【深度学习】经典网络-(InceptionV2)GoogLeNet网络复现(使用Tensorflow实现)
论文地址:(V2)https://arxiv.org/abs/1502.03167v2
本文所包含代码GitHub地址:https://github.com/shankezh/DL_HotNet_Tensorflow
如果对机器学习有兴趣,不仅仅满足将深度学习模型当黑盒模型使用的,想了解为何机器学习可以训练拟合最佳模型,可以看我过往的博客,使用数学知识推导了机器学习中比较经典的案例,并且使用了python撸了一套简单的神经网络的代码框架用来加深理解:https://blog.csdn.net/shankezh/article/category/7279585
项目帮忙或工作机会请邮件联系:cloud_happy@163.com
数据集下载地址:https://www.kaggle.com/c/cifar-10 or http://www.cs.toronto.edu/~kriz/cifar.html
更正,我还是用了inceptionv2复现了训练。往下看即可 。
论文精华(V2)
关键信息提取
1.提出Batch Normalization方法,用来加速网络训练;
2.文章把模型训练难,调参难,初始化不方便等现象,统一称作Internal Covariate Shift(内均方差偏移?),因此提出了一个强有力的方法就是在每一次训练的小批次样本的时候,对模型结构进行Normalization(规范化);
3.BN允许使用大一点的学习速率,且不用太在意初始化参数问题,也可以作为正则化项,并在一些情况下不需要使用dropout;
4.顶尖分类图像模型中,使用BN使得模型训练14次都少于原来的训练步骤( 我觉得这里应该是减少14倍的意思吧?),并且比原来的模型更加优秀;
5.使用组合的BN网络,提升ImageNet分类结果达到 top-5 error 4.9%(val sets)和4.8%(test sets),超越了人类的水平;
6.介绍了SGD优化器,典型的凑字数...
7.网络变深,训练复杂,所有的前置层参数输入都会产生影响,小的改变都会导致网络参数放大;
8.层输入分布改变带来一个问题,因为层需要连续不断的适应新的分布,当输入分布作用在一个学习系统中改变,根据经验就叫做covariate shift.这种概念可以扩展到整个学习系统中,应用到部分中,如1个子网络或者1个层;
9.固定输入分布至子网落,将会有积极的结果对于子网落。
10.实践中,饱和问题和梯度消失通常出现在使用ReLU,初始化,以及小学习速率上;从而确认非线性分布输入会让网络训练更稳定,优化器将更不可能卡在饱和状态,训练便会加速(重点);
11.为了白化输入层,做了两个必要的简化:a)不将输入和输出层的特征进行白化,将会规范化每个具有依赖的缩放特征,通过对其做零均值和1的均方差;b)当使用小批次随机梯度训练时,每个小批次都会生成均值和方差的估计值;
12.BN算法过程见Figure1,训练阶段;
13.激活规范化依赖在mini-batch,使其训练高效,但其既不必要的也不适合在推理阶段;
14.为了让BN在推理阶段也能用,那么就需要产生BN变体来应对推理,具体算法过程见Figure2;
15.传统深度网络使用太高的学习速率容易梯度爆炸或者梯度消失,也容易困在局部极小值,BN就能帮助解决这个问题(重点);
16.通常大学习速率会增加层参数尺度,紧接着在反向传播中放大梯度,使得模型爆炸;然而BN在反向传播通过一层的时候是不受参数尺度影响的;BN(Wu) = BN((aW)u),尺度因子a,对输入u和权重 W进行求导,会发现左右求导,求导u时候u不受a影响,求导W的时候,左边乘上1/a等于右边,这个时候放大的尺度a在BN变成了1/a,再和层参数的a相乘就变成了1,因此BN可以避免收到尺度影响;
17.通常使用dropout来防止过拟合,但使用了BN的网络,我们发现可以移除dropout或者减少dropout的比例;
18.加速BN网络:简单添加BN并不会发挥所有效果,因此需要跟随以下步骤进行:a)增加学习速率,BN不怕大学习速率带来的问题;b)移除Dropout;c)减少L2权重正则化;d)加速学习速率的衰减(因为训练太快了);e)移除LRN(BN更强,还要啥自行车);f)尽可能的打乱训练数据;g)减少光照扭曲(训练太快了,因此希望用更真实的图片来训练);
结构细节
1.验证时使用了LeCun的MNIST数据集,28x28的二进制图像作为输入,3层全连接,每一层为100激活数,使用sigmoid计算含隐层,权重w使用高斯随机分布初始化;最后一个全连接使用了10激活数(总共就10类),交叉熵做误差函数;跑了5w步,每个mini-batch为60个图像;BN添加在每一个隐藏层;比较了原始网络和BN网络,而非实现最佳性能在MNIST上,对比情况在下文的Figure3;
2.应用BN到Inception变体网路,训练ImageNet分类任务,卷积层使用ReLU,主要不同是网络中的5x5卷积全被2个3x3使用128个滤波器替代,网络共包含136w个参数,顶部使用softmax层(老外喜欢从下往上看),没有全连接;更多细节在附录中;
3.训练使用momentum;mini-batch size为32;
4.对每张图使用了剪裁;
5.论文附录给出了inceptionv2的结构:5x5卷积被2个3x3代替,这将会导致增加9个权重层;28x28的inception模块从2个变成3个;有一部分没有使用池化层在两个Inception模块中间,但使用了Stride为2的卷积/池化在3c,4e中;模型使用了稀疏卷积层,depth_multiplier为8在第一个卷积层上;具体结构图看图Figure4.;

Figure1.BN的算法
其中,γ和β是需要学习的参数,x是mini-batch中的值,可以清晰的看到过程,计算均值,方差,标准化,缩放和偏移;

Figure2.推理BN算法,BNtr表示是训练时候的BN,BNinf表示的是推理的BN,训练的是时候统计了BN均值和方差,通过统计结果最后求出了全局的方差,训练的时候求出了γ和β,推理的时候直接拿来用;
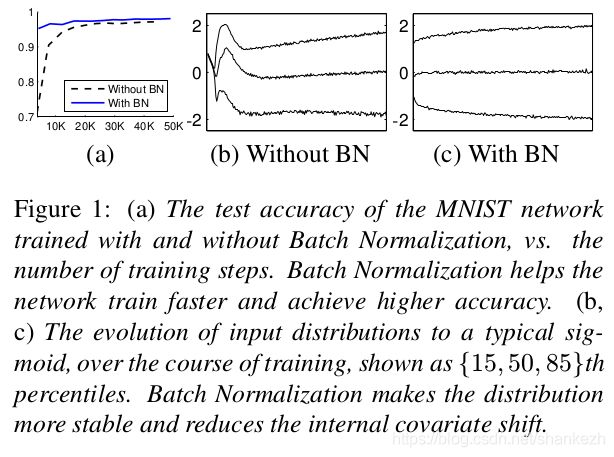
Figure3.使用BN和不使用BN的对比,bc对比展示了输入分布和内均方差漂移情况。

Figure5. InceptionV2结构图
Tensorflow代码实现
说明
使用Tensorflow搭建论文网络,搭建过程遵循论文原意,并且确认google官方给出的IncetpionV2的代码与我的区别,基本一致,由于论文中结果网络图太长,请大家自行观察论文去看;
代码
模型
InceptionV2.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Created by Inception on 19-1-23
import tensorflow as tf
import tensorflow.contrib.slim as slim
def inception_moudle_v2(net,scope,filters_num,pool_type,stride):
with tf.variable_scope(scope):
if filters_num[0] != 0:
with tf.variable_scope('bh1'):
bh1 = slim.conv2d(net,filters_num[0],1,stride=stride,scope='bh1_conv1_1x1')
with tf.variable_scope('bh2'):
bh2 = slim.conv2d(net,filters_num[1],1,stride=1,scope='bh2_conv1_1x1')
bh2 = slim.conv2d(bh2,filters_num[2],3,stride=stride,scope='bh2_conv2_3x3')
with tf.variable_scope('bh3'):
bh3 = slim.conv2d(net,filters_num[3],1,stride=1,scope='bh3_conv1_1x1')
bh3 = slim.conv2d(bh3,filters_num[4],3,stride=1,scope='bh3_conv2_3x3')
bh3 = slim.conv2d(bh3,filters_num[5],3,stride=stride,scope='bh3_conv3_3x3')
with tf.variable_scope('bh4'):
if pool_type == 'avg':
bh4 = slim.avg_pool2d(net,3,stride=stride,scope='bh4_avg_3x3')
elif pool_type == 'max':
bh4 = slim.max_pool2d(net,3,stride=stride, scope='bh4_max_3x3')
else:
raise TypeError("没有此参数类型(params valid)")
if filters_num[0] != 0:
bh4 = slim.conv2d(bh4,filters_num[6],1,stride=1,scope='bh4_conv_1x1')
net = tf.concat([bh1,bh2,bh3,bh4],axis=3)
else:
net = tf.concat([bh2,bh3,bh4],axis=3)
return net
def V2_slim(inputs, num_cls, keep_prob=0.8,is_training = False, spatital_squeeze = True):
batch_norm_params = {
'decay': 0.998,
'epsilon': 0.001,
'scale': False,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'is_training': is_training
}
net = inputs
with tf.name_scope('reshape'):
net = tf.reshape(net,[-1,224,224,3])
with tf.variable_scope('GoogLeNet_V2'):
with slim.arg_scope(
[slim.conv2d,slim.separable_conv2d],
weights_initializer=slim.xavier_initializer(),
normalizer_fn= slim.batch_norm,
normalizer_params= batch_norm_params,
# normalizer_fn = tf.layers.batch_normalization,
# normalizer_params = params
):
with slim.arg_scope(
[slim.conv2d,slim.max_pool2d,slim.avg_pool2d,slim.separable_conv2d],
stride=1,
padding='SAME'
):
with slim.arg_scope([slim.batch_norm],**batch_norm_params):
net = slim.separable_conv2d(net, 64, 7, depth_multiplier=8, stride=2,
weights_initializer=slim.xavier_initializer(), scope='layer1')
net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='layer2')
net = slim.conv2d(net, 64, 1, stride=1, padding='SAME', scope='layer3')
net = slim.conv2d(net, 192, 3, stride=1, padding='SAME', scope='layer4')
net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='layer5')
net = inception_moudle_v2(net,scope='layer6_3a',filters_num=[64, 64, 64, 64, 96, 96, 32],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer9_3b',filters_num=[64, 64, 96, 64, 96, 64, 64],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer12_3c',filters_num=[0, 128,160,64, 96, 96],pool_type='max',stride=2)
net = inception_moudle_v2(net,scope='layer15_4a',filters_num=[224,64,96,96,128,128,128],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer18_4b',filters_num=[192,96,128,96,128,128,128],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer21_4c',filters_num=[160,128,160,128,160,160,128],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer24_4d',filters_num=[96,128,192,160,192,192,128],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer27_4e',filters_num=[0,128,192,192,256,256],pool_type='max',stride=2)
net = inception_moudle_v2(net,scope='layer30_5a',filters_num=[352,192,320,160,224,224,128],pool_type='avg',stride=1)
net = inception_moudle_v2(net,scope='layer33_5b',filters_num=[352,192,320,192,224,224,128],pool_type='max',stride=1)
net = slim.avg_pool2d(net,7,stride=1,padding='VALID',scope="layer36_avg")
net = slim.dropout(net,keep_prob=keep_prob,scope="dropout")
net = slim.conv2d(net,num_cls,1,activation_fn=None,normalizer_fn=None,scope="layer37")
if spatital_squeeze:
net = tf.squeeze(net,[1,2],name='squeeze')
net = slim.softmax(net,scope="softmax")
return net
在以上代码中的net = inception_moudle_v2(net,scope='layer9_3b',filters_num=[64, 64, 96, 64, 96, 64, 64],pool_type='avg',stride=1) ,其中参数填写按照论文,应改为net = inception_moudle_v2(net,scope='layer9_3b',filters_num=[64, 64, 96, 64, 96, 96, 64],pool_type='avg',stride=1),属于当时写代码的时候,看图看差了。多谢小生gogogo同学提醒
训练
import tensorflow as tf
import coms.utils as utils
import coms.pre_process as pre_pro
import coms.coms as coms
import net.GoogLeNet.InceptionV2 as InceptionV2
import coms.learning_rate as LR_Tools
import time
import cv2
import numpy as np
import os
def run():
model_dir = ''
logdir = ''
img_prob = [224, 224, 3]
num_cls = 10
is_train = False
is_load_model = False
is_stop_test_eval = True
BATCH_SIZE = 100
EPOCH_NUM = 150
ITER_NUM = 500 # 50000 / 100
LEARNING_RATE_VAL = 0.001
if utils.isLinuxSys():
logdir = r''
model_dir = r''
else:
model_dir = r'D:\DataSets\cifar\cifar\model_flie\inceptionv2'
logdir = r'D:\DataSets\cifar\cifar\logs\train\inceptionv2'
if is_train:
train_img_batch, train_label_batch = pre_pro.get_cifar10_batch(is_train = True, batch_size=BATCH_SIZE, num_cls=num_cls,img_prob=[224,224,3])
test_img_batch, test_label_batch = pre_pro.get_cifar10_batch(is_train=False,batch_size=BATCH_SIZE,num_cls=num_cls,img_prob=[224,224,3])
inputs = tf.placeholder(tf.float32,[None, img_prob[0], img_prob[1], img_prob[2]])
labels = tf.placeholder(tf.float32,[None, num_cls])
is_training = tf.placeholder(tf.bool)
LEARNING_RATE = tf.placeholder(tf.float32)
calc_lr = LR_Tools.CLR_EXP_RANGE()
# layer_batch_norm_params = {
# 'training': is_training
# }
logits = InceptionV2.V2_slim(inputs, num_cls, is_training=is_training)
train_loss = coms.loss(logits,labels)
train_optim = coms.optimizer_bn(lr=LEARNING_RATE,loss=train_loss)
train_eval = coms.evaluation(logits,labels)
saver = tf.train.Saver(max_to_keep=4)
max_acc = 0.
config = tf.ConfigProto(allow_soft_placement=True)
with tf.Session(config=config) as sess:
if utils.isHasGpu():
dev = '/gpu:0'
else:
dev = '/cpu:0'
with tf.device(dev):
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess= sess, coord=coord)
try:
if is_train:
if is_load_model:
ckpt = tf.train.get_checkpoint_state(model_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
print('model load successful ...')
else:
print('model load failed ...')
return
n_time = time.strftime("%Y-%m-%d %H-%M", time.localtime())
logdir = os.path.join(logdir, n_time)
writer = tf.summary.FileWriter(logdir, sess.graph)
for epoch in range(EPOCH_NUM):
if coord.should_stop():
print('coord should stop ...')
break
for step in range(1,ITER_NUM+1):
if coord.should_stop():
print('coord should stop ...')
break
script_kv = utils.readFile('train_script')
if script_kv != None:
if 'iter' in script_kv.keys():
# 找到对应step,准备保存模型参数,或者修改学习速率
if int(script_kv['iter']) == step:
if 'lr' in script_kv.keys():
LEARNING_RATE_VAL = float(script_kv['lr'])
print('read train_scrpit file and update lr to {}'.format(LEARNING_RATE_VAL))
if 'save' in script_kv.keys():
saver.save(sess,model_dir + '/' + 'cifar10_{}_step_{}.ckpt'.format(str(epoch),str(step)),global_step=step)
print('read train_script file and save model successful ...')
LEARNING_RATE_VAL = calc_lr.calc_lr(step,ITER_NUM,0.001,0.01,gamma=0.9998)
# LEARNING_RATE_VAL = coms.clr(step,2*ITER_NUM,0.001,0.006)
batch_train_img, batch_train_label = sess.run([train_img_batch,train_label_batch])
_, batch_train_loss, batch_train_acc = sess.run([train_optim,train_loss,train_eval],feed_dict={inputs:batch_train_img,
labels:batch_train_label,
LEARNING_RATE:LEARNING_RATE_VAL,
is_training:is_train})
global_step = int(epoch * ITER_NUM + step + 1)
print("epoch %d , step %d train end ,loss is : %f ,accuracy is %f ... ..." % (epoch, step, batch_train_loss, batch_train_acc))
train_summary = tf.Summary(value=[tf.Summary.Value(tag='train_loss',simple_value=batch_train_loss)
,tf.Summary.Value(tag='train_batch_accuracy',simple_value=batch_train_acc)
,tf.Summary.Value(tag='learning_rate',simple_value=LEARNING_RATE_VAL)])
writer.add_summary(train_summary,global_step)
writer.flush()
if is_stop_test_eval:
if not is_load_model:
if epoch < 3:
continue
if step % 100 == 0:
print('test sets evaluation start ...')
ac_iter = int(10000/BATCH_SIZE) # cifar-10测试集数量10000张
ac_sum = 0.
loss_sum = 0.
for ac_count in range(ac_iter):
batch_test_img, batch_test_label = sess.run([test_img_batch,test_label_batch])
test_loss, test_accuracy = sess.run([train_loss,train_eval],feed_dict={inputs:batch_test_img,
labels:batch_test_label,
is_training:False})
ac_sum += test_accuracy
loss_sum += test_loss
ac_mean = ac_sum / ac_iter
loss_mean = loss_sum / ac_iter
print('epoch {} , step {} , accuracy is {}'.format(str(epoch),str(step),str(ac_mean)))
test_summary = tf.Summary(
value=[tf.Summary.Value(tag='test_loss', simple_value=loss_mean)
, tf.Summary.Value(tag='test_accuracy', simple_value=ac_mean)])
writer.add_summary(test_summary,global_step=global_step)
writer.flush()
if ac_mean >= max_acc:
max_acc = ac_mean
saver.save(sess, model_dir + '/' + 'cifar10_{}_step_{}.ckpt'.format(str(epoch),str(step)),global_step=step)
print('max accuracy has reaching ,save model successful ...')
# print('saving last model ...')
# saver.save(sess, model_dir + '/' + 'cifar10_last.ckpt')
print('train network task was run over')
else:
model_file = tf.train.latest_checkpoint(model_dir)
saver.restore(sess, model_file)
cls_list = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship',
'truck']
for i in range(1, 11):
name = str(i) + '.jpg'
img = cv2.imread(name)
img = cv2.resize(img, (32, 32))
img = cv2.resize(img, (224, 224))
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img / 255.
img = np.array([img])
res = sess.run(logits, feed_dict={inputs:img , is_training:False})
# print(res)
print('{}.jpg detect result is : '.format(str(i)) + cls_list[np.argmax(res)] )
except tf.errors.OutOfRangeError:
print('done training -- opoch files run out of ...')
finally:
coord.request_stop()
coord.join(threads)
sess.close()
if __name__ == '__main__':
np.set_printoptions(suppress=True)
run()结果
复现训练使用了cifar10数据集,由于inceptionv2的网络结构,无法直接使用32x32像素的数据,因此将其转换成了224x224的大小,这也是论文原文使用的尺寸,但由于cifar10源数据只有32x32的分辨率,因此转换成224x224的效果后,依旧十分模糊,训练出来的模型,对于高清像素转换成的224x224的数据集合效果并不是很好,因此我在检测网上下下来的十张图片时,先resize成32x32,然后在resize成224x224,这样检测分类的效果会比直接resize成224x224的效果好很多,原因其实也很简单,卷积核学到的特征就是32x32变成224x224的模糊图片上的特征,学出来的就是马赛克形式,因此更擅长检测马赛克图片;
BN的配置写在了arg_score()中,normalizer_fn= slim.batch_norm是配置batch_norm, normalizer_params= batch_norm_params是配置BN的参数,注意里面的is_training,训练的时候要设置为True,测试的时候要设置为False,本次训练的最高准确率到达了79.9%;
以下是百度上下载的十张图片:

检测结果:

可以看到,十张错了3张,对了7张;
同时我对比了使用BN和不适用BN的训练过程:
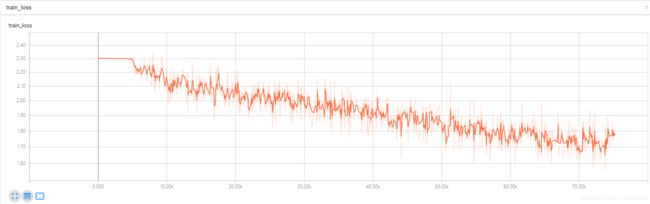
不使用BN的loss,如下图:
不使用BN的正确率曲线,如下图:

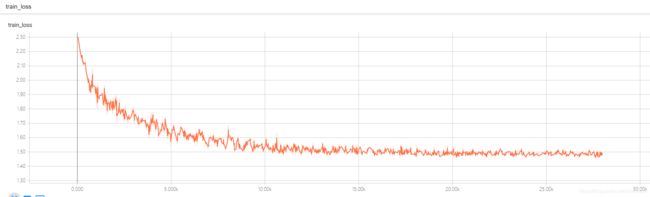
使用BN的loss,如下图,:
使用BN的正确率,如下图:
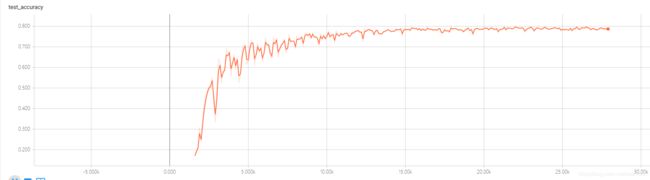
可以看到结果,不使用BN时候,训练刚开始没有任何效果,5K后才开始慢慢下降,正确率也提升较慢,而使用了BN的网络结构,在训练刚开始就下降很快,并且只花了15K左右就到达了不用BN的50K之后的效果:
结论:
BN确实是一种非常有用的训练手段,将训练过程的离散的数据重新进行了超平面映射,使其变得更容易进行拟合,同时去除了全连接的inception结构,使得模型参数变得非常小,这样就更加有在嵌入式设备应用的前景了。
至此,InceptionV2复现完毕;
训练模型已经上传至百度网盘,GitHub可以下到我的源码,地址在最上部分,感兴趣的可以下载学习,或者试用;
权重文件,百度云地址为链接:链接:https://pan.baidu.com/s/1BdMZYvkiYT9Fts0dLIgrog
提取码:0rmi