numpy与pandas各种功能及其对比(超全)
在做数据处理的时候经常会用到numpy和pandas,有时候容易搞混,这篇文章就从功能方面总结对比一下二者的区别。
一、简介
numpy:numpy是以矩阵为基础的数学计算模块,提供高性能的矩阵运算,数组结构为ndarray。可以把它看作是多维数组(ndarray)的容器,可以对数组执行元素级计算以及直接对数组执行数学运算的函数。其也是用于读写硬盘上基于数组的数据集的工具。数据处理速度比Python自身的嵌套列表要快很多。ndarray中所有元素必须是相同类型。
pandas:pandas是基于numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。pandas数组结构有一维Series和二维DataFrame。
二、创建数据
1.数据结构
在开始创建数据之前,再说明一下两种方法创建的数据结构形式
numpy:是通用的同构数据多维容器,其中的所有元素必须是相同类型的
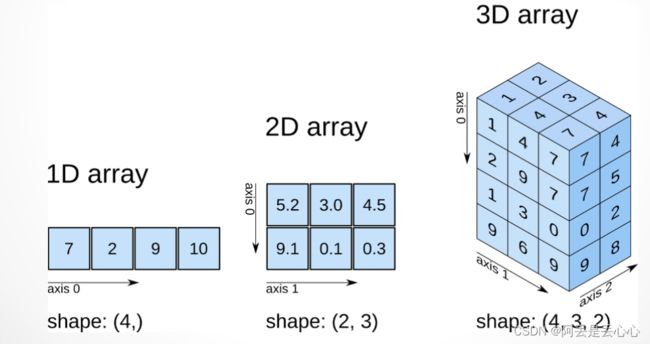
pandas:一维数据结构为series,多维是dataframe
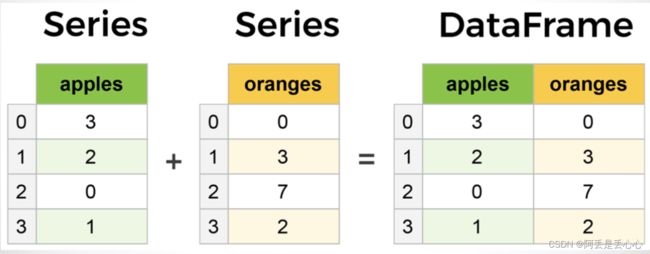
其中:
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,索引在左边,值在右边。

DataFrame是一个表格型的数据结构,既有行索引(index)也有列索引(columns),它可以被看做由Series组成的字典(共用同一个索引)。
每列可以是不同的值类型(数值、字符串、布尔值等)。

下面对比一下两者创建数据的方式。
(由于输出比较长,部分地方就只放了代码,没有放运行结果哈)
2. 一维数据创建(numpy和pandas对比)
#列表转化
list1 = [1, 2, 3, 4]
arr1 = np.array(list1)
s1 = pd.Series(list1)
## 直接创建
arr2 = np.array([1, 2, 3, 4])
s2 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
输出格式为

#创建连续数值数组
arr3 = np.arange(5)
s3 = pd.Series(np.arange(5))
s3_1 = pd.Series(range(5)) #输出与s3相同
#创建全为0的数组
arr4 = np.zeros(5)
s4 = pd.Series(0 ,index = ['a','b','c','d'])
s4_1 = pd.Series(np.zeros(5))
#创建随机数数组
arr5 = np.random.rand(5)
arr_1 = np.random.random_sample(size=5)
s5 = pd.Series(np.random.rand(5))
3.多维创建
arr1 =np.array([[1, 2, 3, 4],
[5, 6, 7, 8]])
s0 = pd.DataFrame([[1, 2, 3, 4],
[5, 6, 7, 8]])
s1 = pd.DataFrame(np.arange(16).reshape((4, 4)))
输出

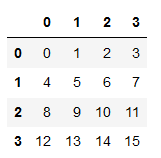
#创建全为0的数组和矩阵
arr2 = np.zeros((3,6))
s2 = pd.DataFrame(0,index = range(3), columns=range(6))
#创建单位矩阵
arr3 = np.eye(4) #单位矩阵
s3 = pd.DataFrame(np.eye(4))
#随机数矩阵
arr4 = np.random.randn(4,5)
s4 = pd.DataFrame(np.random.randn(4,5))
4.pandas的更多创建方式
我们日常使用numpy中一般用来创建数值型数组(其他类型用的比较少),pandas则可以用来创建多种数据类型
li = [1,'a','d',True]
s1 = pd.Series(li)输出:

我们经常用字典的方式来创建series和dataframe
#用字典创建series
data = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
s2 = pd.Series(data)

#外层字典的键作为列索引,dataframe自动加上行索引
data = {'one': [0, 1],
'two': [2, 3]}
s3 = pd.DataFrame(data)
#对于嵌套字典,外层字典作为列索引,内层键作为行索引
data = {'one': {'a':0, 'b':1},
'two': {'a':2, 'b':3}}
s4 = pd.DataFrame(data)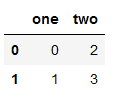

还可以自定义列和索引,并且依据索引对改变数据顺序
#自定义列和索引标签
s4 = pd.DataFrame(data, columns=['one', 'two', 'three', 'four'])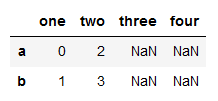
s5 = pd.DataFrame(data, columns=['three', 'two', 'one', 'four'])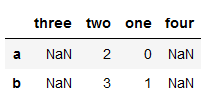
5.对象常用属性
(1)ndarray
- data. shape 数组的形状
- data.ndim 维度的数量
- data.size 数组的总大小
- data.dtype 数组中的数据类型(int8, uint8, float32, complex64, bool, object, string.
- data.astype 数据类型转换
(2)Series
- obj.values 获取数组的值
- obj.index 获取数组的索引对象
- obj.name 获取数组的名称
- obj.index.name 获取索引的名称
(3) DateFrame
- frame.index 获取表格的行索引
- frame.columns 获取表格的列索引
- frame.values 获取表格中的数据
- frame.col_name 获取指定列的数据
- frame.index.name 获取索引的名称
- frame.columns.name 获取列的名称
三、索引和切片
1.一维对象(numpy与series)的基础操作
arr = np.arange(6)
print(arr)
print(arr[2])
print(arr[3:5])
print(arr[[2,4,5]]) #花式索引
#赋值
arr[3:5]=6
print(arr)
ser = pd.Series(np.arange(0,6),index=list('abcdef'))
print(ser)
print(ser[0])
print(ser[0:2])
print(ser[[0,2,4]]) #花式索引
ser[0:2] = 5
print(ser)
2.多维numpy
(1)数值索引
#1.数值索引
arr1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr1)
print(arr1[2])
print(arr1[0][2])
print(arr1[0,2]) #与上面等价 表示根据索引取单个元素
print(arr1[:2,1:])
print(arr1[1:2,:2])
print(arr1[:,:1]) 
(2)花式索引
#花式索引——利用用于指定顺序的整数列表或ndarray进行索引
arr2 = np.random.rand(3,4)
print(arr2)
print(arr2[[0,2]]) #选择index=0行和index=2行
print(arr2[[0,2],[1,3]]) #选择arr2[0,1]和arr2[2,3]
(3)布尔索引
#布尔索引
names = np.array(['Bob', 'Joe', 'Bob', 'Will', 'Joe'])
print(names == 'Bob')
data = np.random.randn(5,5)
print(data)
print(data[names == 'Bob']) #按行
print(data[:,names == 'Bob']) #按列
print(data[names == 'Bob',:2]) #按行
print(data[(names == 'Bob') | (names == 'Joe')])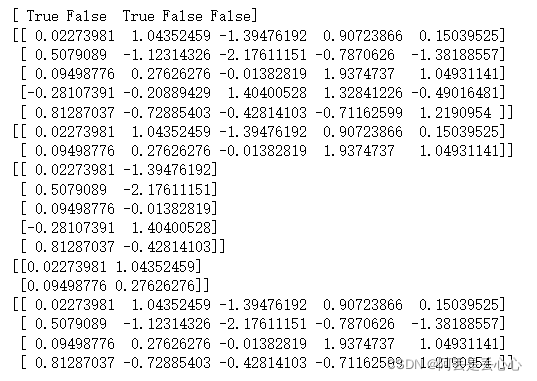
3.pandas的索引方式
df = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=list('abcd'),
columns=['one', 'two', 'three', 'four'])
df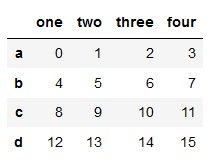
(1)列索引
#索引列
print(df['one'])
print(df.two)
print(df[['one','two']])
(2)位置索引和标签索引
对于DataFrame的行索引,可以通过位置或标签的方式进行获取,使用特殊的标签运算符位置索引(iloc)或标签索引(loc),从DataFrame选择行和列的子集。
print(df.loc['a':'b',['one','three']])
print(df.iloc[0:2,[1,3]])
(3)布尔索引
# 布尔索引
#DataFrame的布尔索引可以从整个表或者某个列进行
print(df<10)
print(df[df<10])#整个表
print(df.two<9)
print(df[df.two<9]) #某列
(4)列赋值
#当某个值赋给某个列时,会把这个值传播到所有列中
df['one'] = [2,6,7,8]
df['five'] = 6
df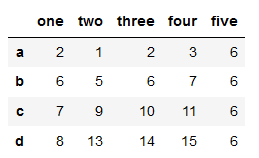
#也可以将某个series精确匹配到dataframe索引进行赋值
ser = pd.Series(np.arange(3, 7), index=list('abce'))
print(ser)
df['five'] = ser
df
四、排序
1. numpy排序
(1)numpy.sort()
函数返回输入数组的排序副本。函数格式如下:
numpy.sort(a, axis, kind, order)
- a: 要排序的数组
- axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
- kind: 默认为'quicksort'(快速排序)
- order: 如果数组包含字段,则是要排序的字段
(2) numpy.argsort()
|
|
功能: 将矩阵a按照axis排序,并返回排序后的下标
参数: a:输入矩阵, axis:需要排序的维度
arr = np.array([[4,7,2], [9,5,2], [7,8,9]])
print(arr)
print(np.sort(arr,0))
print(np.sort(arr,axis = 1))
#numpy.argsort() 函数返回的是数组值从小到大的索引值。
print(np.argsort(arr))
print(np.argsort(arr,1)) #与上面一样,每一行进行排序
print(np.argsort(arr,0)) #每一列进行排序
2.pandas排序
(1) sort_index 索引排序
DataFrame.sort_index(by=None,
axis=0, level=None,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last',
sort_remaining=True)-
by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
-
axis:0按照行名排序;1按照列名排序
-
level:默认None,否则按照给定的level顺序排列---貌似并不是,文档
-
ascending:默认True升序排列;False降序排列
-
inplace:默认False,否则排序之后的数据直接替换原来的数据框
-
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
-
na_position:缺失值默认排在最后{"first","last"}
s1 = pd.Series([4,1,2,3],index=['d','a','c','b'])
print(s1)
print(s1.sort_index())
print(s1.sort_index(ascending=False)) #对Series的索引进行降序排序,使用ascending=False参数 
data1 = pd.DataFrame( np.arange(9).reshape(3,3),
index = ["0","2","1"],
columns = ["col_a","col_c","col_b"])
print(data1)
print(data1.sort_index())
print(data1.sort_index(axis=0)) #按行索引升序排序
print(data1.sort_index(axis=1)) #按列索引升序排序
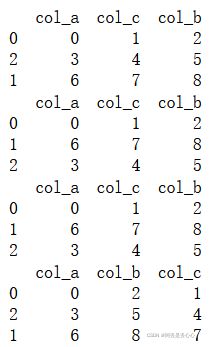
(2)sort_values 值引排序
DataFrame.sort_values(
by,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last')参 数:
-
by:字符串或者List<字符串>;如果axis=0,那么by="列名";如果axis=1,那么by="行名"。
-
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。
-
ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。
-
inplace:布尔型,是否用排序后的数据框替换现有的数据框。
-
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
-
na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
s2 = pd.Series([4,1,2,3],index=['d','a','c','b'])
print(s2)
print(s2.sort_values())
print(s2.sort_values(ascending=False))
data2 =pd.DataFrame([[2,3,12],[6,2,8],[9,5,7]],
index=["0", "2", "1"],
columns=["col_a", "col_c", "col_b"])
print(data2)
print(data2.sort_values(by='col_c')) #按指定列的值大小顺序进行排序
print(data2.sort_values(by=['col_b','col_a'])) #按列进行排序
print(data2.sort_values(by=['col_b','col_a'],axis=0,ascending=[False,True])) #先按col_b列升序,再按col_a列降序排序
print(data2.sort_values(by='2',axis=1)) #按行升序排列
print(data2.sort_values(by=['2','0'],axis=1)) #按 2行 升序,0行降排列
五、运算
1.标量运算
数组与标量的算术运算会将标量值传播到各个元素
不同大小的数组之间的算术运算的执行方式叫做广播(broadcasting)
广播中较小数组的‘广播维’必须为1, 广播会在缺失和(或)长度为1的维度上进行。较小的数组会在较大的数组上沿着该维度广播,并在经过的地方做相应的算术运算。最简单的广播就是标量值跟数组合并的运算。
(1)numpy
#numpy
arr = np.array([[1., 2., 3.],[4., 5., 6.]])
print(arr)
print(arr+1)
print(np.add(arr,1))
print(1/arr)
print(np.divide(1,arr))
print(arr**0.5)
print(np.power(arr, 0.5))
arr2 = np.array([[0., 4., 1.],[7., 2., 12.]])
#数组和标量之间的比较会生成布尔值数组
print(arr > 5)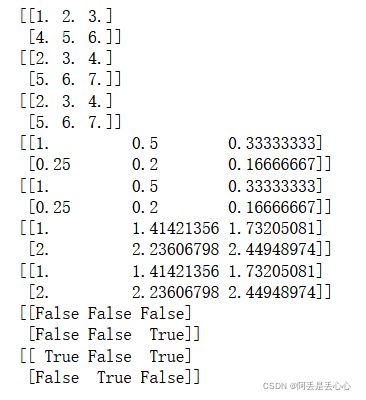
(2)series
#series
ser = pd.Series(np.arange(1,6), index = list('abcde'))
print(ser)
print(ser*2)
print(np.multiply(ser,2)) #series基于numpy数组进行计算,我们可以直接使用np的运算方法
print(ser/2)
print(ser > 3)
(3)dataframe
# Dataframe
df = pd.DataFrame(np.arange(9.).reshape((3,3)),
index = list('abc'),
columns = ['one','two','three'])
print(df)
print(df + 1)
print(np.add(df, 1)) #dataframe基于numpy数组进行计算,我们可以直接使用np的运算方法
print(df ** 2)
print((df > 2) & (df < 6))
2.向量运算
(1)numpy
# numpy
arr1 = np.array([[1., 2., 3.],[4., 5., 6.]])
arr2 = np.array([[0., 4., 1.],[7., 2., 12.]])
print(arr1 + arr2)
print(np.add(arr1, arr2))
print(arr1 * arr2)
arr1 > arr2
(2)series
# series
ser1 = pd.Series(np.arange(1, 6))
ser2 = pd.Series(np.arange(2, 7))
print(ser1 * ser2) 
# 根据运算的索引标签自动对齐数据,对不同索引的对象进行算术运算。
ser1 = pd.Series(np.arange(1, 6), index = list('abcde'))
ser2 = pd.Series(np.arange(2, 6), index = list('bcef'))
print(ser1 + ser2)
ser1 > ser2 # 会报错
(3)dataframe
df = pd.DataFrame(np.arange(9.).reshape((3,3)),
index = list('abc'),
columns = ['one','two','three'])
print(df)
#当从DataFrame减去相同索引的Series(df.iloc[0]),每一行都会执行这个操作。这就叫做广播(broadcasting)
ser = df.iloc[0]
print(ser)
print(df-ser)
#如果希望匹配行且在列上广播,则必须使用DataFrame的算术运算方法。
#传入的轴号就是希望匹配的轴,行索引(axis=‘index’ or axis=0)或列索引(axis=‘column’ or axis=1)。
ser2 = df.iloc[:,1]
print(ser2)
df.sub(ser2, axis = 'index')
#如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集
ser3 = pd.Series(range(3), index = ['one', 'two','four'])
print(df - ser3)

3.函数运算
(1)通用函数
通用函数(ufunc): 一种对ndarray中的数据执行元素级运算的函数。对pandas中的Series和DataFrame也适用。
一元ufunc: abs, sqrt, square, exp, log, sign, isnan, ceil, floor, rint, modf, isfinit, isinf, cos, cosh, sin, sinh, tan, tanh,....
用法:np.abs(arr)
二元ufunc:add, substract, multiply, divide, floor_divide, power, maximum, minimum, mod, copysign, greater, greater_equal, less, less_equal, equal, not_equal, logical_and, logical_or
用法:np.add(arr1, arr2)
(2)numpy
ndarray对象的基本数学和统计方法函数
sum, mean, std, var, min, max, argmin, argmax, cumsum, cumprod
arr = np.random.randn(3,4)
print(arr)
print(arr.mean())
print(arr.sum())
print(arr.mean(axis = 1))
print(arr.sum(axis = 0))
(3)pandas
pandas对象拥有的数学和统计方法:count, describe, min, max, argmin, argmax, idxmin, idxmax, quantile, sum, mean, median, mad, var, std, skew, kurt, cumsum, cummin, cummax, cumprod, diff, pct_change
#顺便对比一下numpy
arr = np.array([[1, 2, 3, 4, 5], [6, 4, 3, 2, 1]])
print(arr)
print(arr.argmax(axis=0))
print(arr.argmax(axis=1))
ser = pd.Series([1,3,2,5,7])
print(ser)
print(ser.argmax)
df = pd.DataFrame(np.arange(9.).reshape((3,3)),
index = list('abc'),
columns = ['one','two','three'])
print(df.describe())
print(df.idxmax())
print(df.idxmax(axis = 1))
#将函数应用到每个元素,应用元素级函数的applymap方法进行传播
def double(x):
return x +x
df.applymap(double)
#double = lambda x : x+x
#df.apply(double) 结果一样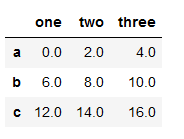
#想得到DataFrame中各个浮点值的格式化字符串
f = lambda x : format(x, '.2%')
df.applymap(f)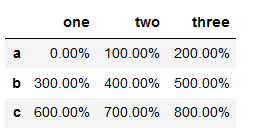
#apply的axis参数:0或‘index’:对每一列应用函数;1或‘columns':应用函数到每一行
f = lambda x: x.max() - x.min()
df.apply(f, axis = 0)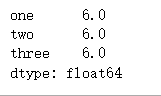
#数据填充
#对于DataFrame对象,dropna默认丢弃任何有缺失值的行,传入how=‘all'则将只丢弃全为NA的那些行。
data = pd.DataFrame([[1., 6.5, 3.], [1., np.nan, np.nan],[np.nan, np.nan, np.nan], [np.nan, 6.5, 3.]])
print(data)
print(data.dropna())
print(data.dropna(how='all'))
print(data.fillna(0))
print(data.fillna({1:0.5, 2:-1})) #对不同列填充不同值 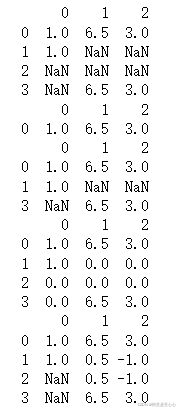
六、文件读取与加载
np.savetxt('test1.csv', arr, delimiter = ',') #存储文件
np.loadtxt('test1.csv', delimiter = ',') #加载文件
pd.read_csv('test2.csv', encoding='gbk', index_col=0)
pd.to_csv('test2.csv', encoding='gbk')参考:Python数据分析中Numpy和Pandas对比 - 知乎
NumPy 排序、条件刷选函数 | 菜鸟教程
DataFrame(8):DataFrame运算——基本统计函数 - math98 - 博客园