《CROSS-DOMAIN FEW-SHOT CLASSIFICATION VIA LEARNED FEATURE-WISE TRANSFORMATION》论文总结
这篇文章基于小样本分类,在度量方法的基础上做出了一些改进
论文下载:https://arxiv.org/abs/2001.08735
论文代码:https://github.com/hytseng0509/CrossDomainFewShot
介绍:基于度量的方法
要素:特征编码器和度量函数
基于度量的方法过程:给定一个输入任务,该任务由来自新类的少量标记图像(支持集)和未标记图像(查询集)组成,编码器首先提取图像特征。然后,该度量函数将标记图像和未标记图像的特征作为输入,并预测查询图像的类别。
1、提出问题
本文依旧对少样本的分类泛化性能进行了讨论,我们的主要观察结果是,从不同域的任务中提取的图像特征分布存在显著差异。因此,在训练阶段,度量函数可能会过度拟合仅从可见域编码的特征分布,而不能推广到未可见域。指出现有的metric-based few-shot classification算法在unseen domains上不能表现出很好的泛化性。
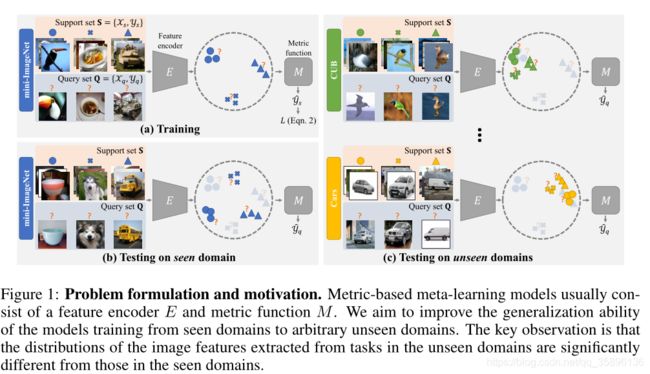
我所认为的图像特征分布存在显著差异可以表现为:在mini-ImageNet上不同种类的图像分布较为分散,而和mini-ImageNet不同域的数据集CUB和Cars,作为未看见领域,它们的分布却较为集中。
2.改进办法
将feature-wise transformation layers(特征变换层) 插入到Feature Encoder 的BN层之后,将特征转换层集成到特征编码器中。
核心思想是在训练阶段使用基于特征的变换层通过仿射变换来增强图像特征,以模拟不同域下的各种特征分布,从而提高测试阶段度量函数的泛化能力。
然而,基于特征的变换层的超参数可能需要细致的手工调整,因为很难建模图像特征分布在不同领域的复杂变化。基于此,我们开发了一个learning-to-learn算法来优化所提出的特征转换层。主要目的是优化功能上的转换层,以便在使用所看到的领域训练模型之后,模型可以在未看到的领域上工作。
因此,只要能够学习到特征变换层的参数,增强图像的特征表现能力,使我们能够在训练阶段模拟图像特征的各种分布,从而提高测试阶段度量函数的泛化能力。就显得尤为重要。
3、优化参数算法过程:

与特征变换层集成的特征编码器E可以产生更多种特征分布,从而提高度量函数M的泛化能力。如上右半图所示,在批量归一化之后插入特征变换层。 超参数θγ∈RC×1×1和θβ∈RC×1×1表示用于采样仿射变换参数的高斯分布的标准偏差。
给定特征编码器中尺寸为C×H×W的中间特征激活图z,首先从高斯分布中采样缩放项γ和偏置项β:
γ ∼ N ( 1 , s o f t p l u s ( θ γ ) ) β ∼ N ( 0 , s o f t p l u s ( θ β ) ) . γ ∼ N(1, softplus(θ _γ )) β ∼ N(0, softplus(θ _β )). γ∼N(1,softplus(θγ))β∼N(0,softplus(θβ)).
之后计算:
z ^ c , h , w = γ c × z ^ c , h , w + β c \hat{z}_{c,h,w} = γ _c × \hat{z}_{ c,h,w} + β_c z^c,h,w=γc×z^c,h,w+βc
更新超参数算法为:

主要有两次迭代更新,第一次更新利用已知域数据对度量模型参数的更新,也既是特征编码器和模型函数的参数 θ e \theta_e θe和 θ m \theta_m θm
第二次更新是利用未知域对变换层参数的更新,也既是 θ f \theta_f θf