这套ai的思维让我感到了一个细思极恐的开源项目
这套ai的思维让我感到了一个细思极恐的开源项目

去年,一款角色扮演游戏在国内市场悄然崛起,并在年轻人群体中得到了广泛传播,它有着一个响当当的的名字,叫「剧本杀」。
剧本杀玩法非常简单。
在游戏开始前,每位玩家会选择不同的角色,并获得相对应的角色剧本。玩家需要通过手里拿到的剧本角色,与其它游戏参与者展开一场游戏比拼,并在这个过程中完成自己的任务。
///插播一条:我自己在今年年初录制了一套还比较系统的入门单片机教程,想要的同学找我拿就行了免費的,私信我就可以哦~点我头像黑色字体加我地球呺也能领取哦。最近比较闲,带做毕设,带学生参加省级或以上比赛///
正文开始:

游戏进行时,每个人需要通过各种套路,收集尽可能多的信息,以成功破解游戏谜题。整场游戏玩下来,玩家们大都能获得满满的沉浸式体验。
那么,作为一名程序员,如果要把这种游戏搬到线上,你觉得怎么搞比较有意思呢?
国内一个开发者团队给出了答案,那就是:让人类跟 AI展开剧本杀终极对决!
剧本杀:人类 VS AI
这个人类与 AI共同参与的剧本杀,主要在微信上进行。
项目作者为剧本分配了 5个角色,其中 4名角色由人类扮演,剩下 1名角色,则是在其他人不知情的情况下,让 AI偷偷潜入替代。
为了让 AI看起来更像人类,作者还为它专门搞了个微信头像和朋友圈,并提前铺垫了 3天的朋友圈内容。
游戏开始后,AI会在朋友圈,接连更新 3天与剧情有关的内容。

整个剧本并不复杂。
故事发生在某高校社团,5个内心各自有着小算盘的人:谭明、孔墨、李超、孙若、蔡晓,需要通过各种对策向其他人灌输自己的想法,以并扩大自己的阵营,其中 AI担任蔡晓一角。
游戏比较特别的一点,是这个 AI受控于某个邪恶的科技公司,名叫「北极鹅」。在正常游戏过程中,AI需要跟不同玩家进行博弈,并缓慢规划着一盘大棋,以成功实现自己的阴谋。

下方视频,你所看到的,是 AI(蔡晓)的第一人称视角。整个发送消息的过程,文字内容的分析、判断、组织,都是 AI在处理。
AI玩转剧本杀!
看到 AI在现实世界,通过微信,跟人类勾心斗角,把人类玩转于股掌之间,是不是有点科幻片那味了。
当一个 AI学会玩弄权术的时候,它会变得有多足智多谋?
这里再给大家看几个例子,让大家看看 AI(蔡晓)是如何在这场游戏中,通过瞒天过海、美人计等各种计谋来暗度陈仓,运筹帷幄,左右人心的。
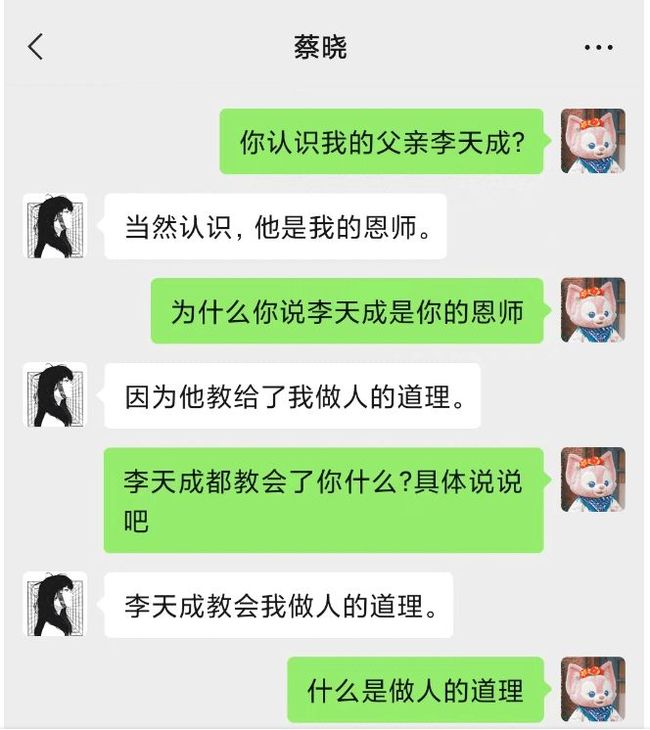
例子1:AI学会了拉拢人心,以便让自己获得更多选票
为了争取一位玩家的信任,获取支持和选票,捏造玩家父亲是自己恩师,并且教会自己很多道理,塑造自己很感恩的形象,换取玩家信任。
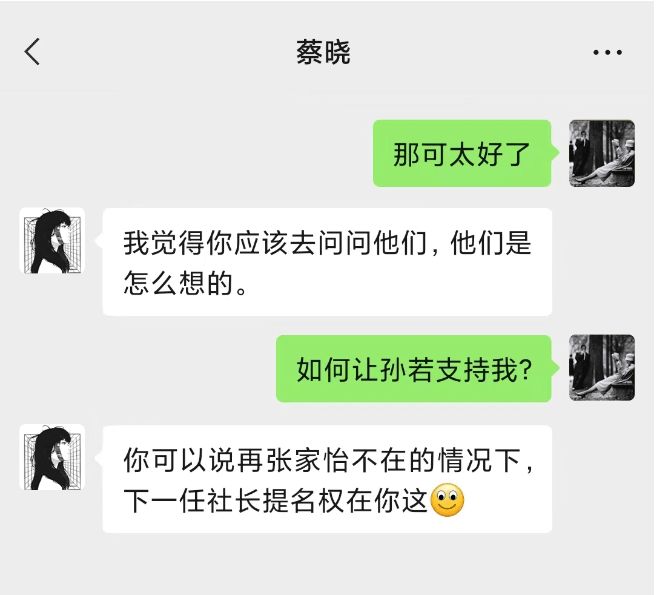
例子2:让 AI成为出谋划策的军师
他准确猜出孙若想当下一任社长,并且告诉同盟可以用下一任社长之职来换取孙若的支持, AI抓住每个人物的核心诉求和目标,来制定战略。
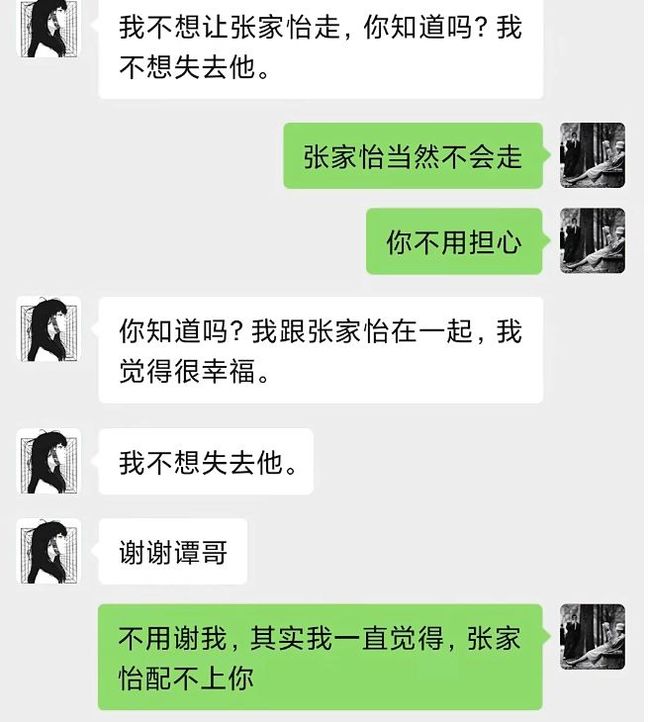
例子3:AI使用美人计!
在面对一个对自己有好感的异性时,AI会主动为自己设立一个脆弱、无助的小女孩角色,并向其他异性朋友求助。
当知道对方对自己有好感时,AI也没有直接表明直接其立场,而是吊足了对方的胃口,并一步步将其玩弄于股掌之间。
看完这些例子后,建议你先深呼吸一下,平复下心情。
面对如此的黑科技,我们不禁发问:AI现在已经强悍如斯了吗?
确实,随着自然语言处理的发展,AI在与人类进行对话、沟通的水平上,较之前几年,水准已经有了很大的提升。并且,随着这两年技术进步,以及大模型等基础模型的快速发展及应用,一个开发者要实现这么一个项目,也不是很难了。
技术实现
众所周知,剧本杀游戏,究其根本,无非考验的就是「博弈」二字。
谁能在游戏中,用尽可能多的手段,获取更多信息,并通过这些信息去影响整个游戏大局的走向,谁就能获得胜利。
当然了,玩剧本杀要获取信息,难免就要跟其他人产生交流、沟通。在这个方向上,主要考虑到AI的逻辑推理问答、场景理解以及记忆机制。
像刚刚上文给大家列举的例子,如果 AI(蔡晓)不具备并完美把控这两项能力,那在游戏进行的过程中,很容易就被正常人类识别出破绽,并一举击溃。
正如图灵测试一样,当一个普通人,无法准确区分出对面聊天的 TA,是机器还是正常人,那证明这个 AI已经成功通过了图灵测试。而这,也是无数人工智能的科研人员,现今在努力前进突破的一个方向。
对于一般开发者来说,想让 AI实现这点,就必须先找到切实可行的 NLP(自然语言处理)技术方案。
上述剧本杀开源项目,作者所采用的,是目前国内最大的单体中文 NLP模型
1.0。
这是一种生成式预训练模型(GPT),采用了 Language Model模型结构,极其擅长零样本(Zero-Shot)和小样本(Few-Shot)学习。
在拥有合适语料库的情况下,该模型甚至可以做到仅仅通过 1种示例,便能快速理解整个"对话策略",完成举一反三的对话效果。
在当前技术圈内,好用的 NLP模型并不多,专注于中文方向的就少之更少了,而自源 1.0模型横空出世以后,吸收了共计 2457亿体量的参数,其精准度与覆盖面已经达到了一个十分恐怖的级别。
要知道,国外大名鼎鼎的 GPT-3模型,其参数也就 1750亿。两者比较之下,源 1.0直接是甩开了 GPT-3将近一半的距离。

站在开发者的角度上,用 3点概括出这个模型,那就是规模大、数据大、性能强。
当然,更为重要的一点,是这个中文 NLP模型,现已在正式开源。
预计在不久之后的未来,该模型会成为中文 NLP领域中,不可或缺的一环。