Python办公自动化练习——合并工作表
目录
一、题目描述
二、函数分析
1、合并单元格函数
2、获取excel单元中的数据
三、思路解析
1、合并单元格
2、获取数据
①首先获取工作簿对象
②获取工作簿中工作表的名称
③ 通过工作表的名称获取工作表的数据
④调用函数进行和平工作表操作
四、源码
五、效果图
1、合并前
2、合并后
一、题目描述
在Excel表格中将上下行相同内容的单元格自动合并
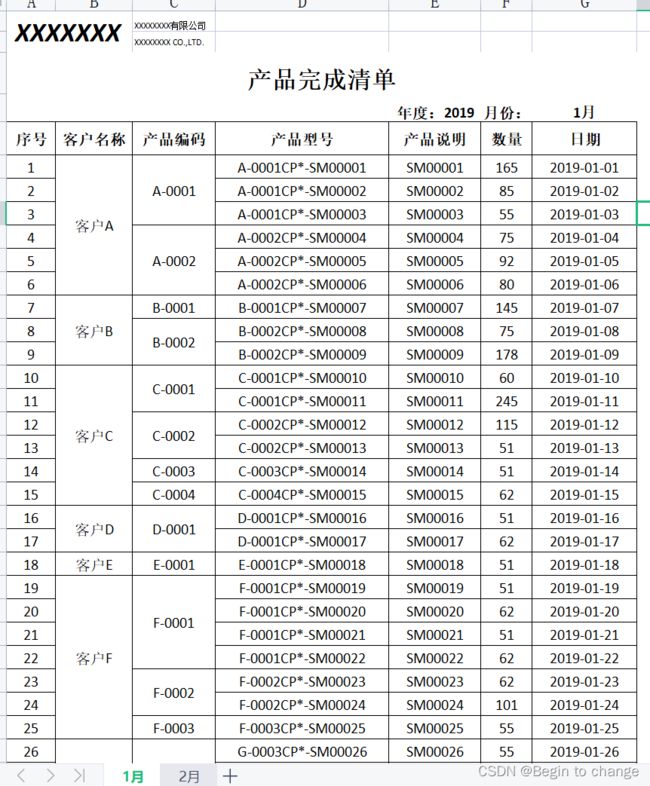
从汇总统计的角度,合并单元格非常不友好。单元格一旦合并,使用数据透视表,分类汇总都无法得到正确的结果。所以,对于原始数据,最好别随意合并单元格。但在日常的工作中,部分Excel打印档要求将某列上下内容相同的单元格合并,以便看起来清爽,比如下面这样的表格:
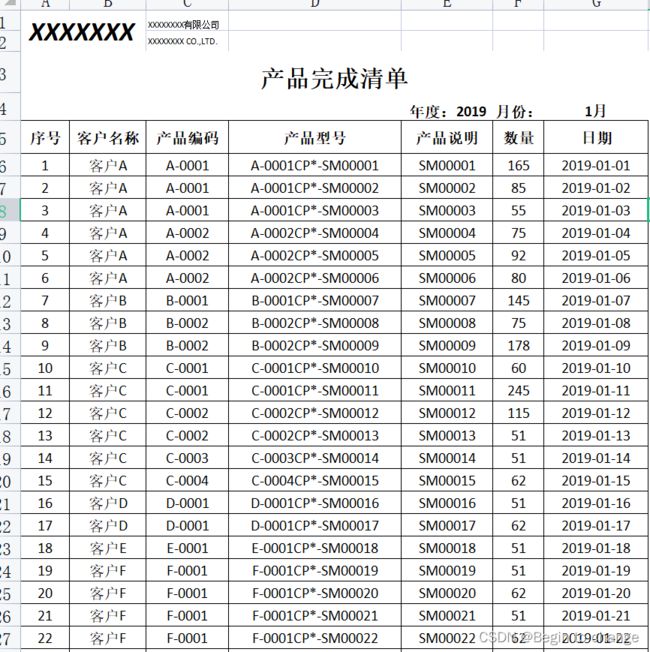
老板一般会要求在打印之前将B,C列上下相邻单元格内容相同的合并成如下这样的:
 二、函数分析
二、函数分析
1、合并单元格函数
#定义合并单元格的函数
def Merge_cells(ws,target_list,start_row,col):
'''
ws: 是需要操作的工作表
target_list: 是目标列表,即含有重复数据的列表
start_row: 是开始行,即工作表中开始比对数据的行(需要将标题除开)
col: 是需要处理数据的列
'''
start = 0 #开始行计数,初试值为0,对应列表中的第1个元素的位置0
end = 0 #结束行计数,初试值为0,对应列表中的第1个元素的位置0
reference = target_list[0] #设定基准,以列表中的第一个字符串开始
for i in range(len(target_list)): #遍历列表
if target_list[i] != reference: #开始比对,如果内容不同执行如下
reference = target_list[i] #基准变成列表中下一个字符串
end = i - 1 #列计数器
ws.merge_cells(col + str(start + start_row) + ":"+col + str(end + start_row))
start = end + 1
if i == len(target_list) - 1: #遍历到最后一行,按如下操作
end = i
ws.merge_cells(col + str(start + start_row) + ":"+ col + str(end + start_row)) 由于合并单元格是一个重复动作,一张工作表的B列和C列都需要使用。对于这种需要重复使用的功能,定义成函数,每用一次调用一次,最为方便。此处,我们先定义一个函数Merge_cells,方便后续调用。这个函数包含四个参数,ws指需要操作的工作表,target_list指目标列表,即B列所有客户名称的列表,或者C列所有产品编码的列表,这些列表中有很多重复项。我们就根据这些重复项的重复次数为依据来判断单元格合并的起始行。
2、获取excel单元中的数据
#获取Excel表格中的数据
from openpyxl import load_workbook #用于读取Excel中的信息
wb = load_workbook('产品清单.xlsx')
sheet_names = wb.get_sheet_names()
for sheet_name in sheet_names: #遍历每个工作表,抓取数据,并根据要求合并单元格
ws = wb[sheet_name]
customer_list = [] #客户名称
pn_list = [] #产品编码
for row in range(6,ws.max_row-2):
customer = ws['B' + str(row)].value
pn = ws['C' + str(row)].value
customer_list.append(customer)
pn_list.append(pn)
#调用以上定义的合并单元格函数`Merge_cells`做单元格合并操作
start_row=6 #开始行是第六行
Merge_cells(ws,customer_list,start_row,"B") #"B" - 客户名称是在B列
Merge_cells(ws,pn_list,start_row,"C") #"C" - 产品编码是在C列
wb.save("产品清单-合并单元.xlsx")三、思路解析
1、合并单元格
合并单元格就是将数值相同的给合并起来,此时的问题就变成了怎么找全这些相同的值?
因为合并的不是简单的一两个单元格,可能有很多个,所以我们要找到的是不相同的值,然后将其上一个和最开始一个的合并即可;而开始的位置就是找到的值不相同的位置,而要合并的最后一个就是最后一个位置的前一个位置;
逻辑清楚之后需要的就是传入的参数,第一个是要操作的工作表(因为工作簿中的工作表不止一个),第二个是要合并的值,存在一个列表中,第三个是第一行开始的行数(因为前面的行不是要处理的数据),第四个是数据所在的列,例如B8就是第B列的第8行的数据
2、获取数据
①首先获取工作簿对象
wb = load_workbook('产品清单.xlsx')②获取工作簿中工作表的名称
sheet_names = wb.get_sheet_names()③ 通过工作表的名称获取工作表的数据
for sheet_name in sheet_names: #遍历每个工作表,抓取数据,并根据要求合并单元格
ws = wb[sheet_name]#获取工作表对象
customer_list = [] #客户名称
pn_list = [] #产品编码
for row in range(6,ws.max_row-2):
customer = ws['B' + str(row)].value#获取第B列各行的值,然后将其值存到列表中
pn = ws['C' + str(row)].value#获取C列各行的值,然后将其值存到列表中
customer_list.append(customer)
pn_list.append(pn)④调用函数进行和平工作表操作
start_row=6 #开始行是第六行
Merge_cells(ws,customer_list,start_row,"B") #"B" - 客户名称是在B列
Merge_cells(ws,pn_list,start_row,"C") #"C" - 产品编码是在C列四、源码
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
def Merge_cells(ws,target_list,start_row,col):
"""
:param ws:是需要操作的工作表
:param target_list: 是目标列表
:param start_row: 是开始行,及工作表中开始比对数据的行
:param col: 是需要处理的列
:return:
"""
start = 0
end = 0
reference = target_list[0]
for i in range(len(target_list)):
if target_list[i] != reference:
reference = target_list[i]
end = i - 1
ws.merge_cells(col + str(start + start_row) + ":" +col + str(end + start_row))
start = end + 1
if i == len(target_list) - 1:
end = i
ws.merge_cells(col + str(start + start_row) + ":" + col + str(end + start_row))
if __name__ == '__main__':
wb = load_workbook('产品清单.xlsx')
sheet_names = wb.get_sheet_names()
for sheet_name in sheet_names:
ws = wb[sheet_name]
customer_list = []
pn_list = []
for row in range(6,ws.max_row - 2):
customer = ws['B' + str(row)].value
pn = ws['C' + str(row)].value
customer_list.append(customer)
pn_list.append(pn)
start_row = 6
Merge_cells(ws,customer_list,start_row,'B')
Merge_cells(ws,pn_list,start_row,'C')
wb.save('产品清单-合并单元.xlsx')
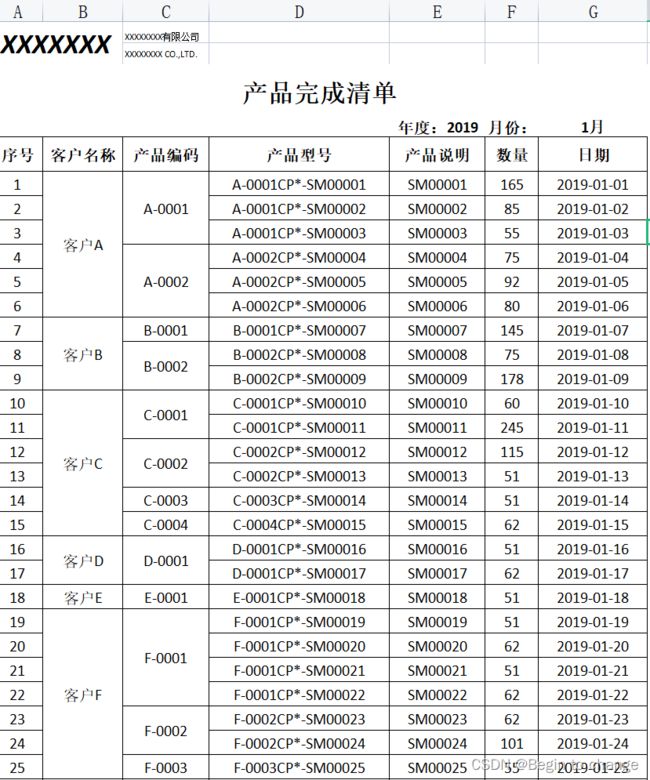
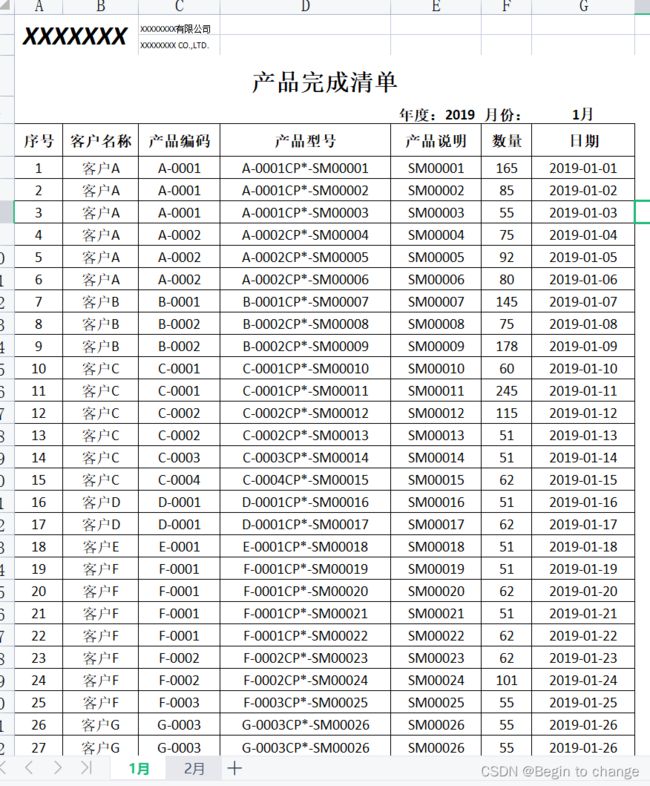
五、效果图
1、合并前
2、合并后