Radix树
Radix树,即基数树,也称压缩字典树,是一种提供key-value存储查找的数据结构。radix tree常用于快速查找的场景中,例如:redis中存储slot对应的key信息、内核中使用radix tree管理数据结构、大多数http的router通过radix管理路由。Radix树在Trie Tree(字典树)的原理上优化过来的。因此在介绍Radix树的特点之首先简单介绍一下Trie Tree。
Trie树
Trie Tree,即字典树。Trie Tree的原理是将每个key拆分成一个个字节,然后对应到每个分支上,分支所在的节点对应为从根节点到当前节点的拼接出的key的值。下图由四个字符串:haha、hehe、god、goto,形成的一个Trie树的示例: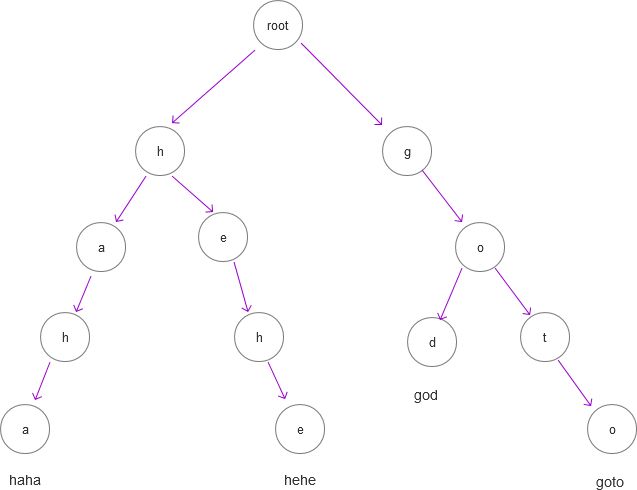
利用上图中构造的Trie Tree,我们可以很方便的检索一个单词是否出现在原来的字符串集合中。例如,我们检索单词:hehe,那么我们从根节点开始,然后逐个单词进行对比,途径结点:h-e-h-e,就定位到要检索的字符串了。从中可以看出,Trie Tree查找效率是非常高的,达到了O(K),其中K是字符串的长度。
Radix树特点
虽然Trie Tree具有比较高的查询效率,但是从上图可以看到,有许多结点只有一个子结点。这种情况是不必要的,不但影响了查询效率(增加了树的高度),主要是浪费了存储空间。完全可以将这些结点合并为一个结点,这就是Radix树的由来。Radix树将只有一个子节点的中间节点将被压缩,使之具有更加合理的内存使用和查询的效率。下图是采用Radix树后的示例: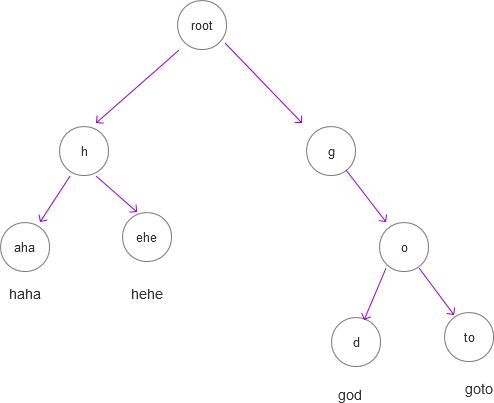
与hash表的对比
- 查询效率
Radix树的插入、查询、删除操作的时间复杂度都为O(k)。hash表的安查询效率:hash函数计算效率+O(1),当然与若hash函数若选取不合理,则会造成冲突,会造成hash表的查询效率降低。 总总体上来说两者查询性能基本相等(hash函数的效率基本上等于O(k))。 - 空间效率
从空间使用来说,hash占优,因为Radix树的每个节点的节点负载较高,Radix树的结点需要有指向子结点的指针。 - 其他方面
hash表的缺点有:数据量增长的情况下可能需要rehash。Radix树不会存在rehash的情况,但是若数据数据密集,则会造成Radix树退化为Trie树,会降低空间使用效率以及查询效率。 - 取舍建议
如果数据稀疏,Radix树可以更好的节省空间,这种情况下使用Radix树会更佳。如果数据量小但数据密集,则建议选择hash表。
Radix树的Go语言版本
本文使用Go语言来实现Radix树,目前代码已经上传到github中,下载地址
在该代码中使用二叉树来实现Radix树,相对与四叉树的版本,本版本在存储空间的使用率方面会更好一点,但会牺牲一定的查询效率。
若追求查询效率,请使用多叉树来实现。
使用二叉树来处理字符串时,将字符串看作bit数组,然后逐个bit来对比两这个bit数组,将bit数组前面相同的部分保存到父结点,
将两个bit数组的后面的部分分别保存到left子结点以及right子结点中。例如:
god: 0110-0111 0110-1111 0110-0100
goto: 0110-0111 0110-1111 0111-0100 0110-1111从上例可以看到,二者在地20位处不相等,因此:
- 0110-0111 0110-1111 011:被划分到父节点。
- 0-0100:被划分到left子结点。
- 1-0100 0110-1111:被划分到right子结点。
定义
首先给出Radix树的定义:
type RaxNode struct {
bit_len int
bit_val []byte
left *RaxNode
right *RaxNode
val interface{}
}
type Radix struct {
root [256]*RaxNode
}
func NewRaxNode() *RaxNode {
nd := &RaxNode{}
nd.bit_len = 0
nd.bit_val = nil
nd.left = nil
nd.right = nil
nd.val = nil
return nd
}将数据添加到Radix树
//添加元素
func (this *Radix)Set(key string, val interface{}) {
data := []byte(key)
root := this.root[data[0]]
if root == nil {
//没有根节点,则创建一个根节点
root = NewRaxNode()
root.val = val
root.bit_val = make([]byte, len(data))
copy(root.bit_val, data)
root.bit_len = len(data) * 8
this.root[data[0]] = root
return
} else if root.val == nil && root.left == nil && root.right == nil {
//只有一个根节点,并且是一个空的根节点,则直接赋值
root.val = val
root.bit_val = make([]byte, len(data))
copy(root.bit_val, data)
root.bit_len = len(data) * 8
this.root[data[0]] = root
return
}
cur := root
blen := len(data) * 8
for bpos := 0; bpos < blen && cur != nil; {
bpos, cur = cur.pathSplit(data, bpos, val)
}
}
func (this *RaxNode)pathSplit(key []byte, key_pos int, val interface{}) (int, *RaxNode) {
//与path对应的key数据(去掉已经处理的公共字节)
data := key[key_pos/8:]
//key以bit为单位长度(包含开始字节的字节内bit位的偏移量)
bit_end_key := len(data) * 8
//path以bit为单位长度(包含开始字节的字节内bit位的偏移量)
bit_end_path := key_pos % 8 + int(this.bit_len)
//当前的bit偏移量,需要越过开始字节的字节内bit位的偏移量
bpos := key_pos % 8
for ; bpos < bit_end_key && bpos < bit_end_path; {
ci := bpos / 8
byte_path := this.bit_val[ci]
byte_data := data[ci]
//起始字节的内部偏移量
beg := 0
if ci == 0 {
beg = key_pos % 8
}
//终止字节的内部偏移量
end := 8
if ci == bit_end_path / 8 {
end = bit_end_path % 8
if end == 0 {
end = 8
}
}
if beg != 0 || end != 8 {
//不完整字节的比较,若不等则跳出循环
//若相等,则增长bpos,并继续比较下一个字节
num := GetPrefixBitLength2(byte_data, byte_path, beg, end)
bpos += num
if num < end - beg {
break
}
} else if byte_data != byte_path {
//完整字节比较,num为相同的bit的个数,bpos增加num后跳出循环
num := GetPrefixBitLength2(byte_data, byte_path, 0, 8)
bpos += num
break
} else {
//完整字节比较,相等,则继续比较下一个字节
bpos += 8
}
}
//当前字节的位置
char_index := bpos / 8
//当前字节的bit偏移量
bit_offset := bpos % 8
//剩余的path长度
bit_last_path := bit_end_path - bpos
//剩余的key长度
bit_last_data := bit_end_key - bpos
//key的数据有剩余
//若path有子结点,则继续处理子结点
//若path没有子结点,则创建一个key子结点
var nd_data *RaxNode = nil
var bval_data byte
if bit_last_data > 0 {
//若path有子结点,则退出本函数,并在子结点中进行处理
byte_data := data[char_index]
bval_data = GET_BIT(byte_data, bit_offset)
if bit_last_path == 0 {
if bval_data == 0 && this.left != nil {
return key_pos + int(this.bit_len), this.left
} else if bval_data == 1 && this.right != nil {
return key_pos + int(this.bit_len), this.right
}
}
//为剩余的key创建子结点
nd_data = NewRaxNode()
nd_data.left = nil
nd_data.right = nil
nd_data.val = val
nd_data.bit_len = bit_last_data
nd_data.bit_val = make([]byte, len(data[char_index:]))
copy(nd_data.bit_val, data[char_index:])
//若bit_offset!=0,说明不是完整字节,
//将字节分裂,并将字节中的非公共部分分离出来,保存到子结点中
if bit_offset != 0 {
byte_tmp := CLEAR_BITS_LOW(byte_data, bit_offset)
nd_data.bit_val[0] = byte_tmp
}
}
//path的数据有剩余
//创建子节点:nd_path结点
//并将数据分开,公共部分保存this结点,其他保存到nd_path结点
var nd_path *RaxNode = nil
var bval_path byte
if bit_last_path > 0 {
byte_path := this.bit_val[char_index]
bval_path = GET_BIT(byte_path, bit_offset)
//为剩余的path创建子结点
nd_path = NewRaxNode()
nd_path.left = this.left
nd_path.right = this.right
nd_path.val = this.val
nd_path.bit_len = bit_last_path
nd_path.bit_val = make([]byte, len(this.bit_val[char_index:]))
copy(nd_path.bit_val, this.bit_val[char_index:])
//将byte_path字节中的非公共部分分离出来,保存到子结点中
if bit_offset != 0 {
byte_tmp := CLEAR_BITS_LOW(byte_path, bit_offset)
nd_path.bit_val[0] = byte_tmp
}
//修改当前结点,作为nd_path结点、nd_data结点的父结点
//多申请一个子节,用于存储可能出现的不完整字节
bit_val_old := this.bit_val
this.left = nil
this.right = nil
this.val = nil
this.bit_len = this.bit_len - bit_last_path //=bpos - (key_pos % 8)
this.bit_val = make([]byte, len(bit_val_old[0:char_index])+1)
copy(this.bit_val, bit_val_old[0:char_index])
this.bit_val = this.bit_val[0:len(this.bit_val)-1]
//将byte_path字节中的公共部分分离出来,保存到父结点
if bit_offset != 0 {
byte_tmp := CLEAR_BITS_HIGH(byte_path, 8-bit_offset)
this.bit_val = append(this.bit_val, byte_tmp)
}
}
//若path包含key,则将val赋值给this结点
if bit_last_data == 0 {
this.val = val
}
if nd_data != nil {
if bval_data == 0 {
this.left = nd_data
} else {
this.right = nd_data
}
}
if nd_path != nil {
if bval_path == 0 {
this.left = nd_path
} else {
this.right = nd_path
}
}
return len(key) * 8, nil
}Radix树的查询
func (this *Radix)Get(key string) interface{}{
data := []byte(key)
blen := len(data) * 8
cur := this.root[data[0]]
var iseq bool
for bpos := 0; bpos < blen && cur != nil; {
iseq, bpos = cur.pathCompare(data, bpos)
if iseq == false {
return nil
}
if bpos >= blen {
return cur.val
}
byte_data := data[bpos/8]
bit_pos := GET_BIT(byte_data, bpos%8)
if bit_pos == 0 {
cur = cur.left
} else {
cur = cur.right
}
}
return nil
}
func (this *RaxNode)pathCompare(data []byte, bbeg int) (bool, int) {
bend := bbeg + int(this.bit_len)
if bend > len(data) * 8 {
return false, len(data) * 8
}
//起始和终止字节的位置
cbeg := bbeg / 8; cend := bend / 8
//起始和终止字节的偏移量
obeg := bbeg % 8; oend := bend % 8
for bb := bbeg; bb < bend; {
//获取两个数组的当前字节位置
dci := bb / 8
nci := dci - cbeg
//获取数据的当前字节以及循环步长
step := 8
byte_data := data[dci]
if dci == cbeg && obeg > 0 {
//清零不完整字节的低位
byte_data = CLEAR_BITS_LOW(byte_data, obeg)
step -= obeg
}
if dci == cend && oend > 0 {
//清零不完整字节的高位
byte_data = CLEAR_BITS_HIGH(byte_data, 8-oend)
step -= 8-oend
}
//获取结点的当前字节,并与数据的当前字节比较
byte_node := this.bit_val[nci]
if byte_data != byte_node {
return false, len(data)*8
}
bb += step
}
return true, bend
}Radix树的删除
func (this *Radix)Delete(key string) {
data := []byte(key)
blen := len(data) * 8
cur := this.root[data[0]]
var iseq bool
var parent *RaxNode = nil
for bpos := 0; bpos < blen && cur != nil; {
iseq, bpos = cur.pathCompare(data, bpos)
if iseq == false {
return
}
if bpos >= blen {
//将当前结点修改为空结点
//若parent是根节点,不能删除
cur.val = nil
if parent == nil {
return
}
//当前结点是叶子结点,先将当前结点删除,并将当前结点指向父结点
if cur.left == nil && cur.right == nil {
if parent.left == cur {
parent.left = nil
} else if parent.right == cur {
parent.right = nil
}
bpos -= int(cur.bit_len)
cur = parent
}
//尝试将当前结点与当前结点的子节点进行合并
cur.pathMerge(bpos)
return
}
byte_data := data[bpos/8]
bit_pos := GET_BIT(byte_data, bpos%8)
if bit_pos == 0 {
parent = cur
cur = cur.left
} else {
parent = cur
cur = cur.right
}
}
}
func (this *RaxNode)pathMerge(bpos int) bool {
//若当前结点存在值,则不能合并
if this.val != nil {
return false
}
//若当前结点有2个子结点,则不能合并
if this.left != nil && this.right != nil {
return false
}
//若当前结点没有子结点,则不能合并
if this.left != nil && this.right != nil {
return false
}
//获取当前结点的子结点
child := this.left
if this.right != nil {
child = this.right
}
//判断当前结点最后一个字节是否是完整的字节
//若不是完整字节,需要与子结点的第一个字节进行合并
if bpos % 8 != 0 {
char_len := len(this.bit_val)
char_last := this.bit_val[char_len-1]
char_0000 := child.bit_val[0]
child.bit_val = child.bit_val[1:]
this.bit_val[char_len-1] = char_last | char_0000
}
//合并当前结点以及子结点
this.val = child.val
this.bit_val = append(this.bit_val, child.bit_val...)
this.bit_len += child.bit_len
this.left = child.left
this.right = child.right
return true
}