作者
吴连火,腾讯游戏专家开发工程师,负责欢乐游戏大规模分布式服务器架构。有十余年微服务架构经验,擅长分布式系统领域,有丰富的高性能高可用实践经验,目前正带领团队完成云原生技术栈的全面转型。
导语
欢乐游戏这边对 istio 服务网格的引进,自 2019 开始,从调研到规模化落地,至今也已近三年。本文对实践过程做了一些思考总结,期望能给对网格感兴趣的同学们以参考。
在正文开始之前,先明确一下本文所说的服务网格(service mesh)概念 —— 基于 sidecar 通信代理,网状拓扑的后端架构级解决方案。目前业界最流行的开源解决方案为 istio。
服务网格的架构思想,是解耦,以及加一层。通过将基础的治理能力从进程中解耦出去,以 sidecar 的形式提供,以达到更大规模的复用,一旦标准化,将会是行业级的复用!其实作为微服务领域炙手可热的解决方案,网格所做的解耦分拆进程这件事情本身就很 “微服务”,因为微服务其实也是做进程拆分,解耦并独立部署,以方便服务的复用。
现状与收益
技术栈现状
- 编程语言:go / c++ / python
- meta 体系:protobuf(用于描述配置、存储、协议)
- RPC 框架:gRPC
- 单元测试:gtest
- 容器化:docker + k8s
- 网格:istio,envoy 网关
- 配置:基于 pb 的 excel 转表工具,配置分发管理中心
- 监控:prometheus
- 其他:代码生成工具,蓝盾流水线,codecc 代码扫描,helm 部署等。
核心收益
- 技术价值观:团队的技术价值观变得比较开放,拥抱开源生态,贴近云原生技术栈。
- 团队成长:大技术栈演进,是一项颇具挑战性的任务,团队同学在打怪升级之后自然就有了能力的提升。
- RPC 框架:通过引入 gRPC 统一了跨语言的 RPC 框架,原自研 RPC 框架也继续在用,但底层会适配为 gRPC。
- 引入 golang:引入了 golang 做常规特性研发,提高了研发效率。
- 网格能力:无需开发,基于 istio 的 virtual service 做流量治理,按 label 聚合分版本调度流量,使用一致性 hash。
- 机器成本:这是唯一相对好量化的收益点,准确的数据还是要等后续完成 100% 上云后才好给出,初步估算的话,可能是原来的百分之六七十。
总体上,我们做的是一个大技术栈体系的演进,体现了较好的技术价值,提升了研发效能。所以对于我们而言,现在再回望,网格化是否值得实践?答案依旧是肯定的。
但假如抛开技术栈演进这个大背景,单独看网格本身的话,那么坦率地讲,我们对网格能力的使用是较为初步的:
- 转不转包:熔断、限流、重试(以幂等为前提),暂未实践。
- 包转给谁:名字服务,有实践,使用了 virtual service,使用了 maglev 一致性 hash。
- 调试功能:故障注入、流量镜像,暂未实践。
- 可观测性:关掉了 tracing,暂未实践。
考虑到实际开销情况,我们并没有拦截 inbound 流量,所以如果有依赖这点的功能特性,目前也无法实践。
网格的真正卖点
从笔者个人的观察来讲,istio 网格最具吸引力的,实际上就两点:
- 开放技术栈的想象空间,随着 istio、envoy、gRPC 整个生态越来越丰富,未来可能会有更多能力提供,开箱即用,业务团队不必投入开发。
- 多语言适配,不用为每种语言开发治理 sdk,例如 C++ 编写的 envoy 可以给所有用 gRPC 的 service 使用。
至于熔断、限流、均衡、重试、镜像、注入,以及 tracing 监控之类的能力,严格来讲不能算到网格头上,用 sdk 也是一样可以实现的。在团队语言统一的时候,只用维护一种语言版本的 sdk,此时采用治理 sdk 方案也是可行的,也就是所谓的微服务框架方案。采用 sdk 方式下的版本维护问题,以及后期进一步演进网格的问题,这些都不难解决,这里不再发散。
对于我们自己来讲,因为恰好有引进 golang 以及 gRPC,所以现在再看,选择 istio 作为网格方案也算合适。
网格的思考实践
一些前置条件
接入网格,要考虑天时地利人和。即,需要满足一些基本条件:
- 需要项目阶段允许,如果团队本身一直在做快版本内容迭代,业务需求都忙不过来,恐怕也很难有人力保障。
- 要有基础设施环境支持(我们使用了腾讯云的 tke mesh 服务),这样不至于所有东西都从零开始。
此外,对于这类大的技术优化,还有必要先统一思想:
- 自上而下,获得各级管理干系人的认可,这样才好做较大人力的投入。
- 自下而上,发动同学们深度介入探讨,使得整体的方向、方案得到大家的认可,这样大家才有干劲。
行动之前的三思
在早期的构思阶段,需要明确几个大的关键问题:
- 1)想要达到什么目标?节约机器成本 / 提升研发效能 / 培养团队 / 技术栈演进?如果要达到对应的目标,有没有其他更优路径?
- 2)有没有失控风险?性能是否不可接受,k8s、istio 稳定性是否足够,有没有极端的可用性大风险?
- 3)如何平稳地过渡?服务搬迁过程,研发模式是否都可以平稳过渡?
对于第一点,不同团队要看自己的实际情况,这里不做展开。
对于第二点,k8s 在业界的大规模应用非常多,所以还算是可靠的,而且它 level triggered 的设计,使其具备较好的健壮性。相对未知的是 istio,团队一开始对 istio 做了一些压测,也考虑了回退无 mesh 的情形,结论是可以尝试。istio 本质上就是一个复杂大型软件,所以其本身主要使人望而生畏的点,是其复杂的配置,版本之间的兼容性担忧,以及偏黑盒可控性不好这几点。现在想来,其实我们团队的步子迈得还是比较大的。幸运的是,后面的落地过程表明,istio 本身稳定性也还行,不至于三天两头出问题。
对于第三点,我们针对性地做了引入间接层的设计,使用私有协议与 gRPC 互转的网关确保了服务平滑迁移上云,在服务内部引入 grpc 适配层确保了研发人员的开发模式基本不变。
系统整体架构
系统整体架构如下图所示,可以清晰地看到上文所说的间接层:

图示:gRPC 适配与网格内外通信代理
云原生研发体验
对于评需求、定方案、写代码等差异不大的点,这里不做展开。下面主要罗列一些在云原生的技术栈体系下,与我们以前相比,有显著差异的一些研发体验。
- helm:通过 helm 管理所有服务的内外网 yaml,在服务自身 yaml 里完整描述其所有部署依赖。
- 测试环境 dev 副本:因为系统服务过多,虽然内网都是 debug version,资源消耗要远低于 release 版本,但考虑到复杂的服务间依赖,为每个人部署一套测试环境也不可取,所以目前还是选择的少数几套环境,大家复用。对于多人自测环境的冲突问题,我们借助网格的能力,做了基于 uin 的 dev 副本部署,这样当小 A 同学开发特定服务的时候,他自己的请求会落到自己的专属 deployment 上。


图示:基于不同号码部署不同的专属 deployment
- 测试环境每日全量自动构建部署:但是这也带来一个问题,pod 重建漂移后日志、coredump 等信息都不匹配,例如测试同学反馈说前一天遇到个什么问题,然后开发也不知道前一天在哪个 pod(已经被销毁)。我们通过设置 k8s 节点亲和策略 preferredDuringSchedulingIgnoredDuringExecution,结合日志路径固定化(取 deployment 名而非 pod 名),确保测试环境下 pod 重建后还在原 node,日志路径也保持一致,这样进入同服务的新 pod 便可以继续看到前一天的日志。
- 外网金丝雀版本:灰度期间使用,直接通过 yaml 的 deploymentCanary 配置项打开,借助 istio virtual service 来配置灰度的流量比例。排查外网问题有时候也会启用,对于染色的号码,流量也会导入金丝雀版本。具体实现就是网关进程会读一份号码列表配置,只要是在列表里的号码请求,就给 gRPC 的 header 打上相关的 label,再基于 vs 的路由能力导入到金丝雀版本。
- hpa 实践:对于 hpa 笔者早先的态度还是有些犹豫的,因为这本质上是会将服务部署发布时机变得不可控,不像是常规人工干预的发布,出了问题好介入。线上也确实出过一些问题,例如 hpa (会依赖 hpa 关联的 metric 链路畅通)夜间失效导致业务过载;还有就是在日志采集弄好之前,hpa 导致 pod 漂移,前一天夜里某 pod 的告警信息,第二天想看就比较费劲,还得跑到之前调度到的 node 上去看;另外也出现过进程 hpa 启动不起来的问题,配置有误无法加载初始化成功,正在跑着的进程只会 reload 失败,但是停掉重启就会启动失败。不过 hpa 对于提升资源利用率,还是很有价值的,所以我们现在的做法是做区分对待,对于普通的业务,min 副本数可以较小,对于重要的服务,min 副本数则配置稍大一些。
- 优雅启停:直接基于 k8s 的就绪、存活探针实现。
- 外网日志收集:这块之前一直还没有用到比较好用的平台服务,业务自己有打过 rsyslog 远程日志,后面可能会用 cfs 挂网盘,也算能凑合用。
- 配置体系:配置的定义用 protobuf,配置的解析基于代码生成,配置的分发基于 rainbow,配置的拉取基于 configAgent,配置的归档表达以 excel 形式放在了 svn,用工具完成 excel 到程序读取格式的转换。configAgent,是 webhook 给 pod 动态注入的容器。
- 监控体系:prometheus,云监控。
- DEBUG_START 环境变量:在容器化部署的早期,我们遇到过一些进程启动失败的情况,反复拉起失败,然后 pod 到处漂移,排查很不方便,所以我们增加了 DEBUG_START 环境变量,如果设置为 true 的时候,进程启动失败时不退出容器。
- 云上 perf因为一些安全的权限原因,容器内无法 perf,现在是临时申请 node 的 root 权限进行 perf,需要在 node 上也放一份二进制文件,不然 perf 无法解析 symbol 信息。对于 go 服务的话,则直接使用它自己的工具链来剖析。
- 问题 pod 现场保留:由于 deployment 是基于 label 识别的,所以对于外网那种想保留故障 pod 的现场时会很简单,直接改一下 label 就好了。
- coredump 查看:段错误信号捕获后会把二进制本身也拷贝到 coredump 的文件夹,随便 attach 到 coredump node 上当前存活的任意 pod 就可以查看。
- 代码生成:这个其实和是否上云关系不大,只是我们基于 protobuf 做了不少工作(例如用 .proto 定义配置文件,提供类似 xresloader 的功能),深感颇有益处,这里也列一下。后续整理相关代码并完善文档后,也会考虑开源。
性能情况
讨论性能之前,这里先说一下我们的实践方式:关掉 tracing,关掉 inbound 拦截(远端流量过来的时候,并不会走 sidecar)。

图示:pod1 上的业务容器调用 pod2 上的服务,仅拦截 outbound
在上述背景下,结合我们的线上真实案例情况,分享一下读者可能会比较感兴趣的性能数据:
- 内存开销:系统中共有几百个服务,使用一致性 hash,envoy sidecar 的内存占用约两三百兆。
- CPU 开销:典型 cpu 开销和扇出情况相关,例如一个服务较多访问其他 gRPC 服务,那么 envoy 的 cpu 开销甚至会超过主业务进程,但当业务进程扇出较少时 envoy 的开销就比较低。
对于内存开销的问题,社区有相对明确的解决方案,采用 sidecar crd 来限定载入业务所需访问目标服务的 xds 信息,即可大幅减少内存占用。业务进程需要访问哪些目标服务,可以通过手动维护、静态注册或代码生成之类的办法明确,我们后面也会做相关的优化。
接下来我们用相对大的篇幅讨论一下 cpu 开销的问题,先看一个大扇出业务的性能 top 示例:

图示:大扇出业务进程与 envoy 性能对比示意
看到上图中的数据,读者可能会有这样的疑问:为什么仅支持 gRPC 的转发,envoy 就需要如此高的 cpu 开销(图中 71.3%,远超业务进程的 43.7%)呢?关于这点,我们在分析火焰图之后,也没有发现显著异常的地方,它所做的主要工作,也就是在做协议的编解码与路由转发而已,无明显异常热点。

图示:envoy 火焰图示意
现在网上大量介绍 envoy 的资料,基本都会说它性能比较好,难道...真相其实是 envoy 其实做的不够高效么?针对这个问题,笔者这里也无法给出一个明确的答案,envoy 内部确实大量使用了各种 C++ 的抽象,调用层级比较多,但这未必是问题的关键所在,因为:
- 可能是 envoy 使用的 libnghttp2 协议解析库的性能拖累所致...
- 可能是 envoy 使用 libnghttp2 的“姿势”不大对,没有充分发挥其性能...
- 抑或是 http2 解析、编解码,以及收发包本来就需要消耗这么多的 cpu?
关于最后这一点,我们观测了业务主进程中的 grpc thread,它也需要做 http2 的解析和编解码,但它的 cpu 开销显然低得多。
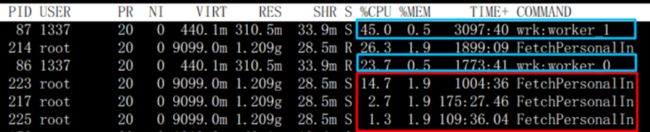
图示:业务进程中的 grpc 线程 %cpu * 2 后依然比 envoy 小很多
将业务进程中的 grpc 线程(红框部分)%cpu 乘 2 后再与 envoy(蓝框部分)做对比,是因为 envoy 对 outbound 拦截的 workload 相对业务进程而言确实近似翻倍,例如就编解码而言,对于一次 req、rsp,业务进程就是 req 的编码和 rsp 的解码,但是对于 envoy,则是 req 的解码 + 编码,rsp 的解码 + 编码。
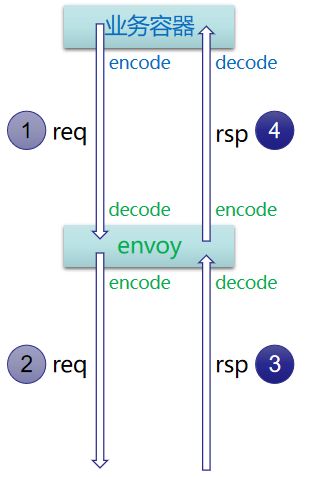
图示:envoy vs 业务进程的编解码开销
从上面的示例来看,grpc 自己做 http2 parse + 编解码 + 收发包的性能,要远好于使用 libnghttp2 的 envoy,但 envoy 显然不可能直接采用 grpc 里面的相关代码。要想更好地回答关于 envoy 做 grpc 通信代理性能的疑问,恐怕还需要做更加细致的分析论证以及测试(欢迎感兴趣或有经验的读者来交流)。
总之对于 gRPC 大扇出业务 sidecar cpu 损耗过大的这个问题,我们暂时也没想到好的优化方案。当然上面那个案例其实相对极端,因为是大扇出 + 主业务进程为 C++ 的情况,如果是小扇出则 sidecar 不会耗多少 cpu,如果是 golang 业务进程则 sidecar 占 pod 整体 cpu 开销的比例不会这么夸张(当然这也反过来说明 golang 性能和 C++ 差距还是蛮大的...)。
对于我们自身来讲,网格的综合性能并没有严重到无法接受的地步:
- 首先很多业务并不是大扇出型的,这类业务下的 sidecar 的开销并不大。
- 其次对于 golang 类的业务进程,sidecar 相较带来的涨幅比例也会小一些。
- 最后相对于传统 IDC 粗放的部署方式,在我们做了整体上云之后,总体上还是更省机器的。
私有协议或私有网格
如前文所述,envoy 的性能问题,在大扇出业务场景下确实难以忽视。
如果真的无法接受相应的性能开销,那么可能私有协议或私有网格会是可选的替代方案。
- 采用私有协议,基于 envoy 自己写 filter,解析私有协议头,然后结合 envoy xds 相关的能力来提供服务(可以参考腾讯开源的解决方案 https://github.com/aeraki-mes... ),不难想象在该方案下,完全无需解析 http2,性能必然会有非常显著的提升。但如果我们真的走到私有协议的老路上去,其实就等于又放弃了 gRPC 生态。(参考前文网格核心卖点 1)
- 采用私有网格,自己实现 xDS 相对应的系列能力,可以先从最核心能力做起。但采用该方案的话,就又会回到多语言支持的问题上来,需要为 C++ 和 golang 都实现对应的能力(参考前文网格核心卖点 2)。假如真的要自己实现私有网格,在设计上,应当考虑语言相关的 sdk 代码是相对简易的,路由策略等控制面功能依旧下沉在自研 sidecar/agent 里,数据面逻辑出于性能考虑则由业务进程自己处理。
未来趋势展望
欢乐自己的实践
对于欢乐自己的团队而言,后面会持续做更深度的实践。例如 envoy filter 开发、k8s crd,以及 istio 的更多能力的实践(上文也提到了,我们目前仅使用了一小部分网格能力,期望以后能使用熔断、限流等能力来提升业务的可用性)。
ebpf 的融合
ebpf 可能未来会与容器网络、网格有更好的融合,可以提升网络相关性能表现,或许还会带来其他一些可能。
proxyless mesh
proxyless mesh 可以看做基于前文讨论性能问题的一个延伸,和前面提及的私有网格有些类似。这类方案也会有对应的生存空间,因为始终有些团队无法接受数据面 sidecar 所带来的性能开销:
- 时延,这点也有不少团队提及,但如果是普通互联网业务,笔者个人认为多几十毫秒级别的延迟影响都不大。
- cpu 和内存开销,前文已有较多讨论。
proxyless mesh 实际上就是 sdk + 网状拓扑的方案,gRPC 现在也在持续完善对 xDS 的支持,所以也有可能借助 gRPC 的能力来实现。如果自行研发支持 xDS 的 sdk,那对于团队的投入还是有要求的,除非团队本身就是大厂的中间件类团队(网易轻舟、百度服务网格、阿里 dubbo,这一两年都有做 proxyless mesh 的实践)。

图示:proxyless gRPC mesh
私有方案对标 xDS
对于编程语言统一的团队,例如全 golang,那么只用维护一套服务治理相关的 sdk(控制面逻辑也可以用 agent 承载),所以可能会倾向于做一套自己私有的解决方案。据笔者了解,B 站之前就是采用的这种方案,参考 eureka 实现名字服务自己做流量调度。
现在随着网格的流行(起码对应的理念已经广为人知了),私有方案也可以参考对标 xDS 的各种 feature。因为私有方案通常是自研的,所以理论上还能提供相对高效可控的实现,但是需要团队持续投入维护。
Dapr 运行时
概念很好,故事很宏大,不过目前看来还为时过早。
参考资料
让 istio 支持私有协议:【https://github.com/aeraki-mes...】
grpc 对 xDS 的支持:【https://grpc.github.io/grpc/c...】
proxyless grpc:【https://istio.io/latest/blog/...】
nghttp2 解析库:【https://nghttp2.org/】
infoQ 基础软件创新大会微服务专场:【https://www.infoq.cn/video/7R...】
xresloader 配置转换工具:【https://github.com/xresloader...】
Dapr:【https://dapr.io/】
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
④公众号后台回复【光速入门】,可获得腾讯云专家5万字精华教程,光速入门Prometheus和Grafana。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!