“机器学习与深度学习”简要介绍与深度学习Hello World
前言
博主也是自己从零开始自学的,因为感兴趣,所以使用工作外的零散时间坚持学了下来,博主主要工作是工程相关的。整理这篇博客的目的是为了整理一下自己之前学的一些东西,也希望能对感兴趣想自学的同学们有一点点帮助,里面可能有谬误地方,也望指正。
机器学习定义
机器学习研究的是计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身。简单一点说,就是计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务。近年来互联网数据大爆炸,数据的丰富度和覆盖面远远超出人工可以观察和总结的范畴,而机器学习的算法能指引计算机在海量数据中,挖掘出有用的价值。
在李航的《统计学习方法》将机器学习称之为统计机器学习(statical machine learning),做了如下定义:
统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测和分析的一门学科,统计学习也称为统计机器学习。
机器学习分类
按问题分类
Classification 分类问题
根据数据样本上抽取出的特征,判定其属于有限个类别中的哪一个。比如:
垃圾邮件识别(结果类别:1、垃圾邮件 2、正常邮件)
文本情感褒贬分析(结果类别:1、褒 2、贬)
图像内容识别识别(结果类别:1、喵星人 2、汪星人 3、人类 4、草泥马 5、都不是)。
Regression 回归问题
根据数据样本上抽取出的特征,预测一个连续值的结果。比如:
星爷《美人鱼》票房
大帝都2个月后的房价
Cluster 聚类问题
根据数据样本上抽取出的特征,让样本抱抱团(相近/相关的样本在一团内)。比如:
google的新闻分类
用户群体划分
按方法分类
Supervised learning 监督学习
是有特征(feature)和标签(label)的。
举例子理解:高考试题是在考试前就有标准答案的,在学习和做题的过程中,可以对照答案,分析问题找出方法。在高考题没有给出答案的时候,也是可以给出正确的解决。这就是监督学习。
一句话概括:给定数据,预测标签。
通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
Unsupervised learning 无监督学习
只有特征,没有标签。
举例子理解:高考前的一些模拟试卷,是没有标准答案的,也就是没有参照是对还是错,但是我们还是可以根据这些问题之间的联系将语文、数学、英语分开,这个过程就叫做聚类。在只有特征,没有标签的训练数据集中,通过数据之间的内在联系和相似性将他们分成若干类。
一句话概括:给定数据,寻找隐藏的结构,直接对数据集建模。
以上两者的区别:监督学习只利用标记的样本集进行学习,而无监督学习只利用未标记的样本集。
Semi-Supervised learning 半监督学习
使用的数据,一部分是标记过的,而大部分是没有标记的。
和监督学习相比较,半监督学习的成本较低,但是又能达到较高的准确度。综合利用有类标的和没有类标的数据,来生成合适的分类函数。
半监督学习出现的背景:实际问题中,通常只有少量的有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到。
Reinforcement learning 强化学习
强化学习也是使用未标记的数据,但是可以通过一些方法知道你是离正确答案越来越近还是越来越远(奖惩函数)。可以把奖惩函数看作正确答案的一个延迟、稀疏的形式。可以得到一个延迟的反馈,并且只有提示你是离答案越来越近还是越来越远。
关于“如何学机器学习”的一点心得
学习路线图
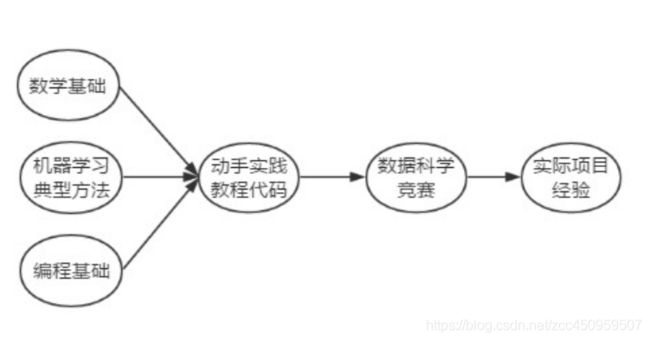
我自己在学的时候是边看算法,边把用到的数学知识再去回忆和研究一下。基本的求导、矩阵点乘、叉乘等需要先知道,这里有一份简单总结。数学相关抠一抠觉得还是能理解的。
机器学习中的数学知识
微积分
微分的计算及其几何、物理含义,是机器学习中大多数算法的求解过程的核心。比如算法中运用到梯度下降法、牛顿法等。如果对其几何意义有充分的理解,就能理解“梯度下降是用平面来逼近局部,牛顿法是用曲面逼近局部”,能够更好地理解运用这样的方法。
凸优化和条件最优化 的相关知识在算法中的应用随处可见,如果能有系统的学习将使得你对算法的认识达到一个新高度。
线性代数
大多数机器学习的算法要应用起来,依赖于高效的计算,这种场景下,程序员GG们习惯的多层for循环通常就行不通了,而大多数的循环操作可转化成矩阵之间的乘法运算,这就和线性代数有莫大的关系了
向量的内积运算更是随处可见。
矩阵乘法与分解在机器学习的主成分分析(PCA)和奇异值分解(SVD) 等部分呈现刷屏状地出现。
概率与统计
从广义来说,机器学习在做的很多事情,和统计层面数据分析和发掘隐藏的模式,是非常类似的。
极大似然思想、贝叶斯模型 是理论基础,朴素贝叶斯(Native Bayes )、语言模型(N-gram)、隐马尔科夫(HMM)、隐变量混合概率模型是他们的高级形态。
常见分布如高斯分布是混合高斯模型(GMM)等的基础。
编程语言与IDE
编程语言
Python和R语言相对较多,推荐Python:
python有着全品类的数据科学工具,从数据获取、数据清洗到整合各种算法都做得非常全面。
- 网页爬虫:
- scrapy
- 数据挖掘:
- pandas:模拟R,进行数据浏览与预处理。
- matplotlib:非常方便的数据可视化工具。
- 机器学习:
- numpy: 数组、矩阵运算。
- scipy:高效的科学计算。
- scikit-learn:远近闻名的机器学习package。未必是最高效的,但是接口真心封装得好,几乎所有的机器学习算法输入输出部分格式都一致。而它的支持文档甚至可以直接当做教程来学习,非常用心。对于不是非常高纬度、高量级的数据,scikit-learn胜任得非常好(有兴趣可以看看sklearn的源码,也很有意思)。
- libsvm:高效率的svm模型实现(了解一下很有好处,libsvm的系数数据输入格式,在各处都非常常见)
- TensorFlow:目前非常主流的深度学习框架,方便地搭建自己的神经网络了,tensorflow其实也支持js、c++等语言,但是主推python。
- 自然语言处理:
- nltk:自然语言处理的相关功能做得非常全面,有典型语料库,而且上手也非常容易。
IDE
推荐IDEA组织的Pycharm工具。
集成环境
建议使用Anaconda环境,该环境能够很方便的解决依赖问题,非常主流,能够非常轻松的安装tensorflow。
如果想体验完整安装tensorflow-gpu过程,可以参考个人博客:
https://blog.csdn.net/zcc450959507/article/details/89672332
机器学习三要素
模型
模型用于决定学习一个什么样的模型。
- 决策函数模型

- 条件概率模型

策略
策略用于定义如何度量一个模型的好坏。
我们定义一下损失函数:它就是通过我们模型预测出来的值和真实值的差距,差距越大,损失函数。
常用的损失函数有如下几种:

算法
算法决定了如何求解最优的模型,一般我们会通过降低训练样本的损失函数期望值来达到求解模型的最优的参数,达到求解最优模型,对于不同模型用到的算法可能比较独特,比如SVM的smo算法、Adaboost的前向加法算法,比较通用的算法有如下算法,算法的详解见对应链接:
- 梯度下降法
- 单个参数变量的梯度下降:
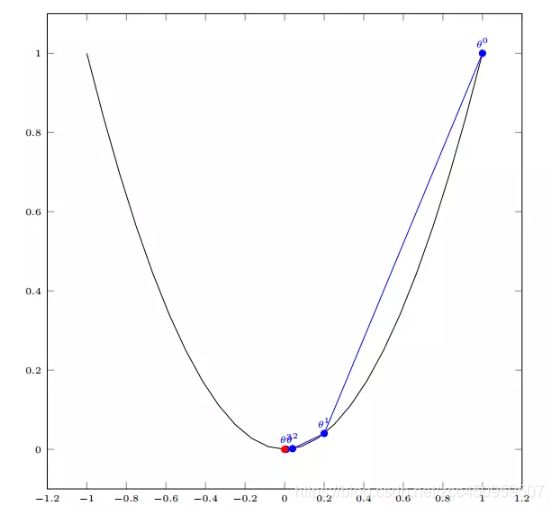
- 多个参数变量的梯度下降:
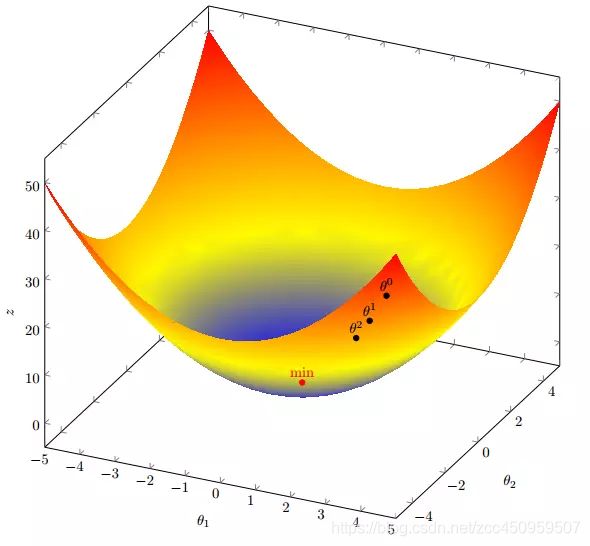
- 全局最小与局部极小:
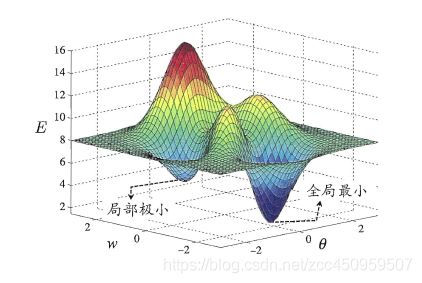
- 随机梯度下降法:
随机梯度下降法是防止陷入“局部极小”比较有效的方法:
使用随机梯度下降,与标准梯度下降法精确计算梯度不同, 随机梯度下降法在计算梯度时加入了随机因素。于是即便陷入局部极小点它计算出的梯度仍可能不为零, 这样就有机会跳出局部极小继续搜索。
假设一个样本(X, Y)的损失函数如下定义:
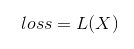
我们随机从所有训练样本中随机选择一批样本数据,我们称为一个mini batch,定义此时的损失函数如下:
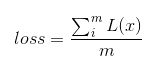
实际上就是随机选择一批样本求损失函数的平均值就是随即梯度下降法的损失值,我们对此时的损失值求解梯度。
- 牛顿法与拟牛顿法

以“逻辑斯特回归分类”为例介绍
深度学习的一个神经元可以看作“逻辑斯特回归分类”演变而来,所以我以该模型为例进行介绍。
- 模型:

我们可以将上面的模型总结为:
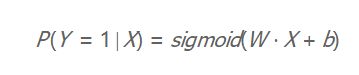
其中sigmoid函数指的是:

函数形状为:
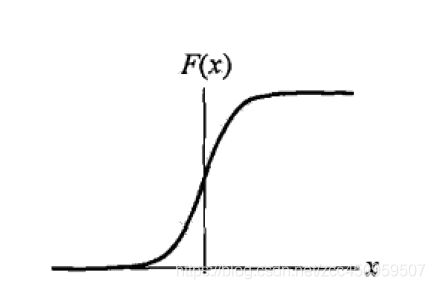
当z=0时,y=0.5,即我们可以认为当z大于0时我们划分到1类,z小于0时划分为0类。
这里z = WX + b
也就是说我们当前的模型是能用于二分类的,我们需要做的就是通过算法得出最优的W和b参数值。 - 策略:

这里我们选择极大似然函数策略,可以认为在前面加一个负号就是我们的损失函数。 - 算法:
我们可以使用梯度下降算法(如果策略没有加负号,就是梯度上升算法)来求解最优的W和b参数值。
W和b梯度推导如下链接:
https://blog.csdn.net/ligang_csdn/article/details/53838743
机器学习的步骤与评估
步骤
- 得到一个有限的训练数据集合;
- 确定包含所有可能的模型的假设空间,即学习模型的集合,即确定选用哪种模型;
- 确定模型选择的准则,即学习的策略;
- 实现求解最优模型的算法,即学习的算法;
- 通过学习算法选择最优模型;
- 利用最优模型对新数据进行预测和分析。
评估
评估一个模型的好坏的能力,称之为“泛化能力”,即模型对未知数据的预测能力。
- 训练误差与测试误差
训练误差就是指模型在训练数据集上的精准度,测试误差就是指模型在测试数据集上的精准度。 - 何为过拟合?
过拟合就是指在训练数据集上预测效果非常好,但是在测试数据集上较差,我们就成该模型过拟合了,如果一味的增加模型复杂度,可能会造成模型在训练数据集上效果越来越好,但是在测试数据集上效果越来越差。
一般情况下训练误差、测试误差和模型复杂度的关系如下:

- 正则化
为了防止模型过拟合,我们在损失函数中增加正则化项,即对参数的惩罚项,能帮助我们选择经验损失(训练数据集损失函数的期望值)和模型复杂度同时较小的模型,从而增强模型的泛化能力。正则化符合奥卡姆剃刀原理,奥卡姆剃刀原理应用于模型选择时变为如下想法:在所有可能选择的模型中,能够很好的解释已知数据并且十分简单的模型才是最好的模型。
正则化一般具有如下形式:
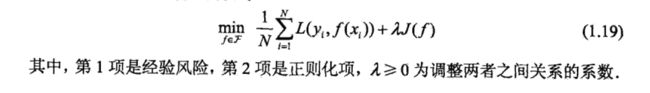
正则化的形式有如下两种常用形式:

- 常用指标
评判一个模型的预测能力的指标有多种,比较常用的像准确率,召回率,PR曲线,ROC曲线等等。下面这个链接讲的比较好,建议直接跳转过去详细看下:
https://blog.csdn.net/weixin_34347651/article/details/88731035
常用传统机器学习算法有哪些?
分类算法
kNN(k近邻法)、DecisionTree(决策树)、NaiveBayes(朴素贝叶斯算法)、SVM(支持向量机算法)、LogisticRegressionClassifier(逻辑斯特回归分类算法)
其中SVM算法比较主流,效果比较好,推导起来也非常复杂。
回归算法
regression(最小二乘法、局部加权回归、岭回归等)、regressionTrees(回归树)
聚类算法
kMeans(k均值算法)、Apriori(关联分析算法)、FP-growth(频繁模式树)
集成与提升
Adaboost(自适应提升算法)、Random forest(随机森林)、GBDT(梯度提升树)
降维方法
PCA(主成分分析)、SVD(奇异值分解)
推荐算法
Collaborative filtering algorithm(协同过滤算法)
上述常用的算法的推导和讲解可以参考网上的资源或者书本资源,基本上每个算法使用scikit-learn框架都有实现,可以直接用。
深度学习
前言
下面以简要介绍为目的,入门详细内容见周志华 -《机器学习》第五章,以及http://neuralnetworksanddeeplearning.com/
强烈建议把这两个链接的完整阅读完,后边这个对于入门非常重要,里面不仅会介绍深度全连接神经网络的一步一步构成和梯度公式的推导,还有各种DNN中用到的trick,还会解释为何DNN能够模拟任意函数关系,强烈建议阅读完一遍,这样会对DNN有一个全面的理解。下面是这个网站的译文链接:
https://mp.weixin.qq.com/s/t-UPSoVnwSD7XT6IxbE-Wg
深度学习与机器学习的关系
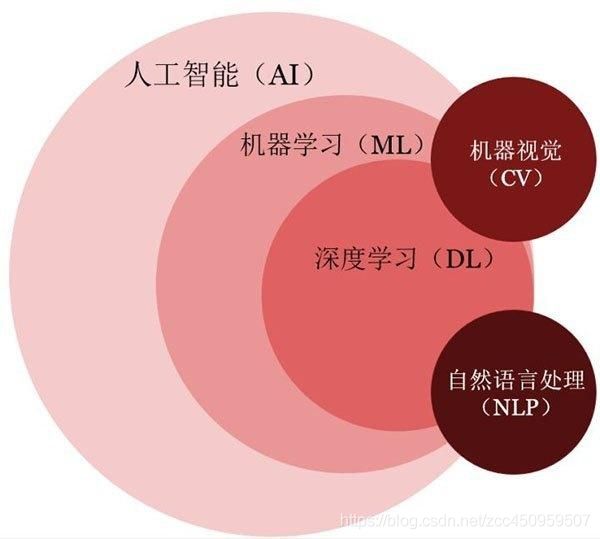
我的理解,可以认为深度学习是使用神经网络模型来表示机器学习的三要素中的模型。
深度学习发展历史
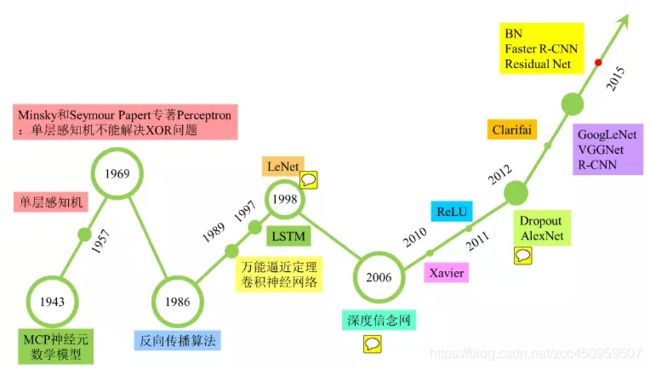
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引到了众多研究者的注意。
神经元单元
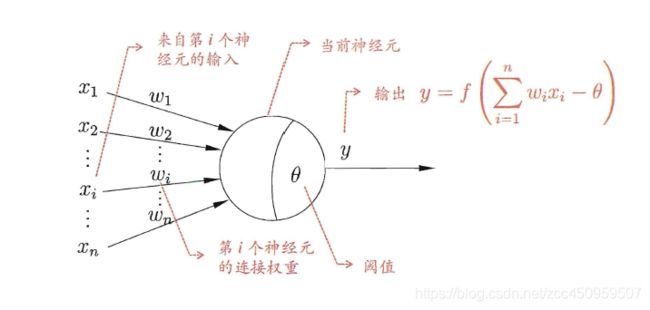
我们能看到一个典型的神经元单元其实就是一个逻辑斯特回归模型,我们也称为感知机,sigmoid函数在这里我们成为神经元的激活函数(当然激活函数还有很多种),但是逻辑斯特回归无法做到非线性分类,那么我们通过神经元的组合就能满足我们的非线性分类的需求。
全连接多层神经网络
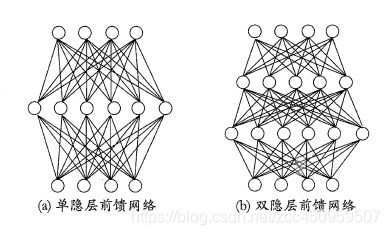
我们称第一层和最后一层为输入输出层,中间层为隐藏层,全连接则指的是每一层每一个神经元与前一层的每一个神经元都相连,前一层相当于本层神经元的输入。
误差逆传播算法
我们以单隐层神经网络为例:
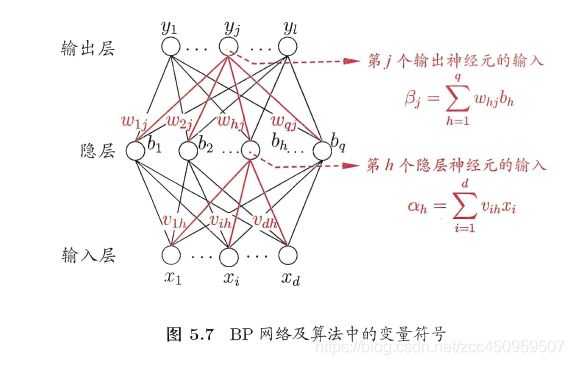

我们知道如下求导公式的链式法则:

这个结论可推广到任意有限个函数复合到情形,于是复合函数的导数将是构成复合这有限个函数在相应点的 导数的乘积,就像锁链一样一环套一环,故称链式法则。
我们可以认为神经网络输出层相对于前面每一层每一个神经元的参数都是一个复合函数,所以我们只需求出每一层所有参数的梯度,就可以使用梯度下降法来寻找最优参数了,因为我们是自上往下推导每一层参数梯度的,所以我们称该算法为误差逆传播算法。
具体求导过程见周志华 - 《机器学习》第五章,这里不再详细推导。
之前写过一个误差逆传播算法的实现代码,见下面这个链接:
https://github.com/zhaocc1106/machine_learn/blob/master/NeuralNetworks/ErrBackPropagation.py
代码实践过程中能发现一个多层神经网络能够很容易的做分线性分类。
实际上,一个深度足够的神经网络能够模拟实际上任何函数(X->Y),这里X和Y代表输入和输出向量。这个是有证明的,具体证明的过程见如下链接:
http://neuralnetworksanddeeplearning.com/chap4.html
tensorflow有一个很形象的工具,能让我们更直观的理解全连接神经网络,如下链接:
https://playground.tensorflow.org/?hl=zh-cn
梯度消失问题与不同的激活函数
我们发现当神经网络越来越深,对于sigmoid tanh函数来说,越往两侧梯度越小,导致神经网络越往前的层的梯度会越来越小直至消失,所以就出现了不同的激活函数来解决该问题。


参数初始化
选择优秀的参数初始化能够避免梯度消失,也可加快和提升训练效果。
https://zhuanlan.zhihu.com/p/25110150
正则化
如之前的讲解,正则化是为了防止我们的模型过拟合,包括L1、L2、Dropout等。
Softmax激活函数与交叉熵损失函数
- Softmax激活函数
我们发现Sigmoid激活函数作为输出层的话实际上适合二分类,为处理多分类的问题,我们引入了Softmax激活函数:
我们假设有n个输出,则对于第i个输出Yi经过激活函数后的输出值Zi如下定义:
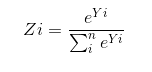
能看出所有的Yi之和为1,所以我们可以认为这是一个概率模型,比如有10个分类,每个分类对应一个输出,概率值最大的就是我们预测的结果。 - 交叉熵损失函数
对应于有多个概率输出,我们有交叉熵损失函数可以代替之前的平方误差损失函数,它更符合概率模型。定义如下:
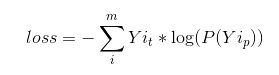
其中Yi_t代表真实概率值,Yi_p代表模型预测的概率值。
交叉熵损失函数还能简化梯度逆传播的算法,见如下链接讲解:
http://neuralnetworksanddeeplearning.com/chap3.html#the_cross-entropy_cost_function
全连接神经网络代码实现
- 纯numpy版本
下面是包含多种提升方法的全连接神经网络的代码实现,包括了初始化方法、正则化方法、不同激活函数,使用纯numpy实现,详细分解神经网络的梯度逆传播过程。
https://github.com/zhaocc1106/machine_learn/blob/master/NeuralNetworks/ImprovedFullConnectedNN.py
卷积神经网络(CNN)
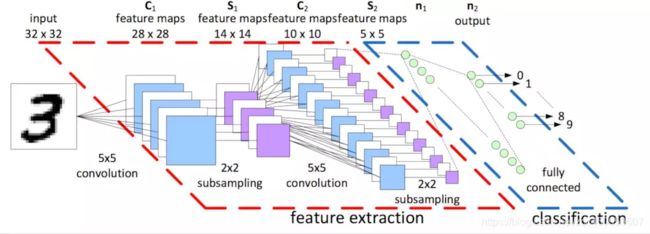
下面这个链接讲解的比较好,我们直接参考下面的链接:
https://www.jianshu.com/p/49b70f6480d1
直观理解卷积:

以上图为例:第一次卷积可以提取出低层次的特征。
第二次卷积可以提取出中层次的特征。
第三次卷积可以提取出高层次的特征。
特征是不断进行提取和压缩的,最终能得到比较高层次特征,简言之就是对原式特征一步又一步的浓缩,最终得到的特征更可靠。利用最后一层特征可以做各种任务:比如分类、回归等。
包含卷积层的神经网络可以称之为卷积神经网络。
更多深度学习模型
RNN(循环卷积神经网络)、DCGAN(深度卷积对抗生成网络)、Deep reinforcement learning(深度强化学习模型)等。
比较常见的应用场景
- CNN
图像分类与识别、目标检测等等。 - RNN
自然语音处理、你画我猜等。 - GAN
模仿画家画画等。 - Deep reinforcement learning
自动驾驶、游戏中AI、AlphaGo等等。
深度学习框架
当前有很多深度学习框架,比如流行的tensorflow、Keras、PyTorch、以及我们公司的PaddlePaddle等。
使用这些框架的话我们只需关心我们自己神经网络的层定义不需要关心梯度计算过程,他们为我们定义了各种通用的神经网络层,会以较快的方式帮我们完成梯度的计算和参数优化。
Tensor是什么?
tensor是tensorflow基础的一个概念——张量。
Tensorflow用到了数据流图,数据流图包括数据(Data)、流(Flow)、图(Graph)。Tensorflow里的数据用到的都是tensor,所以谷歌起名为tensorflow。
下面介绍张量几个比较重要的概念
张量的维度(秩):Rank/Order
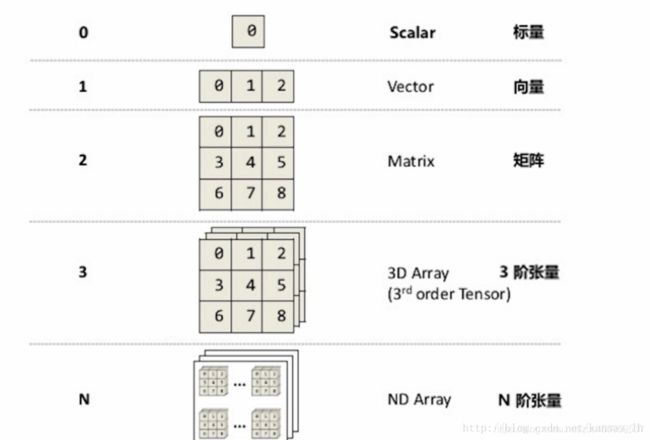
Rank为0、1、2时分别称为标量、向量和矩阵,Rank为3时是3阶张量,Rank大于3时是N阶张量。这些标量、向量、矩阵和张量里每一个元素被称为tensor element(张量的元素),且同一个张量里元素的类型是保持一样的。
深度学习的Hello World
https://colab.research.google.com/drive/1kSpWbpMWjtx4HX8LqkE9hMF8NwPzrL3v
参考资料
书籍方面我这边主要看了如下五本书
Aurelien Geron - 《Hands-On Machine Learning with Scikit-learn & TensorFlow》:非常推荐这本书,这本书以实践的方式带你学习机器学习与深度学习,教你如何使用当前主流的机器学习框架库,Scikit-Learn和TensorFlow,理论知识点到为止,没有过多的数学推导,但是会让你明白各个算法的原理。同时里面会有很多经验分享,比如如何选择正则化方式、如何选择深度学习的激活函数和优化器、如何选择SVM的核函数、如何选择超参数。特别是当机器学习库给你提供多种选择给你,纠结选择的时候,这本书里会有很多经验帮你选择。这本书中文版为王静源、贾玮等人翻译《机器学习实战》。
李航 -《统计学习方法》:主要介绍主流监督学习算法,对于每个算法都有非常详细的数学推导。
Peterr Harrington -《机器学习实战》:以实际代码编写入手,用纯numpy实现主流的机器学习算法,注重代码编写,理论相对较少,建议和其他算法推导的书籍资料结合着看。
周志华 - 《机器学习》:本书作为该领域的入门教材,在内容上尽可能涵盖机器学习基础知识的各方面,
作者试图尽可能少地使用数学知识. 然而, 少量的概率、统计、代数、优化、逻辑知识似乎不可避免。
黄文坚 - 《tensorflow实战》:以实战方式讲解tensorflow框架,教你如何使用tensorflow实现自己的神经网络。
还有很多书都值得看,参考下面这个博客最后部分:
https://blog.csdn.net/longxinchen_ml/article/details/50749614
网络资料
scikit-learn官网:主流机器学习算法的介绍和使用样例。
tensorflow官网:深度学习框架。
http://neuralnetworksanddeeplearning.com/ 深度学习和神经网络的入门书籍,包含大量细节的讲解。
代码实践
个人的代码仓库如下链接:
https://github.com/zhaocc1106/machine_learn
包含一些常用传统机器学习算法的numpy版实现和简要介绍。
包含了深度学习的代码实践,包括简单DNN、CNN、RNN、迁移学习、对抗生成网络、深度强化学习网络、目标检测等。
结尾
希望能和同样对机器学习感兴趣的同学一同坚持学习下去。