放飞自我-scrapy框架进阶无限制爬取数据(6300字详解)
文章适合于所有的相关人士进行学习
各位看官看完了之后不要立刻转身呀
期待三连关注小小博主加收藏
小小博主回关快 会给你意想不到的惊喜呀
文章目录
-
- scrapy怎么做到无限制爬取
-
-
- ⚠️爬取过程可能会遇到的问题
- 解决问题
-
- 下载器中间键介绍
-
- process_request(self,request,spider)
- process_response(self,request,response,spider)
- 代理介绍
-
- 实战-实践是检验真理的唯一标准
-
-
- 网站分析
- 爬取内容
-
- css介绍
- 代码
-
- liepin的demo
- 中间件
- models的demo
-
scrapy怎么做到无限制爬取
⚠️爬取过程可能会遇到的问题
在我们爬虫的过程当中,很有可能会遇到由于你爬的太快了,导致被网站识别出来你在做爬虫。然后就不允许让你继续爬取了。或者是你这个ip地址访问目标网址次数太多,导致的被网站直接封禁。比如会出现give up url。。。这种错误,那么我们如果遇到这种问题怎么解决的呢,这就是我们所说的网站限制问题。
就比如这种,洗澡的时候就会给你脱发警告!!!

解决问题
遇到问题我们就解决问题,上有政策,下有对策呗。兵来将挡水来土掩。这里我们就要介绍一下下载器中间件。
下载器中间键介绍
下载器中间件是引擎和下载器之间通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法。一个是process_request(self,request,spider),这个方法是在请求发送之前会执行,还有一个process_response(self,request,response,spider),这个方法是数据下载到引擎之前执行。
总而言之吧,我们可以在下载器中间件中设置代理、更换请求头。从而达到避免被网站发现的目的。
process_request(self,request,spider)
这个方法是下载器在发送请求之前会执行的。一般可以在这个里面设置随机代理ip等。
参数: request:发送请求的request对象。
spider:发送请求的spider对象。
返回值:
返回None:如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用。
返回Response对象:Scrapy将不会调用任何其他的process_request方法,将直接返回这个response对象。已经激活的中间件的process_response()方法则会在每个response返回时被调用。
返回Request对象:不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据。
如果这个方法中抛出了异常,则会调用process_exception方法。
process_response(self,request,response,spider)
这个是下载器下载的数据到引擎中间会执行的方法。
参数: request:request对象。 response:被处理的response对象。
spider:spider对象。
返回值:
返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫。
返回Request对象:下载器链被切断,返回的request会重新被下载器调度下载。
如果抛出一个异常,那么调用request的errback方法,如果没有指定这个方法,那么会抛出一个异常。
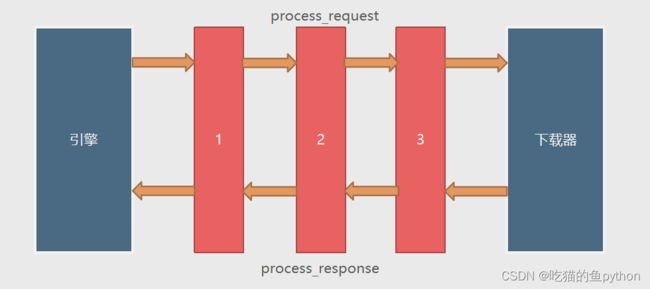
上方返回值具体参照图解来看。
代理介绍
之前我们做IP更换的时候,一般都是用快代理或者其他代理软件的免费代理,来去做。那么这样就会有什么样的缺点呢,就是不够稳定,而且可能发现的差错也较多。那么我们可以去购买一些代理来满足自己的爬虫需求。我自己用的就是芝麻代理。在其中的获取api就可以看到这样一个界面:
然后我们只要按照自己的需求来获取ip就ok了。我们这里选择上方图中的然后生成链接就ok了。就获取到了自己的独享ip。
然后我们进入目标网站liepin网,搜索python然后准备爬取相关信息。
实战-实践是检验真理的唯一标准
网站分析
我们还是通过rule规则来查找页面,首先我们定义详情url规则。
按照之前的方式检查就看到了。
要是之前遇到这种肯定是要骂街了,这是什么呀?

但是经过一段时间的学习我们发现这也是非常简单,我们简单分析一下,前面的内容一致,www…,然后就是一串数字,然后就是以.shtml,然后跟着一大串字母,那就简单多了一串数字我们对应\d+,一大串乱七八糟字母就对应.*。完美解决!!!
然后就是翻页的操作,当我们检查翻页的时候,发现了一点就是tm的网吧蛋,竟然是这种拼接型。
![]()
在源码中搜索page也找不到相关内容,到了这一刻我是崩溃的,但是妈妈告诉我,什么事都不要轻言放弃,于是我想了想,我直接手动翻页不好吗,不按照rule规则。
for i in range(1,50):
next_url=connect_url % i
request = scrapy.Request(next_url)
yield request
解决!
但是这里有一个小细节就是什么呢?就是我们在爬取的过程中有的时候为了避免爬虫乱爬,我们在rule规则中添加参数。
restrict收紧;约束。就是说把它约束在一个范围内,只能在这个范围进行爬取。
restrict_xpaths=["//div[@class='left-list-box']//a"]
爬取内容
爬取内容呢,我们想爬取标题,工资,介绍。。。。。这里不多介绍。爬取规则我们使用css。
css介绍
css就是和xpath一样的功能,我们这节课就用css。
我们以标题为例
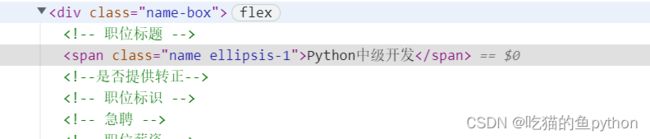
这里我们可以看到属于div class=name-box下的span中的内容。
css
.name-box span::text
class为name-box的标签 下面的span标签中的text。完事!!
代码
其中settings、items、pipelines、这里就不过多介绍了
liepin的demo
import scrapy
from scrapy.spiders.crawl import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
from ..items import LpwItem
class LiepinSpider(CrawlSpider):
name = 'liepin'
allowed_domains = ['www.lin.com']#具体自己去添加
start_urls = ['https://wn.com/zhaopin/?key=python¤tPage=0']#具体自己去添加
rules = (
Rule(LinkExtractor(allow=r'https://www..com/job/\d+\.shtml.*',restrict_xpaths=["//div[@class='left-list-box']//a"]),callback='parse_job',follow=False)
)
def parse_job(self, response):
title=response.css(".name-box span::text").get()
salary=response.css(".name-box span::text").getall()[2]
years=response.css(".job-properties span::text").getall()[1]
edu=response.css(".job-properties span::text").getall()[2]
desc_list=response.css(".paragraph dd::text").get()
desc="".join(desc_list).strip()
item=LpwItem(title=title,salary=salary,years=years,edu=edu,desc=desc)
yield item
connect_url = "https://www.l.com/zhaopin/?key=python¤tPage=%s"
for i in range(1,50):
next_url=connect_url % i
request = scrapy.Request(next_url)
yield request
这里大家可以对照网页中的信息去试一下如何使用css去爬取数据。
中间件
import requests
from .models import ProxyModel
import threading
import time
class IPDownloaderMiddleware:
def __init__(self):
super(IPDownloaderMiddleware, self).__init__()
self.current_proxy=None#目前没有代理
self.update_proxy_url='http://webapi.acangku.com/getip?num=1&type=2&pro=&city=0&yys=0&port=11&time=1&ts=1&ys=0&cs=0&lb=1&sb=0&pb=45&mr=1®ions='
#这里是我们从芝麻网站中提取到的ip
self.headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'
}#请求头
self.update_proxy()#这个函数看下方,获取到了代理
self.lock = threading.Lock()#设置锁
# 创建一个多线程:专门用来管理代理的
# 管理方式:只要这个代理的时间超过了1分钟,或者是这个代理被拉黑了,那么在多线程中就要更换代理了
th = threading.Thread(target=self.update_proxy_in_thread)
th.start()
def process_request(self, request, spider):
#更换代理,是在请求之前更换,也就是在这个函数进行更换
request.meta['proxy'] = self.current_proxy.proxy_url
def process_response(self, request, response, spider):
#在响应中,通过判断状态码,来判断是否需要更新ip
if response.status != 200:
# 标记某个标记位,要更新代理了
self.lock.acquire()
self.current_proxy.is_blacked = True
self.lock.release()
# 如果这个请求没有被正确的响应到,那么应该重新返回,等待下一次重新请求获取
return request#重新请求更换代理啦
# 如果是正常的响应,那么一定要记得返回response,否则在爬虫中获取不到
return response
def update_proxy(self):
resp = requests.get(self.update_proxy_url, headers=self.headers)#请求代理网站
proxy_model = ProxyModel(resp.json())
self.current_proxy = proxy_model
print("更新了新的代理:%s"%self.current_proxy.proxy_url)#提取到具体的ip地址,函数如下方models 这里我们就是提取到了标准格式
def update_proxy_in_thread(self):
# 管理方式:只要这个代理的时间超过了1分钟,或者是这个代理被拉黑了,那么在多线程中就要更换代理了
count = 0
while True:
time.sleep(10)
if count >= 6 or self.current_proxy.is_blacked:
self.update_proxy()
count = 0
else:
count += 1
print("count+1=%d"%count)
models的demo
class ProxyModel(object):
def __init__(self,proxy_dict):
proxy=proxy_dict['data'][0]#提取到ip的地址端口号和过期时间
self.proxy_url="https://"+proxy['ip']+':'+str(proxy['port'])#进行拼接
expire_time_str=proxy['expire_time']
self.expire_time=datetime.datetime.strptime(expire_time_str,'%Y-%m-%d %H:%M:%S')#过期时间的转化
self.is_blacked = False#定义目前没有过期
@property
def is_expiring(self):#判断ip是否过期
now=datetime.datetime.now()
if (self.expire_time-now)<=timedelta(seconds=5):
return True
else:
return False
这里就完成了IP的更换(满足一定的条件下)
好啦!今天我们就结束了!
