协同过滤算法
协同过滤算法
简介
协同过滤算法:
常用于电商系统的一种算法,基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。简单来说就是淘宝的,京东里面的**”猜你喜欢“**;
分类:
- 基于用户的协同过滤算法
- 基于物品的协同过滤算法
流程:
- 根据历史数据收集用户偏好
- 找到相似的用户或物品
1、基于用户的协同过滤算法
基于用户的协同过滤算法的实现主要需要解决两个问题,一是如何找到和你有相似爱好的人,也就是要计算数据的相似度
例如:有A,B,C三个用户,A,B都买了相同的三本书,C买了其中两本,那么就会给C推荐AB购买的另外一本书
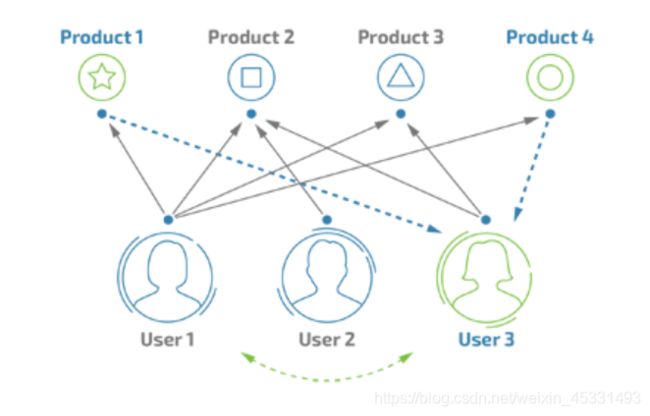
1.1、寻找偏好相似的用户
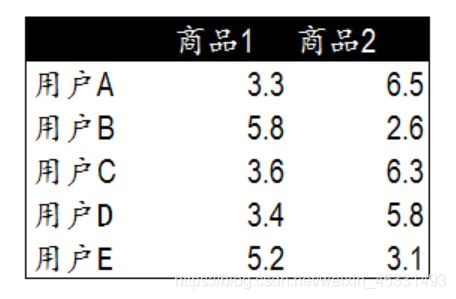
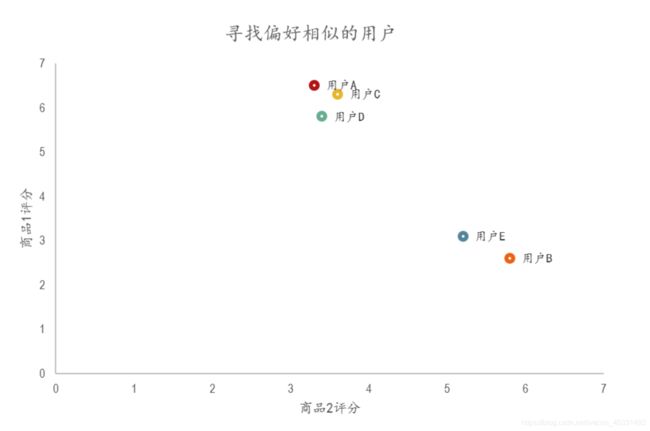
五个用户对于不同两个商品的评价,由于只有两个商品,可以通过散点图来直接观察它们之间的关系
1.2、欧氏距离算法
欧氏距离是最易于理解的一种距离计算方法
(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
![]()
(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
![]()
(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
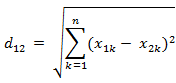
求两个用户之间的一个**”距离“**
public Double findSimilarCommodity(Double[] d1,Double[] d2){
double sum = 0;
for (int i = 0; i < d1.length; i++) {
sum += Math.pow((d1[i] - d2[i]), 2);
}
return Math.sqrt(sum);
}
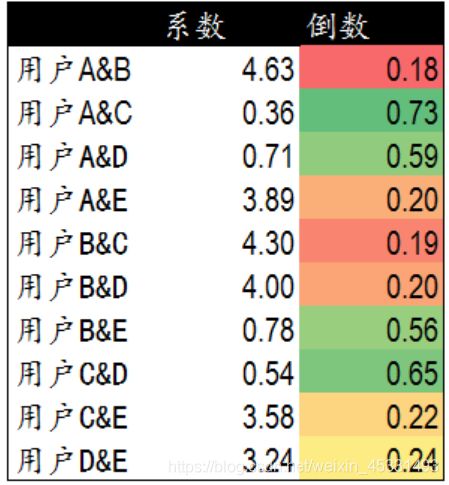
从得出的结果,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近,与散点图情况一致。
1.3 、皮尔逊相关度评价
在自然科学领域中,皮尔逊相关系数广泛用于度量两个变量之间的相关程度,其值介于-1与1之间
简单来说就是两组数据集,在一个坐标图上的落点,而这个范围就是x(-1,1),y(-1,1)
理解起来有些困难,但不理解也可以,需要做的就是通过对应的公式获取到两个用户之间的一个系数关系
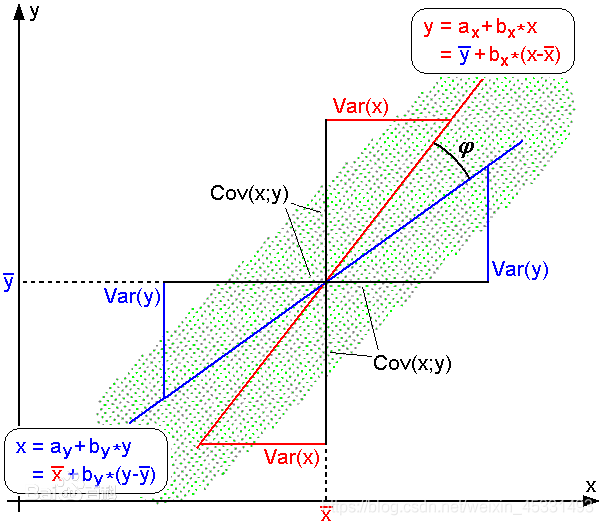
公式:
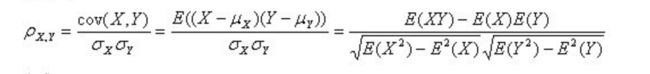
经过这个公式可以得出两个用户的皮尔逊相关系数,结果在-1到1之间。该系数两个用户间联系的强弱程度。
public Double getPearsonByDim(List<Double> ratingOne, List<Double> ratingTwo) {
try {
if(ratingOne.size() != ratingTwo.size()) {//两个变量的观测值是成对的,每对观测值之间相互独立。
if(ratingOne.size() > ratingTwo.size()) {//保留小的处理大
List<Double> temp = ratingOne;
ratingOne = new ArrayList<>();
for(int i=0;i<ratingTwo.size();i++) {
ratingOne.add(temp.get(i));
}
}else {
List<Double> temp = ratingTwo;
ratingTwo = new ArrayList<>();
for(int i=0;i<ratingOne.size();i++) {
ratingTwo.add(temp.get(i));
}
}
}
double sim = 0D;//最后的皮尔逊相关度系数
double commonItemsLen = ratingOne.size();//操作数的个数
double oneSum = 0D;//第一个相关数的和
double twoSum = 0D;//第二个相关数的和
double oneSqSum = 0D;//第一个相关数的平方和
double twoSqSum = 0D;//第二个相关数的平方和
double oneTwoSum = 0D;//两个相关数的乘积和
for(int i=0;i<ratingOne.size();i++) {//计算
double oneTemp = ratingOne.get(i);
double twoTemp = ratingTwo.get(i);
//求和
oneSum += oneTemp;
twoSum += twoTemp;
oneSqSum += Math.pow(oneTemp, 2);
twoSqSum += Math.pow(twoTemp, 2);
oneTwoSum += oneTemp*twoTemp;
}
double num = (commonItemsLen*oneTwoSum) - (oneSum*twoSum);
double den = Math.sqrt((commonItemsLen * oneSqSum - Math.pow(oneSum, 2)) * (commonItemsLen * twoSqSum - Math.pow(twoSum, 2)));
sim = (den == 0) ? 1 : num / den;
return sim;
} catch (Exception e) {
return null;
}
}
相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
结果如下:
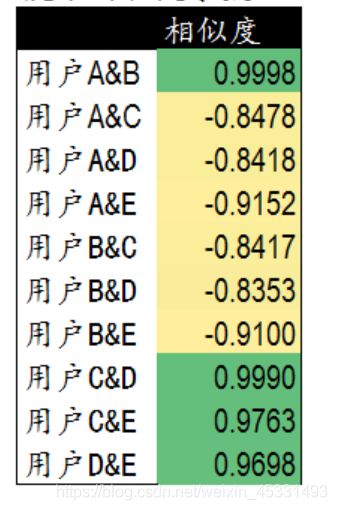
从结果可以知道 AB,CD,CE,DE具有较高的相似度,所以在推荐C商品的时候,就给C推荐D和E的商品。
当向C推荐DE的商品的时候,需要对多个商品进行一个排序,优先推荐C最合适的商品
公式:
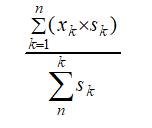
public Double sortGood(Double[] scores, Double[] coefficients){
double dine = 0;
double nums = 0;
for (int i = 0; i < scores.length; i++) {
dine += scores[i] * coefficients[i];
nums += coefficients[i];
}
return dine/nums;
}
排序结果:

问题:基于用户的协同过滤算法依靠用户的历史行为数据来计算相关度。也就是说必须要有一定的数据积累(冷启动问题)。对于新网站或数据量较少的网站,还有一种方法是基于物品的协同过滤算法。
2、基于物品的协同过滤算法
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将上诉算法中商品和用户互换即可。通过计算不同用户对不同物品的评分获得物品间的关系。