吴恩达深度学习课程-Course 4 卷积神经网络 第一周 卷积神经网络编程作业(第一部分)
时隔三个月终于有时间更新了…在ppt的夹缝中练习。
期待圣诞节!!!
卷积神经网络:Step by Step
- 1 - 导入相关包
- 2 - 作业大纲
- 3 - 卷积神经网络
-
- 3.1 - 零填充
- 3.2 - 单步卷积
- 3.3 - 卷积神经网络-前向传播
- 4 - 池化层(Pooling Layer)
-
- 4.1 - 前向池化
- 5 - 卷积神经网络的反向传播(可选)
-
- 5.1 - 卷积层反向传播
-
- 5.1.1 计算dA
- 5.1.2 计算dW
- 5.1.3 计算db
- 5.2 - 池化层反向传播
-
- 5.2.1 最大池化 - 反向传播
- 5.2.2 平均池化 - 反向传播
- 5.2.3 把它们放在一起:反向传播
欢迎来到第四课的第一个作业!在本任务中,您将在numpy中实现 卷积(CONV)和池化(POOL)层,包括前向传播和( 可选) 反向传播
【符号】:
- 上标 [ l ] [l] [l]表示第1层的对象。
- 示例: a [ 4 ] a^{[4]} a[4]表示第四层激活。 W [ 5 ] W^{[5]} W[5]和 b [ 5 ] b^{[5]} b[5]是第五层参数。
- 上标 ( i ) (i) (i)表示来自第 i i i个样本的对象。
- 示例: x ( i ) x^{(i)} x(i)是第 i i i个训练样本输入。
- 小写 i i i表示向量的第 i i i项。
- 示例: a i [ l ] a^{[l]}_i ai[l]表示第 l层中第 i i i个激活值,假设这是一个全连接(FC)层。
- n H n_H nH, n W n_W nW 和 n C n_C nC分别表示给定层的高度,宽度和通道数。如果你想特指某层 l l l,也可以写作 n H [ l ] n_H^{[l]} nH[l], n W [ l ] n_W^{[l]} nW[l], n C [ l ] n_C^{[l]} nC[l]
- n H p r e v n_{H_{prev}} nHprev, n W p r e v n_{W_{prev}} nWprev 和 n C p r e v n_{C_{prev}} nCprev分别表示上一层的高度、宽度和通道数。如果特指某层 l l l,也可以表示为 n H [ l − 1 ] n_H^{[l-1]} nH[l−1], n W [ l − 1 ] n_W^{[l-1]} nW[l−1], n C [ l − 1 ] n_C^{[l-1]} nC[l−1]
1 - 导入相关包
让我们首先导入在这个作业中需要的所有包。
numpy是用Python进行科学计算的基本包。
matplotlib是Python中绘制图形的库。
Np.random.seed(1)用于保持所有随机函数调用的一致性。它会帮助我们给你的作业评分
import numpy as np
import h5py
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize']=(5.0, 4.0) #设置图形默认大小
plt.rcParams['image.interpolation']='nearest' #设置最近邻插值
plt.rcParams['image.cmap']='gray' #设置灰色
%load_ext autoreload
%autoreload 2
np.random.seed(1) #设置随机种子
2 - 作业大纲
你将实现一个卷积神经网络的构建模块!你要实现的每个函数都有详细的说明,这些说明将指导你完成所需的步骤:
-
卷积模块,包含:
- Zero Padding 0边界扩充
- Convolve window 卷积窗
- Convolution forward 前向卷积
- Convolution backward (optional) 反向卷积
-
池化模块,包含:
- Pooling forward 前向池化
- Create mask 创建掩码
- Distribute value 值的分配
- Pooling backward (optional) 反向池化
本手册将要求您在numpy中从头开始实现这些函数。在接下来的笔记中,你将使用这些函数的TensorFlow等价形式来构建以下模型:
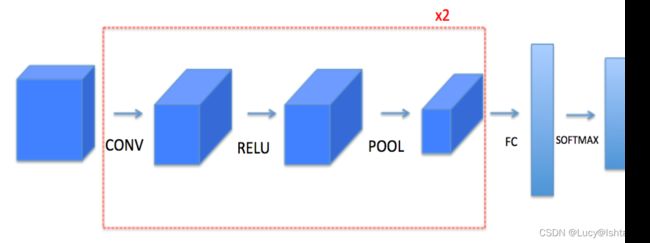
请注意,对于每个正向函数,都有相应的反向等价函数。因此,在前向模块的每一步中,您都将在缓存中存储一些参数。这些参数用于计算反向传播过程中的梯度。
3 - 卷积神经网络
虽然编程框架使卷积易于使用,但它们仍然是深度学习中最难理解的概念之一。卷积层将输入体积转换为不同大小的输出体积,如下所示。
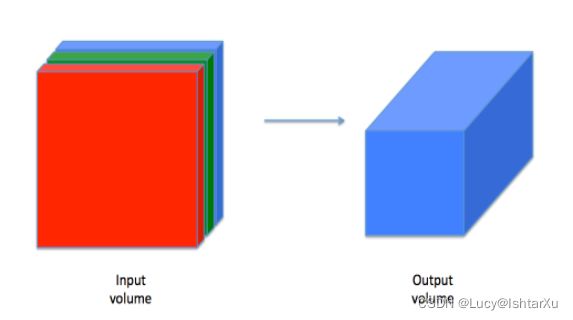
在这一部分中,您将构建卷积层的每一步。您将首先实现两个辅助函数:一个用于零填充,另一个用于计算卷积函数本身
3.1 - 零填充
零填充在图像的边界周围添加0:
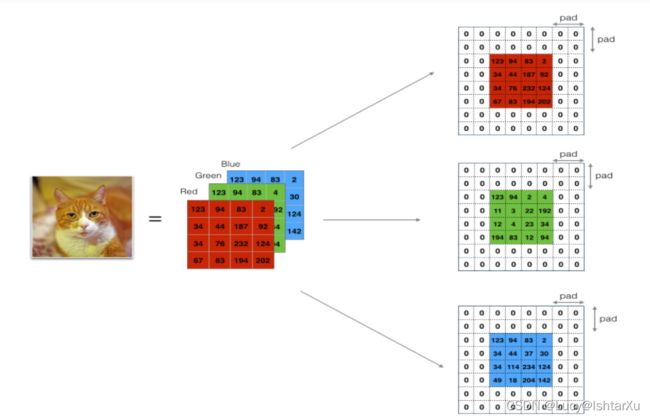
Image (3 channels, RGB) with a padding of 2.
填充的主要好处如下:
- 它允许您使用一个CONV层,而不必缩小高度和宽度的体积。这对于构建更深层次的网络很重要,因为如果不这样,高度/宽度会随着你进入更深层次而缩小。一个重要的特殊情况是same卷积,其中高度/宽度完全保留。
- 它帮助我们在图像的边缘保留更多的信息。没有填充,下一层的值很少会像图像的边缘一样受到像素的影响。
练习:实现以下函数,将一批样本X的所有图像填充为0。使用np.pad。注意,如果你想填充形状(5,5,5,5,5)的数组“a”,第2维的pad = 1,第4维的pad = 3,其余的pad = 0,你会这样做:
参考大佬博客:Numpy学习——数组填充np.pad()函数的应用
a = np.pad(a, ((0,0), (1,1), (0,0), (3,3), (0,0)), 'constant', constant_values = (..,..))
# GRADED FUNCTION: zero_pad
def zero_pad(X, pad):
"""
用0填充数据集X的所有图像,适用于一个图像的高度和宽度,
如图1所示。
参数:
X -- 形状为(m, n_H, n_W, n_C)的python numpy array,代表了一批图像
pad -- 整数,垂直和水平尺寸上每个图像周围的填充量
Returns:
X_pad -- 形状为 (m, n_H + 2*pad, n_W + 2*pad, n_C)的填充图像
"""
### START CODE HERE ### (≈ 1 line)
X_pad = np.pad(X, ((0,0), (pad,pad), (pad,pad), (0,0)), 'constant', constant_values=0 )
### END CODE HERE ###
return X_pad
np.random.seed(1)
x = np.random.randn(4,3,3,2)
x_pad = zero_pad(x, 2)
print ("x.shape =", x.shape)
print ("x_pad.shape =", x_pad.shape)
print ("x[1,1] =", x[1,1])
print ("x_pad[1,1] =", x_pad[1,1])
fig, axarr = plt.subplots(1, 2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
关于绘图:python 可视化:fig, ax = plt.subplots()画多表图的3中常见样例 & 自定义图表格式
输出结果:
x.shape = (4, 3, 3, 2)
x_pad.shape = (4, 7, 7, 2)
x[1,1] = [[ 0.90085595 -0.68372786]
[-0.12289023 -0.93576943]
[-0.26788808 0.53035547]]
x_pad[1,1] = [[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]]

3.2 - 单步卷积
在这一部分会实现一个简单的卷积步骤,将过滤器应用到输入的某个位置。这将用于构建一个卷积单元,其中:
- 取一个输入层(体,Volume)
- 在输入层的每个位置使用过滤器
- 输出另一层(通常大小不同)
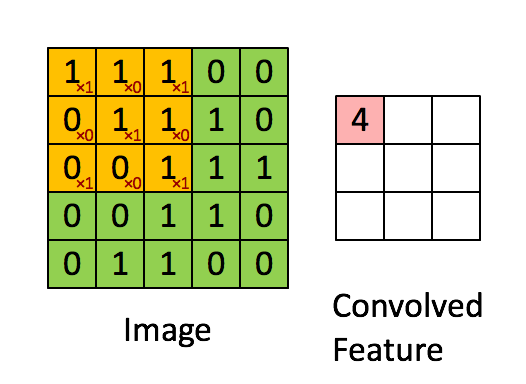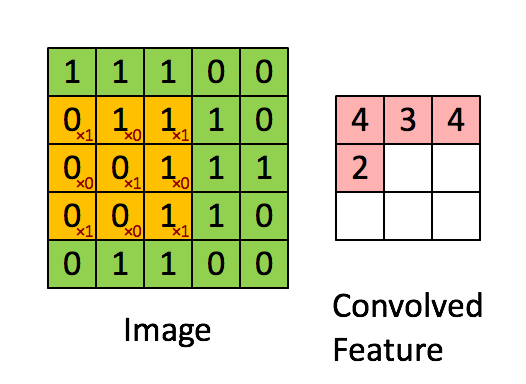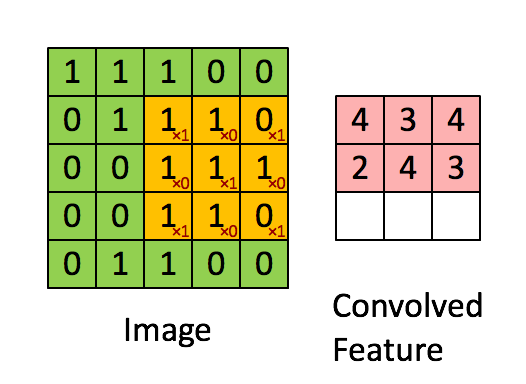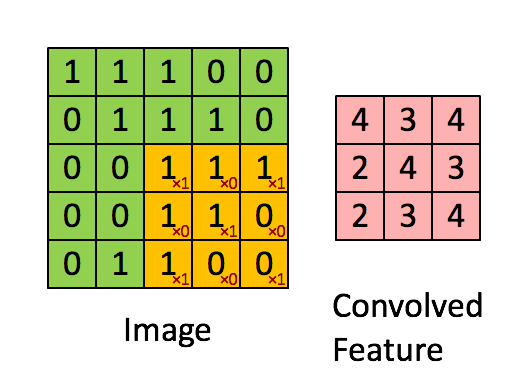
大小为2x2的过滤器,步长为1 (Stride = 每次滑动时移动窗口的数量)
在计算机视觉应用程序中,左边矩阵中的每一个值对应一个像素值,我们将一个3x3的过滤器与图像进行卷积,方法是将其元素值与原始矩阵相乘,然后将它们相加。在这个练习的第一步中,您将实现一个卷积步骤,只对其中一个位置应用一个过滤器以获得单个实值输出。
在本手册的后面部分,您将对输入的多个位置应用这个函数来实现完整的卷积操作。
【练习】:实现conv_single_step()。提示
# GRADED FUNCTION: conv_single_step
def conv_single_step(a_slice_prev, W, b):
"""
在上一层输出激活的单个切片(a_slice_prev)上应用由参数W定义的一个过滤器。
Arguments:
a_slice_prev -- 输入数据切片的形状(f, f, n_C_prev)
W -- 权重参数 - 矩阵形状 (f, f, n_C_prev)
b -- 偏置参数 - 矩阵形状 (1, 1, 1)
Returns:
Z -- 一个标量值,滑动窗口(W, b)在输入数据的切片x上卷积的结果
"""
### START CODE HERE ### (≈ 2 lines of code)
# a_slice和W之间的元素乘积加偏置
s = np.multiply(a_slice_prev, W) + b
# 对Volume s的所有项求和
Z = np.sum(s)
### END CODE HERE ###
return Z
np.random.seed(1)
a_slice_prev = np.random.randn(4, 4, 3)
W = np.random.randn(4, 4, 3)
b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b)
print("Z =", Z)
输出结果
Z = -23.16021220252078
3.3 - 卷积神经网络-前向传播
在前向传播中,您将使用许多过滤器并将它们与输入进行卷积。每个“卷积”都给你一个2D矩阵输出。然后将这些输出叠加起来,得到一个3D Volume。
【练习】:实现以下函数,在输入激活A_prev上对过滤器W进行卷积。该函数将前一层的激活输出A_prev(对于一批m个输入)、F滤波器/权重(W)和一个偏置向量(b)作为输入,其中每个滤波器都有自己的(单个)偏置。最后,您还可以访问包含stride和padding的超参数字典。
Hint:
- 要在矩阵“a_prev”(shape(5,5,3))的左上角选择一个2x2的切片,你可以这样做:
a_slice_prev = a_prev[0:2,0:2,:]
当您使用将要定义的start/end索引在下面定义a_slice_prev时,这将非常有用
2. To define a_slice you will need to first define its corners vert_start, vert_end, horiz_start and horiz_end. This figure may be helpful for you to find how each of the corner can be defined using h, w, f and s in the code below.
要定义a_slice,你需要首先定义它的角 vert_start,vert_end, horiz_start and horiz_end。这张图可能有助于您了解如何在下面的代码中使用h、w、f和s定义每个角。

Figure 3 : 使用垂直和水平起始/结束的切片定义(使用2x2过滤器)
This figure shows only a single channel.
Reminder:
将卷积的输出形状与输入形状联系起来的公式为:
n H = ⌊ n H p r e v − f + 2 × p a d s t r i d e ⌋ + 1 n_H = \lfloor \frac{n_{H_{prev}} - f + 2 \times pad}{stride} \rfloor +1 nH=⌊stridenHprev−f+2×pad⌋+1
n W = ⌊ n W p r e v − f + 2 × p a d s t r i d e ⌋ + 1 n_W = \lfloor \frac{n_{W_{prev}} - f + 2 \times pad}{stride} \rfloor +1 nW=⌊stridenWprev−f+2×pad⌋+1
n C = number of filters used in the convolution n_C = \text{number of filters used in the convolution} nC=number of filters used in the convolution
在这个练习中,我们不需要担心向量化,只需要用For循环来实现所有的东西。
# GRADED FUNCTION: conv_forward
def conv_forward(A_prev, W, b, hparameters):
"""
实现了卷积函数的前向传播
参数:
A_prev -- 输出前一层的激活,numpy数组的形状 (m, n_H_prev, n_W_prev, n_C_prev)
W -- 权重,numpy数组的形状 (f, f, n_C_prev, n_C)
b -- 偏差,numpy数组的形状 (1, 1, 1, n_C)
hparameters -- python字典包含 "stride" and "pad"
Returns:
Z -- Conv输出,numpy数组形状 (m, n_H, n_W, n_C)
cache -- conv_backward()函数所需值的缓存
"""
### START CODE HERE ###
# 从A_prev's中提取维度 (≈1 line)
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# 从A_prev's中提取维度 (≈1 line)
(f, f, n_C_prev, n_C) = W.shape
# 从“hparameters”检索信息 (≈2 lines)
stride = hparameters['stride']
pad = hparameters['pad']
# 使用上面给出的公式计算CONV输出体积的尺寸。Hint: use int() to floor. (≈2 lines)
n_H = int((n_H_prev - f + 2 * pad)/stride) + 1
n_W = int((n_W_prev - f + 2 * pad)/stride) + 1
# 用0初始化输出Z. (≈1 line)
Z = np.zeros([m, n_H, n_W, n_C])
# 通过填充A_prev创建A_prev_pad
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m): # 循环这批训练样本
a_prev_pad = A_prev_pad[i] # 选择训练样本的填充激活
for h in range(n_H): # loop over vertical axis of the output volume
for w in range(n_W): # loop over horizontal axis of the output volume
for c in range(n_C): # loop over channels (= #filters) of the output volume
# Find the corners of the current "slice" (≈4 lines)
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# Use the corners to define the (3D) slice of a_prev_pad (See Hint above the cell). (≈1 line)
a_slice_prev = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end,:]
# Convolve the (3D) slice with the correct filter W and bias b, to get back one output neuron. (≈1 line)
Z[i, h, w, c] = conv_single_step(a_slice_prev, W[:,:,:,c], b[:,:,:,c])
### END CODE HERE ###
# Making sure your output shape is correct
assert(Z.shape == (m, n_H, n_W, n_C))
# Save information in "cache" for the backprop
cache = (A_prev, W, b, hparameters)
return Z, cache
np.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 1}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
print("Z's mean =", np.mean(Z))
print("cache_conv[0][1][2][3] =", cache_conv[0][1][2][3])
输出结果为
Z's mean = 0.15585932488906465
cache_conv[0][1][2][3] = [-0.20075807 0.18656139 0.41005165]
最后,CONV层也应该包含一个激活,在这种情况下,我们将添加以下代码行:
# Convolve the window to get back one output neuron
Z[i, h, w, c] = ...
# Apply activation
A[i, h, w, c] = activation(Z[i, h, w, c])
你不需要在这里做。
4 - 池化层(Pooling Layer)
池化(Pooling)层降低了输入的高度和宽度。它有助于减少计算,并有助于使特征检测器更不改变其在输入中的位置。两种类型的池化层是:
- 最大池化层:将(,)窗口滑动到输入上,并将窗口的最大值存储在输出中。
- 平均池化层:将(,)窗口滑动到输入上,并将窗口的平均值存储在输出中。

这些池化层没有用于反向传播训练的参数。但是,它们有超参数,例如窗口大小 f。这指定了 f × f f×f f×f窗口的高度和宽度,你可以计算它的最大值或平均值。
4.1 - 前向池化
现在,您将在同一个函数中实现MAX-POOL和AVG-POOL。
练习:实现池化层的前向传播。请跟随下面评论中的提示。
提示:由于没有填充,将池的输出形状绑定到输入形状的公式是:
n H = ⌊ n H p r e v − f s t r i d e ⌋ + 1 n_H = \lfloor \frac{n_{H_{prev}} - f}{stride} \rfloor +1 nH=⌊stridenHprev−f⌋+1
n W = ⌊ n W p r e v − f s t r i d e ⌋ + 1 n_W = \lfloor \frac{n_{W_{prev}} - f}{stride} \rfloor +1 nW=⌊stridenWprev−f⌋+1
n C = n C p r e v n_C = n_{C_{prev}} nC=nCprev
# GRADED FUNCTION: pool_forward
def pool_forward(A_prev, hparameters, mode = "max"):
"""
实现池化层的前向传播
Arguments:
A_prev -- 输入数据, numpy数组形状为 (m, n_H_prev, n_W_prev, n_C_prev)
hparameters -- python字典包括 "f" and "stride"
mode -- 您想要使用的池化模式,定义为字符串 ("max" or "average")
Returns:
A -- 池化层的输出, numpy数组形状为 (m, n_H, n_W, n_C)
cache -- 在池化层的反向传播中使用的缓存,包含输入和hparameters
"""
# Retrieve dimensions from the input shape
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve hyperparameters from "hparameters"
f = hparameters["f"]
stride = hparameters["stride"]
# Define the dimensions of the output
n_H = int(1 + (n_H_prev - f) / stride)
n_W = int(1 + (n_W_prev - f) / stride)
n_C = n_C_prev
# Initialize output matrix A
A = np.zeros((m, n_H, n_W, n_C))
### START CODE HERE ###
for i in range(m): # loop over the training examples
for h in range(n_H): # loop on the vertical axis of the output volume
for w in range(n_W): # loop on the horizontal axis of the output volume
for c in range (n_C): # loop over the channels of the output volume
# Find the corners of the current "slice" (≈4 lines)
vert_start = i
vert_end = vert_start + f
horiz_start = i
horiz_end = horiz_start + f
# Use the corners to define the current slice on the ith training example of A_prev, channel c. (≈1 line)
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
# Compute the pooling operation on the slice. Use an if statment to differentiate the modes. Use np.max/np.mean.
if mode == "max":
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":
A[i, h, w, c] = np.mean(a_prev_slice)
### END CODE HERE ###
# Store the input and hparameters in "cache" for pool_backward()
cache = (A_prev, hparameters)
# Making sure your output shape is correct
assert(A.shape == (m, n_H, n_W, n_C))
return A, cache
我们来测试一下
np.random.seed(1)
A_prev = np.random.randn(2, 4, 4, 3)
hparameters = {"stride" : 1, "f": 4}
A, cache = pool_forward(A_prev, hparameters)
print("mode = max")
print("A =", A)
print()
A, cache = pool_forward(A_prev, hparameters, mode = "average")
print("mode = average")
print("A =", A)
输出结果为:
mode = max
A = [[[[1.74481176 1.6924546 2.10025514]]]
[[[1.19891788 1.51981682 2.18557541]]]]
mode = average
A = [[[[-0.09498456 0.11180064 -0.14263511]]]
[[[-0.1797859 0.21522908 0.38364167]]]]
恭喜你! 现在,您已经实现了卷积网络所有层的前向传播。
本笔记本的剩余部分是可选的,不计分。
5 - 卷积神经网络的反向传播(可选)
在现代的深度学习框架中,你只需要实现正向传递,而框架负责向后传递,所以大多数深度学习工程师不需要操心向后传递的细节。卷积网络的后向通过是复杂的。但是,如果你愿意,你可以通过笔记本的这个可选部分来了解卷积网络中的backprop是什么样子的。
在之前的课程中,您实现了一个简单的(全连接的)神经网络,使用反向传播来计算相对于更新参数的成本的导数。类似地,在卷积神经网络中,你可以计算出关于成本的导数来更新参数。backprop方程不是平凡的,我们没有在课上推导,但我们在下面简要地介绍了它们。
5.1 - 卷积层反向传播
让我们从实现CONV层的反向传播开始。
5.1.1 计算dA
这是计算相对于某个过滤器的成本的公式,以及一个给定的训练样本:
d A + = ∑ h = 0 n H ∑ w = 0 n W W c × d Z h w (2) dA += \sum _{h=0} ^{n_H} \sum_{w=0} ^{n_W} W_c \times dZ_{hw} \tag{2} dA+=h=0∑nHw=0∑nWWc×dZhw(2)
其中 W c W_c Wc是一个过滤器, d Z h w dZ_{hw} dZhw是一个标量,对应于在第 h h h行和第 h h h列的conv层 Z Z Z的输出的成本梯度(对应于在第 i i i个步幅左和第 j j j个步幅下的点积)。请注意,每次更新 d A dA dA时,我们都将相同的过滤器 W c W_c Wc乘以不同的 d Z dZ dZ。我们这样做的主要原因是,在计算正向传播时,每个过滤器都用不同的a_slice进行点和求和。因此,当计算 d A dA dA的backprop时,我们只是把所有a_slice的梯度相加。
在代码中,在合适的for循环中,这个公式可以转换为:
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c]
5.1.2 计算dW
这是计算 d W c dW_c dWc ( d W c dW_c dWc是一个过滤器的导数)关于损失的公式:
d W c + = ∑ h = 0 n H ∑ w = 0 n W a s l i c e × d Z h w (2) dW_c += \sum _{h=0} ^{n_H} \sum_{w=0} ^ {n_W} a_{slice} \times dZ_{hw} \tag{2} dWc+=h=0∑nHw=0∑nWaslice×dZhw(2)
其中 a s l i c e a_{slice} aslice对应于用于生成激活 Z i j Z_{ij} Zij的切片。因此,这最终给了我们 W W W相对于那片的梯度。因为它是相同的 W W W,我们将把所有这些梯度加起来得到 d W dW dW。
在代码中,在合适的for循环中,这个公式可以转换为:
dW[:,:,:,c] += a_slice * dZ[i, h, w, c]
5.1.3 计算db
这是计算 d b db db相对于某个过滤器 W c W_c Wc的成本的公式:
d b = ∑ h ∑ w d Z h w (3) db = \sum_h \sum_w dZ_{hw} \tag{3} db=h∑w∑dZhw(3)
正如您以前在基本神经网络中看到的, d b db db是通过对 d Z dZ dZ求和计算出来的。在这种情况下,你只是把所有的梯度的卷积输出(Z)和成本相加。
在代码中,在合适的for循环中,这个公式可以转换为:
db[:,:,:,c] += dZ[i, h, w, c]
练习:实现下面的' conv_backward '函数。你应该总结所有的训练样本,过滤器,高度和宽度。然后你应该用上面的公式1、2和3来计算导数。
def conv_backward(dZ, cache):
"""
Implement the backward propagation for a convolution function
Arguments:
dZ -- gradient of the cost with respect to the output of the conv layer (Z), numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward(), output of conv_forward()
Returns:
dA_prev -- gradient of the cost with respect to the input of the conv layer (A_prev),
numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
dW -- gradient of the cost with respect to the weights of the conv layer (W)
numpy array of shape (f, f, n_C_prev, n_C)
db -- gradient of the cost with respect to the biases of the conv layer (b)
numpy array of shape (1, 1, 1, n_C)
"""
### START CODE HERE ###
# Retrieve information from "cache"
(A_prev, W, b, hparameters) = cache
# Retrieve dimensions from A_prev's shape
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve dimensions from W's shape
(f, f, n_C_prev, n_C) = W.shape
# Retrieve information from "hparameters"
stride = hparameters['stride']
pad = hparameters['pad']
# Retrieve dimensions from dZ's shape
(m, n_H, n_W, n_C) = dZ.shape
# Initialize dA_prev, dW, db with the correct shapes
dA_prev = np.zeros((m,n_H_prev, n_W_prev, n_C_prev))
dW = np.zeros((f, f, n_C_prev, n_C))
db = np.zeros((1, 1, 1, n_C))
# Pad A_prev and dA_prev
A_prev_pad = zero_pad(A_prev, pad)
dA_prev_pad = zero_pad(dA_prev, pad)
for i in range(m): # loop over the training examples
# select ith training example from A_prev_pad and dA_prev_pad
a_prev_pad = A_prev_pad[i]
da_prev_pad = dA_prev_pad[i]
for h in range (n_H): # loop over vertical axis of the output volume
for w in range(n_W): # loop over horizontal axis of the output volume
for c in range(n_C): # loop over the channels of the output volume
# Find the corners of the current "slice"
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# Use the corners to define the slice from a_prev_pad
a_slice = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end]
# Update gradients for the window and the filter's parameters using the code formulas given above
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i,h,w,c]
dW[:,:,:,c] += a_slice * dZ[i,h,w,c]
db[:,:,:,c] += dZ[i,h,w,c]
# Set the ith training example's dA_prev to the unpaded da_prev_pad (Hint: use X[pad:-pad, pad:-pad, :])
dA_prev[i, :, :, :] = da_prev_pad[pad:-pad,pad:-pad,:]
### END CODE HERE ###
# Making sure your output shape is correct
assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev))
return dA_prev, dW, db
np.random.seed(1)
dA, dW, db = conv_backward(Z, cache_conv)
print("dA_mean =", np.mean(dA))
print("dW_mean =", np.mean(dW))
print("db_mean =", np.mean(db))
输出结果为
dA_mean = 9.608990675868995
dW_mean = 10.581741275547566
db_mean = 76.37106919563735
5.2 - 池化层反向传播
接下来,让我们实现池化层的向后传递,从MAX-POOL层开始。即使池化层没有参数来更新backprop,你仍然需要通过池化层反向传播梯度,以便为池化层之前的层计算梯度。
5.2.1 最大池化 - 反向传播
在进入池层的反向传播之前,你将构建一个名为create_mask_from_window()的helper函数,它的功能如下:
X = [ 1 3 4 2 ] → M = [ 0 0 1 0 ] (4) X = \begin{bmatrix} 1 && 3 \\ 4 && 2 \end{bmatrix} \quad \rightarrow \quad M =\begin{bmatrix} 0 && 0 \\ 1 && 0 \end{bmatrix}\tag{4} X=[1432]→M=[0100](4)
正如你所看到的,这个函数创建了一个“掩码”矩阵,用来跟踪矩阵的最大值。True(1)表示X中最大值的位置,其他条目为False(0)。稍后你将看到平均池的反向传播将与此类似,但使用了不同的掩码。
练习:实现create_mask_from_window()。这个函数将有助于反向池化。
提示:
Np.max()可能会有帮助。它计算数组的最大值。- 如果你有一个矩阵X和一个标量x:
A = (X == x)将返回一个与X相同大小的矩阵A,这样
A[i,j] = True if X[i,j] = x
A[i,j] = False if X[i,j] != x
- 这里,你不需要考虑矩阵中有几个极大值的情况。
def create_mask_from_window(x):
"""
Creates a mask from an input matrix x, to identify the max entry of x.
Arguments:
x -- Array of shape (f, f)
Returns:
mask -- Array of the same shape as window, contains a True at the position corresponding to the max entry of x.
"""
### START CODE HERE ### (≈1 line)
mask = ( x == np.max(x) )
### END CODE HERE ###
return mask
np.random.seed(1)
x = np.random.randn(2,3)
mask = create_mask_from_window(x)
print('x = ', x)
print("mask = ", mask)
输出结果为
x = [[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]]
mask = [[ True False False]
[False False False]]
为什么我们要跟踪最大值的位置?因为这是最终影响输出的输入值,因此也影响了成本。Backprop计算的是与成本相关的梯度,所以任何影响最终成本的东西都应该有一个非零的梯度。因此,backprop会将梯度“传播”回这个影响成本的特定输入值。
5.2.2 平均池化 - 反向传播
在max pooling中,对于每个输入窗口,所有对输出的“影响”都来自一个单一的输入值——max。在平均池化中,输入窗口的每个元素对输出的影响是相等的。为了实现backprop,你现在要实现一个反映这个的helper函数。
例如,如果我们使用2x2过滤器在前进通道中使用平均池,那么你将使用反向传播的掩码将是这样的:
d Z = 1 → d Z = [ 1 / 4 1 / 4 1 / 4 1 / 4 ] (5) dZ = 1 \quad \rightarrow \quad dZ =\begin{bmatrix} 1/4 && 1/4 \\ 1/4 && 1/4 \end{bmatrix}\tag{5} dZ=1→dZ=[1/41/41/41/4](5)
这意味着矩阵中的每个位置对输出的贡献相等,因为在前向传递中,我们取了平均值。
练习:实现下面的函数,通过维数形状的矩阵平均分配值dz。Hint
def distribute_value(dz, shape):
"""
Distributes the input value in the matrix of dimension shape
Arguments:
dz -- input scalar
shape -- the shape (n_H, n_W) of the output matrix for which we want to distribute the value of dz
Returns:
a -- Array of size (n_H, n_W) for which we distributed the value of dz
"""
### START CODE HERE ###
# Retrieve dimensions from shape (≈1 line)
(n_H, n_W) = shape
# Compute the value to distribute on the matrix (≈1 line)
average = dz / (n_H * n_W)
# Create a matrix where every entry is the "average" value (≈1 line)
a = np.ones(shape) * average
### END CODE HERE ###
return a
a = distribute_value(2, (2,2))
print('distributed value =', a)
输出结果为
distributed value = [[0.5 0.5]
[0.5 0.5]
5.2.3 把它们放在一起:反向传播
现在,您已经拥有了在池化层上计算反向传播所需的一切。
练习:在两种模式下(“max"和"average”)实现pool_backward函数。您将再次使用4个for循环(迭代训练示例、高度、宽度和通道)。你应该使用if/elif语句来判断模式是否等于’max’或’average’。如果它等于’average’,你应该使用上面实现的distribute_value()函数来创建一个与a_slice形状相同的矩阵。否则,该模式等于’max’,您将使用create_mask_from_window()创建一个掩码,并将其乘以dZ的相应值。
def pool_backward(dA, cache, mode = "max"):
"""
Implements the backward pass of the pooling layer
Arguments:
dA -- gradient of cost with respect to the output of the pooling layer, same shape as A
cache -- cache output from the forward pass of the pooling layer, contains the layer's input and hparameters
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
dA_prev -- gradient of cost with respect to the input of the pooling layer, same shape as A_prev
"""
### START CODE HERE ###
# Retrieve information from cache (≈1 line)
(A_prev, hparameters) = cache
# Retrieve hyperparameters from "hparameters" (≈2 lines)
stride = hparameters['stride']
f = hparameters['f']
# Retrieve dimensions from A_prev's shape and dA's shape (≈2 lines)
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
m, n_H, n_W, n_C = dA.shape
# Initialize dA_prev with zeros (≈1 line)
dA_prev = np.zeros_like(A_prev)
for i in range(m): # loop over the training examples
# select training example from A_prev (≈1 line)
a_prev = A_prev[i]
for h in range(n_H): # loop on the vertical axis
for w in range(n_W): # loop on the horizontal axis
for c in range(n_C): # loop over the channels (depth)
# Find the corners of the current "slice" (≈4 lines)
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# Compute the backward propagation in both modes.
if mode == "max":
# Use the corners and "c" to define the current slice from a_prev (≈1 line)
a_prev_slice = a_prev[vert_start:vert_end, horiz_start:horiz_end, c]
# Create the mask from a_prev_slice (≈1 line)
mask = create_mask_from_window(a_prev_slice)
# Set dA_prev to be dA_prev + (the mask multiplied by the correct entry of dA) (≈1 line)
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += mask * dA[i, vert_start, horiz_start, c]
elif mode == "average":
# Get the value a from dA (≈1 line)
da = dA[i, vert_start, horiz_start, c]
# Define the shape of the filter as fxf (≈1 line)
shape = (f, f)
# Distribute it to get the correct slice of dA_prev. i.e. Add the distributed value of da. (≈1 line)
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)
### END CODE ###
# Making sure your output shape is correct
assert(dA_prev.shape == A_prev.shape)
return dA_prev
np.random.seed(1)
A_prev = np.random.randn(5, 5, 3, 2)
hparameters = {"stride" : 1, "f": 2}
A, cache = pool_forward(A_prev, hparameters)
dA = np.random.randn(5, 4, 2, 2)
dA_prev = pool_backward(dA, cache, mode = "max")
print("mode = max")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
print()
dA_prev = pool_backward(dA, cache, mode = "average")
print("mode = average")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
输出结果
mode = max
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0. 0. ]
[ 5.05844394 -1.68282702]
[ 0. 0. ]]
mode = average
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0.08485462 0.2787552 ]
[ 1.26461098 -0.25749373]
[ 1.17975636 -0.53624893]]
恭喜你!
恭喜你完成了这项任务。现在您了解了卷积神经网络的工作原理。您已经实现了神经网络的所有构建模块。在下一个作业中,你将使用TensorFlow实现一个ConvNet。