CVPR 2021 | Few-shot Image Generation via Cross-domain Correspondence 阅读笔记 & 部分翻译
Few-shot Image Generation via Cross-domain Correspondence
Author Unit: Adobe Research, UC Berkeley, UC Davis
Authors: Utkarsh Ojha 1 , 2 ^{1,2} 1,2 Yijun Li 1 ^1 1 Jingwan Lu 1 ^1 1 Alexei A. Efros 1 , 3 ^{1,3} 1,3 Yong Jae Lee 2 ^2 2 Eli Shechtman 1 ^1 1 Richard Zhang 1 ^1 1
Code: https://github.com/utkarshojha/few-shot-gan-adaptation
Conference: CVPR 2021
Paper address: https://openaccess.thecvf.com/content/CVPR2021/html/Ojha_Few-Shot_Image_Generation_via_Cross-Domain_Correspondence_CVPR_2021_paper.html
Notion 版的笔记

Abstract
我们提出通过一种新的跨域距离一致性损失(cross-domain distance consistency loss)来 维持源中实例之间的相对相似性和差异性。为了进一步减少过拟合,我们提出了一种基于锚(anchor-based)的策略,以鼓励在潜空间中不同区域的不同层次的 realism。通过在 photorealistic 和 non-photorealistic 领域的广泛结果,我们定性和定量地证明了我们的 few-shot 模型自动发现了源和目标领域之间的对应关系,并产生比以前的方法更多样化和逼真的图像。
1. Introduction
我们探索了从源域中迁移另一种信息的方式来解决少样本的数据,这种信息为 how images relate to each other。直观上来说,如果模型在源域中可以维持实例间的相对相似性和差异性,则在适应新域的时候也有机会去继承这个多样性。
在两个域之间执行这种结构级 structure-level 对齐时,会出现一些有趣的属性。具体来说,当源域和目标域相关时(如人脸和漫画),我们的方法自动发现它们之间一对一的对应关系,能够更真实地模拟目标分布的多样性和图像的真实性,如图1所示。当这两个领域不相关时(例如,汽车和漫画),我们的方法无法建模目标分布,但仍然发现有趣的部分级 part-level 对应,以生成不同的样本。
由于少量的训练样本只形成了需要近似目标分布的一个小子集,我们发现有必要以两种不同的方式加强 realism,以不过分地惩罚生成的图像之间的多样性。 我们在一张合成的图像上应用一个图像级 image-level 的对抗损失,它应该映射到一个真实的样本。对于所有其他合成图像,我们只实施一个补丁级 patch-level 的对抗损失。这样,我们生成的样本中只有一小部分需要看起来像少量训练图像中的一个,而其余的只需要捕获它们的 patch-level 纹理。
2. Related work
Few-shot learning.
Domain translation.
Distance preservation. 为了缓解 gan 中的模式崩塌,DistanceGAN[2] 建议在相应生成的输出对中保留输入对之间的距离。类似的方案被用于无条件[25,17]和有条件[18,33]的生成任务,以增加生成的多样性。

3. Approach
We are given a source generator G s G_s Gs, trained on a large source dataset D s \mathcal{D}_s Ds, which maps noise vectors z ∼ p z ( z ) ⊂ Z z∼ p_z (z)⊂ \mathcal{Z} z∼pz(z)⊂Z , drawn from a simple distribution in a low-dimensional space, into images x x x. We aim to learn an adapted generator G s → t G_{s\to t} Gs→t by initializing the weights to the source generator and fitting it to a small target dataset D t \mathcal{D}_t Dt. discriminator D.
L adv ( G , D ) = D ( G ( z ) ) − D ( x ) G s → t ∗ = E z ∼ p z ( z ) , x ∼ D t arg min G max D L adv ( G , D ) . ( 1 ) \begin{gathered} \mathcal{L}_{\text {adv }}(G, D)=D(G(z))-D(x) \\ {G_{s \rightarrow t}^{*}=\mathbb{E}_{z \sim p_{z}(z), x \sim \mathcal{D}_{t}}} \arg \min _{G} \max _{D} \mathcal{L}_{\text {adv }}(G, D) . \end{gathered} (1) Ladv (G,D)=D(G(z))−D(x)Gs→t∗=Ez∼pz(z),x∼DtargGminDmaxLadv (G,D).(1)
之前的工作 [32] 表明,当目标数据集大小超过 1000 个训练样本时,这很有效。 然而,在极少样本设置中,这种方法会过拟合,因为鉴别器可以记住少数样本并强制生成器重现它们。 这如图 2 所示,在将源模型(顶行)调整到少样本目标数据集(中行)后,我们看到崩溃。
为了防止过度拟合以生成多样化和逼真的图像(图 2,底行),我们提出了一种新的跨域一致性损失(第 3.1 节),它积极使用原始源生成器来规范 tuning process,以及一个“宽松 relaxed”的鉴别器 (第 3.2 节),这鼓励了潜空间中不同区域的不同程度的 realsim。 我们的方法如图 3 所示。

3.1. Cross-domain distance consistency
在适应过程中,过拟合的一种原因是源域的相对距离没有得到保留,如 图2。
为此,我们对一批 N+1 个噪声向量 { z n } 0 N \{z_n\}^N_0 {zn}0N 进行采样,并使用它们在特征空间中的成对 pairwise 相似性为每个图像构建 N 路 N-way 概率分布。这在图 3 中从 z 0 z_0 z0 的视角进行了说明。对于源生成器和自适应生成器,第 i 个噪声向量的概率分布由下式给出,
y i s , l = Softmax ( { sim ( G s l ( z i ) , G s l ( z j ) ) } ∀ i ≠ j ) y i s → t , l = Softmax ( { sim ( G s → t l ( z i ) , G s → t l ( z j ) ) } ∀ i ≠ j ) , ( 2 ) \begin{gathered}y_{i}^{s, l}=\operatorname{Softmax}\left(\left\{\operatorname{sim}\left(G_{s}^{l}\left(z_{i}\right), G_{s}^{l}\left(z_{j}\right)\right)\right\}_{\forall i \neq j}\right) \\y_{i}^{s \rightarrow t, l}=\operatorname{Softmax}\left(\left\{\operatorname{sim}\left(G_{s \rightarrow t}^{l}\left(z_{i}\right), G_{s \rightarrow t}^{l}\left(z_{j}\right)\right)\right\}_{\forall i \neq j}\right),\end{gathered} (2) yis,l=Softmax({sim(Gsl(zi),Gsl(zj))}∀i=j)yis→t,l=Softmax({sim(Gs→tl(zi),Gs→tl(zj))}∀i=j),(2)
其中 sim 表示第 l 层生成器激活之间的余弦相似度。 我们受到对比学习中最近方法的启发 [22, 4, 7],它将相似性转换为无监督表示学习的概率分布,以及感知特征损失 [10, 5, 26],这表明判别网络上多个层的激活有助于保持相似性。 我们鼓励自适应模型,通过在层和图像实例上使用 KL 散度,来具有与源相似的分布:
L d i s t ( G s → t , G s ) = E { z i ∼ p z ( z ) } ∑ l , i D K L ( y i s → t , l ∥ y i s , l ) ( 3 ) \mathcal{L}_{\mathrm{dist}}\left(G_{s \rightarrow t}, G_{s}\right)=\mathbb{E}_{\left\{z_{i} \sim p_{z}(z)\right\}} \sum_{l, i} D_{K L}\left(y_{i}^{s \rightarrow t, l} \| y_{i}^{s, l}\right) (3) Ldist(Gs→t,Gs)=E{zi∼pz(z)}l,i∑DKL(yis→t,l∥yis,l)(3)
这有助于防止崩溃,我们也修改了对抗损失来进一步防止过拟合。
3.2. Relaxed realism with few examples
对于非常少的目标数据,构成“真实”样本的定义变得越来越受限制,因为鉴别器可以简单地记住少样本的目标训练集。我们注意到少数训练图像仅形成所需分布的一个小子集,并将此概念扩展到了潜空间。 我们定义了“锚”区域, Z a n c h ⊂ Z \mathcal{Z}_{anch}⊂ \mathcal{Z} Zanch⊂Z,它形成了整个潜空间的一个子集。 当从这些区域采样时,我们使用完整的图像鉴别器 D i m g D_{img} Dimg。 在它们之外,我们使用补丁级别的鉴别器 D p a t c h D_{patch} Dpatch 来实施对抗性损失,
L adv ′ ( G , D img , D patch ) = E x ∼ D t [ E z ∼ Z anch L adv ( G , D img ) + E z ∼ p z ( z ) L adv ( G , D patch ) ] ( 4 ) \begin{aligned}\mathcal{L}_{\text {adv }}^{\prime}\left(G, D_{\text {img }}, D_{\text {patch }}\right)=\mathbb{E}_{x \sim \mathcal{D}_{t}} &\left[\mathbb{E}_{z \sim Z_{\text {anch }}} \mathcal{L}_{\text {adv }}\left(G, D_{\text {img }}\right)\right.\\&\left.+\mathbb{E}_{z \sim p_{z}(z)} \mathcal{L}_{\text {adv }}\left(G, D_{\text {patch }}\right)\right]\end{aligned} (4) Ladv ′(G,Dimg ,Dpatch )=Ex∼Dt[Ez∼Zanch Ladv (G,Dimg )+Ez∼pz(z)Ladv (G,Dpatch )](4)
为了定义锚空间,我们选择 k 个随机点,对应于训练图像的数量,并保存它们。 我们从这些固定点中采样,并添加了一个小的高斯噪声 ( σ = . 05 ) (σ = .05) (σ=.05)。 我们通过将 D p a t c h D_{patch} Dpatch 定义为更大的 D i m g D_{img} Dimg 网络 [9, 38] 的子集,在两个鉴别器之间使用共享权重; 使用内部激活对应于输入上的 patches。 patch 大小取决于网络架构和层。 我们读取了一组层,有效补丁大小从 22 × 22 到 61 × 61 不等。
3.3. Final Objective
我们的最终目标仅包含这两项:用于目标外观的 L adv \mathcal{L}_{\text {adv }} Ladv ,以及利用源模型来保持结构多样性的 L dist \mathcal{L}_{\text {dist }} Ldist :
KaTeX parse error: No such environment: equation at position 7: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲\begin{gathered…
补丁鉴别器为生成器提供了对图像结构的一些额外自由。 由于跨域一致性损失,自适应生成器被直接激励从源生成器借用域结构。 如图 2 上下两行所示,该模型确实发现了源域和目标域之间的跨域对应关系。
我们使用在大型数据集(例如 FFHQ [12])上预训练的 StyleGANv2 架构 [13] 作为我们的源模型。 我们使用 4 的批量大小。根据经验,我们发现从 1 0 3 10^3 103 到 1 0 4 10^4 104 的高 λ 工作得很好。 其他训练详情可在补充材料中找到。
4. Experiments
Baselines:
Datasets:
4.1. Quality and Diversity Evaluation
Qualitative comparison Figure 4.
Quantitative comparison Table 1, Table 2.


What role do different components of our method play?
4.2. Analyzing source ↔ ↔ ↔ target correspondence
Related source/target domains Figure 4,Figure 6. 当源域和目标域语义相似时,相同的噪声向量在各自域中产生的结果具有明显的对应关系。

Unrelated source/target domains Figure 7. 虽然对应关系很牵强,但仍具有 part-level 的对应关系。
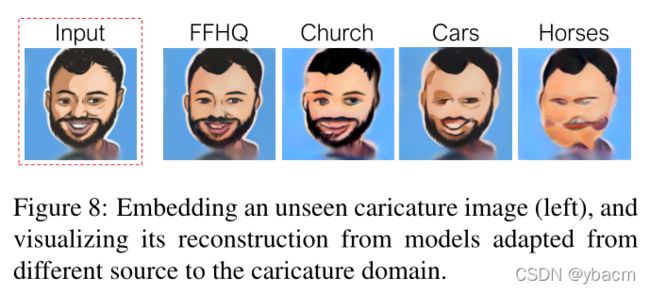
Quantitative analysis of source/target relevance Figure 8,Table 3.

4.3. Effect of target dataset size
Figure 9.
5. Conclusion and Limitations
通过发现 cross-domain correspondences,我们实现了从源域到目标域的自适应 GAN 模型。然而我们的模型也不是没有限制的,例如 图6 中 Cars —> Abandoned cars,红色的车变成了橘色,可能是因为在10张训练图像中存在一辆橙色的车(没有红色的)。FFHQ→ Sunglasses,在这个例子中,一个金发在戴上墨镜后变成了黑色。这表明需要发现源域和目标域之间更好的对应关系,并会有更多样化的生成。尽管如此,我们相信这项工作朝着创建更有效的数据生成模型迈出了重要的一步,证明现有的源模型可以以一种有效的方式利用更少的数据来建模新的分布情况。
个人总结: 作者使用 cross-domain distance consistency 来维持源域中的多样性(使用相同的 latent code 来做损失);使用 D i m g D_{img} Dimg 来对目标训练集中采样的图像做完整的 image-level 损失(通过固定 k 个随机点),使用 D p a t c h D_{patch} Dpatch 来对目标训练集外采样的图像做 patch-level 损失,这样会减少了对应有的多样性的惩罚,还提升了生成图像的真实度。