join和子查询效率_如何进行hive查询优化?

hive查询优化的主要目的是提升效率。用过hive的朋友,我想或多或少都有类似的经历:一天下来,没跑几次hive,就到下班时间了 。下面总结了查询中经常使用的优化点:
。下面总结了查询中经常使用的优化点:
1. 少用count(distinct )
建议用group by 代替 distinct 。原因为count(distinct)逻辑只会有一个reducer来处理,即使设定了reduce task个数,set mapred.reduce.tasks=100也一样,所以很容易导致数据倾斜。坊间传闻,在面对大数据量时很多大厂都“明令禁止使用distinct”。
如sql语句:select count(distinct uid) from users
建议改成: select count(*) from (select uid from testmac group by uid) t
2. 谓词下推
Predicate Pushdown,PPD,白话的意思就是就是将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。例如以下HiveSQL语句:
select a.uid,a.event_type,b.topic_id,b.title from calendar_record_log a left outer join ( select uid,topic_id,title from forum_topic where pt_date = 20190224 and length(content) >= 100 ) b on a.uid = b.uid where a.pt_date = 20190224 and status = 0;
对forum_topic做过滤的where语句写在子查询内部,而不是外部。
3. 用sort by代替order by
order by : 对查询结果进行全局排序消耗时间长,需要set hive.mapred.mode=nostrict
sort by : 局部排序,并非全局有序,提高效率。
HiveSQL中的order by与其他SQL语言中的功能一样,就是将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,在数据量大时可能会长时间计算不完。
如果使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用。如果不加distribute by的话,map端数据就会随机分配到reducer。
4. join优化
A. 小表join大表
在小表和大表进行join时,将小表放在前边,效率会高。hive会将小表进行缓存。Hive在解析带join的SQL语句时,会默认将最后一个表作为probe table,将前面的表作为build table并试图将它们读进内存。如果表顺序写反,probe table在前面,引发OOM(Out Of Memery)的风险就很高。left join和right join一样, hive默认都是从左往右开始读。
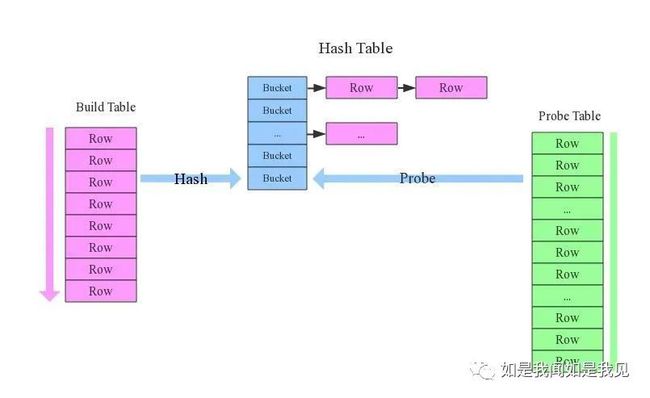
B. 多表join时key保持一致
当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job,执行效率相对快。
C.启用mapjoin优化
map join特别适合大小表join的情况。Hive会将build table和probe table在map端直接完成join过程,消灭了reduce,效率很高。
在Hive 0.8版本之后,就不需要写map join hint了。map join的配置项是set hive.auto.convert.join=true
D. 去除空值或无意义值
出现空值或无意义值时,如null,空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
因此,若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid,a.event_type,b.nickname,b.age from ( select (case when uid is null then cast(rand()*-10240 as int) else uid end) as uid, event_type from calendar_record_log where pt_date >= 20190201 ) a left outer join ( select uid,nickname,age from user_info where status = 4 ) b on a.uid = b.uid;
5. MapReduce优化
A. map阶段优化:增加或者减少map数量
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB 通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
何时增加或者减少map数量呢?
减少map数量的情况:map数量过多,而且很多都是小文件(远小于128兆),这时会出现的问题是map任务启动和初始化的时间远远大于逻辑处理的时间,造成很大的资源浪费.
增加map数量的情况:当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
减少map数量:适当调高mapred.min.split.size
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
增加map数量:
除了降低mapred.min.split.size之外,也可以调高mapred.map.tasks,
如 set mapred.reduce.tasks=10;
B. reduct 阶段优化:
Reduce的个数对整个作业的运行性能有很大影响。如果Reduce设置的过大,那么将会产生很多小文件,对NameNode会产生一定的影响,而且整个作业的运行时间未必会减少;如果Reduce设置的过小,那么单个Reduce处理的数据将会加大,很可能会引起OOM异常。
2. 调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
如:
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
select pt, count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;
3. 调整reduce个数方法二:
set mapred.reduce.tasks=15;
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;
当然,可以优化的点实际远不止这些,到时就得具体情况具体分析了~