如何使用 YOLOv5 训练自己的数据集
跑代码 戳这里:
链接: 如何使用 YOLOv5 训练自己的数据集.
有小伙伴问:他们天天都在 yolo,yolo 的,是中国有嘻哈和目标检测有什么联系吗?

YOLO 是“You Only Look Once”的首字母缩写,是一种将图像划分为网格系统的目标检测算法。网格中的每个单元格负责检测自身内部的目标。由于其速度和准确性,YOLO 是最著名的物体检测算法之一。
链接: 如何使用 YOLOv5 训练自己的数据集.

下载代码
YOLO 是 Ultralytics 对视觉 AI 的开源研究,结合了在数千小时的研究和开发中获得的经验教训和最佳实践。YOLO 的代码目前托管在 GitHub 上,所以我们使用 git 工具将代码下载下来,并且安装要求的依赖。

数据来源
本次实验数据来源于 Kaggle 的 Global Wheat Detection。
该项目旨在利用这些图像数据来估计不同品种小麦头的密度和大小,便于农民在他们的田地做出管理决策时,可以使用这些数据来评估健康和成熟度。
然而,在室外田间图像中准确检测麦头在视觉上具有挑战性。密密麻麻的小麦植株经常重叠,风会模糊照片。两者都使识别单个头部变得困难。
此外,外观因成熟度、颜色、基因型和头部方向而异。最后,由于小麦在世界范围内种植,因此必须考虑不同的品种、种植密度、模式和田间条件。

DATA = '/home/featurize/data/'
df = pd.read_csv(os.path.join(DATA, 'train.csv'))
df.head(2)
| image_id 1 | height 2 | bbox 1 | source 2 |
|---|---|---|---|
| b6ab77fd7 | 1024 | 1024 | [834.0, 222.0, 56.0, 36.0] |
%matplotlib inline
随机可视化一个样本
%matplotlib inline
idx = random.randint(0, len(df) - 1)
img = cv2.imread(os.path.join(DATA, f'train/{df.iloc[idx].image_id}.jpg'))
def get_box(image_name):
df_single = df[df.image_id == image_name]
bboxes = list(df_single.bbox)
box_list = []
for box in bboxes:
box_list.append([int(float(i)) for i in box[1:-1].split(',')])
return box_list
box_list = get_box(df.iloc[idx].image_id)
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
for box in box_list:
cv2.rectangle(img, (box[0], box[1]), (box[0]+box[2], box[1]+box[3]), (0, 255, 0), 2)
ax.set_axis_off()
ax.imshow(img);

转换数据
原始数据的标注框数据是 [ xmin, ymin, width, height ],并不符合 YOLO 的原本数据格式。(很多数据集可能都会出现或多或少的不完全匹配的情况,我们需要做的就是将各种各样的标注框转换为 YOLO 的 [ x_center y_center width height ] 格式)

# convert [xmin, ymin, width, height] to [x_center y_center width height]
LABEL = '/home/featurize/data/labels/train'
for fn in tqdm(df.image_id.unique()):
box_list = get_box(fn)
with open(os.path.join(LABEL, f'{fn}.txt'), 'a') as f:
for box in box_list:
f.write(f'0 {(box[0] + box[2]/2)/1024} {(box[1] + box[3]/2)/1024} {(box[2])/1024} {(box[3])/1024}\n')
分割训练集与交叉验证集
通常我们会将 20% 的数据分出来作为交叉验证集来对模型的效果进行验证。
from sklearn.model_selection import train_test_split
X_train, X_test = train_test_split(df.image_id.unique(), test_size=0.2, random_state=42)
if not os.path.exists(os.path.join(DATA, 'images/val')):
os.mkdir(os.path.join(DATA, 'images/val'))
if not os.path.exists(os.path.join(DATA, 'labels/val')):
os.mkdir(os.path.join(DATA, 'labels/val'))
for i in tqdm(X_test):
try:
shutil.move(os.path.join(DATA, f'images/train/{i}.jpg',), os.path.join(DATA, f'images/val/{i}.jpg'))
shutil.move(os.path.join(DATA, f'labels/train/{i}.txt',), os.path.join(DATA, f'labels/val/{i}.txt'))
except:
print(i, 'not in train')
配置数据
要使用 YOLOv5 便捷的训练自己的数据集,那么整理好自己的数据目录结构一定是最快的方式。
dataset/
│ dataset.yaml
│
└───images/
│ └────train/ train 目录存放的是训练的图片
│ │ └────1.jpg
│ │ └────2.jpg
│ │ ...
│ └────val/ val 目录存放的是交叉验证集的图片
│
└───labels/
└────train/
│ └────1.txt txt 文件里是对应同名的 images 里的图片标注,每一行为一个标注框
│ └────2.txt 例:0 0.88 0.79 0.09 0.07
│ ... 类别 标注框中心 x 轴相对坐标 标注框中心 y 轴相对坐标 标注框相对宽度 标注框相对高度
└────val/ 注意:标注框为小数是相对于图片尺寸的归一化 标注框高度 =(框高度 / 图片高度)
训练
(这次训练是基于 Tesla V100-SXM2-16GB 显卡训练的,不同的 GPU 硬件可能需要对 batchsize 进行适当调整)
- –img 设置图片的大小
- –batch 设置每个批次送进模型的数据量,俗称 batchsize
- –epochs 设置训练的轮数
- –data 设置刚才配置好的 yaml 文件的路径
- –weights 设置模型(在 coco 数据集上预训练的模型)
!python yolov5/train.py --img 1024 --batch 16 --epochs 10 --data /home/featurize/data/dataset.yaml --weights yolov5s.pt
train: weights=yolov5s.pt, cfg=, data=/home/featurize/data/dataset.yaml, hyp=data/hyps/hyp.scratch.yaml, epochs=10, batch_size=16, imgsz=1024, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, adam=False, sync_bn=False, workers=8, project=runs/train, entity=None, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, upload_dataset=False, bbox_interval=-1, save_period=-1, artifact_alias=latest, local_rank=-1, freeze=0, patience=100
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
YOLOv5 v5.0-419-gc5360f6 torch 1.8.1+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160.5MB)
hyperparameters: lr0=0.01, lrf=0.2, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
2021-09-11 17:50:55.202084: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 3 156928 models.common.C3 [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1182720 models.common.C3 [512, 512, 1, False]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 283 layers, 7063542 parameters, 7063542 gradients, 16.4 GFLOPs
Transferred 356/362 items from yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 59 weight, 62 weight (no decay), 62 bias
albumentations: version 1.0.3 required by YOLOv5, but version 1.0.0 is currently installed
train: Scanning '/home/featurize/data/labels/train' images and labels...2698 fou
train: New cache created: /home/featurize/data/labels/train.cache
val: Scanning '/home/featurize/data/labels/val' images and labels...675 found, 0
val: New cache created: /home/featurize/data/labels/val.cache
Plotting labels...
autoanchor: Analyzing anchors... anchors/target = 5.72, Best Possible Recall (BPR) = 0.9991
Image sizes 1024 train, 1024 val
Using 8 dataloader workers
Logging results to runs/train/exp6
Starting training for 10 epochs...
Epoch gpu_mem box obj cls labels img_size
0/9 8.73G 0.08772 0.3469 0 591 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.385 0.51 0.395 0.111
Epoch gpu_mem box obj cls labels img_size
1/9 10.2G 0.05916 0.3294 0 796 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.787 0.757 0.785 0.285
Epoch gpu_mem box obj cls labels img_size
2/9 10.2G 0.05187 0.33 0 801 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.857 0.826 0.884 0.374
Epoch gpu_mem box obj cls labels img_size
3/9 10.2G 0.04985 0.3246 0 524 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.892 0.873 0.919 0.415
Epoch gpu_mem box obj cls labels img_size
4/9 10.2G 0.04505 0.3226 0 995 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.876 0.854 0.9 0.399
Epoch gpu_mem box obj cls labels img_size
5/9 10.2G 0.04381 0.31 0 497 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.904 0.891 0.936 0.48
Epoch gpu_mem box obj cls labels img_size
6/9 10.2G 0.0419 0.3135 0 627 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.91 0.884 0.935 0.493
Epoch gpu_mem box obj cls labels img_size
7/9 10.2G 0.0387 0.3026 0 653 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.919 0.89 0.943 0.514
Epoch gpu_mem box obj cls labels img_size
8/9 10.2G 0.03727 0.3009 0 557 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.927 0.885 0.945 0.522
Epoch gpu_mem box obj cls labels img_size
9/9 10.2G 0.03671 0.2964 0 489 1024: 100%|█|
Class Images Labels P R [email protected] mAP@
all 675 29422 0.925 0.898 0.949 0.531
10 epochs completed in 0.136 hours.
Optimizer stripped from runs/train/exp6/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp6/weights/best.pt, 14.5MB
Results saved to runs/train/exp6
查看训练结果
注意上面的 Results saved to runs/train/exp6,这是保存训练结果的路径,下面可视化的路径要和上面保持一致。
plot_results('./runs/train/exp6/results.csv')
image = mi.imread('./runs/train/exp6/results.png')
f, ax = plt.subplots(figsize=(16,8))
ax.set_axis_off()
ax.imshow(image);
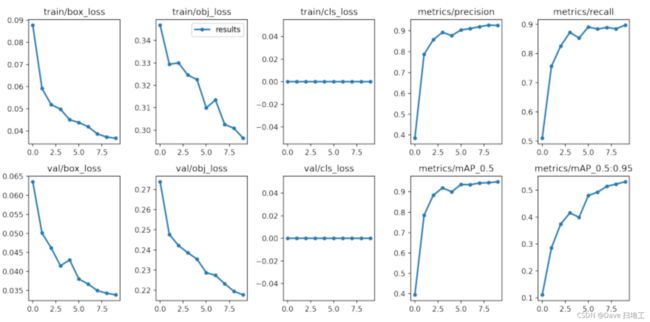
模型推断
训练好了以后当然是对目标测试数据集进行推断。
- –source 是目标数据集的目录,目录中是所有需要进行推断的图片文件
- –weights 是选择之前训练的模型
!python yolov5/detect.py --source /home/featurize/data/test --weights ./runs/train/exp4/weights/best.pt
detect: weights=['./runs/train/exp4/weights/best.pt'], source=/home/featurize/data/test, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
requirements: /cloud/notebooks/requirements.txt not found, check failed.
YOLOv5 v5.0-419-gc5360f6 torch 1.8.1+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160.5MB)
Fusing layers...
Model Summary: 224 layers, 7053910 parameters, 0 gradients, 16.3 GFLOPs
image 1/10 /home/featurize/data/test/2fd875eaa.jpg: 640x640 29 wheats, Done. (0.011s)
image 2/10 /home/featurize/data/test/348a992bb.jpg: 640x640 38 wheats, Done. (0.011s)
image 3/10 /home/featurize/data/test/51b3e36ab.jpg: 640x640 25 wheats, Done. (0.011s)
image 4/10 /home/featurize/data/test/51f1be19e.jpg: 640x640 18 wheats, Done. (0.011s)
image 5/10 /home/featurize/data/test/53f253011.jpg: 640x640 32 wheats, Done. (0.011s)
image 6/10 /home/featurize/data/test/796707dd7.jpg: 640x640 25 wheats, Done. (0.011s)
image 7/10 /home/featurize/data/test/aac893a91.jpg: 640x640 23 wheats, Done. (0.011s)
image 8/10 /home/featurize/data/test/cb8d261a3.jpg: 640x640 29 wheats, Done. (0.011s)
image 9/10 /home/featurize/data/test/cc3532ff6.jpg: 640x640 27 wheats, Done. (0.011s)
image 10/10 /home/featurize/data/test/f5a1f0358.jpg: 640x640 28 wheats, Done. (0.011s)
Results saved to runs/detect/exp3
Done. (0.578s)
plt.subplots(figsize=(16,16))[1].imshow(cv2.cvtColor(cv2.imread('./runs/detect/exp2/2fd875eaa.jpg'),cv2.COLOR_BGR2RGB));
总结
这个笔记本主要是帮助不会使用 YOLO 的小伙伴把代码跑起来而已,赶快试一试吧。
原文链接跑代码: 如何使用 YOLOv5 训练自己的数据集.
