Java-集合知识点整理
集合
概念
集合是存储任意数量的具有共同属性的对象的容器,集合存储的是 Java 对象的内存地址 / 引用,不能直接存储 Java 对象或基本数据类型,集合类与集合接口都在 java.util 包下。
分类

Iterator 迭代器
-
方法
boolean hasNext():如果下一个元素可以迭代,则返回 true
Object next():返回迭代中的下一个元素
void remove():删除迭代器指向的当前对象
-
迭代器和 ConcurrentModificationException 并发修改异常
-
该异常的触发条件是当前集合状态和迭代器快照(原集合状态)不同
-
解决方案:
在遍历集合的过程中使用迭代器的 remove() 方法,不是集合对象的 remove() 方法删除元素
获取迭代器后禁止改变集合结构(禁止对集合进行增删改操作)
集合结构发生改变就必须重新获取迭代器
-
-
remove()
删除的是迭代器指向的当前元素,同时删除迭代器快照和集合中的元素,删除元素时会自动更新迭代器与集合
Collection 接口
常用方法
boolean add(Object obj):向集合中添加元素 obj
boolean remove(Object obj):删除集合中的某个元素 obj,底层调用 equals() 方法进行比对
boolean contain(Object obj):判断集合中是否存在元素 obj,底层调用 equals() 方法进行比对
boolean isEmpty():判空
int size():获取集合中元素个数
void clear():清空
Object[] toArray():把集合转换成数组
Iterator
子接口 List 集合
List 集合存储元素的特点:有序(存储和读取顺序一致)、可重复、有下标
List 集合方法
void add(int index,Object element):指定位置添加元素
Object get(int index):获取指定位置元素
Object remove(int index):删除指定位置元素并返回该元素
Object set(int index,Object element):设置指定位置为某元素,并将原元素返回
int indexOf(Object obj):获取指定对象在集合中第一次出现的索引
int lastIndextOf(Object obj):获取指定对象在集合中最后一次出现的索引
List 集合分类
-
Vector 集合:数组,查询效率高,增删效率低,线程安全(方法都带synchronized)
创建方法:
- new Vector():初始化容量为10,每次扩容为原来的2倍
- new Vector(int initialCapacity):指定初始化容量
- new Vector(int initialCapacity,int capacityIncrement):指定初始化容量和增量
- new Vector(Collection coll):将 Collection 集合转换成 Vector 集合
-
ArrayList 集合:数组,查询效率高,增删效率低,非线程安全
创建方法:
- new ArrayList():初始化容量为10,每次扩容为原来的1.5倍
- new ArrayList(int initialCapacity):指定初始化容量
- new ArrayList(Collection coll):将 Collection 集合转换成 ArrayList 集合
注意:数组扩容涉及到数组拷贝,应该尽可能减少扩容操作,要预估进行合适的初始化容量设置。
-
LinkedList 集合:双向链表,查询效率低,增删效率高,非线程安全
创建方法:
- new LinkedList():创建一个空的集合(没有初始化容量和扩容机制)
- new LinkedList(Collection coll):将 Collection 集合转换成 LinkedList 集合
**注意:**LinkedList 增删效率未必高于 ArrayList (头部、中间、尾部)
List 集合遍历
-
迭代器遍历
Iterator<String> iterator=list.iterator(); while(iterator.hasNext()) System.out.println(iterator.next()); -
for 循环下标遍历
for(int i=0;i<list.length;i++) System.out.println(list[i]); -
for-each 循环遍历
for(String str:list) System.out.println(str);
子接口 Set 集合
Set 集合存储元素的特点:无序(存储和读取顺序不一定相同)、不可重复(元素唯一性)、无下标
Set 集合分类
-
HashSet 集合:哈希表,非线程安全、效率高
创建方法:
- new HashSet():初始化容量为16,每次扩容为原来的2倍,扩容因子为0.75
- new HashSet(int initialCapacity):指定初始化容量
- new HashSet(int initialCapacity,float loadFactor):指定初始化容量和扩容因子
- new HashSet(Collection coll):将 Collection 集合转换成 HashSet 集合
补充:哈希表
哈希表是一维数组和单链表 / 红黑树的结合体(拉链式)
- 当哈希表中的单向链表上的结点 > 8,单向链表转换成红黑树
- 当哈希表中的红黑树上的结点 < 6,红黑树转换成单向链表
- 结合了数组的高效查询和链表的高效增删(都只发生在某一条链表上)
- 哈希碰撞
-
TreeSet 集合:二叉树(中序遍历读取数据),非线程安全、效率高,存储元素自动排序(可排序集合)
创建方法:
- new TreeSet():创建一个空的集合
- new TreeSet(Comparator comp):创建指定比较规则的集合
- new TreeSet(Collection coll):将 Collection 集合转换成 TreeSet 集合
Set 集合遍历
-
迭代器遍历
Iterator<String> iterator=set.iterator(); while(iterator.hasNext()) System.out.println(iterator.next()); -
for-each 遍历
for(String str:set) System.out.println(str);
如何选择创建哪种 Collection 集合?
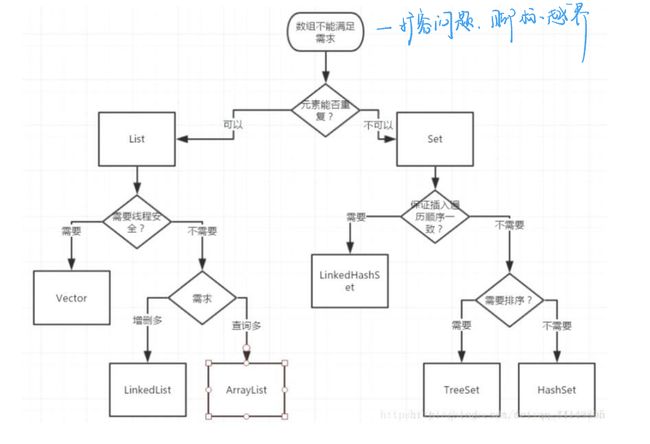
Map 接口
Map 集合以键值对(key-value)的形式存储数据。key 和 value 都是引用数据类型、都是存储对象的内存地址 / 引用,key 起主导作用。
Map 集合存储元素的特点:无序(存储和读取顺序不一定相同)、不可重复(数据元素唯一性)
常用方法
V put(K key,V value):添加键值对
V get(Object key):通过 key 获取 value
V remove(Object key):通过 key 删除键值对
int size():获取键值对数量
void clear():清空
boolean isEmpty():判空
boolean containsKey(Object key):判断是否包含某个 key
boolean containsValue(Object value):判断是否包含某个 value
Set
Collection
Set
Map 集合分类
-
HashMap 集合:哈希表,非线程安全,效率高
创建方法:
- new HashMap():初始容量为16,扩容为原来的2倍,扩容因子为0.75
- new HashMap(int initialCapacity):指定初始容量,必须是2的倍数(保证散列分布均匀、提高存取效率)
- new HashMap(int initialCapacity,float loadFactor):指定初始容量和扩容因子
注意:允许 key 为 null,但是只能存在一个。
-
HashTable 集合:哈希表,线程安全(所有方法带 synchronized),效率低
创建方法:
- new HashTable():初始容量为11,扩容为原来的2倍+1,扩容因子为0.75
- new HashTable(int initialCapacity):指定初始容量
- new HashTable(int initialCapacity,float loadFactor):指定初始容量和扩容因子
**注意:**不允许 key、value 为 null,否则报空指针异常。
-
TreeMap 集合:红黑树
创建方法:
- new TreeMap():创建一个空的集合,无初始化容量和扩容机制
注意:TreeMap 集合的 key 部分按大小自动排序(可排序集合)。
小结
数组 VS 集合
- 数组长度不可变,可以存储基本数据类型和引用数据类型,只能存储同一类型的元素
- 集合长度可变,只能存储引用数据类型,可以存储不同类型的元素
底层数据结构
| 实现类 | 底层数据结构 | 特点 |
|---|---|---|
| Vector | 数组 | 有序,可重复,线程安全 |
| ArrayList | 数组 | 有序,可重复,非线程安全 |
| LinkedList | 双链表 | 有序,可重复,非线程安全 |
| HashSet | 哈希表 | 无序,不可重复,非线程安全 |
| TreeSet | 二叉树 | 无序,不可重复,非线程安全,自动排序 |
| HashMap | 哈希表 | 无序,不可重复,非线程安全 |
| HashTable | 哈希表 | 无序,不可重复,线程安全 |
| TreeMap | 红黑树 | 无序,不可重复,非线程安全,自动排序 |
补充:ConcurrentHashMap
JDK 1.5 中,有了 concurrent 包,ConcurrentHashMap 是线程安全的,但是跟 HashTable 不同,HashTable 是在所有方法上加了 synchronized 实现线程安全,而 ConcurrentHashMap 则是将整个 Map 分为 N 个 Segment (类似 HashTable),因此可以提供相同的线程安全。
泛型机制
本质是参数化类型,即在类、接口、方法的定义上指定元素的数据类型(只能是引用数据类型),作用是在编译阶段(泛型机制只在程序编译阶段起作用)检查元素类型是否匹配,避免程序在运行阶段出现过多错误。
优缺点:
- 同一集合中的元素类型,不需要进行大量的向下转型
- 元素类型缺乏多样性
自定义泛型:
List
List
仅供参考,如有错误,感谢指正!