Kafka 压测:3 台廉价服务器竟支撑 200 万 TPS
-
Kafka in 30 seconds
-
This Benchmark
-
The Setup
-
Producer Throughput
-
Consumer Throughput
这篇文章是关于LinkedIn如何用kafka作为一个中央发布-订阅日志,在应用程序,流处理,hadoop数据提取之间集成数据。无论如何,kafka日志一个好处就是廉价。百万级别的TPS都不是很大的事情。因为日志比起数据库或者K-V存储是更简单的东西。我们的生产环境kafka集群每天每秒处理上千万读写请求,并且只是构建在一个非常普通的硬件上。
接下来让我们做一些压测,看看kafka究竟多么牛逼。
Kafka in 30 seconds
为了帮助理解接下来的压测,首先让我们大概了解一下kafka是什么,以及一些kafka工作的细节。kafka是LinkedIn开发一个分布式消息系统,现在是 Apache Software Foundation的成员之一,并且非常多的公司在使用kafka。
生产者将记录发送到kafka集群,集群保留这些记录并将其交给消费者;

01-producer_consumer.png
kafka一个最核心的概念就是topic(笔者在这里并不打算翻译它,无论翻译成什么都觉得变味了)。生产者发布记录到topic,消费者订阅一个或多个topic。kafka的topic实际上就是一个分区后的write-ahead log。生产者把需要发布的记录追加到这些日志后面。消费者订阅它们。每一个记录都是一个K-V对,key主要用于分配记录到日志分区。
下图是一个简单的示例图,生产者如何写记录到一个拥有两个分区的topic,以及消费者如何读这个topic:

02-partitioned_log_0.png
上图展示了生产者如何追加日志到两个分区,以及消费者读取日志。日志中每条记录都有一个相关的条目编号,我们把它称为offset。消费者使用offset来描述其在每个日志中的位置。
这些分区分区在集群的各个服务器上。
需要注意kafka与很多消息系统不一样,它的日志总是持久化,当接收到消息后,会立即写到文件系统。消费者读消息时消息并不会被删除。它的保留策略通过配置来决定。这就允许在数据使用者可能需要重新加载数据的情况下使用。并且也能节省空间,无论多少消费者,日志共享一份。
传统的消息系统,常常一个消费者一个队列,因此增加消费者,数据空间就会成倍增加。这使得Kafka非常适合普通消息传递系统之外的事物,例如充当离线数据系统(如Hadoop)的管道。 这些离线系统可能仅作为周期性ETL周期的一部分在一定时间间隔加载,或者可能会停机几个小时进行维护,在此期间,如果需要,Kafka能够缓冲甚至TB量级的未消耗数据。
kafka也复制日志到多台服务器上,为了容错。复制实现是kafka一个非常重要的架构特性。和其他消息系统相比,复制不是一种需要复杂配置的异乎寻常的插件,只能在非常特殊的情况下使用。 相反,kafka的架构复制被假定为默认值:我们将未复制的数据视为复制因子恰好为1的特殊情况。
生产者在发布包含记录偏移量的消息时会收到确认。发送到同一个分区的第一条记录分配的offset为0,第二条是1,以此类推。消费者通过offset指定的位置消费数据,并且消费者通过周期性的提交topic(名为__consumer_offsets)从而保存代表消息位置的offset到日志中,达到持久化的目标。保存这个offset的目的是为了消费者崩溃后,其他消费者能从保存的位置继续消费消息。
kafka简单介绍到此为止,系统这一切都有意义。
This Benchmark
对于此次基准测试,我喜欢遵循我称之为“懒惰基准测试(lazy benchmarking)”的风格。当您使用系统时,您通常拥有将其调整到任何特定用例的完美的专有技术。这导致了一种基准测试,您可以将配置大幅调整到基准测试,或者更糟糕的是针对您测试的每个场景进行不同的调整。我认为系统的真正测试不是它在完美调整时的表现,而是它如何“现成”执行。对于在具有数十个或数百个用例的多租户设置中运行的系统尤其如此,其中针对每个用例的调优不仅不切实际而且不可能。因此,我几乎坚持使用服务器和客户端的默认设置。我将指出我怀疑通过一点调整可以改善结果的区域,但我试图抵制任何摆弄自己以改善结果的诱惑。
配置和压测命令文末会贴出来,所以如果你感兴趣的话,在你们的服务器上也能重现本文的压测结果。
The Setup
本次测试,总计6台服务器,配置如下:
-
Intel Xeon 2.5 GHz processor with six cores
-
Six 7200 RPM SATA drives
-
32GB of RAM
-
1Gb Ethernet
kafka集群安装在其中的3台服务器上,6块硬盘直接挂载,没有RAID。另外三台服务器用于Zookeeper和压力测试。
3台服务器的集群不是很大,但是因为我们只测试复制因子为3,所以三台服务器集群足够。显而易见的是,我们能通过增加更多的分区,传播数据到更多的服务器上来水平扩展我们的集群。
这些硬件不是LinkedIn平常使用的kafka硬件。我们的kafka服务器有针对性的调优,能更好的运行的运行kafka。这次测试,我从Hadoop集群中借用了这几台服务器,这些服务器都是我们持久化系统中最便宜的设备。 Hadoop的使用模式与Kafka非常相似,所以这是一件合理的事情。
Producer Throughput
接下来的测试是压测生产者的吞吐量,测试过程中没有消费者运行,因此所有消息被持久化(稍后会测试生产者和消费者都存在的场景),但是没有被读取。
Single producer thread, no replication
-
821,557 records/sec
-
78.3 MB/sec
这第一个测试基于的topic:6个分区,没有副本。然后单线程尽可能快的产生5千万个小记录(100byte)。在这些测试中关注小记录的原因是它对于消息系统来说是更难的情况。如果消息很大,很容易以MB/秒获得良好的吞吐量,但是当消息很小时反而很难获得良好的吞吐量,因为处理每个消息的开销占主导地位。
一个直接的观察是,这里的压测数据远高于人们的预期,特别是对于持久存储系统。 如果您习惯于随机访问数据系统(如数据库或键值存储),通常会产生大约5,000到50,000次查询的最大吞吐量,这接近于良好的RPC层可以执行的速度远程请求。 由于两个关键设计原则,我们超过了这一点:
-
我们努力确保我们进行线性磁盘I/O。这些服务器提供的六块廉价磁盘的线性总吞吐量为822 MB /秒。许多消息系统将持久性视为昂贵的附加组件,认为其会降低性能并且应该谨慎使用,但这是因为它们没有进行线性I/O.
-
在每个阶段,我们都致力于将少量数据批量合并到更大的网络和磁盘I/O操作中。 例如,在新生产者中,我们使用“group commit”类似的机制来确保在另一个I/O正在进行中时发起的任何记录被组合在一起。 有关了解批处理重要性的更多信息,请参阅David Patterson写的"Latency Lags Bandwidth"。
Single producer thread, 3x async replication
-
786,980 records/sec
-
75.1 MB/sec
这次测试和前一次的测试几乎一样,除了每个分区有三个副本(因此写到网络或者磁盘的数据是前一次的三倍)。每个服务器都从生产者那里为它作为leader分区执行写操作,以及为其作为follower分区获取和写入数据。
本次测试的复制是异步的,即acks=0。消息只要写到本地日志即可,不需要等待这个分区的其他副本收到消息。这就意味着,如果leader崩溃,可能会丢失最新的一些还未同步到副本的消息。
我希望人们能从中得到的关键是复制可以更快。对应3x复制,集群总写入能力有3倍的退化,因为每个写操作要做3次。但是每个客户端的吞吐量依然表现不错。 高性能复制在很大程度上取决于我们的消费者的效率,后面会在消费者部分讨论。
Single producer thread, 3x sync replication
-
421,823 records/sec
-
40.2 MB/sec
此次测试和前面的测试一样,除了leader需要等待所有in-sync replicas确认收到消息才会返回结果给生产者。即acks=all或者acks=-1。这种模式下,只要有一个in-sync replica存在,消息就不会丢失。
Kafka中的同步复制与异步复制没有根本的不同。分区leader总是跟踪follower副本进度,监控它们是否存在。在所有in-sync replicas确认收到消息之前,我们永远不会向消费者发出消息。使用同步复制,我们要等待响应给生产者的请求,直到follower副本都已经复制。
这种额外的延迟似乎会影响我们的吞吐量。由于服务器上的代码路径非常相似,我们可以通过调整批处理来更好地改善这种影响,并允许客户端缓冲更多未完成的请求。 但是,本着避免特殊情况调整的原则,我没有这么做。
Three producers, 3x async replication
-
2,024,032 records/sec
-
193.0 MB/sec
我们的单一生产者处理显然不能压出三节点集群的能力上限。为了增加负载,重复前面的异步复制模式测试流程,但是在三台不同服务器上运行三个不同的生产者(在同一台机器上运行更多进程将无助于我们使NIC饱和)。然后,我们可以查看这三个生产者的总吞吐量,以更好地了解群集的总容量。
Producer Throughput VS. Stored Data
许多消息系统一个隐藏的危险是,只有在他们保存的数据在内存中才会工作的很好。当数据备份不能被消费时(数据就需要存储到磁盘上),吞吐量会下降几个等级,甚至更多。这就意味着只有在消费者速度能跟上生产者,并且队列是空的情况下系统才会运行良好。一旦消费者落后,没有消费的消息需要备份,备份可能会使数据持久化到磁盘上,这就会引起性能大幅下降。这意味着消息传递系统无法跟上传入的数据。这种情况非常严重,消息系统在大部分情况下,应该能做到平和的处理队列中的消息。
kafka总是采用追加的方式持久化消息,并且对于没有消费的数据,持久化的的时间复杂度是 O(1)。
这次实验测试,让我们在一段延长的时间内运行吞吐量测试,并在存储的数据集增长时绘制结果图:
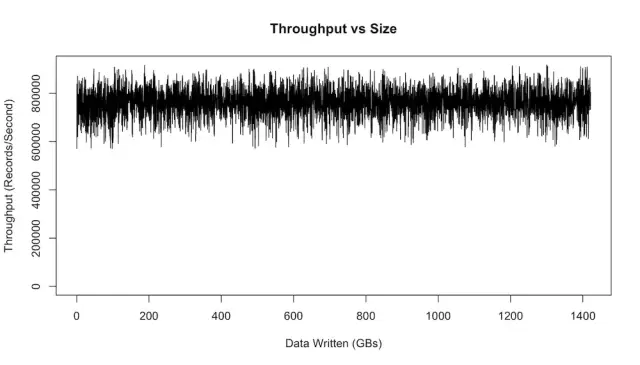
03-throughput_vs_size_0.png
如图所示,性能并没有明显的变化。但是由于数据大小所以没有影响:我们在写入TB数据之后也表现得同样好,就像前几百MB一样。
图中的性能波动主要是因为Linux系统I/O管理批量处理数据,周期性的把数据flush到磁盘。LinkedIn的kafka生产环境上针对这个有一些调优。可以参考kafka Hardware and OS。
Consumer Throughput
OK,现在让我们把注意力转移到消费者吞吐量上来。
请注意,复制因子不会影响此测试的结果。因为不管复制因子如何,消费者只能从一个副本读取。 同样,生产者的确认级别(acks参数)也无关紧要,因为消费者只读取完全确认的消息(所有In-Sync Replicas都已经同步的消息才能被消费)。 这是为了确保消费者看到的任何消息在leader切换后始终存在(如果当前leader发生异常需要重新选举新的leader的话)。
Single Consumer
-
940,521 records/sec
-
89.7 MB/sec
第一次测试:将在有6个分区,3个副本的topic中单线程消费5千万条消息。
kafka消费者效率很高,它直接从linux文件系统中抓取日志块。它通过sendfile这个API,直接通过操作系统传输数据,所以没有通过应用程序复制此数据的开销。
本次测试实际上从日志初始位置开始,因此它在做真正的读I/O。但是在生产环境中,消费者几乎完全从OS页面缓存中读取,因为它正在读取刚刚由某个生产者产生的数据(这些数据仍然在缓存中)。事实上,如果您在生产服务器上运行相关命令查看I/O stat,会看到消耗大量数据被消费,也根本没有物理读取。
让消费者尽可能cheap,是我们希望kafka做的一件非常重要的事情。首先,副本也是消费者。所以,让消费者cheap,副本也会cheap。其次,这样会是处理数据不是非常昂贵的操作。因此出于可伸缩性的原因,我们不需要严格控制。
cheap字面含义是便宜,但是在这里的含义,我觉得是业务逻辑不要太复杂。
Three Consumers
-
2,615,968 records/sec
-
249.5 MB/sec
重复上面相同的测试,不同的是有三个消费者并行处理。三个消费者分布在三台不同服务器上。这三个消费者属于同一个消费者组中的成员,即它们消费同样的topic。
和我们预期一样,我们看到消费能力线性扩展,几乎就是单个消费者吞吐量的3倍,这一点都不令人惊讶。
Producer and Consumer
-
795,064 records/sec
-
75.8 MB/sec
上面的测试仅限于生产者和消费者运行在不同服务器。现在,让我们把生产者和消费者运行在同一台服务器上。实际上,我们也是这样做的,因为这样的话,复制工作就是让服务器本身充当消费者。
对于此次测试,我们将基于6个分区,3个副本的topic,分别运行1个生产者和1个消费者,并且topic初始为空。 生产者再次使用异步复制。 报告的吞吐量是消费者吞吐量(显然,是生产者吞吐量的上限)。
和我们预期一样,得到的结果和只有生产者时基本相同,前提是消费者相当cheap。
Effect of Message Size
前面的测试已经展示了100字节大小消息kafka的性能。对于消费系统来说,更小的消息是更大的问题。因为它们放大了系统记账的开销。 我们可以通过在记录/秒和MB/秒两者中绘制吞吐量来显示这一点:

04-size_vs_record_throughput.png
这张图和我们预期一样,随着消息体越来越大,每秒我们能发送的消息数量也会减少。但是,如果我们看MB/秒性能报告,我们会看到实际用户数据的总字节吞吐量随着消息变大而增加:
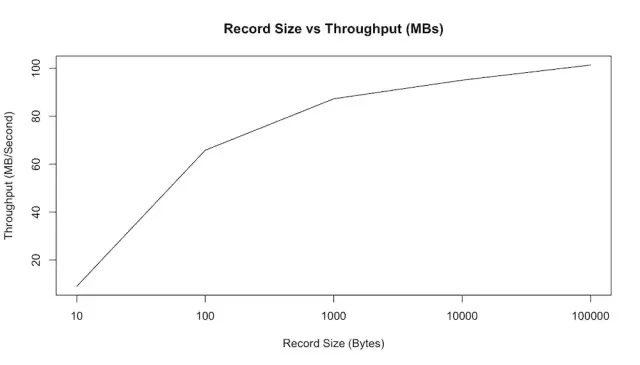
05-size_vs_mb_throughput.png
总结:消息体越大,每秒能处理的消息数量越少,但是每秒能处理的消息体积越大;消息体越小,每秒能处理的消息数量越多,但是每秒能处理的消息体积越小;
另外我们可以看到,对于10字节的消息,我们实际上只是通过获取锁并将消息排入发送来限制CPU - 我们无法实际最大化网络。 但是,从100字节开始,我们实际上看到网络饱和。
End-to-end Latency
-
2 ms (median)
-
3 ms (99th percentile)
-
14 ms (99.9th percentile)
到现在为止,我们讨论的都是吞吐量。但是消息传递的延迟情况呢?也就是说,消息传递到消费者,需要多长的时间。此次测试,我们将创建生产者和消费者,并重复计算生产者将消息发送到kafka集群然后由我们的消费者接收所需的时间。
请注意,Kafka仅在所有in-sync replicas确认消息后才向消费者发出消息。因此,无论我们使用同步还是异步复制,此测试都会给出相同的结果,因为该设置仅影响对生产者的确认,而本次测试是生产者发送的消息传递到消费者的时间。
Replicating this test
如果你想要在你自己的服务器上,运行这些压力测试,当然没有问题。正如我所说的,我大部分情况下只是使用我们预装的性能测试工具,这些工具随Kafka发布包一起提供,并且服务器和客户端大部分都是默认配置。
attachment
下面给出本次压测一些命令,以及kafka服务器配置。
benchmark commands
###############################################################
压测脚本(zk集群地址后的/afei是配置的chroot):
--zookeeper:10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei
--broker: 10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092
################################################################
创建需要的TOPIC:
bin/kafka-topics.sh --zookeeper 10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei --create --topic TPC-P6-R1 --partitions 6 --replication-factor 1
bin/kafka-topics.sh --zookeeper 10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei --create --topic TPC-P6-R3 --partitions 6 --replication-factor 3
1个生产者-单线程&无副本:
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R1 --num-records 50000000 --record-size 128 --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
执行脚本说明:
--num-records表示发送消息的数量,即5kw条;
--record-size表示每条消息的大小,即128字节;
--throughput表示吞吐量限制,-1没有限制;
--producer-props后面的都是生产者配置
1个生产者-单线程&3个副本异步写入:
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records 50000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
1个生产者-单线程&3个副本同步写入:
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records 50000000 --record-size 100 --throughput -1 --producer-props acks=-1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
3个生产者-单线程&3个副本异步写入:
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records 50000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
- 发送50亿条100个字节大小的消息
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records 5000000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
消费尺寸的影响--分别尝试各种不同字节大小消息
for i in 10 100 1000 10000 100000;
do
echo ""
echo $i
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records $((1000*1024*1024/$i)) --record-size $i --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
done;
单个消费者消息能力:
bin/kafka-consumer-perf-test.sh --zookeeper 10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei --messages 50000000 --topic TPC-P6-R3 --threads 1
3个消费者消费能力--在3台服务器上运行3个消费者:
bin/kafka-consumer-perf-test.sh --zookeeper 10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei --messages 50000000 --topic TPC-P6-R3 --threads 1
生产者&消费者:
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic TPC-P6-R3 --num-records 50000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=10.0.0.1:9092,10.0.0.2:9092,10.0.0.3:9092 buffer.memory=67108864 batch.size=8196
bin/kafka-consumer-perf-test.sh --zookeeper 10.0.1.1:2181,10.0.1.2:2181,10.0.1.2:2181/afei --messages 50000000 --topic TPC-P6-R3 --threads 1
server config
broker.id=0
port=9092
num.network.threads=4
num.io.threads=8
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dirs=/grid/a/dfs-data/kafka-logs,/grid/b/dfs-data/kafka-logs,/grid/c/dfs-data/kafka-logs,/grid/d/dfs-data/kafka-logs,/grid/e/dfs-data/kafka-logs,/grid/f/dfs-data/kafka-logs
num.partitions=8
log.retention.hours=168
log.segment.bytes=536870912
log.cleanup.interval.mins=1
zookeeper.connect=10.0.0.1:2181
zookeeper.connection.timeout.ms=1000000
kafka.metrics.polling.interval.secs=5
kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter
kafka.csv.metrics.dir=/tmp/kafka_metrics
kafka.csv.metrics.reporter.enabled=false
replica.lag.max.messages=10000000
在此我向大家推荐一个架构学习交流群。交流学习群号:993070439 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系,还能领取免费的学习资源。