mysql基础 -- DDl DML DQL 总结
mysql基础 -- DDl DML DQL 总结
-
-
- SQL是什么?
- 注释
- SQL分类
- DDL操作数据库,表
-
- 操作库
-
- C create : 创建
- R retrieve : 查询
- U updata:修改
- 操作表
-
- C create : 创建
- R retrieve : 查询
- U updata:修改
- D delete:删除
- DML:增删改
-
-
- 数据类型
- INSERT 插入
- UPDATE 更新
- DELETE 删除
-
- DQL查询
-
- 新建一张表
- 向表中插入数据
-
- 基础查询
- 查询所有列
- 条件查询
- 模糊查询 like
- 字段控制
- 查询结果去重
- 给列起别名
- 列之间的计算
- 查询结果排序:
- 聚合函数
- 查询分组
- having
- 分页
-
SQL是什么?
结构化查询语言(SQL)是用于关系数据库管理和数据操作的标准计算机语言。SQL用于查询,插入,更新和修改数据。
注释
单行注释:-- 注释内容
多行注释:/* 注释内容 */
SQL分类
SQL语言共分为四大类:
1.数据查询语言DDL 用来定义数据库对象:数据库,表,列。
2.数据操纵语言DML 用于对数据库当中的表进行增删改。
3.数据定义语言DQL 用于查询数据库当中表的记录。
4.数据控制语言DCL 用于定义数据库的权限(授权),安全级别,用户。
注意: SQL语句是不缺分大小写的。 但是实际使用中,要么纯大写、要么纯小写。
DDL操作数据库,表
操作库
C create : 创建
-- 创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;
R retrieve : 查询
-- 查询所有数据库
SHOW DATABASES;
-- 查看数据库字符集
SHOW CREATE DATABASE 数据库名;
--设置数据库字符集
CREATE DATABASE IF NOT EXISTS 数据库名 CHARACTER SET 字符集名;
U updata:修改
--设置数据库字符集
ALTER DATABASE IF NOT EXISTS 数据库名 CHARACTER SET 字符集名;
D delete:删除
-- 删除数据库
drop database 数据库名;
--判断数据库是否存在,存在删除
drop database if exists 数据库名;
#####使用数据库
-- 查询正在使用数据库
select database();
--使用数据库
use 数据库名称;
操作表
在数据库的表中,常见的数据类型:
| 类型 | 描述 |
|---|---|
| int | 整型,存储整数 |
| double | 浮点型,存储小数 double(4,3): 这个小数最多只有4位,且有三位是小数部分 |
| char | 字符串,在使用的时候需要定义长度 char(5): 每个数据占用固定的长度5 |
| varchar | 字符串,在使用的时候需要定义长度 varchar(5): 长度可动态调整的,这里的5只是一个上限 |
| text | 字符串,在使用的时候不需要指定长度 |
| blob | 字节类型 |
| date | 日期类型,格式是 yyyy-MM-dd |
| time | 时间类型,格式是 hh:mm:ss |
| timestamp | 时间戳,格式是 yyyy-MM-dd hh:mm:ss,会自动赋值 |
| datetime | 时间类型,格式是 yyyy-MM-dd hh:mm:ss |
C create : 创建
create table if not exists 表名(
列名1 数据类型1
.....
)
注意:
最后一列不加逗号
data:日期 年月日 yyyy-MM-dd
datatime:日期 年月日时分秒 yyyy-MM-dd HH:mm:ss
R retrieve : 查询
--查表
show tables;
--查表结构
desc 表名;
U updata:修改
--修改表名
alter table 表名 rename to 新表名;
-- 修改表的字符集
alter table if not exists 表名 character set 字符集名;
--添加一列
alter table 表名 add 列名 数据类型;
--修改列名称 类型
alter table 表名 change 列名 新列名 新数据类型;
alter table 表名 modify 列名 新数据类型;
-- 删除列
alter table 表名 drop 列名;
D delete:删除
drop table 表名;
drop table if exists 表名;
DML:增删改
数据类型
| 类型 | 描述 |
|---|---|
| int | 整型,存储整数 |
| double | 浮点型,存储小数 double(4,3): 这个小数最多只有4位,且有三位是小数部分 |
| char | 字符串,在使用的时候需要定义长度 char(5): 每个数据占用固定的长度5 |
| varchar | 字符串,在使用的时候需要定义长度 varchar(5): 长度可动态调整的,这里的5只是一个上限 |
| text | 字符串,在使用的时候不需要指定长度 |
| blob | 字节类型 |
| date | 日期类型,格式是 yyyy-MM-dd |
| time | 时间类型,格式是 hh:mm:ss |
| timestamp | 时间戳,格式是 yyyy-MM-dd hh:mm:ss,会自动赋值 |
| datetime | 时间类型,格式是 yyyy-MM-dd hh:mm:ss |
INSERT 插入
insert into 表 (列名1,列名2,列名3...) values (值1,值2,值3...); //向表中插入某些列
INSERT INTO users(id,name,sex,age) VALUES (NULL, 'jak', 'F', 33);
insert into 表 values (值1,值2,值3...); //向表中插入所有列
INSERT INTO users VALUES (NULL, 'jak', 'F', 33);
注意:
列名数与values后面的值的个数相等
列的顺序与插入的值的顺序一致
列名的类型与插入的值要一致
插入值的时候不能超过最大长度
值如果是字符串或者日期需要加引号’’
UPDATE 更新
update 表名 set 字段名=值,字段名=值... where 条件;
UPDATE users set name='lisea' where id = 1;
注意:
列名的类型与修改的值要一致
修改值的时候不能超过最大长度
值如果是字符串或者日期要加’’
DELETE 删除
delete from 表名 [where 条件];
DELETE FROM users WHERE id = 1;
delete from 表名; //删除表的全部数据
# 1. 删除表中的数据(删除表中全部的数据)
delete from t_student;
# 2. 删除所有数据
# 其实并不是删除表中的所有数据,这个语句的执行逻辑:
# 2.1. 记录当前表中的字段信息
# 2.2. 删除这张表
# 2.3. 按照记录的字段信息,重新创建一张一模一样的表
# 这个删除效率,是要比delete from 表,高
truncate t_student;
# 3. 删除指定条件的数据
delete from t_student where name='xiaoming';
delete from t_student where gender not in('male', 'female');
delete from t_student where score is null;
实战演练
DQL查询
从表中查询数据
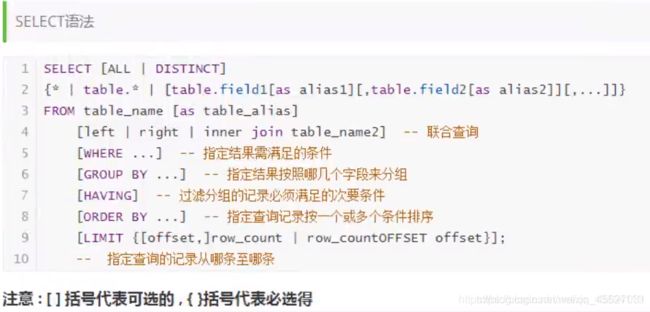
1,查询所有:select * from 表名 where 条件;
2,不能重复查询:select distinct 列名 from 表名 where 条件;
3,连接查询: select concat(列名1,列名2) from 表名;
4,列起别名: select 列名 as 显示列名 from 表名;
5,模糊查询: select * from 表名 where 列名 like ‘%字符串%’;
6,升序与降序:select * from 表名 order by 字段名 ASC(升序默认);
select * from 表名 order by 字段名 DESC(降序)
7,聚合函数:
select count(星) from 表名
select sum(列名) from 表名
select avg列名) from 表名
select max(列名) from 表名
select min(列名) from 表名
8,分组查询
select * from 表名 group by 列名
select * from 表名 group by 列名 HAVING count(*)>number
新建一张表
create table t_score(name varchar(5), java int, mysql int, linux int, hadoop int);
向表中插入数据
insert into t_score values
('张三丰', 59, 62, 70, 65),
('张无忌', 89, 76, 78, 76),
('张翠山', 87, 87, 68, 89),
('殷素素', 98, 89, 78, 67),
('郭靖', 55, 58, 60, 76),
('扫地僧', 99, 99, 99, 99),
('韦小宝', 87, 56, 87, 57),
('貂蝉', 88, 67, 53, 56);
基础查询
[select 列名 from 表]
select name from t_score;
select name, java, hadoop from t_score;
查询所有列
可以使用*替代列
select * from t_score;
条件查询
条件查询在查询的时候将条件放在where后面,where后条件的关键字有:
| – | 描述 |
|---|---|
| = | (等于) |
| < | (小于) |
| > | (大于) |
| != | (不等于) |
| <> | (不等于) |
| <= | (小于等于) |
| >= | (大于等于) |
| and | (表示所有条件都必须满足) |
| or | (表示所有条件中有一个满足就可以) |
| is null | (为空) |
| is not null | (不为空) |
| between … and… | (表示从指定开始的值到结束的值,包含开始值和结束值) |
| in(set) | 查找多个符合条件的内容。使用集合表示,多个值之间用逗号 |
| not(set) | 查找多个不符合条件的内容。 |
# 查询所有java不及格的学生姓名和全部的成绩
select * from t_score where java < 60;
# 查询所有的java不及格,并且mysql也不及格的全部信息
select * from t_score where java < 60 and mysql < 60;
# 查询所有的java成绩在80到90之间的学生信息
select * from t_score where java between 80 and 90;
# 查询java成绩和mysql成绩差值大于10分的所有学生信息
select * from t_score where mysql - java > 10 or java - mysql > 10;
# 查询hadoop成绩为空的学生信息
SELECT * FROM t_score WHERE hadoop IS NULL;
# 查询hadoop成绩为不为空的学生信息
SELECT * FROM t_score WHERE hadoop IS NOT NULL;
模糊查询 like
# _: 通配符,匹配任意的字符,只能匹配一位
# %: 通配符,匹配任意的字符,可以匹配多位
# 可以根据指定的条件,查询表中的相似的数据。
# 查询成绩表中所有姓张的学生信息
select * from t_score where name like '张%';
# 查询成绩表中所有姓张的,并且名字长度是3的学生信息
select * from t_score where name like '张__';
# 查询所有的mysql成绩是个位数的学生信息
select * from t_score where mysql like '_';
# 查询所有的hadoop成绩大于90分的学生信息
select * from t_score where hadoop like '9_';
查询所有的linux成绩尾数为8的学生信息
select * from t_score where linux like '%8';
字段控制
查询结果去重
# 关键字distinct,使用distinct修饰的字段,会进行去重
# 但是,distinct只能放在紧跟在select后面的位置,不能写在其他字段之后
# distinct后面如果有多个字段,会根据多个字段去重:每一个字段的值都相同,才会认为是重复的值
# 查询所有人的所有hadoop成绩,查询结果按照成绩去重
select distinct hadoop from t_score;
给列起别名
# 其实,这个查询,还是从t_score表中按照指定的键来查询数据,
# 只不过,将查询到的数据,在查询结果虚拟机表中的字段重新命名
select name as '姓名', java as 'Java成绩', mysql, linux, hadoop from t_score;
# as 关键字可以省略
select name '姓名' from t_score;
列之间的计算
# 需求:查询表中的所有人的所有成绩和总成绩
select *, java+mysql+linux+hadoop as '总成绩' from t_score;
# 列之间的相加注意事项: NULL值和任意的值相加,结果都是NULL。
# ifnull(列, 值): 如果指定列的值是NULL,则按照指定的值处理
select *, java+mysql+ifnull(linux,0)+hadoop as '总成绩' from t_score;
查询结果排序:
将查询的结果,按照一定的大小关系进行排列。
# 在查询语句的最后方,添加 order by 列
# order by 默认是按照指定的列进行升序排序,如果需要降序,则在最后添加一个 desc
# (注:升序排序,也可以在字段后面添加一个asc)
select *, java+mysql+ifnull(linux,0)+hadoop as '总成绩' from t_score order by java asc;
# 如果有多个排序依据,直接用逗号在后面拼接字段即可
select *, java+mysql+ifnull(linux,0)+hadoop as '总成绩' from t_score order by hadoop, linux;
# 需求:按照总成绩做降序
select *, java+mysql+ifnull(linux,0)+hadoop as '总成绩' from t_score order by java+mysql+ifnull(linux,0)+hadoop desc;
聚合函数
在查询到的所有的结果中,可以使用聚合函数,对某些数据进行一些操作。
| - | 描述 |
|---|---|
| count() | 计算数量,但是不会计算NULL。 |
| sum() | 计算总和 |
| avg() | 计算平均值 |
| max() | 计算最大值 |
| min() | 计算最小值 |
# 重点: 聚合函数,是作用于列。是做纵向计算的。
# 需求1: 统计这张表中有多少学生
select count(linux) from t_score;
# 需求2: 统计有多少人的MySQL成绩及格
select count(mysql) from t_score where mysql > 60;
# 需求3: 计算linux成绩的总和
select sum(linux) from t_score;
# 需求4: 计算hadoop成绩的平均值
select avg(hadoop) from t_score;
# 需求5: 计算Java成绩的最高分和最低分
select max(java), min(java) from t_score;
查询分组
# 可以将查询的结果,按照某一个字段进行分组,当这个字段的值相同的时候,这些数据视为一个分组。
# 给t_score表添加一个字段 group
alter table t_score add `group` int;
# 需求1: 查询每一个分组中有多少人
select `group`, count(`name`) from t_score group by `group`;
# 需求2: 查询每一个分组的java平均值
select `group`, avg(java) from t_score group by `group`;
# 关于where: 可以使用where子句,对要查询的数据进行过滤。
# 注意事项: where必须要放在分组之前。其实分组,是对where保留下来的数据进行分组的。
# 需求3: 查询第二组有多少人
select `group`, count(`name`) from t_score where `group` = 2 group by `group`;
# 需求4: 计算每一个分组中,分别有多少人的java不及格
select `group`, count(`name`) from t_score where java < 60 group by `group`;
# 需求5: 计算每一个分组的人数、java平均成绩和linux总成绩
select `group`, count(`name`), avg(java), sum(linux) from t_score group by `group`;
having
#和where是比较相似的。都是做的条件过滤。
#having和where的区别:
# 1. where要写到分组之前,过滤是发生在分组前的。having要写在分组之后,对分组后的数据进行过滤的。
# 2. where子句中不允许使用聚合函数。having后是可以使用聚合函数的。
# 需求: 查询所有的java平均分小于80分的分组id和java平均分
select `group`, avg(java) from t_score group by `group` having avg(java) < 80;
分页
# 可以将查询到的数据分成若干页。
# limit
# limit需要两个参数:
# 第一个参数,代表从第几个数据开始查询
# 第二个参数,代表每一页要查询多少个数据
select * from t_score limit 3, 2;
# 分页,可以分为真分页和假分页。
# 真分页: 从数据库中查询数据的时候,将数据分段读取。又叫做物理分页。
# 假分页: 直接从数据库中查询到所有的数据,在程序中进行逻辑处理。又叫做逻辑分页。
# 假分页优点: 效率高。
# 假分页缺点: 如果数据量过大,会出现内存溢出。