- 深入解析 Spark:关键问题与答案汇总
※尘
sqlhivespark
在大数据处理领域,Spark凭借其高效的计算能力和丰富的功能,成为了众多开发者和企业的首选框架。然而,在使用Spark的过程中,我们会遇到各种各样的问题,从性能优化到算子使用等。本文将围绕Spark的一些核心问题进行详细解答,帮助大家更好地理解和运用Spark。Spark性能优化策略Spark性能优化是提升作业执行效率的关键,主要可以从以下几个方面入手:首先,资源配置优化至关重要。合理设置Exec
- spark on yarn
不辉放弃
pyspark大数据开发
SparkonYARN是指将Spark应用程序运行在HadoopYARN集群上,借助YARN的资源管理和调度能力来管理Spark的计算资源。这种模式能充分利用现有Hadoop集群资源,简化集群管理,是企业中常用的Spark部署方式。核心角色•Spark应用:包含Driver进程和Executor进程。Driver负责任务调度、逻辑处理;Executor负责执行具体任务并存储数据。•YARN组件:◦
- Spark RDD 之 Partition
博弈史密斯
SparkRDD怎么理解RDD的粗粒度模式?对比细粒度模式SparkRDD的task数量是由什么决定的?一份待处理的原始数据会被按照相应的逻辑(例如jdbc和hdfs的split逻辑)切分成n份,每份数据对应到RDD中的一个Partition,Partition的数量决定了task的数量,影响着程序的并行度支持保存点(checkpoint)虽然RDD可以通过lineage实现faultrecove
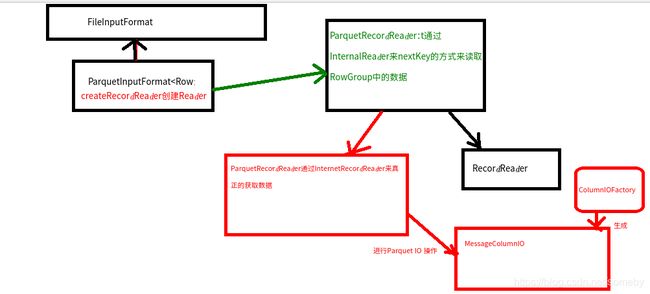
- Python读取.parquet文件
Henrietta's NOTES
pythonpandas
提示:在MacOS和Jupyternotebook环境下的用法Device:MacOSPython:3.10.9Pandas:1.5.3Jupyternotebook问题描述直接用pandas中pd.read_parquet()即可,但是这个方法在和read_csv一样用之前需要先安装fastparquet活着pyarrow,方法如下:打开MacOS的终端,输入:pipinstallfastpar
- 计算机专业大数据毕业设计-基于 Spark 的音乐数据分析项目(源码+LW+部署文档+全bao+远程调试+代码讲解等)
程序猿八哥
数据可视化计算机毕设spark大数据课程设计spark
博主介绍:✌️码农一枚,专注于大学生项目实战开发、讲解和毕业文撰写修改等。全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌️技术范围::小程序、SpringBoot、SSM、JSP、Vue、PHP、Java、python、爬虫、数据可视化、大数据、物联网、机器学习等设计与开发。主要内容:免费功能设计,开题报告、任务书、全b
- 绝佳组合 SpringBoot + Lua + Redis = 王炸!
Java精选面试题(微信小程序):5000+道面试题和选择题,真实面经,简历模版,包含Java基础、并发、JVM、线程、MQ系列、Redis、Spring系列、Elasticsearch、Docker、K8s、Flink、Spark、架构设计、大厂真题等,在线随时刷题!前言曾经有一位魔术师,他擅长将SpringBoot和Redis这两个强大的工具结合成一种令人惊叹的组合。他的魔法武器是Redis的
- AI日报-20250620:华为云重磅发布盘古大模型5.5!宇树科技C轮融资引爆资本圈!Genspark AI Pod震撼发布!
未来世界2099
AI日报人工智能华为云科技业界资讯
1、昆仑万维开源Skywork-SWE-32B:32B模型刷新代码修复SOTA,性能直逼闭源巨头2、腾讯AILab开源音乐生成大模型SongGeneration,人人皆可创作音乐!3、重磅!ManusAIWindows版免码开放,职场效率革命来袭!4、B站618商单效率飙升5倍!通义千问3助力AI选人功能大爆发5、HailuoVideoAgent震撼发布:零门槛生成专业级视频,创意秒变现实!6、中
- SPARKLE:深度剖析强化学习如何提升语言模型推理能力
摘要:强化学习(ReinforcementLearning,RL)已经成为赋予语言模型高级推理能力的主导范式。尽管基于RL的训练方法(例如GRPO)已经展示了显著的经验性收益,但对其优势的细致理解仍然不足。为了填补这一空白,我们引入了一个细粒度的分析框架,以剖析RL对推理的影响。我们的框架特别研究了被认为可以从RL训练中受益的关键要素:(1)计划遵循和执行,(2)问题分解,以及(3)改进的推理和知
- 24.park和unpark方法
卷土重来…
java并发编程java
1.park方法可以暂停线程,线程状态为wait。2.unpark方法可以恢复线程,线程状态为runnable。3.LockSupport的静态方法。4.park和unpark方法调用不分先后,unpark先调用,park后执行也可以恢复线程。publicclassParkDemo{publicstaticvoidmain(String[]args){Threadt1=newThread(()->
- 安全运维的 “五层防护”:构建全方位安全体系
KKKlucifer
安全运维
在数字化运维场景中,异构系统复杂、攻击手段隐蔽等挑战日益突出。保旺达基于“全域纳管-身份认证-行为监测-自动响应-审计溯源”的五层防护架构,融合AI、零信任等技术,构建全链路安全运维体系,以下从技术逻辑与实践落地展开解析:第一层:全域资产纳管——筑牢安全根基挑战云网基础设施包含分布式计算(Hadoop/Spark)、数据流处理(Storm/Flink)等异构组件,通信协议繁杂,传统方案难以全面纳管
- 在sf=0.1时测试fireducks、duckdb、polars的tpch
l1t
数据库编程语言软件工程python压力测试
首先,从https://github.1git.de/fireducks-dev/polars-tpch下载源代码包,将其解压缩到/par/fire目录。然后进入此目录,运行SCALE_FACTOR=0.1./run-fireducks.sh,脚本会首先安装所需的包,编译tpch的数据生成器,然后按照sf=0.1生成tbl文件,再转化为parquet格式,最后执行。如下所示:root@DESKTO
- Hive 事务表(ACID)问题梳理
文章目录问题描述分析原因什么是事务表概念事务表和普通内部表的区别相关配置事务表的适用场景注意事项设计原理与实现文件管理格式参考博客问题描述工作中需要使用pyspark读取Hive中的数据,但是发现可以获取metastore,外部表的数据可以读取,内部表数据有些表报错信息是:AnalysisException:org.apache.hadoop.hive.ql.metadata.HiveExcept
- 云原生--微服务、CICD、SaaS、PaaS、IaaS
青秋.
云原生docker云原生微服务kubernetesserverlessservice_meshci/cd
往期推荐浅学React和JSX-CSDN博客一文搞懂大数据流式计算引擎Flink【万字详解,史上最全】-CSDN博客一文入门大数据准流式计算引擎Spark【万字详解,全网最新】_大数据spark-CSDN博客目录1.云原生概念和特点2.常见云模式3.云对外提供服务的架构模式3.1IaaS(Infrastructure-as-a-Service)3.2PaaS(Platform-as-a-Servi
- Spark运行架构
EmoGP
Sparkspark架构大数据
Spark框架的核心是一个计算引擎,整体来说,它采用了标准master-slave的结构 如下图所示,它展示了一个Spark执行时的基本结构,图形中的Driver表示master,负责管理整个集群中的作业任务调度,图形中的Executor则是slave,负责实际执行任务。由上图可以看出,对于Spark框架有两个核心组件:DriverSpark驱动器节点,用于执行Spark任务中的main方法,负
- Spark 各种配置项
zhixingheyi_tian
大数据sparkSparkConfsparkjvmjava
/bin/spark-shell--masteryarn--deploy-modeclient/bin/spark-shell--masteryarn--deploy-modeclusterTherearetwodeploymodesthatcanbeusedtolaunchSparkapplicationsonYARN.Inclustermode,theSparkdriverrunsinside
- Spark RDD 及性能调优
Aurora_NeAr
sparkwpfc#
RDDProgrammingRDD核心架构与特性分区(Partitions):数据被切分为多个分区;每个分区在集群节点上独立处理;分区是并行计算的基本单位。计算函数(ComputeFunction):每个分区应用相同的转换函数;惰性执行机制。依赖关系(Dependencies)窄依赖:1个父分区→1个子分区(map、filter)。宽依赖:1个父分区→多个子分区(groupByKey、join)。
- Apache Iceberg数据湖基础
Aurora_NeAr
apache
IntroducingApacheIceberg数据湖的演进与挑战传统数据湖(Hive表格式)的缺陷:分区锁定:查询必须显式指定分区字段(如WHEREdt='2025-07-01')。无原子性:并发写入导致数据覆盖或部分可见。低效元数据:LIST操作扫描全部分区目录(云存储成本高)。Iceberg的革新目标:解耦计算引擎与存储格式(支持Spark/Flink/Trino等);提供ACID事务、模式
- 大数据技术之Flink
第1章Flink概述1.1Flink是什么1.2Flink特点1.3FlinkvsSparkStreaming表Flink和Streaming对比FlinkStreaming计算模型流计算微批处理时间语义事件时间、处理时间处理时间窗口多、灵活少、不灵活(窗口必须是批次的整数倍)状态有没有流式SQL有没有1.4Flink的应用场景1.5Flink分层API第2章Flink快速上手2.1创建项目在准备
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- 大数据分析技术的学习路径,不是绝对的,仅供参考
水云桐程序员
学习大数据数据分析学习方法
阶段一:基础筑基(1-3个月)1.编程语言:Python:掌握基础语法、数据结构、流程控制、函数、面向对象编程、常用库(NumPy,Pandas)。SQL:精通SELECT语句(过滤、排序、分组、聚合、连接)、DDL/DML基础。理解关系型数据库概念(表、主键、外键、索引)。MySQL或PostgreSQL是很好的起点。Java/Scala:深入理解Hadoop/Spark等框架会更有优势。初学者
- 大数据开发高频面试题:Spark与MapReduce解析
被招网约司机的盯上了好几天实习了六个月,到期被通知不能转正。外包裁员让我去友商我该去吗?offer比较华为状态码浏览器插件嵌入式项目推荐2019秋招总结+云从语音算法面经+银行群面面经科大讯飞语音算法面经语音算法美团一面已挂科大讯飞智能语音方向值得去吗?语音算法oc科大讯飞语音算法二面荣耀一面语音算法面经,已挂荣耀_语音算法工程一面科大讯飞语音一面凉经8.18携程机器学习(语音方向)一面【vivo
- spark处理kafka的用户行为数据写入hive
月光一族吖
sparkkafkahive
在CentOS上部署Hadoop(Hadoop3.4.1)和Hive(Hive3.1.2)的详细步骤说明。这份指南面向单机安装(伪集群模式),如果需要搭建真正的多节点集群,各节点间的网络互访、SSH免密登录以及配置同步需进一步调整。注意:本指南假设你已拥有root权限或者具有sudo权限,并且系统连接Internet(用于下载安装包)。步骤中的版本号可根据实际需要进行更改。一、环境准备更新系统软件
- Spark 4.0的VariantType 类型以及内部存储
鸿乃江边鸟
大数据SQLsparksparksql大数据
背景本文基于Spark4.0总结Spark中的VariantType类型,用尽量少的字节来存储Json的格式化数据分析这里主要介绍Variant的存储,我们从VariantBuilder.buildJson方法(把对应的json数据存储为VariantType类型)开始:publicstaticVariantparseJson(JsonParserparser,booleanallowDuplic
- 如何学习才能更好地理解人工智能工程技术专业和其他信息技术专业的关联性?
人工智能教学实践
python编程实践人工智能学习人工智能
要深入理解人工智能工程技术专业与其他信息技术专业的关联性,需要跳出单一专业的学习框架,通过“理论筑基-实践串联-跨学科整合”的路径构建系统性认知。以下是分阶段、可落地的学习方法:一、建立“专业关联”的理论认知框架绘制知识关联图谱操作方法:用XMind或Notion绘制思维导图,以AI为中心,辐射关联专业的核心技术节点。例如:AI(机器学习)├─数据支撑:大数据技术(Hadoop/Spark)+数据
- Spark从入门到熟悉(篇二)
本文介绍Spark的RDD编程,并进行实战演练,加强对编程的理解,实现快速入手知识脉络包含如下8部分内容:创建RDD常用Action操作常用Transformation操作针对PairRDD的常用操作缓存操作共享变量分区操作编程实战创建RDD实现方式有如下两种方式实现:textFile加载本地或者集群文件系统中的数据用parallelize方法将Driver中的数据结构并行化成RDD示例"""te
- Kafka生态整合深度解析:构建现代化数据架构的核心枢纽
Kafka生态整合深度解析:构建现代化数据架构的核心枢纽导语:在当今数据驱动的时代,ApacheKafka已经成为企业级数据架构的核心组件。本文将深入探讨Kafka与主流技术栈的整合方案,帮助架构师和开发者构建高效、可扩展的现代化数据处理平台。文章目录Kafka生态整合深度解析:构建现代化数据架构的核心枢纽一、Kafka与流处理引擎的深度集成1.1Kafka+ApacheSpark:批流一体化处理
- Spark on Docker:容器化大数据开发环境搭建指南
AI天才研究院
ChatGPT实战ChatGPTAI大模型应用入门实战与进阶大数据sparkdockerai
SparkonDocker:容器化大数据开发环境搭建指南关键词:Spark、Docker、容器化、大数据开发、分布式计算、开发环境搭建、容器编排摘要:本文系统讲解如何通过Docker实现Spark开发环境的容器化部署,涵盖从基础概念到实战部署的完整流程。首先分析Spark分布式计算框架与Docker容器技术的核心原理及融合优势,接着详细演示单节点开发环境和多节点集群环境的搭建步骤,包括Docker
- SeaTunnel 社区月报(5-6 月):全新功能上线、Bug 大扫除、Merge 之星是谁?
SeaTunnel
bugSeaTunnel开源数据集成大数据
在5月和6月,SeaTunnel社区迎来了一轮密集更新:2.3.11正式发布,新增对Databend、Elasticsearch向量、HTTP批量写入、ClickHouse多表写入等多个连接器能力,全面提升了数据同步灵活性。同时,近100个修复与优化PR合入,涵盖Spark引擎并行性修复、Paimon精度兼容性增强、Mongo-CDCExactlyOnce默认值优化、OracleDDL类型支持补全
- Spark从入门到熟悉(篇三)
小新学习屋
数据分析spark大数据分布式
本文介绍Spark的DataFrame、SparkSQL,并进行SparkSQL实战,加强对编程的理解,实现快速入手知识脉络包含如下7部分内容:RDD和DataFrame、SparkSQL的对比创建DataFrameDataFrame保存成文件DataFrame的API交互DataFrame的SQL交互SparkSQL实战参考资料RDD和DataFrame、SparkSQL的对比RDD对比Data
- 大数据集群架构hadoop集群、Hbase集群、zookeeper、kafka、spark、flink、doris、dataeas(二)
争取不加班!
hadoophbasezookeeper大数据运维
zookeeper单节点部署wget-chttps://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz下载地址tarxfapache-zookeeper-3.8.4-bin.tar.gz-C/data/&&mv/data/apache-zookeeper-3.8.4-bin//data/zoo
- ViewController添加button按钮解析。(翻译)
张亚雄
c
<div class="it610-blog-content-contain" style="font-size: 14px"></div>// ViewController.m
// Reservation software
//
// Created by 张亚雄 on 15/6/2.
- mongoDB 简单的增删改查
开窍的石头
mongodb
在上一篇文章中我们已经讲了mongodb怎么安装和数据库/表的创建。在这里我们讲mongoDB的数据库操作
在mongo中对于不存在的表当你用db.表名 他会自动统计
下边用到的user是表明,db代表的是数据库
添加(insert):
- log4j配置
0624chenhong
log4j
1) 新建java项目
2) 导入jar包,项目右击,properties—java build path—libraries—Add External jar,加入log4j.jar包。
3) 新建一个类com.hand.Log4jTest
package com.hand;
import org.apache.log4j.Logger;
public class
- 多点触摸(图片缩放为例)
不懂事的小屁孩
多点触摸
多点触摸的事件跟单点是大同小异的,上个图片缩放的代码,供大家参考一下
import android.app.Activity;
import android.os.Bundle;
import android.view.MotionEvent;
import android.view.View;
import android.view.View.OnTouchListener
- 有关浏览器窗口宽度高度几个值的解析
换个号韩国红果果
JavaScripthtml
1 元素的 offsetWidth 包括border padding content 整体的宽度。
clientWidth 只包括内容区 padding 不包括border。
clientLeft = offsetWidth -clientWidth 即这个元素border的值
offsetLeft 若无已定位的包裹元素
- 数据库产品巡礼:IBM DB2概览
蓝儿唯美
db2
IBM DB2是一个支持了NoSQL功能的关系数据库管理系统,其包含了对XML,图像存储和Java脚本对象表示(JSON)的支持。DB2可被各种类型的企 业使用,它提供了一个数据平台,同时支持事务和分析操作,通过提供持续的数据流来保持事务工作流和分析操作的高效性。 DB2支持的操作系统
DB2可应用于以下三个主要的平台:
工作站,DB2可在Linus、Unix、Windo
- java笔记5
a-john
java
控制执行流程:
1,true和false
利用条件表达式的真或假来决定执行路径。例:(a==b)。它利用条件操作符“==”来判断a值是否等于b值,返回true或false。java不允许我们将一个数字作为布尔值使用,虽然这在C和C++里是允许的。如果想在布尔测试中使用一个非布尔值,那么首先必须用一个条件表达式将其转化成布尔值,例如if(a!=0)。
2,if-els
- Web开发常用手册汇总
aijuans
PHP
一门技术,如果没有好的参考手册指导,很难普及大众。这其实就是为什么很多技术,非常好,却得不到普遍运用的原因。
正如我们学习一门技术,过程大概是这个样子:
①我们日常工作中,遇到了问题,困难。寻找解决方案,即寻找新的技术;
②为什么要学习这门技术?这门技术是不是很好的解决了我们遇到的难题,困惑。这个问题,非常重要,我们不是为了学习技术而学习技术,而是为了更好的处理我们遇到的问题,才需要学习新的
- 今天帮助人解决的一个sql问题
asialee
sql
今天有个人问了一个问题,如下:
type AD value
A
- 意图对象传递数据
百合不是茶
android意图IntentBundle对象数据的传递
学习意图将数据传递给目标活动; 初学者需要好好研究的
1,将下面的代码添加到main.xml中
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http:/
- oracle查询锁表解锁语句
bijian1013
oracleobjectsessionkill
一.查询锁定的表
如下语句,都可以查询锁定的表
语句一:
select a.sid,
a.serial#,
p.spid,
c.object_name,
b.session_id,
b.oracle_username,
b.os_user_name
from v$process p, v$s
- mac osx 10.10 下安装 mysql 5.6 二进制文件[tar.gz]
征客丶
mysqlosx
场景:在 mac osx 10.10 下安装 mysql 5.6 的二进制文件。
环境:mac osx 10.10、mysql 5.6 的二进制文件
步骤:[所有目录请从根“/”目录开始取,以免层级弄错导致找不到目录]
1、下载 mysql 5.6 的二进制文件,下载目录下面称之为 mysql5.6SourceDir;
下载地址:http://dev.mysql.com/downl
- 分布式系统与框架
bit1129
分布式
RPC框架 Dubbo
什么是Dubbo
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。其核心部分包含: 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。 集群容错: 提供基于接
- 那些令人蛋痛的专业术语
白糖_
springWebSSOIOC
spring
【控制反转(IOC)/依赖注入(DI)】:
由容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在:控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转。
简单的说:对象的创建又容器(比如spring容器)来执行,程序里不直接new对象。
Web
【单点登录(SSO)】:SSO的定义是在多个应用系统中,用户
- 《给大忙人看的java8》摘抄
braveCS
java8
函数式接口:只包含一个抽象方法的接口
lambda表达式:是一段可以传递的代码
你最好将一个lambda表达式想象成一个函数,而不是一个对象,并记住它可以被转换为一个函数式接口。
事实上,函数式接口的转换是你在Java中使用lambda表达式能做的唯一一件事。
方法引用:又是要传递给其他代码的操作已经有实现的方法了,这时可以使
- 编程之美-计算字符串的相似度
bylijinnan
java算法编程之美
public class StringDistance {
/**
* 编程之美 计算字符串的相似度
* 我们定义一套操作方法来把两个不相同的字符串变得相同,具体的操作方法为:
* 1.修改一个字符(如把“a”替换为“b”);
* 2.增加一个字符(如把“abdd”变为“aebdd”);
* 3.删除一个字符(如把“travelling”变为“trav
- 上传、下载压缩图片
chengxuyuancsdn
下载
/**
*
* @param uploadImage --本地路径(tomacat路径)
* @param serverDir --服务器路径
* @param imageType --文件或图片类型
* 此方法可以上传文件或图片.txt,.jpg,.gif等
*/
public void upload(String uploadImage,Str
- bellman-ford(贝尔曼-福特)算法
comsci
算法F#
Bellman-Ford算法(根据发明者 Richard Bellman 和 Lester Ford 命名)是求解单源最短路径问题的一种算法。单源点的最短路径问题是指:给定一个加权有向图G和源点s,对于图G中的任意一点v,求从s到v的最短路径。有时候这种算法也被称为 Moore-Bellman-Ford 算法,因为 Edward F. Moore zu 也为这个算法的发展做出了贡献。
与迪科
- oracle ASM中ASM_POWER_LIMIT参数
daizj
ASMoracleASM_POWER_LIMIT磁盘平衡
ASM_POWER_LIMIT
该初始化参数用于指定ASM例程平衡磁盘所用的最大权值,其数值范围为0~11,默认值为1。该初始化参数是动态参数,可以使用ALTER SESSION或ALTER SYSTEM命令进行修改。示例如下:
SQL>ALTER SESSION SET Asm_power_limit=2;
- 高级排序:快速排序
dieslrae
快速排序
public void quickSort(int[] array){
this.quickSort(array, 0, array.length - 1);
}
public void quickSort(int[] array,int left,int right){
if(right - left <= 0
- C语言学习六指针_何谓变量的地址 一个指针变量到底占几个字节
dcj3sjt126com
C语言
# include <stdio.h>
int main(void)
{
/*
1、一个变量的地址只用第一个字节表示
2、虽然他只使用了第一个字节表示,但是他本身指针变量类型就可以确定出他指向的指针变量占几个字节了
3、他都只存了第一个字节地址,为什么只需要存一个字节的地址,却占了4个字节,虽然只有一个字节,
但是这些字节比较多,所以编号就比较大,
- phpize使用方法
dcj3sjt126com
PHP
phpize是用来扩展php扩展模块的,通过phpize可以建立php的外挂模块,下面介绍一个它的使用方法,需要的朋友可以参考下
安装(fastcgi模式)的时候,常常有这样一句命令:
代码如下:
/usr/local/webserver/php/bin/phpize
一、phpize是干嘛的?
phpize是什么?
phpize是用来扩展php扩展模块的,通过phpi
- Java虚拟机学习 - 对象引用强度
shuizhaosi888
JAVA虚拟机
本文原文链接:http://blog.csdn.net/java2000_wl/article/details/8090276 转载请注明出处!
无论是通过计数算法判断对象的引用数量,还是通过根搜索算法判断对象引用链是否可达,判定对象是否存活都与“引用”相关。
引用主要分为 :强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Wea
- .NET Framework 3.5 Service Pack 1(完整软件包)下载地址
happyqing
.net下载framework
Microsoft .NET Framework 3.5 Service Pack 1(完整软件包)
http://www.microsoft.com/zh-cn/download/details.aspx?id=25150
Microsoft .NET Framework 3.5 Service Pack 1 是一个累积更新,包含很多基于 .NET Framewo
- JAVA定时器的使用
jingjing0907
javatimer线程定时器
1、在应用开发中,经常需要一些周期性的操作,比如每5分钟执行某一操作等。
对于这样的操作最方便、高效的实现方式就是使用java.util.Timer工具类。
privatejava.util.Timer timer;
timer = newTimer(true);
timer.schedule(
newjava.util.TimerTask() { public void run()
- Webbench
流浪鱼
webbench
首页下载地址 http://home.tiscali.cz/~cz210552/webbench.html
Webbench是知名的网站压力测试工具,它是由Lionbridge公司(http://www.lionbridge.com)开发。
Webbench能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webbench的标准测试可以向我们展示服务器的两项内容:每秒钟相
- 第11章 动画效果(中)
onestopweb
动画
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- windows下制作bat启动脚本.
sanyecao2314
javacmd脚本bat
java -classpath C:\dwjj\commons-dbcp.jar;C:\dwjj\commons-pool.jar;C:\dwjj\log4j-1.2.16.jar;C:\dwjj\poi-3.9-20121203.jar;C:\dwjj\sqljdbc4.jar;C:\dwjj\voucherimp.jar com.citsamex.core.startup.MainStart
- Java进行RSA加解密的例子
tomcat_oracle
java
加密是保证数据安全的手段之一。加密是将纯文本数据转换为难以理解的密文;解密是将密文转换回纯文本。 数据的加解密属于密码学的范畴。通常,加密和解密都需要使用一些秘密信息,这些秘密信息叫做密钥,将纯文本转为密文或者转回的时候都要用到这些密钥。 对称加密指的是发送者和接收者共用同一个密钥的加解密方法。 非对称加密(又称公钥加密)指的是需要一个私有密钥一个公开密钥,两个不同的密钥的
- Android_ViewStub
阿尔萨斯
ViewStub
public final class ViewStub extends View
java.lang.Object
android.view.View
android.view.ViewStub
类摘要: ViewStub 是一个隐藏的,不占用内存空间的视图对象,它可以在运行时延迟加载布局资源文件。当 ViewSt