Linux指令合集
50个必备指令
修改环境变量
sudo vim /etc/profile; //修改里面的宏定义
source /etc/profile; //使得修改生效
lsof
List Open File。lsof命令用于查看某个进程打开的文件描述符。常用的方式就是通过ps获取进程的PID,然后通过lsof查看进程打开的所有描述符。
wangjun@ubuntu:~/Desktop/MyWebServer/Debug$ lsof -p 5110
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
MyWebServ 5110 wangjun cwd DIR 8,1 4096 2 /
MyWebServ 5110 wangjun rtd DIR 8,1 4096 2 /
MyWebServ 5110 wangjun txt REG 8,1 1617712 1050164 /home/wangjun/Desktop/MyWebServer/Debug/MyWebServer
MyWebServ 5110 wangjun mem REG 8,1 1088952 691787 /lib/x86_64-linux-gnu/libm-2.23.so
MyWebServ 5110 wangjun mem REG 8,1 1868984 691792 /lib/x86_64-linux-gnu/libc-2.23.so
MyWebServ 5110 wangjun mem REG 8,1 89696 660858 /lib/x86_64-linux-gnu/libgcc_s.so.1
MyWebServ 5110 wangjun mem REG 8,1 1566440 918111 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21
MyWebServ 5110 wangjun mem REG 8,1 138696 691791 /lib/x86_64-linux-gnu/libpthread-2.23.so
MyWebServ 5110 wangjun mem REG 8,1 162632 691790 /lib/x86_64-linux-gnu/ld-2.23.so
MyWebServ 5110 wangjun 0u CHR 1,3 0t0 6 /dev/null
MyWebServ 5110 wangjun 1u CHR 1,3 0t0 6 /dev/null
MyWebServ 5110 wangjun 2u CHR 1,3 0t0 6 /dev/null
MyWebServ 5110 wangjun 3u a_inode 0,11 0 8121 [eventpoll]
MyWebServ 5110 wangjun 4u a_inode 0,11 0 8121 [eventfd]
MyWebServ 5110 wangjun 5u IPv4 65441 0t0 TCP *:8888 (LISTEN)
MyWebServ 5110 wangjun 6u a_inode 0,11 0 8121 [eventpoll]
MyWebServ 5110 wangjun 7u a_inode 0,11 0 8121 [eventfd]
MyWebServ 5110 wangjun 8u a_inode 0,11 0 8121 [eventpoll]
MyWebServ 5110 wangjun 9u a_inode 0,11 0 8121 [eventfd]
MyWebServ 5110 wangjun 10u a_inode 0,11 0 8121 [eventpoll]
MyWebServ 5110 wangjun 11u a_inode 0,11 0 8121 [eventfd]
MyWebServ 5110 wangjun 12u a_inode 0,11 0 8121 [eventpoll]
MyWebServ 5110 wangjun 13u a_inode 0,11 0 8121 [eventfd]
MyWebServ 5110 wangjun 14u IPv4 65452 0t0 TCP localhost:8888->localhost:45320 (ESTABLISHED)
MyWebServ 5110 wangjun 15u IPv4 65458 0t0 TCP localhost:8888->localhost:45322 (ESTABLISHED)
MyWebServ 5110 wangjun 16u IPv4 65465 0t0 TCP localhost:8888->localhost:45324 (ESTABLISHED)

##Valgrind使用说明
valgrind --tool=memcheck --leak-check=full ./MyWebServer
可以很方便的检测内存泄漏,段错误,返回值等等。
##vi
##awk
1、awk简介
awk程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等,非常适合处理文档。通过在每一行上面执行
命令的方式,输出人们需要的格式。
AWK遵循了非常简单的工作流程。
1、读取输入流种的一行。
2、执行,AWK对每一行执行命令,我们可以通过提供模式限制这种行为。
3、重复读取-执行-重复直到到达文件结尾。
2、awk程序的结构
awk ‘pattern { action }’ filename
awk的基本操作是一行一行地扫描输入,搜索匹配任意程序中模式的行。词语“匹配”的准确意义是视具体的模式而言,
每个模式依次测试每个输入行。对于匹配到行的模式,其对应的动作得到执行,然后读取下一行并继续匹配,直到所有的输入读取完毕。
3、awk中关键字
-F参数:指定分隔符,可指定一个或多个
文件中每一行通过设定的分隔符(默认空格可通过-F设定),分割成几个字段。
$1表示第一个字段,$2表示第二个字段,$n表示第n个字段。
NF表示每一行字段数目。
$NF表示最后一个字段。
NR存储当前已经读取了多少行。可以用来打印行数
RS表示每一行结束符。
在输出中可以添加自己的内容awk '{ print "total pay for", $1, "is", $2 * $3 }' filename
BEGIN块:通常,对于每个输入行, awk 都会执行每个脚本代码块一次。然而,在许多编程情况中,可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况, awk允许您定义一个BEGIN块。awk在开始处理输入文件之前会先执行BEGIN块一次,因此它是初始化FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会引用的全局变量的极佳位置。
END块:awk在处理了输入文件中的所有行之后执行这个块一次。通常,END块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
4、简单例子
//1、awk结合grep可以很方便的使用
cat close.txt | grep 'localhost' | awk '{print NR , $0 , $3 , $4 , $5}'
//2、只查看test.txt文件(100行)内第20到第30行的内容
awk 'if(NR >= 20 && NR <= 30 ) print $1' filename.txt
//3、统计/etc/passwd的账户人数
awk 'BEGIN {count=0;print "[start] user count is ",count} {count=count+1;print $0} END{print "[end] user count is ",count}' /etc/passwd
awk ' BEGIN {count = 0 ; print "[start] user count is" , count} {count++ ; print $0} END {print "[end] user count is", count}' /etc/passwd
[start] user count is 0
.................
[end] user count is 44
直接使用内建变量NR
awk 'END {print "user count is" , NR}' /etc/passwd
user count is 44
//4、统计某个文件夹下的文件占用的字节数
ls -l | awk 'BEGIN {size = 0} {size += $5} END{print "total size is" , size}'
total size is 77547
https://www.cnblogs.com/ginvip/p/6352157.html
##gcc编译器搜索Linux下头文件路径
对于头文件从高到低的优先级顺序是:
1、在编译的时候使用I参数直接指定的。
2、环境变量C_INCLUDE_PATH、CPP_INCLUDE_PATH中设定的。
3、/usr/local/include
4、/usr/include
对于库文件从高到低的优先级顺序是:
1、/usr/local/lib/
2、/usr/lib/
所以开源框架,安装的库文件和头文件都在上面对应的文件中,这个必须明白哦,需要哪些头文件,直接到相应的文件夹里面去寻找即可。
##ls

最常用的指令就是ls -al详细显示所以文件或目录信息。
wangjun@ubuntu:~$ ls -al
total 312
drwxr-xr-x 22 wangjun wangjun 4096 May 18 21:33 .
drwxr-xr-x 3 root root 4096 Oct 15 2017 ..
-rwxrwxr-x 1 wangjun wangjun 8736 Oct 30 2017 a.out
-rw-rw-r-- 1 wangjun wangjun 107 Oct 27 2017 .apport-ignore.xml
-rw------- 1 wangjun wangjun 21911 May 18 21:26 .bash_history
-rw-r--r-- 1 wangjun wangjun 220 Oct 15 2017 .bash_logout
-rw-r--r-- 1 wangjun wangjun 3771 Oct 15 2017 .bashrc
drwx------ 17 wangjun wangjun 4096 Mar 29 07:03 .cache
drwx------ 23 wangjun wangjun 4096 Apr 24 06:56 .config
drwx------ 3 root root 4096 Oct 15 2017 .dbus
drwxr-xr-x 9 wangjun wangjun 4096 May 18 21:01 Desktop
-rw-r--r-- 1 wangjun wangjun 25 Oct 15 2017 .dmrc
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Documents
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Downloads
-rw-rw-r-- 1 wangjun wangjun 2858 Apr 13 01:53 :d:wq
-rw-r--r-- 1 wangjun wangjun 8980 Oct 15 2017 examples.desktop
drwx------ 3 wangjun wangjun 4096 May 18 19:35 .gconf
drwx------ 3 wangjun wangjun 4096 May 18 19:35 .gnupg
-rw------- 1 wangjun wangjun 33382 May 18 19:35 .ICEauthority
-rw-rw-r-- 1 wangjun wangjun 151 Mar 15 20:29 index.html
drwx------ 3 wangjun wangjun 4096 Oct 15 2017 .local
drwx------ 5 wangjun wangjun 4096 Nov 26 03:18 .mozilla
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Music
-rw------- 1 root root 56472 May 5 06:40 .mysql_history
-rw-rw-r-- 1 wangjun wangjun 107 Apr 11 00:54 number.sh
-rw-rw-r-- 1 wangjun wangjun 8788 Apr 16 05:51 output.txt
-rw-rw-r-- 1 wangjun wangjun 1646 Apr 11 00:54 phonelist.txt
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Pictures
drwx------ 2 wangjun wangjun 4096 Oct 15 2017 .presage
-rw-r--r-- 1 wangjun wangjun 675 Oct 15 2017 .profile
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Public
drwxrwxr-x 8 wangjun wangjun 4096 Oct 15 2017 Qt5.7.0
drwxr-xr-x 2 wangjun wangjun 4096 Mar 3 05:36 .rpmdb
drwxrwxr-x 2 wangjun wangjun 4096 May 18 19:36 .sogouinput
-rw-r--r-- 1 wangjun wangjun 0 Oct 15 2017 .sudo_as_admin_successful
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Templates
-rw-rw-r-- 1 wangjun wangjun 205 Oct 30 2017 test.c
drwxrwxr-x 2 wangjun wangjun 4096 Oct 15 2017 untitled
drwxr-xr-x 2 wangjun wangjun 4096 Oct 15 2017 Videos
-rw------- 1 wangjun wangjun 7736 May 18 21:33 .viminfo
-rw------- 1 wangjun wangjun 51 May 18 19:35 .Xauthority
-rw-rw-r-- 1 wangjun wangjun 132 Oct 15 2017 .xinputrc
-rw------- 1 wangjun wangjun 82 May 18 19:35 .xsession-errors
-rw------- 1 wangjun wangjun 82 May 17 20:08 .xsession-errors.old
下图详细介绍上述信息。

硬连接:相当于一个文件的别名,默认每个文件都有一个硬链接(每个文件都有文件名)。所以硬链接不能引用目录(因为是文件别名),不能引用与该链接不在同一分区的文件。硬连接删除,仅仅删除这个链接,文件本身没有删除,除非该文件所有链接都删除了。
软链接(符号链接):类似于windows的快捷方式,是另外一种独立的文件,相当于里面存储了文件的绝对路径,访问符号链接就是访问相应的绝对地址。删除符号链接,仅仅删除链接本身,而没有删除文件。所以符号链接使用广泛,可以解决硬链接的两个缺点。
ln -s file softlink
ln file hardlink
##man
将开源项目对应的.m文件放入man相应的目录下面,就可以通过man索引相应的帮助文档了。
##/etc/bash.bashrc
##tar
tar命令可以通过gzip或bzip2来打包和压缩文件。



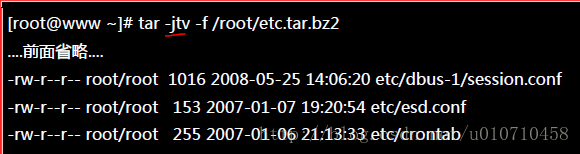
- 为什么会有警告讯息?因为他要去掉/根目录。假如存在就是绝对路径,解压出来直接覆盖/etc里面的内容。否则若在home文件下面解压则是~/etc目录下面。
- 如果确定需要备份,倒是解压出来直接覆盖原来文件,就加上 -P
tar -[j|z]cv -f filemame.tar.bz2 filename //通过bz2或gz压缩文件。
tar -[j|z]tv -f filemame.tar.bz2 //查看bz2或gz压缩文件。
tar -[j|z]xv -f filemame.tar.bz2 dir//将bz2或gz压缩文件解压到dir。
##cp
cp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录。它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下。cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文件参数必须是一个已经存在的目录,否则将出现错误。
语法
cp(选项)(参数)
选项
-a:此参数的效果和同时指定"-dpR"参数相同,复制文件和目录及其属性,包括所有权和权限。通常来说,复制的文件具有用户所操作文件的默认属性。
-d:当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录;
-f:强行复制文件或目录,不论目标文件或目录是否已存在;
-i:覆盖既有文件之前先询问用户;
-l:对源文件建立硬连接,而非复制文件;
-p:保留源文件或目录的属性;
-r:递归处理,将指定目录下的所有文件与子目录一同复制,因为有子目录所以得递归;
-s:对源文件建立符号连接,而非复制文件;
-u:当将文件从一个目录复制到另外一个目录时,只会复制目标目录中不存在的或模板目录相应文件的更新。
-v:详细显示命令执行过程的信息性消息。

##rm
rm命令可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉。对于链接文件,只是删除整个链接文件,而原有文件保持不变。
注意:使用rm命令要格外小心。因为一旦删除了一个文件,就无法再恢复它。所以,在删除文件之前,最好再看一下文件的内容,确定是否真要删除。rm命令可以用-i选项,这个选项在使用文件扩展名字符删除多个文件时特别有用。使用这个选项,系统会要求你逐一确定是否要删除。这时,必须输入y并按Enter键,才能删除文件。如果仅按Enter键或其他字符,文件不会被删除。
语法
rm (选项)(参数)
选项
-d:直接把欲删除的目录的硬连接数据删除成0,删除该目录;
-f:忽略不存在的文件,强制删除文件或目录;
-i:删除已有文件或目录之前先询问用户;
-r:递归删除目录,如果删除目录下有子目录,也要删除,那么必须加递归参数,否则仅仅删除目录下文件。
--preserve-root:不对根目录进行递归操作;
-v:显示指令的详细执行过程。

##mv
mv命令用来执行文件移动或者文件重命名操作,注意这两种操作下,原来的文件名将不存在,相当于windows下面的剪切操作。
语法
mv(选项)(参数)
选项
-b:当文件存在时,覆盖前,为其创建一个备份;
-f:若目标文件或目录与现有的文件或目录重复,则直接覆盖现有的文件或目录;
-i:交互式操作,覆盖前先行询问用户,如果源文件与目标文件或目标目录中的文件同名,则询问用户是否覆盖目标文件。用户输入”y”,表示将覆盖目标文件;输入”n”,表示取消对源文件的移动。这样可以避免误将文件覆盖。
-S<后缀>:为备份文件指定后缀,而不使用默认的后缀;
--target-directory=<目录>:指定源文件要移动到目标目录;
-u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。

##in
##traceroute
通过traceroute我们可以知道数据包从你的计算机到互联网另一端的主机是走的什么路径(通过哪些路由器)。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。
traceroute通过发送小的数据包到目的设备直到其返回,来测量其需要多长时间。一条路径上的每个设备traceroute要测3次(所以返回3个时间)。输出结果中包括每次测试的时间(ms)和设备的名称(如有的话)及其ip地址。
工作原理:
Traceroute最简单的基本用法是:traceroute hostname
Traceroute程序的设计是利用ICMP及IP header的TTL。首先,traceroute送出一个TTL是1的IP datagram(其实,每次送出的为3个40字节的包,包括源地址,目的地址和包发出的时间标签)到目的地,当路径上的第一个路由器(router)收到这个datagram时,它将TTL减1。此时,TTL变为0了,所以该路由器会将此datagram丢掉,并送回一个(ICMP time exceeded)消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),traceroute 收到这个消息后,便知道这个路由器存在于这个路径上;接着traceroute 再送出另一个TTL是2 的datagram,发现第2 个路由器… traceroute 每次将送出的datagram的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个datagram 抵达目的地。当datagram到达目的地后,该主机并不会送回ICMP time exceeded消息,因为它已是目的地了。
命令参数:
-d 使用Socket层级的排错功能。
-f 设置第一个检测数据包的存活数值TTL的大小。
-F 设置勿离断位。
-g 设置来源路由网关,最多可设置8个。
-i 使用指定的网络界面送出数据包。
-I 使用ICMP回应取代UDP资料信息。注意虚拟机里面必须使用ICMP选项才可以。
-m 设置检测数据包的最大存活数值TTL的大小。
-n 直接使用IP地址而非主机名称。
-p 设置UDP传输协议的通信端口。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-s 设置本地主机送出数据包的IP地址。
-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程。
-w 设置等待远端主机回报的时间。
-x 开启或关闭数据包的正确性检验。
简单例子:
$ sudo traceroute -I www.58.com
traceroute to www.58.com (154.8.240.21), 30 hops max, 60 byte packets
1 192.168.24.2 (192.168.24.2) 0.187 ms 0.141 ms 0.098 ms
2 10.26.0.1 (10.26.0.1) 21.245 ms 21.703 ms 21.627 ms
3 172.20.0.5 (172.20.0.5) 12.187 ms 14.217 ms 14.247 ms
4 172.20.0.10 (172.20.0.10) 14.184 ms 14.121 ms 14.056 ms
5 222.24.254.2 (222.24.254.2) 15.616 ms 15.822 ms 17.954 ms
6 172.20.128.9 (172.20.128.9) 13.747 ms 19.694 ms 19.414 ms
7 172.20.128.1 (172.20.128.1) 19.074 ms 12.170 ms 9.934 ms
8 222.90.67.193 (222.90.67.193) 91.267 ms 91.357 ms 91.183 ms
9 10.224.13.13 (10.224.13.13) 9.683 ms 9.641 ms 8.645 ms
10 117.36.240.69 (117.36.240.69) 12.029 ms 9.875 ms 6.715 ms
11 202.97.79.142 (202.97.79.142) 32.189 ms 28.512 ms 28.476 ms
12 221.238.7.182 (221.238.7.182) 37.530 ms 37.483 ms *
13 221.239.85.238 (221.239.85.238) 882.093 ms 878.499 ms 878.436 ms
14 123.150.32.114 (123.150.32.114) 30.458 ms 30.355 ms 32.269 ms
15 * * *
16 154.8.240.21 (154.8.240.21) 31.160 ms 29.232 ms 32.017 ms
记录按序列号从1开始,每个纪录就是一跳(一个路由器),每跳表示一个网关,我们看到每行有三个时间,单位是ms,其实就是-q的默认参数。探测数据包向每个网关发送三个数据包后,网关响应后返回的时间;如果用traceroute -q 4 www.58.com,表示向每个网关发送4个数据包。
有时我们traceroute一台主机时,会看到有一些行是以星号表示的。出现这样的情况,可能是防火墙封掉了ICMP的返回信息,所以我们得不到什么相关的数据包返回数据。
有时我们在某一网关处延时比较长,有可能是某台网关比较阻塞,也可能是物理设备本身的原因。当然如果某台DNS出现问题时,不能解析主机名、域名时,也会 有延时长的现象;您可以加-n参数来避免DNS解析,以IP格式输出数据。
如果在局域网中的不同网段之间,我们可以通过traceroute 来排查问题所在,是主机的问题还是网关的问题。如果我们通过远程来访问某台服务器遇到问题时,我们用到traceroute 追踪数据包所经过的网关,提交IDC服务商,也有助于解决问题;但目前看来在国内解决这样的问题是比较困难的,就是我们发现问题所在,IDC服务商也不可能帮助我们解决。
##free
可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
语法:
free(选项)
选项:
-b:以Byte为单位显示内存使用情况;
-k:以KB为单位显示内存使用情况;
-m:以MB为单位显示内存使用情况;
-o:不显示缓冲区调节列;
-s<间隔秒数>:持续观察内存使用状况;
-t:显示内存总和列;
-V:显示版本信息。
~$ free -m
total used free shared buff/cache available
Mem: 1982 271 1035 8 675 1521
Swap: 1021 0 1021
第一部分Mem行解释:
- total:内存总数;
- used:已经使用的内存数;
- free:空闲的内存数;
- shared:当前已经废弃不用;
- buffers Buffer:缓存内存数;
- cached Page:缓存内存数。
- 关系:total = used + free
##du
是显示当前目录下全部文件件使用磁盘空间的情况,这个可以区别于df。
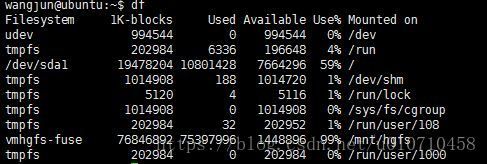
##df
df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
##top
top命令可以实时动态地查看系统的整体运行情况类似于windows的任务管理器方便查看进程的资源使用情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理。类似于windows的任务管理器。
top(选项)
选项:
-b:以批处理模式操作;
-c:显示完整的治命令;
-d:屏幕刷新间隔时间;
-I:忽略失效过程;
-s:保密模式;
-S:累积模式;
-i<时间>:设置间隔时间;
-u<用户名>:指定用户名;
-p<进程号>:指定进程;
-n<次数>:循环显示的次数。
top交互命令:
执行了top之后,可以使用的一些交互式快捷键。
h:显示帮助画面,给出一些简短的命令总结说明;
k:终止一个进程;
i:忽略闲置和僵死进程,这是一个开关式命令;
q:退出程序;
r:重新安排一个进程的优先级别;
S:切换到累计模式;
s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
f或者F:从当前显示中添加或者删除项目;
o或者O:改变显示项目的顺序;
l:切换显示平均负载和启动时间信息;
m:切换显示内存信息;
t:切换显示进程和CPU状态信息;
c:切换显示命令名称和完整命令行;
M:根据驻留内存大小进行排序;
P:根据CPU使用百分比大小进行排序;
T:根据时间/累计时间进行排序;
w:将当前设置写入~/.toprc文件中。
~$ top
top - 22:31:20 up 1:21, 1 user, load average: 0.00, 0.01, 0.00
Tasks: 188 total, 1 running, 187 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2029828 total, 1060248 free, 278312 used, 691268 buff/cache
KiB Swap: 1046524 total, 1046524 free, 0 used. 1557980 avail Mem
解释:
- top - 09:44:56[当前系统时间],
- 16 days[系统已经运行了16天],
- 1 user[个用户当前登录],
- load average: 9.59, 4.75, 1.92[系统负载,即任务队列的平均长度]
- Tasks: 145 total[总进程数],
- 2 running[正在运行的进程数],
- 143 sleeping[睡眠的进程数],
- 0 stopped[停止的进程数],
- 0 zombie[冻结进程数],
- Cpu(s): 99.8%us[用户空间占用CPU百分比],
- 0.1%sy[内核空间占用CPU百分比],
- 0.0%ni[用户进程空间内改变过优先级的进程占用CPU百分比],
- 0.2%id[空闲CPU百分比], 0.0%wa[等待输入输出的CPU时间百分比],
- 0.0%hi[],
- 0.0%st[],
- Mem: 4147888k total[物理内存总量],
- 2493092k used[使用的物理内存总量],
- 1654796k free[空闲内存总量],
- 158188k buffers[用作内核缓存的内存量]
- Swap: 5144568k total[交换区总量],
- 56k used[使用的交换区总量],
- 5144512k free[空闲交换区总量],
- 2013180k cached[缓冲的交换区总量],
##su和sudo
#su [-lm] [-c 指令] [username]
选项与参数:
-:单纯使用-如“ su - ”代表使用login-shell的变量文件读取方式来登陆系统;
若使用者名称没有加上去,则代表切换为root 的身份。
-l :与-类似,但后面需要加欲切换的使用者帐号,也是 login-shell 的方式。
-m :-m 与 -p 是一样的,表示“使用目前的环境设置,而不读取新使用者的配置文件”
-c :仅通过root执行一次指令,所以 -c 后面可以加上指令喔!
exit可以退出su模式。
su: Authentication failure的解决办法:
通过下面方法更新password即可。
$sudo passwd root
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
su #切换root
exit #退出root
su -l wang #切换到wang
su -c ls #通过root执行ls
sudo是su授权可以使用root的指令,需要输入字节的密码。
权限不够可以直接使用sudo + 指令即可执行一次root权限的指令。
##last
用于显示用户最近登录信息。单独执行last命令,它会读取/var/log/wtmp的文件,并把该给文件的内容记录的登入系统的用户名单全部显示出来。
##netstat
Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Memberships) 等等。
列出所有连接
第一个要介绍的,是最简单的命令:列出#所有当前的连接,使用 -a 选项即可。
netstat -a
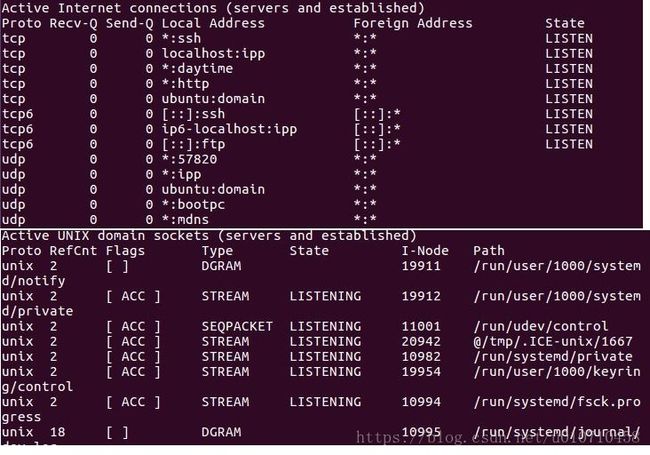
从整体上看,netstat的输出结果可以分为两个部分:
一个是Active Internet connections,称为有源TCP/UDP连接,其中"Recv-Q"和"Send-Q"指%0A的是接收队列和发送队列。这些数字一般都应该是0。如果不是则表示软件包正在队列中堆积。这种情况只能在非常少的情况见到。
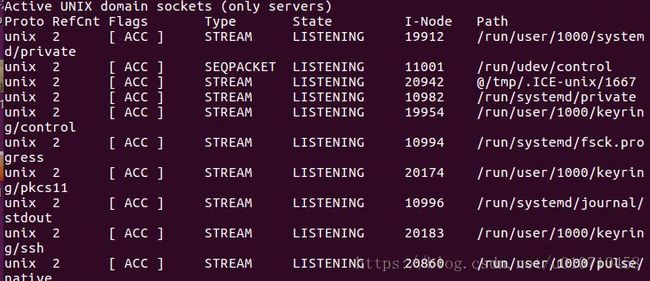
另一个是Active UNIX domain sockets,称为有源Unix域套接口(和网络套接字一样,但是只能用于本机通信,性能可以提高一倍)。
Proto显示连接使用的协议,RefCnt表示连接到本套接口上的进程号,Types显示套接口的类型,State显示套接口当前的状态,Path表示连接到套接口的其它进程使用的路径名。
本地地址为*:ssh其中*号是通配符。
远端地址为*:*表示还不知道远端IP地址和端口号,因为该端还处于Listen状态,正在等待连接请求到达。
netstat常见参数
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服务状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
提示:LISTEN和LISTENING的状态只有用-a或者-l才能看到
列出所有端口 netstat -a
列出所有TCP端口 netstat -at
列出所有UDP端口 netstat -au
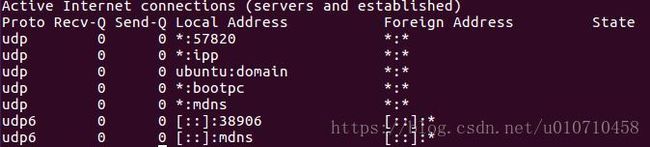
只显示监听端口 netstat -l
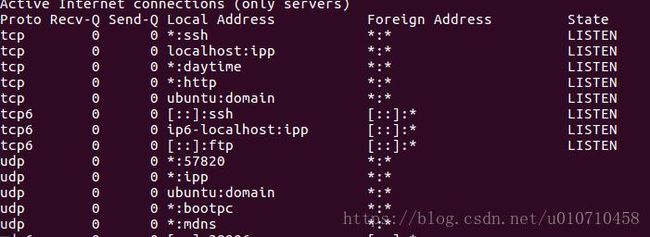
只列出所有监听tcp端口 netstat -lt
只列出所有监听 udp 端口 netstat -lu
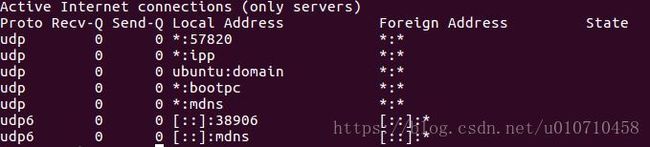
只列出所有监听 UNIX 端口 netstat -lx
显示所有端口的统计信息 netstat -s
显示TCP或UDP端口的统计信息netstat -st 或 -su
省略
在netstat输出中显示PID和进程名称netstat -p
netstat -p 可以与其它开关一起使用,就可以添加 “PID/进程名称” 到 netstat 输出中,这样 debugging 的时候可以很方便的发现特定端口运行的程序。
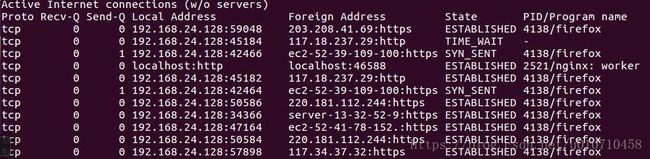
在netstat输出中不显示主机,端口和用户名 (host, port or user)
当你不想让主机,端口和用户名显示,使用 netstat -n。将会使用数字代替那些名称。同样可以加速输出,因为不用进行比对查询。
netstat -an
如果只是不想让这三个名称中的一个被显示,使用以下命令
netsat -a --numeric-ports
netsat -a --numeric-hosts
netsat -a --numeric-users
持续输出netstat信息
netstat -c 将每隔一秒输出网络信息。
显示核心路由信息 netstat -r

注意: 使用 netstat -rn 显示数字格式,不查询主机名称。
找出程序运行的端口
并不是所有的进程都能找到,没有权限的会不显示,使用 root 权限查看所有的信息。
netstat -ap | grep ssh
![]()
找出运行在指定端口的进程
netstat -an | grep ‘:80’
显示网络接口列表
netstat -i
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 0 12645 0 0 0 8261 0 0 0 BMRU
lo 65536 0 1340 0 0 0 1340 0 0 0 LRU
显示详细信息,像是 ifconfig 使用 netstat -ie:
Kernel Interface table
ens33 Link encap:Ethernet HWaddr 00:0c:29:b2:33:f1
inet addr:192.168.24.128 Bcast:192.168.24.255 Mask:255.255.255.0
inet6 addr: fe80::39c1:3ac4:ce03:a69e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12690 errors:0 dropped:0 overruns:0 frame:0
TX packets:8282 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2861450 (2.8 MB) TX bytes:1956369 (1.9 MB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:1348 errors:0 dropped:0 overruns:0 frame:0
TX packets:1348 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:139762 (139.7 KB) TX bytes:139762 (139.7 KB)
查看连接某服务端口最多的的IP地址
netstat -nat | grep "192.168.1.15:22" |awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -20
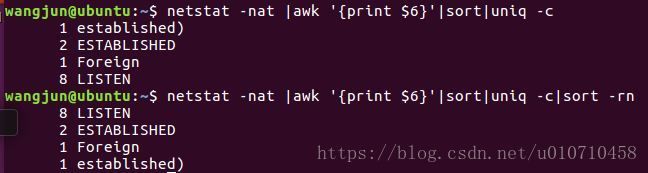
TCP各种状态列表
netstat -nat |awk '{print $6}'
established)
Foreign
LISTEN
LISTEN
LISTEN
LISTEN
LISTEN
ESTABLISHED
LISTEN
LISTEN
LISTEN
先把状态全都取出来,然后使用uniq -c统计,之后再进行排序

最后的命令如下
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
分析access.log获得访问前10位的ip地址
awk '{print $1}' access.log |sort|uniq -c|sort -nr|head -10
参考:https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316661.html
##ifstat
##sysctl
##kill
发送信号的指令
kill命令用来删除执行中的程序或工作。kill可将指定的信息送至程序。预设的信息SIGTERM(15),可将指定程序终止。若仍无法终止该程序,可使用SIGKILL(9)信息尝试强制删除程序,程序或工作的编号可利用ps指令或job指令查看。
kill(选项)(参数)
选项:
-a:当处理当前进程时,不限制命令名和进程号的对应关系;
-l <信息编号>:若不加<信息编号>选项,则-l参数会列出全部的信息名称;
-p:指定kill 命令只打印相关进程的进程号,而不发送任何信号;
-s <信息名称或编号>:指定要送出的信息;
-u:指定用户。
参数:
进程或作业识别号:指定要删除的进程或作业
~$ kill -l //显示所以信号编号及其名字
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
//只有第9种信号(SIGKILL)才可以无条件终止进程,其他信号进程都有权利忽略。
列表中,编号为1 ~ 31的信号为传统UNIX支持的信号,是不可靠信号(非实时的),编号为32 ~ 63的信号是后来扩充的,称做可靠信号(实时信号)。不可靠信号和可靠信号的区别在于前者不支持排队(多个信号同时到了,仅仅一个有效),可能会造成信号丢失,而后者不会。
下面我们对编号小于SIGRTMIN的信号进行讨论。
- SIGHUP
本信号在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联。
登录Linux时,系统会分配给登录用户一个终端(Session)。在这个终端运行的所有程序,包括前台进程组和后台进程组,一般都属于这个Session。当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号。这个信号的默认操作为终止进程,因此前台进程组和后台有终端输出的进程就会中止。不过可以捕获这个信号,比如wget能捕获SIGHUP信号,并忽略它,这样就算退出了Linux登录,wget也能继续下载。
此外,对于与终端脱离关系的守护进程,这个信号用于通知它重新读取配置文件。
2) SIGINT
程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl-C)时发出,用于通知前台进程组终止进程。
3) SIGQUIT
和SIGINT类似,但由QUIT字符(通常是Ctrl-/)来控制. 进程在因收到SIGQUIT退出时会产生core文件,在这个意义上类似于一个程序错误信号。
-
SIGILL
执行了非法指令. 通常是因为可执行文件本身出现错误, 或者试图执行数据段. 堆栈溢出时也有可能产生这个信号。 -
SIGTRAP
由断点指令或其它trap指令产生. 由debugger使用。 -
SIGABRT
调用abort函数生成的信号。 -
SIGBUS
非法地址, 包括内存地址对齐(alignment)出错。比如访问一个四个字长的整数,但其地址不是4的倍数。它与SIGSEGV的区别在于后者是由于对合法存储地址的非法访问触发的(如访问不属于自己存储空间或只读存储空间)。 -
SIGFPE
在发生致命的算术运算错误时发出。不仅包括浮点运算错误,还包括溢出及除数为0等其它所有的算术的错误。
9) SIGKILL
用来立即结束程序的运行。本信号不能被阻塞、处理和忽略。如果管理员发现某个进程终止不了,可尝试发送这个信号。
- SIGUSR1
留给用户使用
11) SIGSEGV
这是经常发生的错误信号。
试图访问未分配给自己的内存, 或试图往没有写权限的内存地址写数据。
-
SIGUSR2
留给用户使用 -
SIGPIPE
管道破裂。这个信号通常在进程间通信产生,比如采用FIFO(管道)通信的两个进程,读管道没打开或者意外终止就往管道写,写进程会收到SIGPIPE信号。此外用Socket通信的两个进程,写进程在写Socket的时候,读进程已经终止。 -
SIGALRM
时钟定时信号, 计算的是实际的时间或时钟时间. alarm函数使用该信号. -
SIGTERM
程序结束(terminate)信号,与SIGKILL不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出,shell命令kill缺省产生这个信号。如果进程终止不了,我们才会尝试SIGKILL。 -
SIGCHLD
子进程结束时, 父进程会收到这个信号。
如果父进程没有处理这个信号,也没有等待(wait)子进程,子进程虽然终止,但是还会在内核进程表中占有表项,这时的子进程称为僵尸进程。这种情况我们应该避免(父进程或者忽略SIGCHILD信号,或者捕捉它,或者wait它派生的子进程,或者父进程先终止,这时子进程的终止自动由init进程来接管)。
18) SIGCONT
让一个停止(stopped)的进程继续执行. 本信号不能被阻塞. 可以用一个handler来让程序在由stopped状态变为继续执行时完成特定的工作. 例如, 重新显示提示符
19) SIGSTOP
停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行。本信号不能被阻塞, 处理或忽略.
-
SIGTSTP
停止进程的运行, 但该信号可以被处理和忽略. 用户键入SUSP字符时(通常是Ctrl-Z)发出这个信号 -
SIGTTIN
当后台作业要从用户终端读数据时, 该作业中的所有进程会收到SIGTTIN信号. 缺省时这些进程会停止执行. -
SIGTTOU
类似于SIGTTIN, 但在写终端(或修改终端模式)时收到. -
SIGURG
有"紧急"数据或out-of-band数据到达socket时产生. -
SIGXCPU
超过CPU时间资源限制. 这个限制可以由getrlimit/setrlimit来读取/改变。 -
SIGXFSZ
当进程企图扩大文件以至于超过文件大小资源限制。 -
SIGVTALRM
虚拟时钟信号. 类似于SIGALRM, 但是计算的是该进程占用的CPU时间. -
SIGPROF
类似于SIGALRM/SIGVTALRM, 但包括该进程用的CPU时间以及系统调用的时间. -
SIGWINCH
窗口大小改变时发出.
29) SIGIO
文件描述符准备就绪,可以开始进行输入/输出操作。
- SIGPWR
Power failure
31) SIGSYS
非法的系统调用。
在以上列出的信号中:
1、程序不可捕获、阻塞或忽略的信号有:SIGKILL,SIGSTOP
2、不能恢复至默认动作的信号有:SIGILL,SIGTRAP
3、默认会导致进程流产的信号有:
SIGABRT,SIGBUS,SIGFPE,SIGILL,SIGIOT,SIGQUIT,SIGSEGV,SIGTRAP,SIGXCPU,SIGXFSZ
3、默认会导致进程退出的信号有:
SIGALRM,SIGHUP,SIGINT,SIGKILL,SIGPIPE,SIGPOLL,SIGPROF,SIGSYS,SIGTERM,SIGUSR1,SIGUSR2,SIGVTALRM
4、默认会导致进程停止的信号有:SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU
5、默认进程忽略的信号有:SIGCHLD,SIGPWR,SIGURG,SIGWINCH
此外,SIGIO在SVR4是退出,在4.3BSD中是忽略;SIGCONT在进程挂起时是继续,否则是忽略,不能被阻塞。
//常见信号及其组合快捷键
HUP 1 终端断线
INT 2 中断(同Ctrl + C)
QUIT 3 退出(同Ctrl + \)
TERM 15 终止
KILL 9 强制终止
CONT 18 继续(与STOP相反,fg/bg命令)
STOP 19 暂停(同Ctrl + Z)
##ps

输入ps -aux


ps工具标识进程的5种状态码:
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header "STAT"
or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
For BSD formats and when the stat keyword is used, additional characters may be displayed:
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group
注: 其它状态还包括W(无驻留页), <(高优先级进程), N(低优先级进程), L(内存锁页).
Linux进程状态:R (TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
Linux进程状态:S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
Linux进程状态:D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
Linux进程状态:T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。)
向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
Linux进程状态:Z (TASK_DEAD – EXIT_ZOMBIE)
退出状态,进程成为僵尸进程。
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
Linux进程状态:X (TASK_DEAD – EXIT_DEAD)
退出状态,进程即将被销毁。
##nc
##wget
##curl
##pstack
pstack命令可显示每个进程的栈跟踪。pstack命令必须由相应进程的属主或root运行。可以使用 pstack 来确定进程挂起的位置。此命令允许使用的唯一选项是进程的PID。
##itrace
是用来跟踪进程调用库函数的情况。类似与strace。
##strace
strace常用来跟踪进程执行时的系统调用和所接收的信号,并将系统调用名、参数、返回值及信号名输出到标准输出或者指定的文件。这是调试网络程序的绝佳利器,可以直到程序最后阻塞在哪个系统调用上,并最后返回值是多少等情况。
strace参数
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出,以秒了表示时间.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column
设置返回值的输出位置.默认 为40.
-e expr
指定一个表达式,用来控制如何跟踪.格式如下:
[qualifier=][!]value1[,value2]...
qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:
-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none.
注意有些shell使用!来执行历史记录里的命令,所以要使用\\.
-e trace=set
只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file
只跟踪有关文件操作的系统调用.
-e trace=process
只跟踪有关进程控制的系统调用.
-e trace=network
跟踪与网络有关的所有系统调用.
-e strace=signal
跟踪所有与系统信号有关的 系统调用
-e trace=ipc
跟踪所有与进程通讯有关的系统调用
-e abbrev=set
设定 strace输出的系统调用的结果集.-v 等与 abbrev=none.默认为abbrev=all.
-e raw=set
将指 定的系统调用的参数以十六进制显示.
-e signal=set
指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set
输出从指定文件中读出 的数据.例如:
-e read=3,5
-e write=set
输出写入到指定文件中的数据.
-o filename
将strace的输出写入文件filename
-p pid
跟踪指定的进程pid.
-s strsize
指定输出的字符串的最大长度.默认为32.文件名一直全部输出.
-u username
以username 的UID和GID执行被跟踪的命令
输出参数含义
@ubuntu:~$ strace cat /dev/null
execve("/bin/cat", ["cat", "/dev/null"], [/* 62 vars */]) = 0
brk(NULL) = 0x1c5d000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=95323, ...}) = 0
mmap(NULL, 95323, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7fca9670a000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\t\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1868984, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fca96709000
mmap(NULL, 3971488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7fca96133000
mprotect(0x7fca962f3000, 2097152, PROT_NONE) = 0
mmap(0x7fca964f3000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1c0000) = 0x7fca964f3000
mmap(0x7fca964f9000, 14752, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7fca964f9000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fca96708000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fca96707000
arch_prctl(ARCH_SET_FS, 0x7fca96708700) = 0
mprotect(0x7fca964f3000, 16384, PROT_READ) = 0
mprotect(0x60b000, 4096, PROT_READ) = 0
mprotect(0x7fca96722000, 4096, PROT_READ) = 0
munmap(0x7fca9670a000, 95323) = 0
brk(NULL) = 0x1c5d000
brk(0x1c7e000) = 0x1c7e000
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=2981280, ...}) = 0
mmap(NULL, 2981280, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7fca95e5b000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 18), ...}) = 0
open("/dev/null", O_RDONLY) = 3
fstat(3, {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 3), ...}) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
mmap(NULL, 139264, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fca966e5000
read(3, "", 131072) = 0
munmap(0x7fca966e5000, 139264) = 0
close(3) = 0
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
每一行都是一条系统调用,等号左边是系统调用的函数名及其参数,右边是该调用的返回值。
strace 显示这些调用的参数并返回符号形式的值。strace 从内核接收信息,而且不需要以任何特殊的方式来构建内核。
通用的完整用法
strace -o output.txt -T -tt -e trace=all -p 28979
上面的含义是跟踪28979进程的所有系统调用(-e trace=all),并统计系统调用的花费时间,以及开始时间(并以可视化的时分秒格式显示),最后将记录结果存在output.txt文件里面。
用strace调试程序
发现这个过程现在正在做什么
突然一个进程拥有大量的CPU?还是有一个过程似乎挂?然后你找到pid。
strace -p pid
直接跟踪进程pid,看到进程现在正在调用哪个函数,卡在了哪里,超级牛逼。
解决库依赖问题
这里时用strace跟踪 whoami时的输出。可以看出调用了哪些库,错误出在哪里,这个程序很牛逼。
什么在花费时间?
直接strace -c -p pid。然后不用管,继续运行pid进程,什么时候想看统计的时间信息,直接结束strace即可。
##ipcs和ipcrm
ipcs用于报告Linux中进程间通信设施的状态,显示的信息包括消息列表、共享内存和信号量的信息。
ipcrm命令用来删除一个或更多的消息队列、信号量集或者共享内存标识。
ipcs(选项)
选项:
-a:显示全部可显示的信息;
-q:显示活动的消息队列信息;
-m:显示活动的共享内存信息;
-s:显示活动的信号量信息。
ipcrm [ -m SharedMemoryID ] [ -M SharedMemoryKey ] [ -q MessageID ] [ -Q MessageKey ] [ -s SemaphoreID ] [ -S SemaphoreKey ]
选项:
-m 通过SharedMemory id删除共享内存标识 SharedMemoryID。与 SharedMemoryID 有关联的共享内存段以及数据结构都会在最后一次拆离操作后删除。
-M 通过SharedMemoryKey 删除用关键字 SharedMemoryKey 创建的共享内存标识。与其相关的共享内存段和数据结构段都将在最后一次拆离操作后删除。
-q 通过MessageID 删除消息队列标识 MessageID 和与其相关的消息队列和数据结构。
-Q 通过MessageKey 删除由关键字 MessageKey 创建的消息队列标识和与其相关的消息队列和数据结构。
-s 通过SemaphoreID 删除信号量标识 SemaphoreID 和与其相关的信号量集及数据结构。
-S 通过SemaphoreKey 删除由关键字 SemaphoreKey 创建的信号标识和与其相关的信号量集和数据结构。
#ipcs -a
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x7401833d 2654208 root 600 4 0
0x00000000 3145729 root 600 4194304 9 dest
0x7401833c 2621442 root 600 4 0
0xd201012b 3080195 root 600 1720 2
#ipcs -m 2654208 //通过id删除
##uptime
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载
uptime(选项)
-V:显示指令的版本信息。
[root@LinServ-1 ~]# uptime -V #显示uptime命令版本信息
procps version 3.2.7
[root@LinServ-1 ~]# uptime
15:31:30 up 127 days, 3:00, 1 user, load average: 0.00, 0.00, 0.00
显示内容说明:
15:31:30 //系统当前时间
up 127 days, 3:00 //主机已运行时间,时间越大,说明你的机器越稳定。
1 user //用户连接数,是总连接数而不是用户数
load average: 0.00, 0.00, 0.00 // 系统平均负载,统计最近1,5,15分钟的系统平均负载
那么什么是系统平均负载呢? 系统平均负载是指在特定时间间隔内运行队列中的平均进程数。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的。如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
##cat

进行文件拼接并显示到标准输出,可以利用重定向功能使其输出到文件里面。
可用于显示文本,也可以用与创建文本。
例子1:
root@ubuntu:~/Desktop/nginx-1.0.15$ cat > foo.txt
this is a demo
root@ubuntu:~/Desktop/nginx-1.0.15$ cat foo.txt
this is a demo
root@ubuntu:~/Desktop/nginx-1.0.15$ cat -A foo.txt
this is a demo$
说明:重定向到文件,然后输入文本内容,按下Enter,最后按下Ctrl+D告诉到达文件末尾。不重定向则用于显示文件。
例子2:输出多行
root@ubuntu:~/Desktop/nginx-1.0.15$ cat << END
> this 1
> this 2
> this 3
> END
输出:
this 1
this 2
this 3
例子3:输出重定向到文件
cat << END > Makefile
default: build
clean:
rm -rf Makefile $NGX_OBJS
END
说明:Here Document操作。END和END之间的多行消息,传递给cat,并将cat输出重定向到Makefile文件,也就是将下面多行消息写入到Makefile。
##2、more
##3、less
##iostat
iostat用于从系统开机到当前执行时刻的统计信息,输出CPU和磁盘I/O相关的统计信息。
用法:iostat [ 选项 ] [ <时间间隔> [ <次数> ]]
常用选项说明:
-c:只显示系统CPU统计信息,即单独输出avg-cpu结果,不包括device结果。
-d:单独输出Device结果,不包括cpu结果。
-k/-m:输出结果以kB/mB为单位,而不是以扇区数为单位。
-x:输出更详细的io设备统计信息。
interval/count:每次输出间隔时间,count表示输出次数,不带count表示循环输出
~$ iostat -x #输出CPU和Device设备详细信息
Linux 4.4.0-121-generic (ubuntu) 05/06/2018 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.40 0.10 0.35 0.06 0.00 99.09
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.60 1.47 0.24 24.46 12.54 43.23 0.01 3.74 0.69 22.46 0.92 0.16
输出含义:
avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值。重点关注
iowait值:表示CPU用于等待每一个IO请求的处理的平均时间(单位是毫秒),这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
Device: 各磁盘设备的IO统计信息。各列含义如下:
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
Blk_read/s: 每秒读扇区数量(一扇区为512bytes)
Blk_wrtn/s: 每秒写扇区数量
Blk_read: 取样时间间隔内读扇区总数量
Blk_wrtn: 取样时间间隔内写扇区总数量
util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
##free
这个命令用于显示系统当前内存的使用情况,包括已用内存、可用内存和交换内存的情况。
默认情况下free会以字节为单位输出内存的使用量。
$ free
total used free shared buffers cached
Mem: 3566408 1580220 1986188 0 203988 902960
-/+ buffers/cache: 473272 3093136
Swap: 4000176 0 4000176
如果你想以其他单位输出内存的使用量,需要加一个选项,-g为GB,-m为MB,-k为KB,-b为字节。
$ free -g
total used free shared buffers cached
Mem: 3 1 1 0 0 0
-/+ buffers/cache: 0 2
Swap: 3 0 3
如果你想查看所有内存的汇总,请使用-t选项,使用这个选项会在输出中加一个汇总行。
ramesh@ramesh-laptop:~$ free -t
total used free shared buffers cached
Mem: 3566408 1592148 1974260 0 204260 912556
-/+ buffers/cache: 475332 3091076
Swap: 4000176 0 4000176
Total: 7566584 1592148 5974436
##top
top命令会显示当前系统中占用资源最多的一些进程(默认以CPU占用率排序)如果你想改变排序方式,可以在结果列表中点击O(大写字母O)会显示所有可用于排序的列,这个时候你就可以选择你想排序的列
#非交互式文本编辑指令
用简单的命令一次性更改多个文件。
##1、tr-删除和替换字符
用于将标准输入的字符进行替换、压缩和删除。
tr [选项]… string1 [string2]
选项说明:
最常用:
-c, -C, –complement指定String1值用String1所指定的字符串的补码替换。
-d, –delete 从标准输入删除string1中出现的任意字符。
-s, –squeeze-repeats 删除所有重复出现字符序列,只保留第一个。需要去重的字符集string1指定,重复字符必须连续否则不起作用。
-t, –truncate-set1 先删除第一字符集较第二字符集多出的字符
没有指定选项则默认从标准输入中将String1中所包含的每一个字符都替换成String2中相同位置上的字符。
字符集合的范围:
\NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
\\ 反斜杠
\a Ctrl-G 铃声
\b Ctrl-H 退格符
\f Ctrl-L 走行换页
\n Ctrl-J 新行
\r Ctrl-M 回车
\t Ctrl-I tab键
\v Ctrl-X 水平制表符
CHAR1-CHAR2 从CHAR1 到 CHAR2的所有字符按照ASCII字符的顺序
[CHAR*] in SET2, copies of CHAR until length of SET1
[CHAR*REPEAT] REPEAT copies of CHAR, REPEAT octal if starting with 0
[:alnum:] 所有的字母和数字
[:alpha:] 所有字母
[:blank:] 水平制表符,空白等
[:cntrl:] 所有控制字符
[:digit:] 所有的数字
[:graph:] 所有可打印字符,不包括空格
[:lower:] 所有的小写字符
[:print:] 所有可打印字符,包括空格
[:punct:] 所有的标点字符
[:space:] 所有的横向或纵向的空白
[:upper:] 所有大写字母
最常用的用法:
tr -c -d -s ["string1_to_translate_from"] ["string2_to_translate_to"] < input-file
1、将文件file中出现的"abc"替换为"xyz"
这里,凡是在t.txt文件中出现的"a"字母,都替换成"x"字母,"b"字母替换为"y"字母,“c"字母替换为"z"字母。而不是将字符串"abc"替换为字符串"xyz”。这里的替换不修改源文件。
[root@Gin scripts]# cat t.txt
abc
[root@Gin scripts]# cat t.txt |tr "abc" "xyz"
xyz
[root@Gin scripts]# cat t.txt
abc
2、使用tr命令“统一”字母大小写
[root@Gin scripts]# cat file
abc
[root@Gin scripts]# cat file|tr [a-z] [A-Z]
ABC
3、把文件中的数字0-9替换为a-j
标准输入中的数字,替换成字母。
[root@Gin scripts]# cat file|tr [0-9] [a-j]
abcdefghij
4、删除文件file中出现的"Snail"字符
这里,凡是在file文件中出现的’S’,‘n’,‘a’,‘i’,'l’字符都会被删除!而不是仅仅删除出现的"Snail”字符串。
[root@Gin scripts]# cat file
what is Snail
[root@Gin scripts]# cat file|tr -d "Snail"
wht s
[root@Gin scripts]# cat file
what is Snail
5、删除文件file中出现的换行’\n’、制表’\t’字符
不可见字符都得用转义字符来表示的,这个都是统一的。
#cat file | tr -d "\n\t"
6、字符集补集
在这里,补集中包含了除数字、空格字符和换行符之外的所有字符,因为指定了-d,所以这些字符全部都会被删除
[root@Gin scripts]# echo "hello 123 world " | tr -d -c '0-9 \n'
123
7、用tr压缩字符
只有连续在一起的才会被删除,保留连续的一个即可。
[root@Gin scripts]# echo "GNU is not UNIX . Recursicve right?" | tr -s ' '
GNU is not UNIX . Recursicve right?
##2、sed-用于过滤文本和转换的流编辑器
介绍:
sed 全名为 stream editor,流编辑器,用程序的方式来编辑文本,功能相当的强大。sed是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后再输出编辑结构。sed 基本上就是在玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。正则表达式就是记录文本规则的代码
原理:
sed会一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,成为"模式空间",接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
语法:
sed [选项] 'command' filename
选项部分,常见选项包括-n,-e,-i,-f,-r选项。
command部分包括:[地址1,地址2] [函数] [参数(标记)]
常用选项
1、选项-n
sed默认会把模式空间处理完毕后的内容输出到标准输出,也就是输出到屏幕上,加上-n选项后被设定为安静模式,也就是不会输出默认打印信息,除非子命令中特别指定打印选项,则只会把匹配修改的行进行打印。
echo -e 'hello world\nnihao' | sed 's/hello/A/'
结果:
A world
nihao
echo -e 'hello world\nnihao' | sed -n 's/hello/A/'
结果:加-n选项后什么也没有显示。
echo -e 'hello world\nnihao' | sed -n 's/hello/A/p'
结果:A world/
说明:-n选项后,再加p标记,只会把匹配并修改的内容打印了出来。
2、选项-e
如果需要用sed对文本内容进行多种操作,则需要执行多条子命令来进行操作。
echo -e 'hello world' | sed -e 's/hello/A/' -e 's/world/B/'
结果:A B
echo -e 'hello world' | sed 's/hello/A/;s/world/B/'
结果:A B
说明:例子1和例子2的写法的作用完全等同,可以根据喜好来选择,如果需要的子命令操作比较多的时候,无论是选择-e选项方式,还是选择分号的方式,都会使命令显得臃肿不堪,此时使用-f选项来指定脚本文件来执行各种操作会比较清晰明了。
3、选项-i
sed默认会把输入行读取到模式空间,简单理解就是一个内存缓冲区,sed子命令处理的内容是模式空间中的内容,而非直接处理文件内容。因此在sed修改模式空间内容之后,并非直接写入修改输入文件,而是打印输出到标准输出。如果需要修改输入文件,那么就可以指定-i选项。
cat file.txt
hello world
[root@localhost]# sed 's/hello/A/' file.txt
A world
[root@localhost]# cat file.txt
hello world
[root@localhost]# sed -i 's/hello/A/' file.txt
[root@localhost]# cat file.txt
A world
[root@localhost]# sed –i.bak 's/hello/A/' file.txt
说明:最后一个例子会把修改内容保存到file.txt,同时会以file.txt.bak文件备份原来未修改文件内容,以确保原始文件内容安全性,防止错误操作而无法恢复原来内容。
4、选项-f
还记得 -e 选项可以来执行多个子命令操作,用分号分隔多个命令操作也是可以的,如果命令操作比较多的时候就会比较麻烦,这时候把多个子命令操作写入脚本文件,然后使用 -f 选项来指定该脚本。
echo "hello world" | sed -f sed.script
结果:A B
sed.script脚本内容:
s/hello/A/
s/world/B/
说明:在脚本文件中的子命令串就不需要输入单引号了。
选项-r
sed命令的匹配模式支持正则表达式的,默认只能支持基本正则表达式,如果需要支持扩展正则表达式,那么需要添加-r选项。
echo "hello world" | sed -r 's/(hello)|(world)/A/g'
A A
定址方法:

上图已经说明了两个定址方法,数字定址和正则定址。默认情况下sed会对每一行内容进行匹配、处理、输出,某些情况不需要对处理的文本全部编辑,只需要其中的一部分,比如1-10行,偶数行,或者是包含"hello"字符串的行,这种情况下就需要我们去定位特定的行来处理,而不是全部内容,这里把这个定位指定的行叫做"定址"。
**数字定址:**数字定址其实就是通过数字去指定具体要操作编辑的行,数字定址有几种方式,每种方式都有不同的应用场景,下边以举例的方式来描述每种数字定址的用法。
sed –n '4s/hello/A/' message
说明:将第4行中hello字符串替换为A,其它行如果有hello也不会被替换。
sed –n '2,4s/hello/A/' message
说明:将第2-4行中hello字符串替换为A,其它行如果有hello也不会被替换。
sed –n '2,+4s/hello/A/' message
说明:从第2行开始,再接着往下数4行,也就是2-6行,这些行会把hello字符替换为A。
sed –n '4~3s/hello/A/' message
说明:从第4行开始,每隔3行就把hello替换为A。比如从4行开始,7行,10行等依次+3行。这个比较常用,比如3替换为2的时候,也就是每隔2行的步调,可以实现奇数和偶数行的操作。
sed –n '$s/hello/A/' message
说明:$符号表示最后一行,和正则中的$符号类似,但是第1行不用^表示,直接1就行了。
sed -n '1!s/hello/A/' message
说明:!符号表示取反,该命令是将除了第1行,其它行hello替换为A,上述定址方式也可以使用!符号。
正则定址
正则定址使用目的和数字定址完全一样,使用方式上有所不同,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要额外处理。
sed -n '/nihao/d' message
说明:将匹配到nihao的行执行删除操作。
sed -n '/^$/d' message
说明:删除空行
sed -n '/^TS/,/^TE/d' message
说明:匹配以TS开头的行到TE开头的行之间的行,把匹配到的这些行删除。
数字定址和正则定址混用
其实数字定址和正则定址可以配合使用,参考下边的例子。
sed -n ‘1,/^TS/d’ message
说明:匹配从第1行到TS开头的行,把匹配的行删除。
基本子指令:


子命令s
子命令s为替换子命令,是平时sed使用的最多的子命令,没有之一。因为支持正则表达式,功能变得强大无比,下边来详细地说说子命令s的使用方法。
# cat message
hello 123 world
sed ‘s/hello/HELLO/’ message
说明:将message每行包含的第一个hello的字符串替换为HELLO,这是最基本的用法,默认仅仅替换第一个出现的hello。
sed -r ‘s/[a-z]+ [0-9]+ [a-z]+/A/’ message
结果:A
说明:使用了扩展正则表达式,需要加-r选项。
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/\1\2\3/’ message
结果:hello 123 world
说明:再看下一个例子就明白了。
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/\3\2\1/’ message
结果:world 123 hello
说明:\1表示正则第一个分组结果,\2表示正则匹配第二个分组结果,\3表示正则匹配第三个分组结果,加()将正则表达式分组。
sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/&/’ message
结果:hello 123 world
说明:&表示正则表达式匹配的整个结果集。
sed -r 's/\([a-z]+\)\( [0-9]+ \)\([a-z]+\)/111&222/' message
结果:111hello 123 world222
说明:在匹配结果前后分别加了111、222,记住上面的转义字符,将其解释为特殊字符。
sed -r 's/.*/111&222/' message
说明:在message文件中每行的首尾分别加上111、222。
sed 's/i/A/g' message
说明:把message文件中每行的所有i字符替换为A,默认不加g标记时只替换每行的第一个字符默认仅仅替换第一个出现的i。
sed 's/i/A/2' message
说明:把message文件中每行的第2个i字符替换为A。
sed -n 's/i/A/p' message
说明:加-p标记会把被替换的行打印出来,再加上-n选项会关闭模式空间打印模式,因此该命令的效果就是只显示被替换修改的行。
sed -n 's/i/A/w b.txt' message
说明:把message文件中内容的每行第一个字符i替换为A,然后把修改内容另存为b.txt文件。
sed -n 's/i/A/i' message
说明:把message文件中每一行的第一个i或I字符替换为A字符,也即是忽略大小写。
sed 's/(\[0-9\]{2})/\([0-9]{2}\)/\([0-9]{4}\)$/\3-\1-\2/'
说明:
([0-9]{2})/([0-9]{2})/([0-9]{4})表示通过正则匹配 12/03/1998 形式,划分子正则。
\3-\1-\2表示替换成 1998-12-03
grep、sed、awk三剑客