- javaweb学习Day10
乐一粒学编程
学习java开发语言
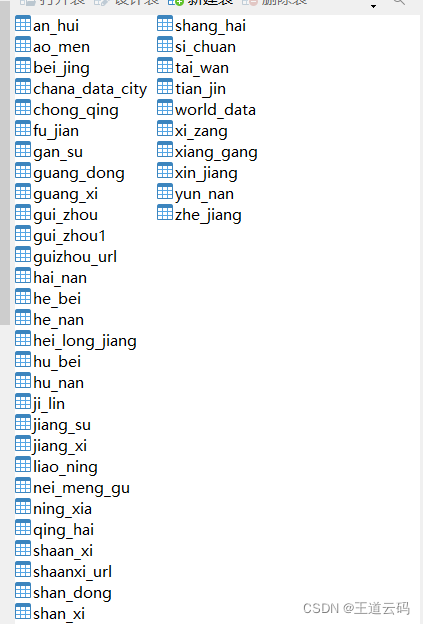
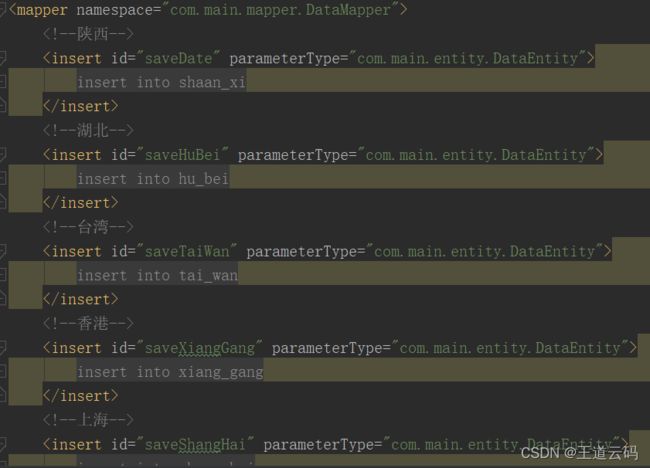
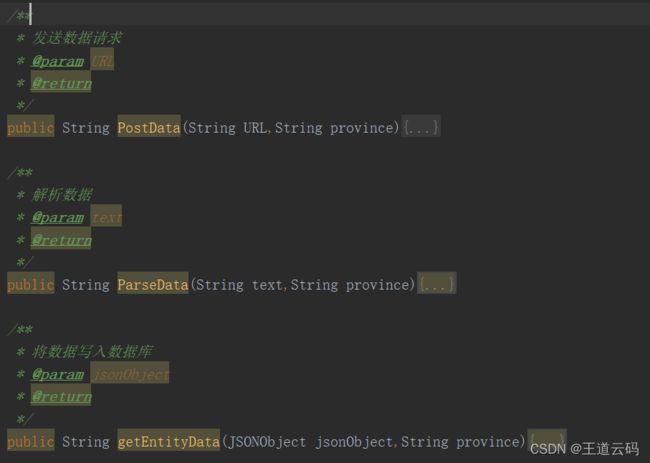
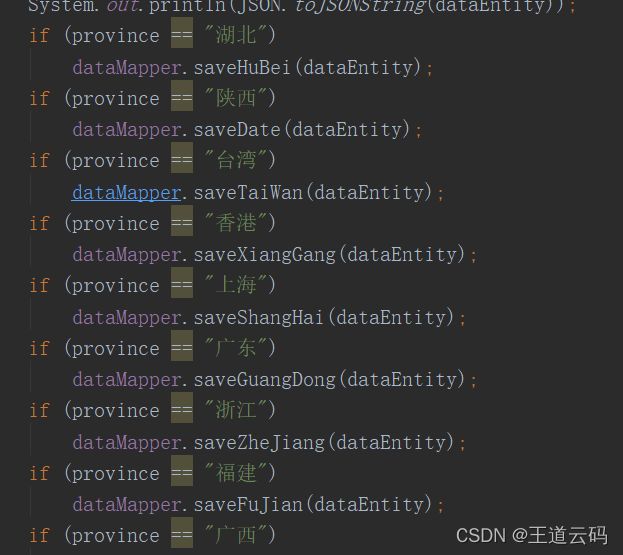
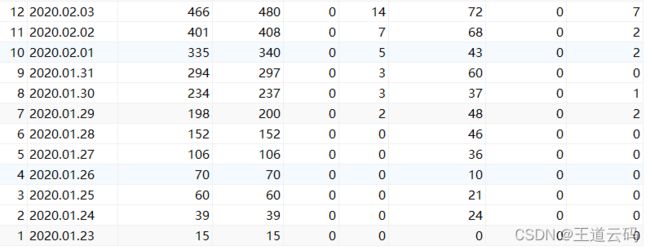
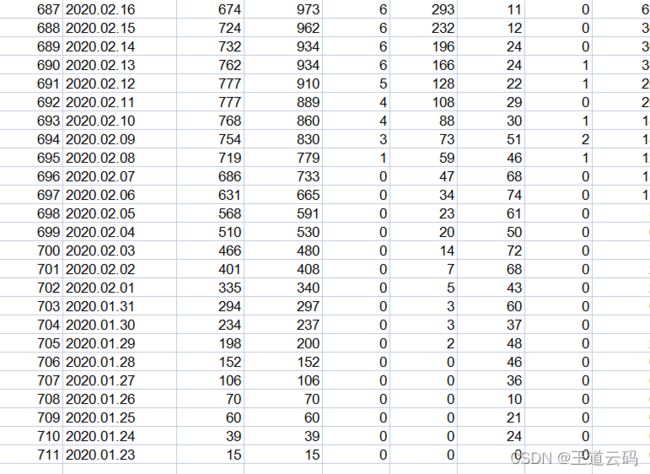
来源:尚硅谷2022版javaweb今日内容:1.日期和字符串之间的格式化//String->java.util.DateStringdateStr1="2021-12-3012:59:59";SimpleDateFormatsdf=newSimpleDateFormat("yyyy-MM-ddHH:mm:ss");try{Datedate1=sdf.parse(dateStr1);}catch(
- Python爬虫:数据抓取工具及类库详解
2401_84692751
程序员python爬虫开发语言
wget也是一个利用URL语法在命令行环境下进行文件传输的工具,其基本用法为wget[URL地址][参数],如:wgethttps://www.baidu.com其常用参数如下:下面例子演示如何使用wget镜像一个网站到本地并启动:使用wget--mirror命令将整个网站的镜像下载到本地wget--mirror-p--convert-linkshttp://www.httpbin.org切换到下
- Java 中 final 与 effectively final
yaoxin521123
【原来如此】java开发语言
Java中final与effectivelyfinal一、为什么我们需要final和effectivelyfinal?为什么这些关键字重要?在Java中,一些变量需要在初始化后不再变化,以确保程序的安全性和可读性。为什么你需要关心final和effectivelyfinal?防止变量进一步修改导致的不可控度问题。提高代码可读性和维护性。对于区别final和effectivelyfinal来说,懂得
- Java面试黄金宝典5
ylfhpy
Java面试黄金宝典java面试开发语言职场和发展算法
1.ConcurrentHashMap和HashTable有哪些区别原理HashTable:它继承自Dictionary类,是Java早期提供的线程安全哈希表。其线程安全的实现方式是对每个方法都使用synchronized关键字进行同步。例如,在调用put、get等方法时,整个HashTable会被锁定,其他线程必须等待当前线程释放锁后才能访问该方法。javaimportjava.util.Has
- Java基础面试题学习
PowerCloud
java学习开发语言
转换成自已的语言来回答,来源小林coding、沉默王二以及其它资源和自已改编。1、概念1、说一下Java的特点我认为Java有很多特点首先是平台无关性:Java可以实现一次编译到处运行,因为Java的编译器将源代码编译成字节码,使得该字节码可以在任意装有JVM的操作系统上运行。其次是面向对象的性质:Java是面向对象编程语言,这种OOP的特性使得代码易于维护和重用。主要源于封装继承多态这三大特性。
- Java复习路线
Code good g
面试准备javamysql数据库
Java复习1、Java基础2、Java多线程3、Javaweb的复习4、MySql复习数据库常用的代码:思维导图:5、计算机组成原理6、网络编程7、Java注解和反射8、计算机网络9、html/css/js10、ssm11、spring12、springmvc13、springboot14、vue15、springcloud16、jvm17、Juc18、mybatis-plus学习19、git2
- 基于LangChain-Chatchat实现智能问答系统
2301_79125431
java
题解|#统计输入正数个数#5.6importjava.util.*;publicclassMain{publics广汽丰田发动机薪酬福利待遇1、工作时间:基本上为5天8小时工作制;2、薪资结构:基本工资+加班工资+各类补贴津贴+各类慰问金+小红书24届春招和25届实习,内部推荐小红书24届春招和25届实习,推荐码为:0T019BWYNARK,内推码仅适用于校招内推及微信小程序题解|#试卷发布当天作
- 23种设计模式-抽象工厂(Abstract Factory)设计模式
程序员汉升
#设计模式设计模式java抽象工厂模式
抽象工厂设计模式什么是抽象工厂设计模式?抽象工厂模式的特点抽象工厂模式的结构抽象工厂模式的优缺点抽象工厂方法的Java实现代码总结总结什么是抽象工厂设计模式?抽象工厂模式(AbstractFactoryDesignPattern)是一种创建型设计模式,它提供了一种方式来创建一系列相关或相互依赖的对象,而无需指定它们的具体类。与工厂方法模式的区别在于,抽象工厂模式通常用于处理产品族的创建,确保创建的
- Caffeine vs Guava Cache:性能巅峰对决,谁才是 Java 本地缓存之王?
Julian.zhou
Java开发基础技能缓存java算法
CaffeinevsGuavaCache:性能巅峰对决,谁才是Java本地缓存之王?导语:在Java本地缓存的战场上,Caffeine和GuavaCache是开发者最常用的两大神器。但究竟谁的性能更胜一筹?为何Caffeine被称为“GuavaCache的终结者”?本文通过算法原理、并发性能、内存管理、实战测试四大维度,彻底揭秘两者的性能差异,文末附迁移指南和选型建议!一、核心差异:算法与淘汰策略
- nginx助力打包部署
潜意识Java
Java知识javanginx开发语言
目录一、打包部署基础入门(一)为什n么要打包部署(二)打包部署的基本流程二、Java项目打包(一)使用Maven进行打包(二)使用Gradle进行打包三、服务器环境准备(一)选择合适的服务器(二)安装Java运行环境四、Nginx初相识(一)Nginx是什么(二)Nginx的安装五、Nginx配置Java项目反向代理(一)反向代理的概念(二)Nginx反向代理配置示例六、Nginx实现负载均衡(一
- java面试题,既然你说到了创建线程池,那么你知道创建线程池的方式有哪几种吗?
java程序员CC
java开发语言
在Java中,创建线程池的方式有多种,其中比较常用的方式包括:FixedThreadPool(固定大小线程池):通过Executors.newFixedThreadPool(intn)方法创建,线程池中的线程数量固定为n,适合处理任务量稳定的场景。CachedThreadPool(缓存线程池):通过Executors.newCachedThreadPool()方法创建,线程池的线程数量不固定,根据
- java集合List,Set,Map怎么理解存储数据有序,无序以及可重复,不可重复
java程序员CC
JAVA基础java面试list
学习java已经有一段时间了,在练习开发项目的过程中经常用到List和Map却不知道其到底有何区别,今天整理了一下知识点对这几个进行浅显易懂的区分。PS:本文中的“有序”指的是存储数据时输入顺序与数据输出顺序相等,“唯一”:指的是不重复首先我们知道java集合有两个接口;一个是Collection,一个是Map;其中Colection衍生出了两个子接口也就是平时我们常见的--List【有序,不唯一
- 定时任务调度框架xxl-job与quartz的区别
java程序员CC
java
XXL-Job和Quartz都是Java项目中常用的定时任务框架,它们有以下几点区别:xxl-job和Quartz都是用于任务调度的开源框架,它们之间有一些区别,主要体现在以下几个方面:语言支持:Quartz主要是基于Java的任务调度框架,支持Java语言。xxl-job是一个分布式任务调度平台,它提供了Java版本的调度中心,同时还提供了Python、PHP等语言的任务执行器,因此支持多种语言
- springboot poi 后端手撕excel自定义表格。包括插入列表、跨行跨列合并
uutale
java应用springbootexcel后端
文章目录前言一、成品展示二、引入二、RestTemplateConfig三、接收实体ReturnResponse四、WriteExcelTableController总结前言这个程序是因为我需要根据数据库返回的数据生成excel,涉及到跨行跨列合并,表格list填充。填充后调用另一个项目的上传接口,把文件转成字节流传输过去,你们在自己进行使用的时候可以把字节流转成file存到本地。这里的代码有很多
- HashSet 扩容的底层机制说明
WH牛
java开发语言
目录1.扩容机制说明2.底层机制说明1.扩容机制说明扩容机制:HashSet的底层就是HashMap(底层是数组+链表/红黑树),当添加元素时先得到其hash值再转换成索引,找到存取数据的table,看这个位置是否已经存放了元素,如果没有,则直接存放,如果有,调用equals后看是否相同,如果不相同,则放在则添加到最后,相同则放弃添加。在Java8中一条链表的元素个数达到默认值8,并且table数
- Java自定义分数类,可以实现分数的自由运算
zhan114514
java开发语言
/***分数对象的类,有分数相关计算*以String为值,(String)value=(int)up+"/"+(int)down*@authorZhan*/publicclassFraction{//分数标准staticfinalStringstandard1="-?\\d+/-?\\d+";//有分母staticfinalStringstandard2="-?\\d+";//无分母//值Stri
- Tinyflow AI 工作流编排框架 v0.0.7 发布
自不量力的A同学
人工智能
目前没有关于TinyflowAI工作流编排框架v0.0.7发布的相关具体信息。Tinyflow是一个轻量的AI智能体流程编排解决方案,其设计理念是“简单、灵活、无侵入性”。它基于WebComponent开发,前端支持与React、Vue等任何框架集成,后端支持Java、Node.js、Python等语言,助力传统应用快速AI转型。该框架代码库轻量,学习成本低,能轻松应对简单任务编排和复杂多模态推理
- 【微服务架构】SpringCloud(二):Eureka原理、服务注册、Euraka单独使用
道友老李
架构师进阶-微服务架构#SpringCloud架构微服务springcloud
文章目录SpringCloudEureka原理RegisterRenewFetchRegistryCancelTimeLagCommunicationmechanism服务注册客户端配置选项服务器端配置选项Eureka单独使用Rest服务调用/eureka/status服务状态注册到eureka的服务信息查看注册到eureka的具体的服务查看服务续约更改服务状态删除状态更新删除服务元数据客户端个人
- 【保姆级】阿里云codeup配置Git的CI/CD步骤
CodeCaptain
阿里云GitLabDevOps阿里云gitci/cd
以下是通过阿里云CodeUp的Git仓库进行CI/CD配置的详细步骤,涵盖前端(Vue3)和后端(SpringBoot)项目的自动化打包,并将前端打包结果嵌入到Nginx的Docker镜像中,以及将后端打包的JAR文件拷贝至Docker指定目录的完整流程:前提条件阿里云账号:已注册并登录阿里云CodeUp。项目代码:前端(Vue3)和后端(SpringBoot)项目代码已托管到CodeUp仓库。D
- 对象的行为-状态影响行为,行为影响状态
Java版蜡笔小新
java学习开发语言
小白Java学习记录4一周掌握Java入门知识学习内容:对象的行为学习产出:你可以传值给方法d.bark(3);方法会运用形参。调用的一方会传入实参。实参是传给方法的值。当传入放后就成了形参。参数跟局部(local)变量是一样的。它有类型与名称,可以在方法内运用。重点是:如果某个方法需要参数,你就一定得传东西给它。那个东西得是适当类型的值。Dogd=newDog();d.bark(3);voidb
- Java直通车系列46【Spring Cloud】(服务监控与追踪Spring Cloud Sleuth 和 Zipkin)
浪九天
Java直通车javaspring开发语言后端springcloud
目录服务监控与追踪(SpringCloudSleuth和Zipkin)一、为什么需要服务监控与追踪?二、核心工具:SpringCloudSleuth+Zipkin三、场景示例:电商下单调用链追踪场景描述:使用Sleuth+Zipkin的追踪流程:四、高级功能与优化五、适用场景六、总结服务监控与追踪(SpringCloudSleuth和Zipkin)一、为什么需要服务监控与追踪?在微服务架构中,一个
- 记录华为OBS文件上传下载多种方式
yychen_java
java华为javaspring
公司要从阿里的oss切换到华为的obs,为了尽量小代价的改动,所以想找和阿里一样上传的方式,之前阿里做的是后端生成文件上传的url,前端做上传动作,这里记录一下obs的多种上传方式。直接上代码:1、获取OBS配置引入mavencom.huaweicloudesdk-obs-java3.21.11其中的各种配置自己在华为平台找到哦。importcom.obs.services.ObsClient;i
- Form表单的三种提交和http请求的三种传参方式,以及Servlet里的取取参方式
哥谭居民0001
httpservlet网络协议
多表单多用于文件上传,因为toacat的实现机制,涉及到了将参数数据临时存储到磁盘上,取的时候只能取字节流get和post虽然在http请求里带参的位置不同但是javaSE里对于HttpServletRequest这个对象定义,这两种传参的取参方式相同假设有一个表单,用户输入了用户名kimi和年龄25,提交GET请求后,URL会变成:http://example.com/FormSubmitSer
- JAVA————十五万字汇总
MeyrlNotFound
java开发语言
JAVA语言概述JAVA语句结构JAVA面向对象程序设计(一)JAVA面向对象程序设计(二)JAVA面向对象程序设计(三)工具类的实现JAVA面向对象程序设计(四)录入异常处理JAVA图形用户界面设计JAVA系统主界面设计JAVA图形绘制JAVA电子相册JAVA数据库技术(一)JAVA数据库技术(二)JAVA数据库技术(三)拓展:JAVA导入/导出——输入/输出JAVA网络通信JAVA多线程编程技
- 在虚拟机上安装Hadoop
杜清卿
hadoop
基本步骤与安装java一致:先用finalshell将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面,然后解压,最后配置环境变量。1.使用finalshell上传。这里直接鼠标拖动操作即可。2.解压。进入到Hadoop安装包路径下,cd/opt/software/,再解压安装文件到/opt/module下,对应的命令是:tar-zxvfhadoop-.1.3
- 使用 Resilience4j 实现重试
树懒_Zz
Springspringcloudspringbootspring
在本文中,我们将首先简要介绍Resilience4j,然后深入研究其重试模块。我们将了解何时以及如何使用它,以及它提供哪些功能.什么是Resilience4j?应用程序通过网络通信时,许多事情都可能出错。由于连接中断、网络故障、上游服务不可用等原因,操作可能会超时或失败。应用程序可能会相互过载、无响应,甚至崩溃。Resilience4j是一个Java库,可帮助我们构建具有弹性和容错能力的应用程序。
- Tomcat从入门到精通:全方位深度解析与实战教程
墨瑾轩
一起学学Java【一】运维tomcatjava
一、Tomcat入门1.Tomcat简介ApacheTomcat,简称Tomcat,是一个开源的轻量级应用服务器,专为运行JavaServlet和JavaServerPages(JSP)技术设计。它是JavaWeb开发中最常用的Servlet容器之一,遵循JavaServlet和JavaServerPages规范,为开发者提供了一个稳定的、易于使用的部署环境。2.安装与启动安装下载最新版Tomca
- Apache Tomcat 远程代码执行漏洞复现(CVE-2025-24813)(附脚本)
iSee857
漏洞复现apachetomcatjavaweb安全安全
免责申明:本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。0x01产品描述:ApacheTomcat是一个开源的JavaServlet容器和Web服务器,支持运行JavaServlet、JavaServerP
- 深入剖析 Spring Boot 应用上下文 (Application Context):核心概念与实践应用
无眠_
springbootjavarpc
深入剖析SpringBoot应用上下文(ApplicationContext):核心概念与实践应用引言在SpringBoot的世界里,应用上下文(ApplicationContext)扮演着至关重要的角色。它不仅是Spring框架的核心容器,负责管理应用中所有Bean的生命周期和依赖关系,更是SpringBoot应用得以运行的基础环境。理解ApplicationContext的概念、作用和工作原理
- Spring Boot 外部化配置 (Externalized Configuration) 超详解:灵活管理应用配置,打造可移植、可扩展的应用
无眠_
springboot数据库oracle
引言在SpringBoot应用开发中,配置管理是至关重要的环节。不同的环境(开发、测试、生产)通常需要不同的配置参数,例如数据库连接、端口号、日志级别、第三方API密钥等等。SpringBoot外部化配置(ExternalizedConfiguration)提供了一套强大的机制,允许我们将应用的配置从代码中解耦出来,并通过多种外部来源进行灵活管理,从而打造出可移植、可扩展、易于维护的SpringB
- PHP,安卓,UI,java,linux视频教程合集
cocos2d-x小菜
javaUIlinuxPHPandroid
╔-----------------------------------╗┆
- zookeeper admin 笔记
braveCS
zookeeper
Required Software
1) JDK>=1.6
2)推荐使用ensemble的ZooKeeper(至少3台),并run on separate machines
3)在Yahoo!,zk配置在特定的RHEL boxes里,2个cpu,2G内存,80G硬盘
数据和日志目录
1)数据目录里的文件是zk节点的持久化备份,包括快照和事务日
- Spring配置多个连接池
easterfly
spring
项目中需要同时连接多个数据库的时候,如何才能在需要用到哪个数据库就连接哪个数据库呢?
Spring中有关于dataSource的配置:
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"
&nb
- Mysql
171815164
mysql
例如,你想myuser使用mypassword从任何主机连接到mysql服务器的话。
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%'IDENTIFIED BY 'mypassword' WI
TH GRANT OPTION;
如果你想允许用户myuser从ip为192.168.1.6的主机连接到mysql服务器,并使用mypassword作
- CommonDAO(公共/基础DAO)
g21121
DAO
好久没有更新博客了,最近一段时间工作比较忙,所以请见谅,无论你是爱看呢还是爱看呢还是爱看呢,总之或许对你有些帮助。
DAO(Data Access Object)是一个数据访问(顾名思义就是与数据库打交道)接口,DAO一般在业
- 直言有讳
永夜-极光
感悟随笔
1.转载地址:http://blog.csdn.net/jasonblog/article/details/10813313
精华:
“直言有讳”是阿里巴巴提倡的一种观念,而我在此之前并没有很深刻的认识。为什么呢?就好比是读书时候做阅读理解,我喜欢我自己的解读,并不喜欢老师给的意思。在这里也是。我自己坚持的原则是互相尊重,我觉得阿里巴巴很多价值观其实是基本的做人
- 安装CentOS 7 和Win 7后,Win7 引导丢失
随便小屋
centos
一般安装双系统的顺序是先装Win7,然后在安装CentOS,这样CentOS可以引导WIN 7启动。但安装CentOS7后,却找不到Win7 的引导,稍微修改一点东西即可。
一、首先具有root 的权限。
即进入Terminal后输入命令su,然后输入密码即可
二、利用vim编辑器打开/boot/grub2/grub.cfg文件进行修改
v
- Oracle备份与恢复案例
aijuans
oracle
Oracle备份与恢复案例
一. 理解什么是数据库恢复当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重构这个完整的数据库,该处理称为数据库恢复。恢复过程大致可以分为复原(Restore)与
- JavaEE开源快速开发平台G4Studio v5.0发布
無為子
我非常高兴地宣布,今天我们最新的JavaEE开源快速开发平台G4Studio_V5.0版本已经正式发布。
访问G4Studio网站
http://www.g4it.org
2013-04-06 发布G4Studio_V5.0版本
功能新增
(1). 新增了调用Oracle存储过程返回游标,并将游标映射为Java List集合对象的标
- Oracle显示根据高考分数模拟录取
百合不是茶
PL/SQL编程oracle例子模拟高考录取学习交流
题目要求:
1,创建student表和result表
2,pl/sql对学生的成绩数据进行处理
3,处理的逻辑是根据每门专业课的最低分线和总分的最低分数线自动的将录取和落选
1,创建student表,和result表
学生信息表;
create table student(
student_id number primary key,--学生id
- 优秀的领导与差劲的领导
bijian1013
领导管理团队
责任
优秀的领导:优秀的领导总是对他所负责的项目担负起责任。如果项目不幸失败了,那么他知道该受责备的人是他自己,并且敢于承认错误。
差劲的领导:差劲的领导觉得这不是他的问题,因此他会想方设法证明是他的团队不行,或是将责任归咎于团队中他不喜欢的那几个成员身上。
努力工作
优秀的领导:团队领导应该是团队成员的榜样。至少,他应该与团队中的其他成员一样努力工作。这仅仅因为他
- js函数在浏览器下的兼容
Bill_chen
jquery浏览器IEDWRext
做前端开发的工程师,少不了要用FF进行测试,纯js函数在不同浏览器下,名称也可能不同。对于IE6和FF,取得下一结点的函数就不尽相同:
IE6:node.nextSibling,对于FF是不能识别的;
FF:node.nextElementSibling,对于IE是不能识别的;
兼容解决方式:var Div = node.nextSibl
- 【JVM四】老年代垃圾回收:吞吐量垃圾收集器(Throughput GC)
bit1129
垃圾回收
吞吐量与用户线程暂停时间
衡量垃圾回收算法优劣的指标有两个:
吞吐量越高,则算法越好
暂停时间越短,则算法越好
首先说明吞吐量和暂停时间的含义。
垃圾回收时,JVM会启动几个特定的GC线程来完成垃圾回收的任务,这些GC线程与应用的用户线程产生竞争关系,共同竞争处理器资源以及CPU的执行时间。GC线程不会对用户带来的任何价值,因此,好的GC应该占
- J2EE监听器和过滤器基础
白糖_
J2EE
Servlet程序由Servlet,Filter和Listener组成,其中监听器用来监听Servlet容器上下文。
监听器通常分三类:基于Servlet上下文的ServletContex监听,基于会话的HttpSession监听和基于请求的ServletRequest监听。
ServletContex监听器
ServletContex又叫application
- 博弈AngularJS讲义(16) - 提供者
boyitech
jsAngularJSapiAngularProvider
Angular框架提供了强大的依赖注入机制,这一切都是有注入器(injector)完成. 注入器会自动实例化服务组件和符合Angular API规则的特殊对象,例如控制器,指令,过滤器动画等。
那注入器怎么知道如何去创建这些特殊的对象呢? Angular提供了5种方式让注入器创建对象,其中最基础的方式就是提供者(provider), 其余四种方式(Value, Fac
- java-写一函数f(a,b),它带有两个字符串参数并返回一串字符,该字符串只包含在两个串中都有的并按照在a中的顺序。
bylijinnan
java
public class CommonSubSequence {
/**
* 题目:写一函数f(a,b),它带有两个字符串参数并返回一串字符,该字符串只包含在两个串中都有的并按照在a中的顺序。
* 写一个版本算法复杂度O(N^2)和一个O(N) 。
*
* O(N^2):对于a中的每个字符,遍历b中的每个字符,如果相同,则拷贝到新字符串中。
* O(
- sqlserver 2000 无法验证产品密钥
Chen.H
sqlwindowsSQL ServerMicrosoft
在 Service Pack 4 (SP 4), 是运行 Microsoft Windows Server 2003、 Microsoft Windows Storage Server 2003 或 Microsoft Windows 2000 服务器上您尝试安装 Microsoft SQL Server 2000 通过卷许可协议 (VLA) 媒体。 这样做, 收到以下错误信息CD KEY的 SQ
- [新概念武器]气象战争
comsci
气象战争的发动者必须是拥有发射深空航天器能力的国家或者组织....
原因如下:
地球上的气候变化和大气层中的云层涡旋场有密切的关系,而维持一个在大气层某个层次
- oracle 中 rollup、cube、grouping 使用详解
daizj
oraclegroupingrollupcube
oracle 中 rollup、cube、grouping 使用详解 -- 使用oracle 样例表演示 转自namesliu
-- 使用oracle 的样列库,演示 rollup, cube, grouping 的用法与使用场景
--- ROLLUP , 为了理解分组的成员数量,我增加了 分组的计数 COUNT(SAL)
- 技术资料汇总分享
Dead_knight
技术资料汇总 分享
本人汇总的技术资料,分享出来,希望对大家有用。
http://pan.baidu.com/s/1jGr56uE
资料主要包含:
Workflow->工作流相关理论、框架(OSWorkflow、JBPM、Activiti、fireflow...)
Security->java安全相关资料(SSL、SSO、SpringSecurity、Shiro、JAAS...)
Ser
- 初一下学期难记忆单词背诵第一课
dcj3sjt126com
englishword
could 能够
minute 分钟
Tuesday 星期二
February 二月
eighteenth 第十八
listen 听
careful 小心的,仔细的
short 短的
heavy 重的
empty 空的
certainly 当然
carry 携带;搬运
tape 磁带
basket 蓝子
bottle 瓶
juice 汁,果汁
head 头;头部
- 截取视图的图片, 然后分享出去
dcj3sjt126com
OSObjective-C
OS 7 has a new method that allows you to draw a view hierarchy into the current graphics context. This can be used to get an UIImage very fast.
I implemented a category method on UIView to get the vi
- MySql重置密码
fanxiaolong
MySql重置密码
方法一:
在my.ini的[mysqld]字段加入:
skip-grant-tables
重启mysql服务,这时的mysql不需要密码即可登录数据库
然后进入mysql
mysql>use mysql;
mysql>更新 user set password=password('新密码') WHERE User='root';
mysq
- Ehcache(03)——Ehcache中储存缓存的方式
234390216
ehcacheMemoryStoreDiskStore存储驱除策略
Ehcache中储存缓存的方式
目录
1 堆内存(MemoryStore)
1.1 指定可用内存
1.2 驱除策略
1.3 元素过期
2 &nbs
- spring mvc中的@propertysource
jackyrong
spring mvc
在spring mvc中,在配置文件中的东西,可以在java代码中通过注解进行读取了:
@PropertySource 在spring 3.1中开始引入
比如有配置文件
config.properties
mongodb.url=1.2.3.4
mongodb.db=hello
则代码中
@PropertySource(&
- 重学单例模式
lanqiu17
单例Singleton模式
最近在重新学习设计模式,感觉对模式理解更加深刻。觉得有必要记下来。
第一个学的就是单例模式,单例模式估计是最好理解的模式了。它的作用就是防止外部创建实例,保证只有一个实例。
单例模式的常用实现方式有两种,就人们熟知的饱汉式与饥汉式,具体就不多说了。这里说下其他的实现方式
静态内部类方式:
package test.pattern.singleton.statics;
publ
- .NET开源核心运行时,且行且珍惜
netcome
java.net开源
背景
2014年11月12日,ASP.NET之父、微软云计算与企业级产品工程部执行副总裁Scott Guthrie,在Connect全球开发者在线会议上宣布,微软将开源全部.NET核心运行时,并将.NET 扩展为可在 Linux 和 Mac OS 平台上运行。.NET核心运行时将基于MIT开源许可协议发布,其中将包括执行.NET代码所需的一切项目——CLR、JIT编译器、垃圾收集器(GC)和核心
- 使用oscahe缓存技术减少与数据库的频繁交互
Everyday都不同
Web高并发oscahe缓存
此前一直不知道缓存的具体实现,只知道是把数据存储在内存中,以便下次直接从内存中读取。对于缓存的使用也没有概念,觉得缓存技术是一个比较”神秘陌生“的领域。但最近要用到缓存技术,发现还是很有必要一探究竟的。
缓存技术使用背景:一般来说,对于web项目,如果我们要什么数据直接jdbc查库好了,但是在遇到高并发的情形下,不可能每一次都是去查数据库,因为这样在高并发的情形下显得不太合理——
- Spring+Mybatis 手动控制事务
toknowme
mybatis
@Override
public boolean testDelete(String jobCode) throws Exception {
boolean flag = false;
&nbs
- 菜鸟级的android程序员面试时候需要掌握的知识点
xp9802
android
熟悉Android开发架构和API调用
掌握APP适应不同型号手机屏幕开发技巧
熟悉Android下的数据存储
熟练Android Debug Bridge Tool
熟练Eclipse/ADT及相关工具
熟悉Android框架原理及Activity生命周期
熟练进行Android UI布局
熟练使用SQLite数据库;
熟悉Android下网络通信机制,S