关系数据库标准语言SQL详解
关系数据库标准语言SQL
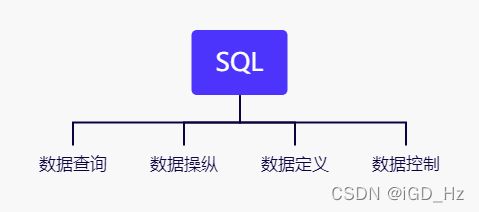
SQL之所以能够为用户和业界所接受并成为国际标准,是因为它是一个综合的、功能极强又简洁易学的语言。SQL集数据查询、数据操作、数据定义和数据控制 功能于一体,其主要特点包括以下几个部分:
综合统一
SQL集数据定义语言、数据操纵语言、数据控制语言的功能于一体,语言风格统一,可以独立完成数据库生命周期中的全部活动。
高度非过程化
SQL进行数据操作时,只要提出“做什么”,而无须指明“怎么做”,因此无须了解存取路径。存取路径的选择以及SQL的操作过程由系统自动完成。
面向集合的操作方法
非关系数据库模型采用面向记录的操作方式,操作对象时一条记录。而SQL采用集合操作方式,不仅操作对象、查找结果可以是元组集合,而且一次插入、删除、更新操作也可以是元组的集合。
以同一语法结构提供多种使用方法
SQL既是独立的语言,又是嵌入式语言
语言简洁,易学易用
1. 数据定义
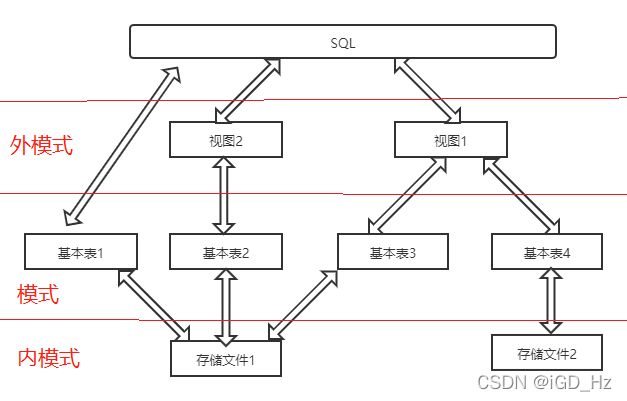
关系数据库支持三级模式结构,其模式、外模式、内模式中的基本对象有模式、表、试图和索引等。因此SQL的数据定义功能包括模式定义、表定义、视图和索引的定义
模式
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据试图。
外模式
外模式也称子模式或用户模式,他是数据库用户(应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示
内模式
内模式也称存储模式,一个数据库只有一个内模式。它是数据物理结构和存储方式的描述,是数据在数据库内部的组织方式
1.1 模式(数据库)的定义与删除
1.1.1 定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名> [<表定义子句>|<试图定义子句>|<授权定义子句>]
在mysql中CREATE SCHEMA与CREATE DATABASE效果一致
![]()
1.1.2 删除模式
DROP SCHEMA <模式名>
CASCADE与RESTRICT二者必选其中一个
CASCADE:级联,表示在删除模式的同时把该模式下所有的数据库对象删除RESTRICT:限制,表示如果模式中已经定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行

1.2 表的定义、删除与修改
1.2.1 数据类型
| 数值 | 类型名 |
|---|---|
| 数值 | tyntint 十分小的数据 1个字节 smallint 较小的数据 2个字节 int 标准的整数 4个字节 bigint 较大的数据 8个字节 float 浮点型 4个字节 double 浮点数 8个字节 decimal 字符串形式的浮点数 |
| 字符串 | char 固定大小的字符串 0~255 vchar 可变字符串 0~65535 tinytext 微型文本 2^8-1 text 文本串 2^16-1 |
| 时间日期 | date YYYY-MM-DD 日期格式 time HH:mm:ss 时间格式 datetime YYYY-MM-DD HH:mm:ss timestamp 时间戳 1970.1.1到现在的毫秒数 year 年份表示 |
1.2.2 基本表的定义
SQL创建数据库基本表的基本格式如下:
CREATE TABLE <表名>(<列名><数据类型> [列级完整性约束条件]
[,<列名><数据类型>[列级完整性约束条件]]
...
[表级完整性约束条件])
例:
CREATE TABLE "S-T".Course ( /*"S-T"模式下的Course表*/
Cno char(4),
Cname char(40) UNIQUE; /*取唯一值*/
Cpno char(4),
FOREIGN KEY (cpno) REFERENCES Course(Cno)
/*表级完整性约束条件,Cpno为外键,被参照表为Course,被参照列为Cno*/
INDEX(`Cno`)
);
1.2.3 修改基本表
SQL修改数据库基本表的基本格式如下:
ALTER TABLE [<模式名>.]<表名>
[ADD [COLUM] <新列名><数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT]]
[DROP CONSTRAINT <完整性约束名> [RESTRICT|CASCADE]]
[ALTER COLUMN <列名><数据类型>];
//添加级联操作
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE;
1.2.4 删除基本表
SQL删除数据库基本表的基本格式如下:
DROP TABLE <表名> [RESTRICT|CASCADE]
1.3 索引
当表的数据量比较大时,查询操作比较耗时。建立索引时加快查询速度的有效手段。数据库索引类似于图书后面的索引,能快速定位道需要查询的内容。
常见的数据库索引有:
- 顺序文件上的索引:针对属性值按升序或降序存储的关系建立一个顺序索引文件,索引文件由属性值和相 应的元组制作组成。
- B+树索引:B+树的叶子结点为属性值和相应的元组指针
- 散列索引:将索引属性按散列函数映射到相应的桶中
- 位图索引:用位向量记录索引属性中可能出现的值
1.3.1 建立索引
SQL中建立索引的基本格式:
CREATE [UNIQUE][CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]...);
- UNIQUE:此索引的每一个索引值只对应唯一的数据记录
- CLUSTER:建立的索引为聚簇索引
1.3.2 修改索引
SQL中修改索引的基本格式:
ALTER INDEX <旧索引名> RENAMETO <新索引名>
1.3.3 删除索引
SQL中删除索引的基本格式:
DROP INDEX <索引名>
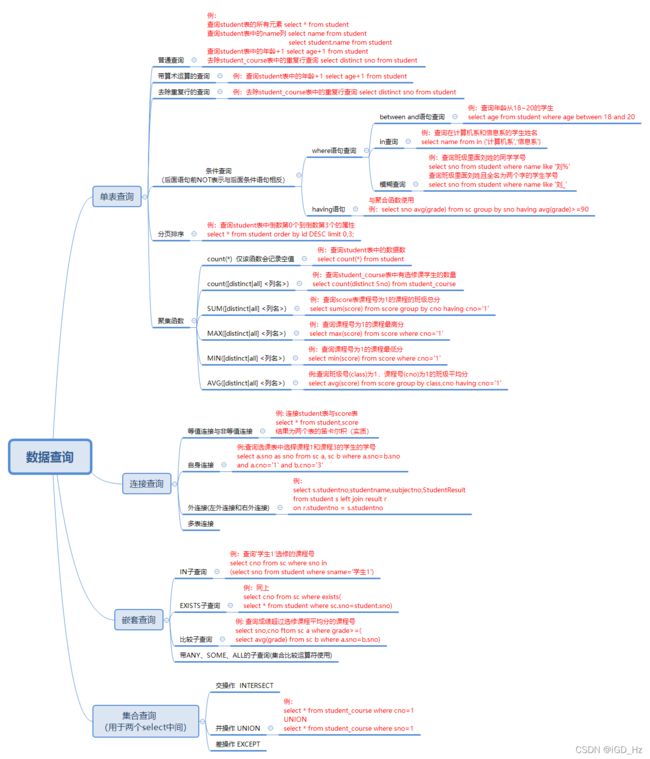
2. 数据查询
SELECT语法
SELECT [ALL | DISTINCT]
{* | table.* | [<列名>[as <别名>][,<列名>[as <表名>]][,...]]}
FROM <表名或视图名> [as <别名>]
[left | right | inner join <表名>] -- 联合查询
[WHERE <条件表达式>] -- 指定结果需满足的条件
[GROUP BY <列名>] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY <列名> [ASC|DESC]] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
[ ] 括号代表可选的 , { }括号代表必选的
2.1 条件查询
| 操作符名称 | 语法 | 描述 |
|---|---|---|
| AND 或 && | a AND b 或 a && b | 逻辑与,同时为真结果才为真 |
| OR 或 || | a OR b 或 a||b | 逻辑或,只要一个为真,则结果为真 |
| NOT 或 ! | NOT a 或 !a | 逻辑非,若操作数为假,则结果为真! |
模糊查找
| 操作符名称 | 语法 | 描述 |
|---|---|---|
| IS NULL | a IS NULL | 若操作符为NULL,则结果为真 |
| IS NOT NULL | a IS NOT NULL | 若操作符不为NULL,则结果为真 |
| BETWEEN | a BETWEEN b AND c | 若 a 范围在 b 与 c 之间,则结果为真 |
| LIKE | a LIKE b | SQL 模式匹配,若a匹配b,则结果为真 |
| IN | a IN (a1,a2,a3,…) | 若 a 等于 a1,a2… 中的某一个,则结果为真 |
模糊查找中字符
| 符号 | 含义 |
|---|---|
| % | '%'表示不限字符个数 |
| _ | '_'表示限制字符数一个(数据库字符集影响汉字的字符数) |
| \ | 转义字符(ESCAPE可以设置转义字符 如:where name like ‘DB\_Desgin’ ESCAPE ‘\’) |
聚合函数
| 聚合函数 | 作用 | 注意事项 |
|---|---|---|
| count(*) | 统计元组个数 | 仅该语句计算过程中包含空值 |
| count([distinct|all] <列名>) | 统计一列中值的个数 | 统计指定列不为NULL的记录行数 |
| max([distinct| all] <列名>) | 求列值中的最大值 | 如果指定列是字符串类型,那么使用字符串排序运算; |
| min([distinct|all] <列名>) | 求列值中的最小值 | 如果指定列是字符串类型,那么使用字符串排序运算 |
| sum([distinct|all] <列名>) | 计算一列值的总和 | 如果指定列类型不是数值类型,那么计算结果为0; |
| avg([distinct|all] <列名>) | 计算一列值的平均值 | 如果指定列类型不是数值类型,那么计算结果为0; |
2.2 连接查询
SELECT [ALL | DISTINCT]
{* | table.* | [<列名>[as <别名>][,<列名>[as <表名>]][,...]]}
FROM <表名或视图名> [as <别名>]
连接查询实质: 查询结果为多个表的笛卡儿积,通过where语句筛选出要查询的数据
| 操作符名称 | 描述 |
|---|---|
| INNER JOIN | 如果表中有至少一个匹配,则返回行 |
| RIGHT JOIN | 即使左表中没有匹配,也从右表中返回所有的行 |
| LEFT JOIN | 即使右表中没有匹配,也从左表中返回所有的行 |
/*
连接查询
如需要多张数据表的数据进行查询,则可通过连接运算符实现多个查询
内连接 inner join
查询两个表中的结果集中的交集
外连接 outer join
左外连接 left join
(以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充)
右外连接 right join
(以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充)
等值连接和非等值连接
自连接
*/
-- 查询参加了考试的同学信息(学号,学生姓名,科目编号,分数)
SELECT * FROM student;
SELECT * FROM result;
/*思路:
(1):分析需求,确定查询的列来源于两个类,student result,连接查询
(2):确定使用哪种连接查询?(内连接)
*/
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
-- 右连接(也可实现)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
RIGHT JOIN result r
ON r.studentno = s.studentno
-- 等值连接
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s , result r
WHERE r.studentno = s.studentno
-- 左连接 (查询了所有同学,不考试的也会查出来)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
-- 查一下缺考的同学(左连接应用场景)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
WHERE StudentResult IS NULL
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectno
2.3 嵌套查询
IN子查询,若select语句查询结果为单行,则 IN等同于 ‘=’EXISTS子查询,exists的返回值为布尔类型,只有当子查询中条件成立是返回对应数据的查询结果- 使用比较运算符的子查询
- 带ANY(有的系统用SOME)ALL的子查询
| 运算符 | 含义 |
|---|---|
| > | 大于 |
| ≥ | 大于等于 |
| < | 小于 |
| ≤ | 小于等于 |
| = | 等于 |
| <> | 不等于 |
/*============== 子查询 ================
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
*/
-- 查询 数据库结构-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列
-- 方法一:使用连接查询
SELECT studentno,r.subjectno,StudentResult
FROM result r
INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE subjectname = '数据库结构-1'
ORDER BY studentresult DESC;
-- 方法二:使用子查询(执行顺序:由里及外)
SELECT studentno,subjectno,StudentResult
FROM result
WHERE subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = '数据库结构-1'
)
ORDER BY studentresult DESC;
3. 数据更新
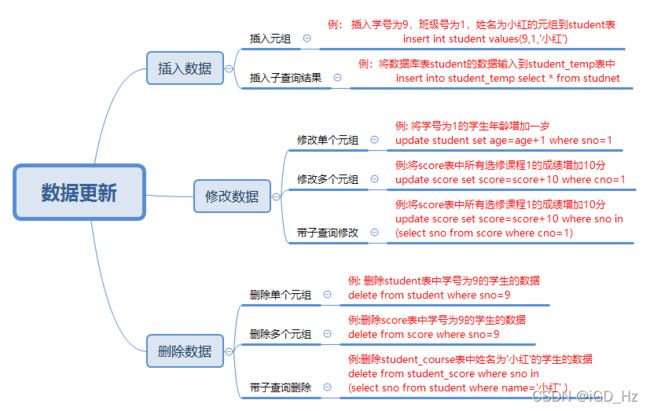
3.1 插入数据
INSERT INTO <表名>[(<列名1>)[,<列名2>]...] VALUES (<常量1>[,<常量2>]...)
INSERT INTO <表名>[(<列名1>)[,<列名2>]...] 子查询
3.2 修改数据
UPDATE <表名> SET <列名>=<表达式>[,<列名>=<表达式>]... [WHERE <条件>]
3.3 删除数据
DELETE FROM <表名> [WHERE <条件>]
空值注意事项
-
空值的判断不能使用比较运算符,需要用
IS NULL和IS NOT NULL表示 -
带
UNIQUE限制的属性不能取空值 -
空值与任何值的算术运算和比较运算为
UNKNOWN,逻辑运算结果如下:x y AND OR NOT T U U T F F U F U T U U U U U U T U T U U F F U U
NULL和IS NOT NULL` 表示
-
带
UNIQUE限制的属性不能取空值 -
空值与任何值的算术运算和比较运算为
UNKNOWN,逻辑运算结果如下:x y AND OR NOT T U U T F F U F U T U U U U U U T U T U U F F U U