Java实现八大排序算法【九千字超详解】
博客首页:痛而不言笑而不语的浅伤
欢迎关注点赞 收藏 ⭐留言 欢迎讨论!
本文由痛而不言笑而不语的浅伤原创,CSDN首发!
系列专栏:《学习经验》
首发时间:2022年5月10日
❤:热爱Java学习,期待一起交流!
作者水平有限,如果发现错误,求告知,多谢!
有问题可以私信交流!!!
目录
一、排序的概述
排序的分类
优点及缺点
如何选择排序算法
8种排序之间的关系:
二、插入排序
分类
直接插入排序
希尔排序
三、交换排序
分类
冒泡排序法:
快速排序:
四、选择排序
分类
直接选择排序
堆排序
五、归并排序
使用方法
六、基数排序
使用方法:
总结:
按平均的时间性能来分
按平均的空间性能来分
排序方法的稳定性能
一、排序的概述
排序的分类
分为5大类:
1.插入排序(直接插入排序、希尔排序)。
2.交换排序(冒泡排序、快速排序)。
3.选择排序(直接选择排序、堆排序)。
4.归并排序。
5.分配排序(箱排序、基数排序)。
优点及缺点
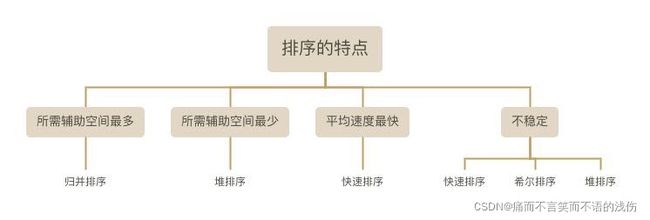
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
如何选择排序算法
1.数据的规模;
2.数据的类型;
3.数据已有的顺序。
一般来说,当数据规模较小时,应选择直接插入排序或冒泡排序。任何排序算法在数据量小时基本体现不出来差距。考虑数据的类型,比如如果全部是正整数,那么考虑使用桶排序为最优。考虑数据已有顺序,快排是一种不稳定的排序(当然可以改进),对于大部分排好的数据,快排会浪费大量不必要的步骤。数据量极小,而起已经基本排好序,冒泡是最佳选择。我们说快排好,是指大量随机数据下,快排效果最理想。而不是所有情况。
8种排序之间的关系:

二、插入排序
分类
1.直接插入排序。
2.希尔插入排序。
直接插入排序
说明
将一个记录插入到已经排序好的有序表中。
1.sorted数组的第0个位置没有放数据。
2.从sorted第二个数据开始处理。
如果该数据比它前面的数据要小,说明该数据要往前面移动。
用法
a.首先将该数据备份放到sorted的第0位置当哨兵。
b.然后将该数据前面那个数据后移。
c.然后往前搜索,找插入位置。
d.找到插入位置之后讲第0位置的那个数据插入对应位置。
O(n*n),当待排记录序列为正序时,时间复杂度提高至O(n)。
实例:

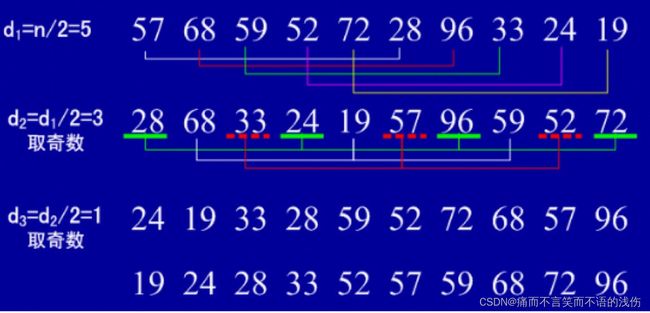
希尔排序
1.先将整个待排记录序列分割成若干个子序列分别进行直接插入排序。
2.待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
实例:
插入排序Java代码:
public class InsertionSort{
//插入排序:直接插入排序,希尔排序
public void straightInsertionSort(double[]sorted){
int sortedLen=sorted.length;
for(intj=2;j=0;k--){
if(sorted[k]>sorted[0]){
sorted[k+1]=sorted[k];
}else{
insertPos=k+1;
break;
}
}
sorted[insertPos]=sorted[0];
}
}
}
public void shellInertionSort(double[] sorted, int inc){
int sortedLen=sorted.length;
for(intj=inc+1:j=0;k-=inc){
if(sorted[k]>sorted[0]){
sorted[k+inc]=sorted[k];//数据结构课本上这个地方没有给出判读出错:
if(k-inc<=0){
insertPos=k;
}
}else{
insertPos=k+inc;
break;
}
}
sorted[insertPos]=sorted[0];
}
}
}
public void shellInsertionSort(double[] sorted){
int[]incs={7,5,3,1};
int num=incs.length;
int inc=0;
for(int j=0;j
三、交换排序
分类
1.冒泡排序。
2.快速排序。
冒泡排序法:
该算法是专门针对已部分排序的数据进行排序的一种排序算法。如果在你的数据清单中只有一两个数据是乱序的话,用这种算法就是最快的排序算法。如果你的数据清单中的数据是随机排列的,那么这种方法就成了最慢的算法了。因此在使用这种算法之前一定要慎重。这种算法的核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。

快速排序:
通过一趟排序,将待排序记录分割成独立的两个部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。具体做法是:使用两个指针lowhigh,初值分别设置为序列的头,和序列的尾,设置pivotkey为第一个记录,首先从high开始向前搜索第一个小于pivotkey的记录和pivotkey所在位置进行交换,然后从low开始向后搜索第一个大于pivotkey的记录和此时pivotkey所在位置进行交换,重复知道low=high了为止。

冒泡排序Java代码:
public class bubbleSort {
public bubbleSortO(){
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
int temp=0;
for(int i=0;ia[j+1]){
temp=a[i];
a[i]=a[j+1];
a[j+1]=temp;
}
}
}
for(int i=0;i 快速排序Java代码:
public class quickSort {
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
public quickSortO{ quick(a);
for(int i=0;i=tmp){
high--;
}
list[low]=list[high];//比中轴小的记录移到低端
while(low0){//查看数组是否为空
quickSort(a2,0,a2.length-1);
}
}
}
四、选择排序
分类
1.直接选择排序。
2.堆排序
直接选择排序
第i次选取到arrayLength-1中间最小的值放在i位置。

堆排序
首先,数组里面用层次遍历的顺序放一棵完全二叉树。从最后一个非终端结点往前面调整,直到到达根结点,这个时候除根节点以外的所有非终端节点都已经满足堆得条件了,于是需要调整根节点使得整个树满足堆得条件,于是从根节点开始,沿着它的儿子们往下面走(最大堆沿着最大的儿子走,最小堆沿着最小的儿子走)。主程序里面,首先从最后一个非终端节点开始调整到根也调整完,形成一个heap,然后将heap的根放到后面去(即:每次的树大小会变化,但是root都是在1的位置,以方便计算儿子们的index,所以如果需要升序排序,则要逐步大顶堆。因为根节点被一个个放在后面去了,降序排序则要建立小顶堆。
实例:
初始序列:46,79,56,38,40,84
建堆:

交换从堆中踢出最大数

剩余结点再建堆,再踢出最大数

依次类推:最后堆中剩余的最后两个结点交换踢出一个,排序完成。
代码中的问题:有时候第2个和第3个顺序不对(原因还没搞明白到底代码哪里有错)
选择排序Java代码:
public class selectSort {
public selectSort(){
int a[]={1,54,6,3,78,34,12,45};
int position=0;
for(int i=0;i堆排序代码:
importjava.util.Arrays;
public class HeapSort {
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
public HeapSort(){
heapSort(a);
}
public void heapSort(int[]a{
System.outprintln("开始排序");
int arraylength=a.length;//循环建堆
for(int i=0;i=0;i--){
//K保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex 五、归并排序
使用方法
将两个或两个以上的有序表组合成一个新的有序表。归并排序要使用一个辅助数组,大小跟原数组相同,递归做法。每次将目标序列分解成两个序列,分别排序两个子序列之后,再将两个排序好的子序列merge到一起。

归并排序Java代码:
public class MergeSort {
private double[]bridge;//辅助数组
public void sort(double[] obj){
if(obj==null){
throw new NullPointerException("The param can not be null!");
}
bridge=new double[obj.length];//初始化中间数组
mergeSort(obj,,obj.length-1);//归并排序
bridge =null;
}
private void mergeSort(double[] obj,int left,int right){
if(left六、基数排序
使用方法:
使用10个辅助队列,假设最大数的数字位数为 x,则一共做x次,从个位数开始往前,以第i位数字的大小为依据,将数据放进辅助队列,搞定之后回收。下次再以高一位开始的数字位为依据。

以Vector作辅助队列,基数排序的Java代码:
public class RadixSort {
private int keyNum=-1;
private Vector> util;
public void distribute(double []sorted,int nth){
if(nth<=keyNum && nth>0){
util=new Vector>();
for(intj=0;j<10;j++){
Vector temp=new Vector();
util.add(temp);
}
for(int j=0;j=nth){
return CharactergetNumericValue(nncharAt(len nth));
}else{
return 0;
}
}
public void collect(double[]sorted){
int k=0;
for(int j=0;j<10;j++){
int len=util.get(j).size();
if(len>0){
for(int i=0;imax){
max=sorted [j];
}
}
return Integer.toString((int)max).length();
}
public void radixSort(double[] sorted){
if(keyNum==-1){
keyNum= getKeyNum(sorted);
}
for(int i=1;i<=keyNum;i++){
distribute(sorted,i);
collect(sorted);
}
}
public static void main(String[]args){
Random random=new Random(6);
int arraysize=21;
double[]sorted=new double[arraysize] ;
System.outprint("Before Sort:");
for(intj=0;j 总结:
按平均的时间性能来分
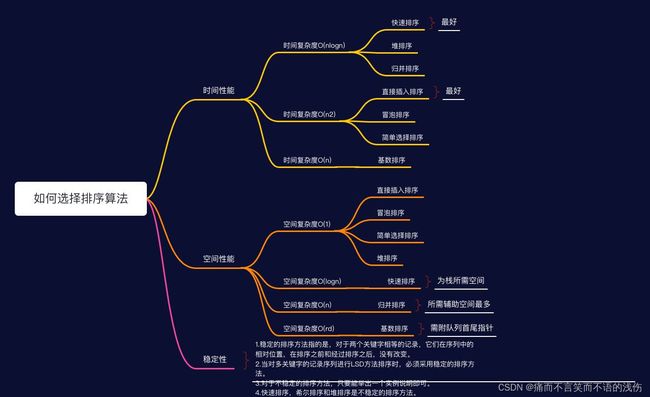
1.时间复杂度为O(nlogn)的方法有:快速排序、堆排序和归并排序,其中以快速排序为最好;
2.时间复杂度为O(n2)的有:直接插入排序、冒泡排序和简单选择排序,其中以直接插入为最好,特别是对那些对关键字近似有序的记录序列尤为如此;
3.时间复杂度为O(n)的排序方法只有,基数排序。
当待排记录序列按关键字顺序有序时,直接插入排序和起泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能蜕化为O(n2),因此是应该尽量避免的情况。简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
按平均的空间性能来分
(指的是排序过程中所需的辅助空间大小):
1.所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1);
2.快速排序为O(logn),为栈所需的辅助空间;
3.归并排序所需辅助空间最多,其空间复杂度为O(n );
4.链式基数排序需附设队列首尾指针,则空间复杂度为O(rd)。
排序方法的稳定性能
1.稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。
2.当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。
3.对于不稳定的排序方法,只要能举出一个实例说明即可。
4.快速排序,希尔排序和堆排序是不稳定的排序方法。

最后,大家重点要掌握每个排序算法的使用方法、还有如何选择,在什么样的情况下用什么的排序算法,以达到效率最好,使用后最优化代码。
好啦!今天的练习就到这里。看吧这么努力的你又学到了很多,新的一天加油鸭!!!
【完】
你的点赞是对我最大的鼓励。
你的收藏是对我文章的认可。
你的关注是对我创作的动力。
