法论角度

基本分析法:用于对”底层数据“进行统计分析的基本统计分析方法。例如:回归分析,分类分析,时间序列分析等。
元分析法:对于”高层数据“,尤其是对基本分析法得到的结果进行进一步分析。
机器学习
与数据科学的关系
主要议题:如何实现和优化机器的自我学习。
机器学习的基本思路:以现有的部分数据(称为训练集)为学习素材(输入),通过特定的学习方法(机器学习算法),让机器学习到(输出)能够处理更多或未来数据的新能力(称为目标函数)。在多数情况下人们很难找到目标函数的精确定义,所以,通常采用函数逼近算法进行估计目标函数。
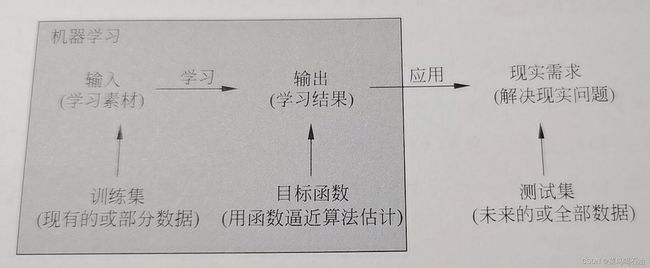
机器学习的定义:如果一个计算机系统在完成某一任务T的性能P随着经验E而改进,则称该系统在从经验E中学习,并将此系统称为一个学习系统。(学习系统三要素:任务T(下象棋),性能指标P(击败对手的概率),经验来源E(与自己进行博弈))
注意:与其他人工智能技术不同,机器学习中的“智能”并不是“预定义”的,而是计算机系统自己从“经验”中通过自主学习后得到的。机器学习的理论基础涉及多个学科领域,包括人工智能、贝叶斯方法、计算复杂性理论、控制论、信息论、哲学、心理学与神经生物学、统计学等
常用知识

(1)基于实例学习
实现将训练样本存储下来,然后每当遇到一个新增查询实例时,学习系统分析此新增实例与以前存储的实例之间的关系,并据此把一个目标函数值赋给新增实例。常用的方法:K近邻方法,局部加权回归算法,基于案例的推理。
(2)概念学习
定义:就是学习把具有共同属性的事物集合在一起并冠以一个名称,把不具有此类属性的事物排除出去。
条件:提供概念范例;利用概念间的联系构图;消除错误概念;在实践中运用概念。
学习过程:获得概念有两种形式,即概念的形成和概念的同化→在认知活动中发挥作用,并认知活动产生影响。
(3)决策树学习
决策树学习 的本质是一种遁近离散值目标函数的过程。决策树代表的是一种分类过程
●根节点:代表分类的开始。
●叶节点:代表一个实例的结束。
●中间节点:代表相应实例的某一个属性。
●节点之间的边:代表某一个属性的属性值。
●从根节点到叶节点的每条路径:代表一个具体的实例,同一个路径上的所有属性之间是“逻辑与”关系 。
从根节点开始,按照给定实例的属性值判断对应的树枝,并依次下移,直到点为止。绝大多数的决策树学习算法都是基于ID3算法设计出来的.
(4)人工神经网络学习
人工神经网络( Artificial Neural Network , ANN )学习借鉴了生物学的一小部分简单理论,其目的是从训练样本中学习到目标函数。根据生物学的观点,学习系统是由相互连接的神经( Neuron )组成的复杂网络。与生物学习系统类似,人工神经网络也是由一系列比较简单的人工神经元相互连接的方式形成的网状结构。人工神经元是人工神经网络的最基本的组成部分。
(5)贝叶斯学习
利用参数的先验分布,由样本信息求来的后验分布,直接求出总体分布。
朴素贝叶斯分类器是最基本的,也是最有用的贝叶斯学习方法之一。通常,可以达到人工神经网络和决策树学习的水平。
(6)遗传算法
定义:主要研究的问题是“从候选假设空间中搜索出最佳假设”。此处,“最佳假设”指“适应度( Fitness )”指标为最优的假设。其中。“适应度”是为当前问题预先定义的一个评价度量值。
实现方式:均具备一个共同结构——遗传算法的总体。遗传算法借鉴的生物进化的三个基本原则——适者生存、两性繁衍及突变。分别对应遗传算法的三个基本算子:选择、交叉和突变。
(7)分析学习
定义:分析学习是相对于归纳学习的一种提法,其特点是使用先验知识来分析或解释每个训练样本,以推理出样本的哪些特征与目标函数相关或不相关。因此,这些解释能使机器学习系统比单独依靠数据进行泛化有更高的精度。
实现:分析学习使用先验知识来减小待搜索假设空间的复杂度,减小了样本复杂度并提高了机器学习系统的泛化精度。
(8)增强学习
研究的问题:一个能感知环境的自治agent,怎样通过学习选择能达到其目标的最优动作。
目的:从有延迟的回报中学习”控制策略“,以便后续的动作产生最大的累计回报。
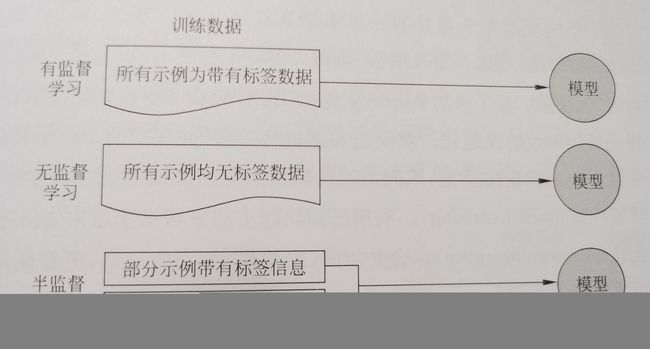
分类:监督学习,无监督学习,半监督学习。
机器学习在数据科学中的应用
IBM Watson 是一款基于 IBM DeepQA 架构,并运行在基于 IBM POWER7处理器的服务器中的工作负载优化系统,在机器学习和认知计算领域具有重要地位。
(1)机器学习的应用:命中列表 。问题分类。迁移学习 。答案合并 。最优答案选择 。证据扩散 。多项答案 。
(2)机器学习与其他技术的集成应用:统计分析。信息检索。
自然语言处理。知识表示与推理。人机接口 等相关知识领域的融合,较好地反映了这些不同技术的集成化应用趋势。
数据科学视角下的机器学习
目前仍存在的挑战:
过拟合:目标函数在训练集上的准确率高,在测试集的效率却很低。
维度灾难:在高纬度空间数据上效果底,甚至不可行。
特征工程:实际数据处理中,往往需要分析训练集的样本特征——分类标签特征。
算法的可扩展性:硬件,软件以及训练集上的可扩展性。
模型集成:将多个模型进行集成处理。
数据可视化
定义
指的是技术上较为高级的技术方法,而这些技术方法允许利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。
在数据科学中的重要地位
(1)视觉感知是人类大脑的最主要途径:视觉感知是人类大脑的最主要功能之一;眼睛是感知信息能力最强的人体器官之一。
(2)相对于统计分析,数据可视化的主要优势体现在:数据可视化处理可以洞察统计分析无法发现的结构和细节;数据可视化结果的解读对用户知识水平的要求较低。
(3)可视化可以帮助人类提高理解与处理数据的效率。
(4)在人类数据处理和科学技术的发展中扮演着重要的角色。