深度学习课堂笔记
第1章 深度学习简介
1.1 课程简介
本学期课程主要介绍:深度学习数学基础、线性回归、神经网络与BP算法,深度神经网络及其训练,卷积神经网络,循环神经网络,无监督深度学习;深度生成模型,深度学习前沿,深度学习部署。
1.2 人工智能和机器学习概述
人工智能:使一部机器人像人一样进行感知、认知、决策、执行的人工程序或系统。
图灵测试:需要理解语言、学习、记忆、推理、决策等能力。
类人思考方式:人工智能是那些与人的思维、决策、问题求解和学习等活动的自动化(通用问题求解器GPS)
1.2.1 人工智能的三个层面
计算智能(能存能算):快速计算记忆存储(深蓝,暴力穷举)
感知智能(听说看认):视觉听觉触觉感知能力(无人驾驶)
认知智能(理解思考):逻辑推理只是理解决策思考(游戏,alphago)
1.3 神经网络和深度学习概述
机器学习是头,深度学习是脑
1.3.1 一切的开始:感知机Perceptron
1943第一个具有自组织自学习能力的数学模型。
缺点:单层神经网络无法解决线性不可分问题:异或门。致命的问题:当时计算量不够。
1.3.2 传统神经网络
分布式表征和传统局部表征相比
存储效率高:线性增加的神经元数目可以表达指数级增加的概念
鲁棒性好:即使局部硬件故障,信息表达也不会收到根本性破坏
传统感知器用梯度下降算法纠错,耗费计算量和神经元数目的平方成正比。神经元数目增多时,庞大的计算量是当是硬件无法胜任的。但在1986.7,BP算法将纠错运算量下降到了与数目本身成正比。增加隐含层解决了XOR问题,硬件也有了很好的发展。
1.3.3 深度学习发展
97 LSTM如何将有效信息经过多层循环神经网络传递后依旧能输送到需要的地方去。
06 限制玻尔兹曼机RBM,深度置信网络DBN就是将几层RBM叠加在一起。
07 Nvida推出CUDA的GPU软件接口。GPU时钟速度比CPU慢,但是擅长大规模并行处理。
11 修正线性单元,稀疏表征能力。
12 ILSVRC竞赛CNN夺冠
1.4 深度学习应用
目标检测、识别、分类,图像分割,目标跟踪,图像检索,特征识别,人脸识别,行人检测等。
1.5 机器学习的基本概念
分类回归聚类,强化学习监督无监督
学习过程:就是在所有假设组成的空间中进行搜索的过程,最终找到一个函数。
第2章 线性模型
2.1 线性回归
一元线性回归使用均方和误差,利用最小二乘法求解wb两个参数,使均方误差最小化。
多元线性回归使用多元最小二乘法,在XtX可逆时有闭式解。
此外还有对数线性回归和广义线性回归。
2.2 logistic回归
使用sigmoid函数族,利用极大似然估计法进行参数求解。具体看机器学习笔记。
2.3 正则化
正则化的目的在于限制参数范围,从而限制过拟合。
因为过拟合和参数范围是息息相关的,如下图:
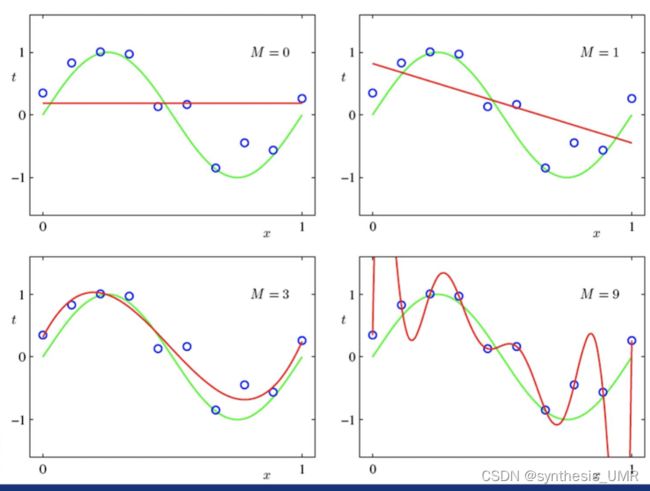
所以如果我在固定参数数量时限制了参数的范围,那就不至于出现这种情况了。
第3章 深度神经网络及训练
本章我们将描述深度学习中的基本过程以及我们可以关注的8个部分,
深度神经网络和训练可以大致分为3步:1、定义网络 2、损失函数 3、优化。
而我们可以关注的部分主要有八点,接下来我们将一一对他们进行简单描述。
3.1 数据预处理
CV领域提出了数据的各种图片问题所导致的训练难点,我们引入数据增广:
通过对图像进行变换or引入噪音的方式来增加数据的多样性。
常见的方法有:旋转,翻转,缩放,平移,加噪音,聚焦等方法。
pytorch里面的train_transfrom函数提供了大量的变换函数供我们使用。
3.1.1 数据归一化
我们可以把一个偏离中心点的簇通过减掉mean移到中心,然后除以他们的标准差使该数据满足方差为1的分布。
一旦我们进行了数据归一化,在进行梯度下降时可以更快地到达最优点。
3.2 网络结构
一般而言有三种经典的网络结构:FCN CNN RNN
3.2.1 全连接神经网络
该网络具有这样的特点:权重矩阵的参数量巨大(所有行列相乘的矩阵),具有某种局部不变性特征(尺度缩放,平移旋转等),这导致全连接神经网络很难提取局部不变特征(每张图都有不同的特征矩阵w,太多了根本处理不了)
3.2.2 卷积神经网络
受到59年生物学提出的上感受野机制而被提出,主要的特征是局部连接,权重共享,拥有平移不变的特点。

使用卷积神经网络,可以让空间中不同位置的特征都提取出相似的特征 ,从而使响应变得简单。
3.2.3 循环神经网络
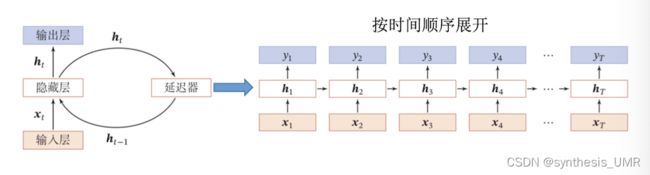
自带自反馈神经元,可以处理人以长度的时序数据
比前馈神经网络更加符合生物神经网络的结构
网络具有自适应记忆能力
3.3 参数初始化
首先参数不可以初始化为0,根据对称权重问题,如果所有层权重都是0,那么输入数据得到的输出结果都一样。更新的梯度也一样,这样没有意义。(如果都是1的话,无法向局部最低收敛也是不行的。)
3.3.1 预训练初始化
利用在其他数据集上预训练的模型权重初始化目标模型
这样模型的收敛速度更快,更有可能得到泛化误差更好的模型,也能很好的改善初始化不当造成的梯度消失或者爆炸问题。
3.3.2 随机初始化
一般有三种,基于固定方差的参数初始化;基于方差缩放的参数初始化;正交初始化。
1、基于固定方差的参数初始化
参数从一个固定均值(通常是0)和固定方差delta^2的分布中采样生成init。
高斯分布初始化
均匀分布初始化 [-r,r] r=sqrt(3*delta^2) (均匀分布的方差推导)
注意如果r取值过小,比如激活函数sigmoid,在一段很小的区间内呈线性,线性模型叠加就没有意思了,非线性能力下降表示能力下降。
r取值过大,参数取值范围大,使得sigmoid函数的输出饱和,老是取到最左和最右的平行位置,导致梯度消失。
2、基于方差缩放的参数初始化
有人认为我们应该根据神经元的性质差异化设计w,如果input连接多,那么每个上面的权重应该小一点儿避免输出过大或过饱和。所以我们尽可能保持每个神经元的输入和输出的方差一致,通过神经元连接数量自适应调整初始化分布的方差。这叫做方差缩放。
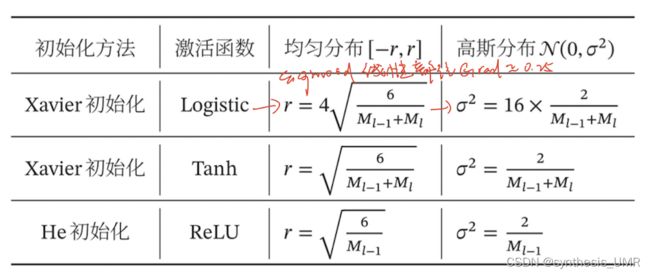
3、正交初始化
主要是基于范数保持性来解决梯度消失或者梯度爆炸问题。
这个数学知识要去补一下
3.4 损失函数
太多了损失函数,一个个看一下把
3.4.1 0-1损失函数
预测值和目标值不相等损失为1,否则为0
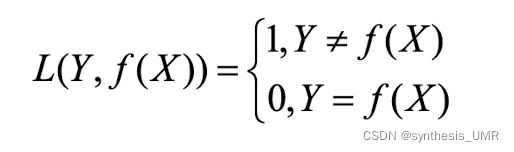
非凸函数不实用,直接判断分类判断错误还是可以的。或者还有以下这种放宽条件的版本:
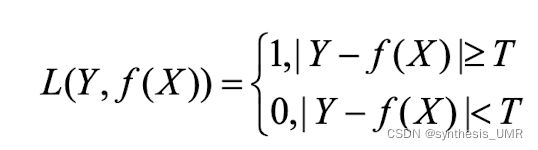
3.4.2 绝对值损失函数
计算预测值和目标值的差的绝对值
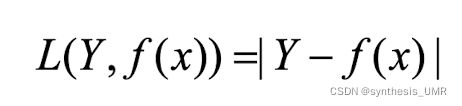
可以用于回归任务,损失函数在训练中大小不稳定,对于底层视觉任务比较有效。
3.4.3 对数损失函数
对数损失函数是对预测得分取对数
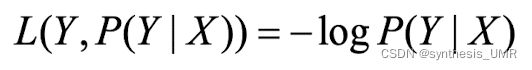
对数损失函数能非常好表现概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度那么他非常合适。
但是鲁棒性不强,对于噪声敏感
(logistic回归用的就是这个对数损失函数)
3.4.4 平方损失函数
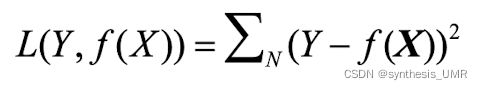
对于一些稀疏问题,用MSE不好做的情况下,平方损失函数非常好用。
回归问题经常用到,鲁棒性不强,对于噪声很敏感。
而且通过最小二乘法处理是有闭式解的。
3.4.5 指数损失函数
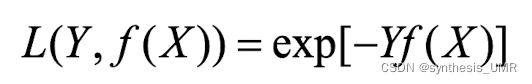
对于离群点,噪声非常敏感,经常用在Adaboost算法
3.4.6 合页损失函数
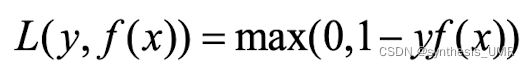
用到再分析
3.4.7 感知损失函数
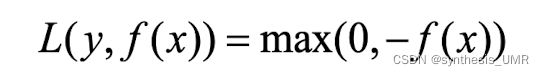
合页损失函数的一个变种
3.4.8 交叉熵损失函数
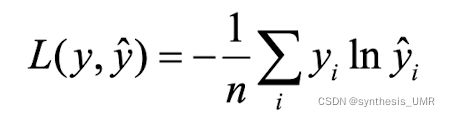
本质上也是一种对数似然函数,可以用于二分类和多分类任务中。二分类问题中损失函数(输入数据是softmax or sigmoid函数的输出)
3.4.9 聚焦损失函数
在交叉熵损失函数的基础上进行修改:
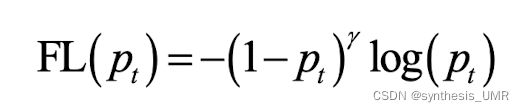
解决目标检测问题中训练集正负样本极度不平衡的问题。且能自适应样本加权,容易分类的样本权重降低,促进分类器更加关注于困难的样本。
3.5 模型优化
机器学习问题最终是转化成了一个最优化问题。所谓神经网络的学习问题,归根结底是高阶非凸优化问题。
对于优化问题有很多的难点:
参数过多,非凸优化问题,梯度消失问题,参数解释困难
梯度消失: 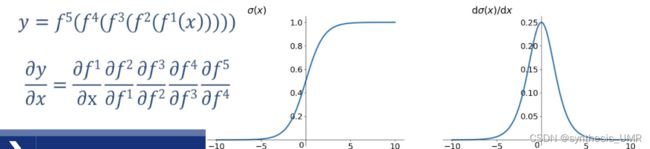
而且对于计算资源要求大,数据要多,算法的收敛要快。
针对这个问题,人类发明了迭代算法来解决问题。下面介绍几种典型的迭代算法:
3.5.1 批次梯度下降
梯度下降的步长也称作:学习率。
批次梯度下降采用整个训练集的样本来进行梯度计算。也是我们在最优化理论里面学的。
因为一次更新中要对整个数据集计算梯度,所以计算起来超级慢,也不能实时更新新数据。对于非凸函数大概率只能收敛到局部极小值。
3.5.2 随机梯度下降
采用训练集中一个样本计算梯度
计算非常快,也能实时更新,噪声比较多所以收敛震荡,准确度也有下降并不一定全局最优。但是这种跳跃性有可能会跳到更好的局部极小值处。
3.5.3 小批次梯度下降
针对前两种梯度下降的缺点改进:每次参数更新,采用训练集中的一个小批次样本来计算梯度。
降低参数更新时方差,收敛更稳定。可以充分利用高度优化的矩阵操作来进行更有效的梯度计算。不能保证很好的收敛性,学习率太小or太大都不利于学习。
但是选择learningrate有困难,因为对于所有的参数更新都要使用同样的learning rate。容易困于鞍点。
3.5.4 Momentum+SGD动量策略梯度下降
下降初期使用上一次参数更新,下降方向一致可以更快;下降中后期在局部最小值来回震荡的时候梯度趋近于0,更新幅度变大,跳出陷阱。
梯度改变方向时u减少更新,抑制震荡,加速收敛。
3.5.5 N下降
先按照动量更新方法走到未来的位置,然后在未来位置计算梯度后更新。
3.5.6 AdaGrad
Ada方法会自适应学习率,根据参数的重要性而对不同的参数进行不同程度的更新。
如果初始学习率较大,那么使用快速梯度下降;如果已经下降很多的变量,减缓学习率;对于还没有怎么下降的变量,保持一个较大的学习率。
训练前期的梯度较小,正则项较大,放大梯度;后期梯度较大,缩小梯度。
优点:
不需要手动设置学习率更新过程
坟墓不断累积,学习率会收缩
超参数n设定值
缺点:
仍然依赖于人工设置的一个全局学习率
n过大的话正则化项会过于敏感,导致梯度的调节太大。
中后期梯度趋近于0使得训练提前结束。
3.5.7 AdaDelta & RMSprop
对于Adagrad的简化
特点:
不依赖全局学习率;训练初期中期加速效果不错,训练后期反复在局部最小值抖动。
3.5.8 Adam自适应动量估计
本质上是带有动量项的RMSprop。
Adam的梯度和动量同时更新,他的适应性是最好的
结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
对于内存的需求小;为不用的参数计算不同的自适应学习率
适用于大多数非凸优化——适用于大数据集和高维空间
3.5.9 优化方法总结
如果数据稀疏,使用自适应方法,Adagrad Adadelta RMSprop Adam
如果需要更快收敛或者训练更深更复杂的神经网络,需要用一种自适应算法
整体来讲Adam是最好的选择。
3.6 超参技巧
神经网络中常见的超参数有:层数,神经元个数,激活函数,学习率,正则化系数,批次大小,迭代次数,动量参数。
在方法的选择上有:网格搜索,随机搜索,贝叶斯优化,动态资源分配,神经架构搜索。
重点关注学习率,正则化系数。
3.6-1 超参数搜索方法
3.6.1 网格搜索
将取值连续的参数离散化然后进行组合
3.6.2 随机搜索
对比网格搜素随机搜索随机进行取值。
3.6.3 贝叶斯优化
用先验点去预测后验知识
通过已构建的函数曲线,找到曲线上升的防线,从而在这个方向上继续探索,大概率可以得到更好的结果。
3.6.4 动态资源分配
可以通过一组超参数的学习曲线来预估这组超参数是否有希望得到比较好的结果。
如果一组超参数配置的学习曲线不收敛或者收敛差,可以应用停止策略终止当前训练。
逐次减半是一种有效的方法。
3.6.5 神经架构搜索
前面几种都是在固定的超参数进行最优配置搜索
NAS通过神经网络来自动实现网络架构的设计。
3.6-2 超参数详解
3.6.6 学习率
学习率可以说是最重要的超参数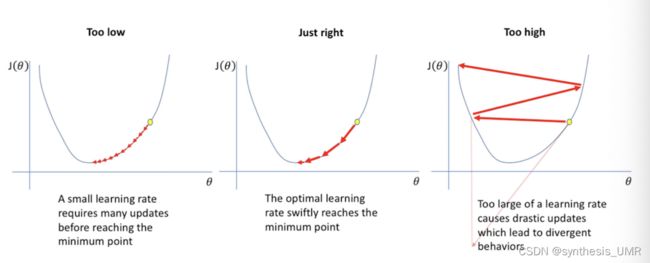
我们希望学习率适应当前的学习状态,自动调整学习率。逆时衰减,指数衰减,自然指数衰减是几种常见的学习率。周期性学习率调整也是一种常用的方法。
3.6.7 正则化系数
正则化系数可以确保模型不发生过拟合
比如说岭回归的正则化系数越大越不容易过拟合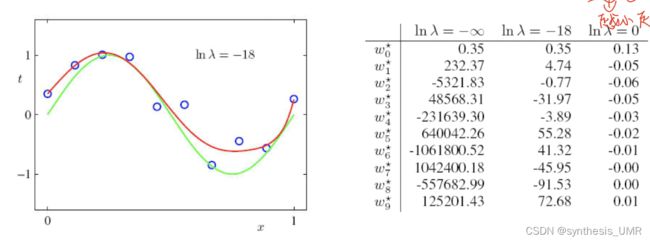
一般我们设置正则项系数为0,先确定好的学习率。然后选择一个正则化系数以后确定他的数量级,接着再进一步微调。
3.6.8 归一化
希望获得更好的尺度不变性,处理内部协变量偏移,更平滑的优化曲面
归一化有很多种方法:批量归一化,层归一化,组归一化,实例归一化
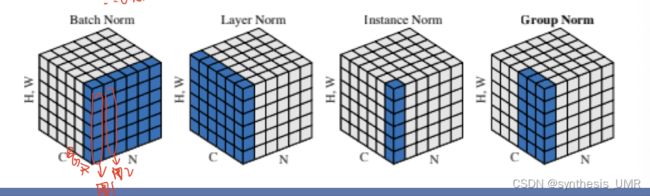
C是通道,HW面每一列都是一个图像,每一个小块是他的第几个像素,一共有N个图像
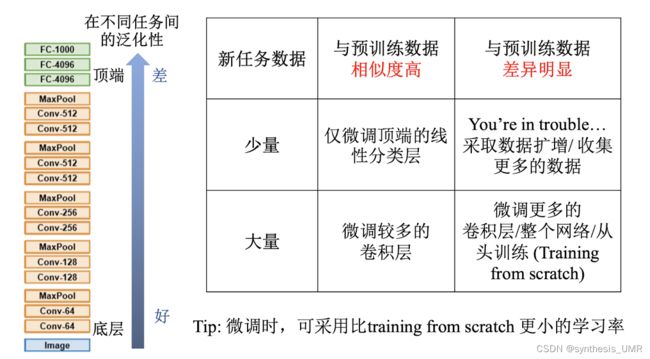
3.7 模型微调
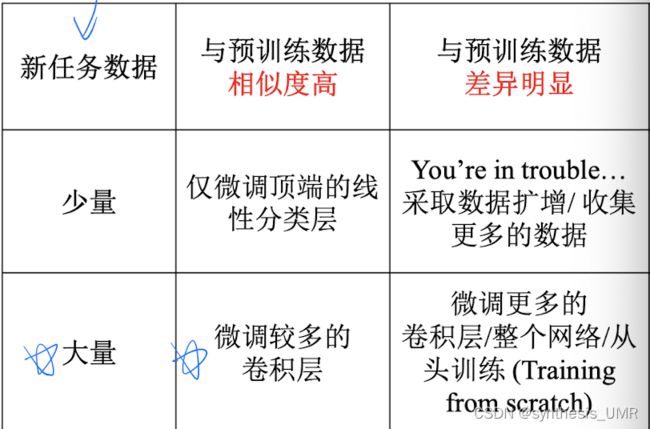
我们为什么要进行模型微调?什么情况下使用微调?
比如我们已经花了3天训练了一个识别动物的网络,然后现在我们想要识别pokemon。我们能不能用识别动物的网络模型作为init直接去训练pokemon呢?这样能缩短训练的时间,节省资源,提高准确率。
3.7.1 预训练模型
与现在相关数据集上训练得到一个模型(ImageNet)
正常情况下不需要改变其他网络结构
3.7.2 模型微调的两种情况
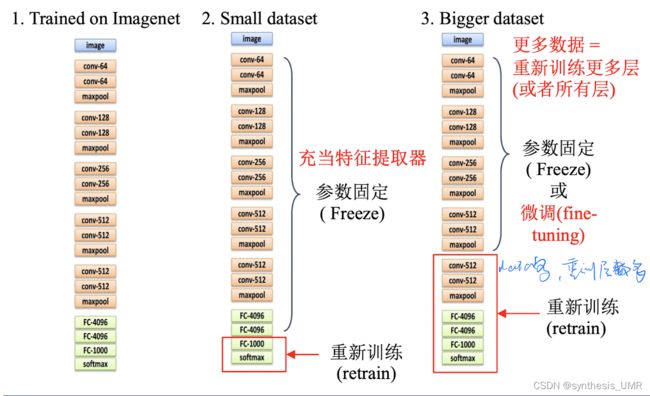
如果迁移问题是一个小数据集的话不需要改变网络内容,只是最后的映射部分需要改变。如果是一个巨大的数据集那么就需要对其中的后几层进行改进了。
卷积神经网络的核心:
浅层卷积层提取基础特征(边缘轮廓)深层卷积层提取抽象特征(整个脸型)全连接层根据特征组合进行分类
3.8 模型泛化
优化本质上是让经验风险最小,但很多情况下我们的经验是片面的不完全的。我们说所有损害优化的方法都是正则化。
我们有两种方法:第一种对优化增加约束(L1L2);第二种干扰优化过程。另外还可以对于数据进行处理。
3.8.1 L1L2正则化
就是加上一个正则化项,要求权重的范数尽可能小。
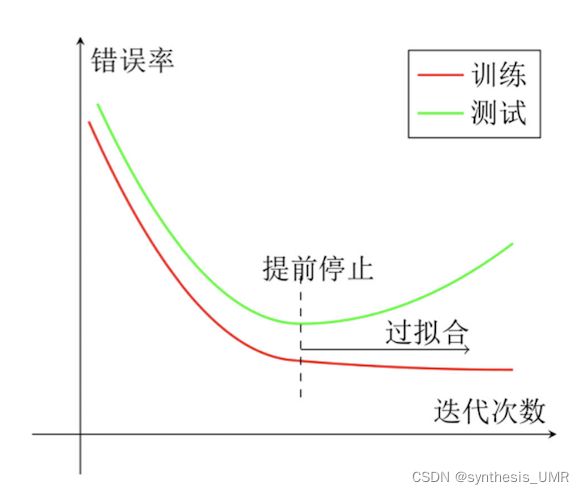
3.8.2 早期终止
训到一半不训了
要观察训练集和测试集的错误率情况
3.8.3 权重衰减
在每次参数更新时引入衰减系数延缓更新。
标准的SGD中,权重衰减正则化和L2正则化是同样的。
Adam中权重衰减正则化和L2正则化不等价。
3.8.4 随机失活
全连接盛景网络每次向前传递随机将激活值置位0,满足伯努利分布。
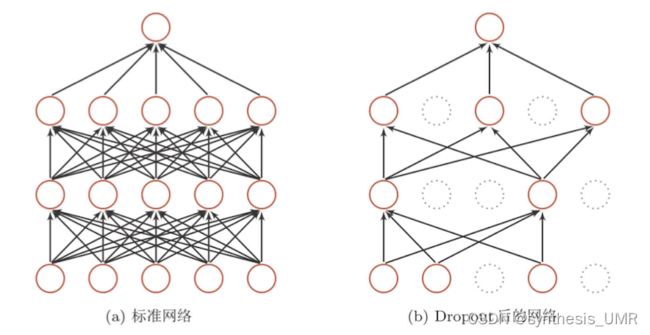
此外还有随机失连和空间随机失活,随机失块,批次随机失块这几种不太常用的方法。
3.8.5 数据增广(标签平滑)
主要对于图片进行变化,引入噪声来增加数据的多样性。这个上面讲过。
但是还有一个:标签平滑
在输出标签中添加噪声避免过拟合。
小结:

第四章 全连接神经网络与BP算法
4.1 多层感知机
首先,单层感知机。由于单个神经细胞只有两种状态:兴奋和抑制,所以可以得到模型:
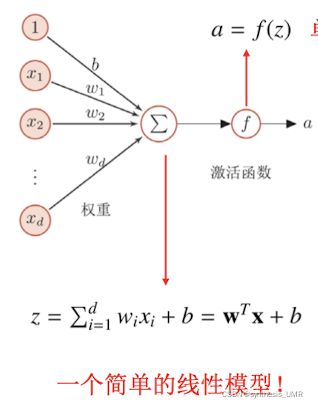
常见的激活函数中sigmoid tanh。sigmoid取值从-1到1,tanh从0到1。但是非零中心化输出会让他后一层的神经元的输入发生bias shift,使得GD的收敛速度变慢
另外还有ReLU LeakyReLU PReLU ELU等
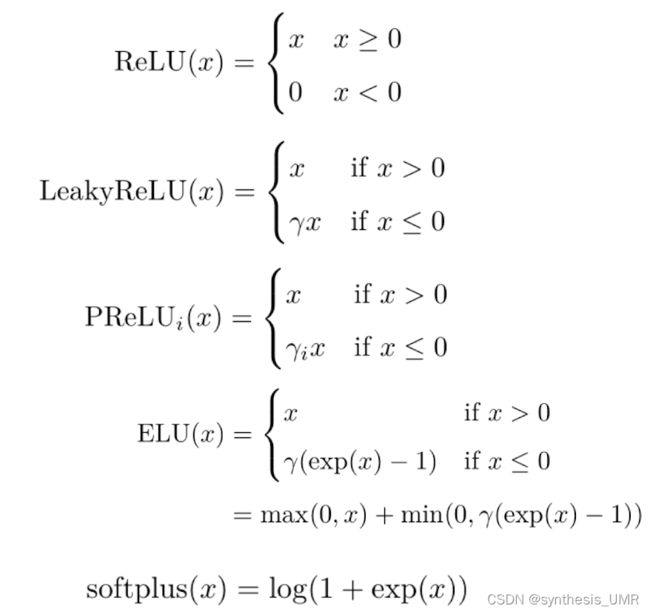
ReLU函数会导致死亡ReLU问题,直接抑制为0损失了大量的信息。所以后来的LeakyReLU等都是对其进行的改进。
这就是单层感知机的两个组成部分:线性层和非线性激活函数。接下来组合成多层感知机。
多层感知机在单层感知机的基础上引入一个到多个隐藏层。之所以叫做隐藏层是因为位于输入和输出层之间。
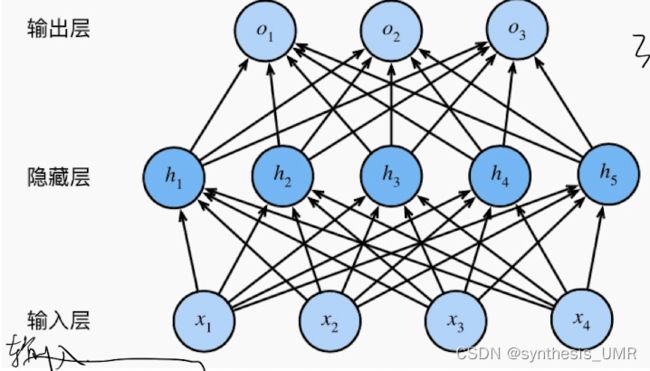
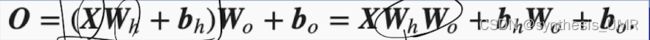
4.2 前馈神经网络
人工神经网络:由许多神经元组成的信息处理网络具有并行分布结构。
前馈神经网络:人工神经网路的一种形式,信息前向传递,逐层编码处理。
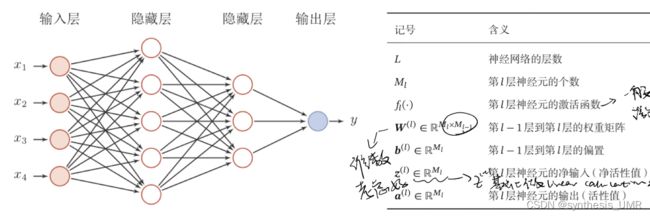
主要特征:
各个神经元分别属于不同的层,层内无连接
相邻两层之间的神经元全部两两连接
整个网络中无反馈,信号从输入层向输出层单向传播,可以用一个有向无环图表示。
计算推导:
第一层
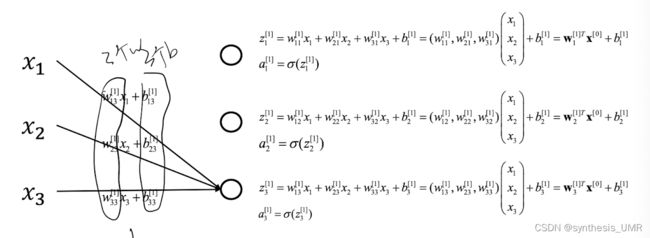
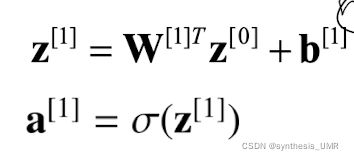
第二层:
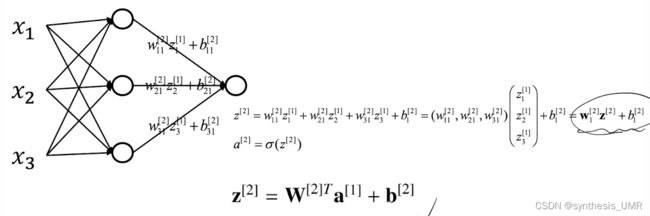
第L层:

加入激活函数:


数学证明:通用近似定理。
“线性与激活的组合只要数量足够,可以以任意精度来近似任何一个从定义在实数空间中的有界闭集函数。”
所以神经网络可以作为一个万能的函数使用。可以用来进行复杂的特征转换,或者逼近一个复杂的条件分布:
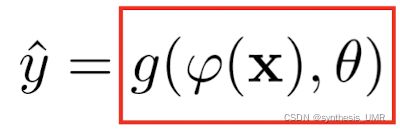
上面这个是个分类器函数。
ok,神经网络的有效性已经得到了证明,下面我们就来看看神经网络的具体应用场景:
分类问题
二分类:使用logistic函数配合对数损失函数
多分类:使用softmax函数配合交叉熵损失函数
关于交叉熵损失函数在机器学习笔记里面有,但这里还要多说几句:
我们说信息熵是衡量信息发生的概率的。相对熵就是KL散度。KL散度是两个概率分布之间差异的非对称性度量,在这里指真实分布和预测分布之间。所谓交叉熵损失函数,就是KL散度加上一个常量(信息熵),公式比KL散度更加容易计算,所以在机器学习中常常使用交叉熵损失函数来计算loss。
4.3 梯度反向传播
参数的更新依赖梯度下降方法:
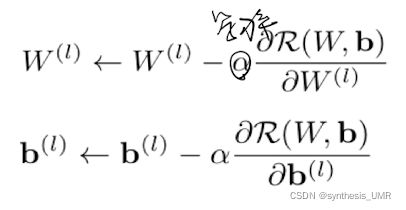
所以我们要学会求偏导才行。
神经网络的本质是复杂的复合函数,求导可以通过链式法则进行求导。
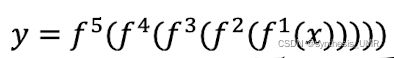
BP算法是根据前馈网络特征而设计的高效算法。更加通用的计算方法有自动微分。
前馈神经网络里面最重要的就是要掌握计算图的构建:
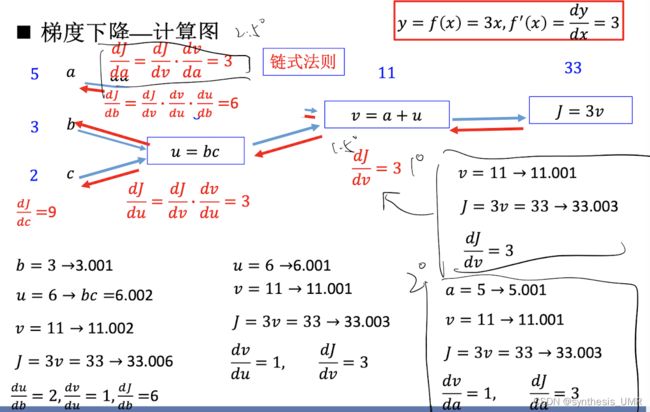
这样其实是可以得到各个参数对于loss的偏导数了,从而就可以进行反向传播。
这个部分单开一章讲好了。
4.4 闭式解
极端学习机ELM
思想:快速学习算法,对于单隐层神经网络,ELM可以随机初始化输入权重和偏重,并利用最小二乘法得到相应的输出权重。无需优化方法迭代。
自编码器AE 详细解释看第七章
思想:一类在半监督学习和无监督学习中使用的人工神经网络。通过输入信息作为学习目标,对输入信息进行表征学习。包括编码器Encoder和解码器Decoder两部分。
按照学习范式,可以分为收缩自编码器,正则自编码器和变分自编码器。前两者是判别模型,后面是生成模型。
按照构建类型,可以是前馈结构或者递归结构。
具有一般意义上表征学习算法的功能,用于降维和异常值检测。
第五章 卷积神经网络
5.1 引言
对于全连接前馈神经网络,权重矩阵的参数过多了。
1000*1000像素的输入图像,假设第一个全连接层有1000个节点,请问该层参数量有多少?
输入层节点:1000*1000=1m 第一层参数量:(1000*1000+1)*1000=1b参数
所以我们认为全连接神经网络的参数量随着图像尺寸增大而激增,对图像处理的延展性差。
而且全连接层忽略了输入数据的局部不变性特征。尺度缩放、平移、旋转等操作不影响语义信息。
所以我们引入卷积层和卷积神经网络。
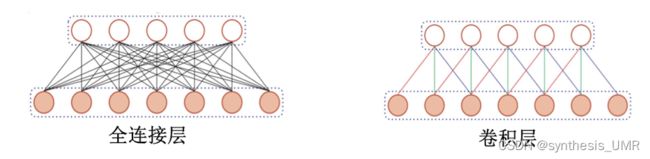
特征:
局部连接:每个神经元只和上一层一小部分神经元连接,所以减少了很多参数。
权值共享:一组连接可以共享同一个权重。
生物学原理:
62年发现感受野,在视觉神经系统中,一个神经元的感受野指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元。
80年Fukushima提出神经感知机 90年Lecun提出使用BP算法训练LeNet 12年ImageNet AlexNet
5.2 基础组件
卷积神经网络三种基础组件:
卷积层、激活层、池化层
CNN就是一种包括卷积计算的前馈神经网络
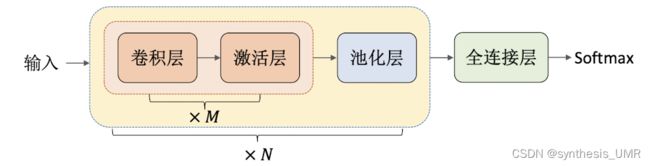
权值共享:不同位置处的神经元共享同一组权重(滤波器)
平移不变性:滤波器可以捕获与图像空间位置无关的区域特征。这点非常好,因为图像中不同位置可能出现相似的图像特征。
5.2.1 卷积层
首先我们来看一维卷积计算
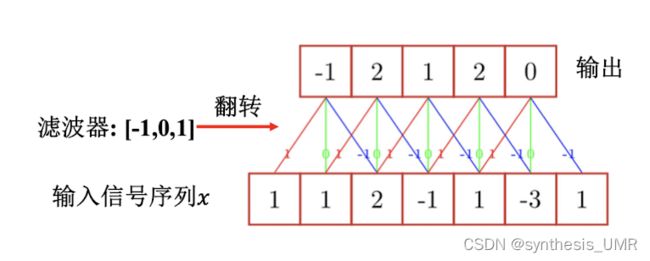
不同的滤波器可以提取信号序列中不同特征:
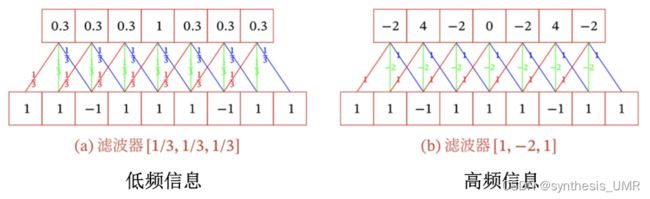
然后来看二维卷积作为特征提取器:
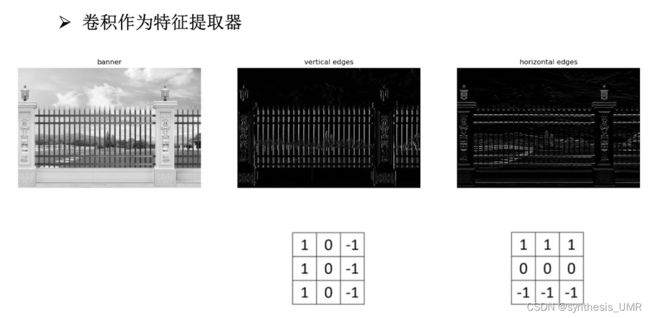
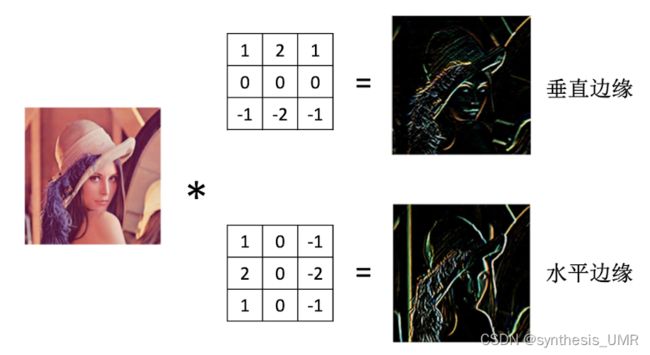
信号处理和DSP里面的卷积是需要翻转的,而CNN卷积是为了提取特征,不需要翻转。即CNN的卷积是互相关的。
下面来看卷积得到的图像尺寸变化:
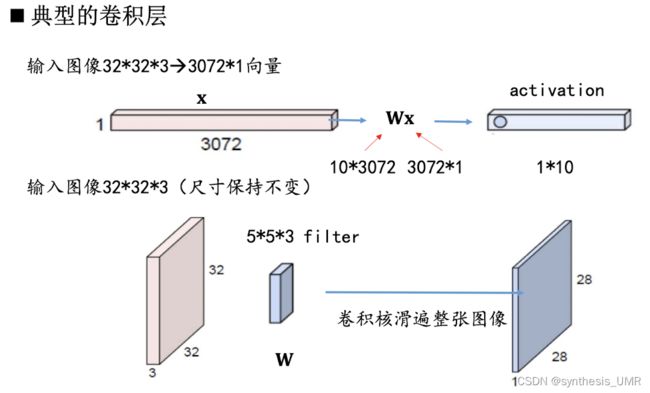
由于我们的图像都是3通道的,所以要考虑三维卷积操作:内积+偏置
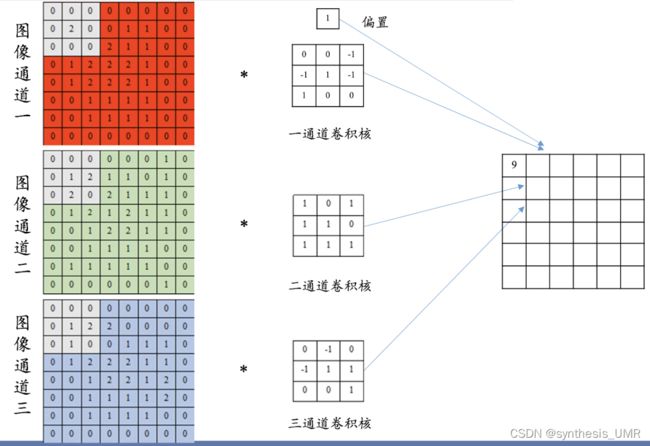
所以一个5*5*3的卷积核卷出来一个二维的feature map,我们叠加几个不同的卷积层:
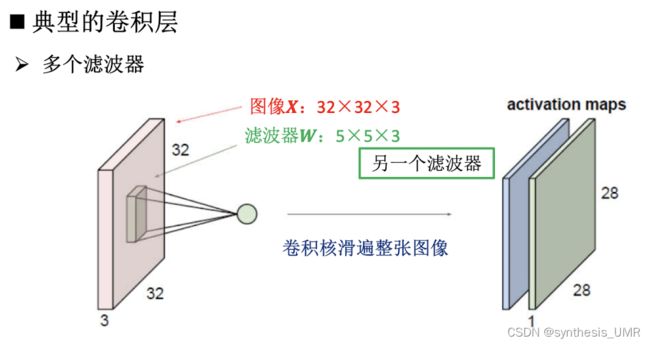
就可以得到卷积公式了:
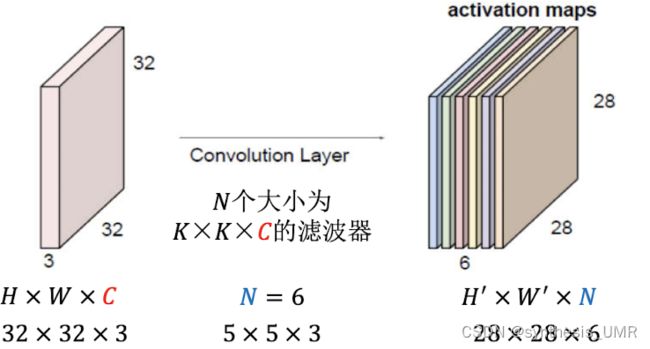
我们发现这个卷积会越卷越小,这对于我们的工作是不利的。所以要加入padding操作。
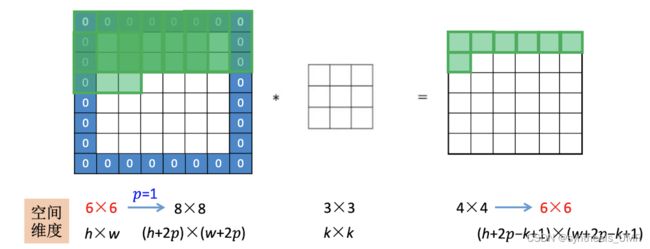
对于padding有两种常用的方式,valid padding和same padding。valid padding就是不做padding处理。same padding就是卷了以后和原来的图像还是一样大。
我们说卷积核通常是奇数,这是因为如果是偶数的话,就只能使用一些不对称填充。而且奇数卷积核会有中心点,这样方便指出卷积核的位置。

除了padding操作外还有stride操作。可以成倍的缩小卷积输出空间尺寸
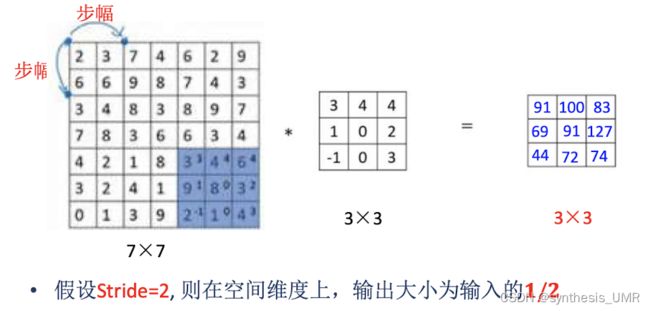
这样总共的卷积输出公式就是
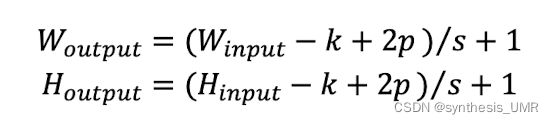
k:卷积核大小 s:步长 p:填充


每个卷积核配一个偏置,这个地方要注意。
值得一提的是1*1卷积滤波器经常被用到。
用途:特征降维(在通道数方向上压缩)是减少网络计算量和参数的重要方式。

最后是感受野的概念:
对于单层卷积层,感受野的大小就是卷积核的大小。
对于多层,首先看两层3*3,他的感受野是5:
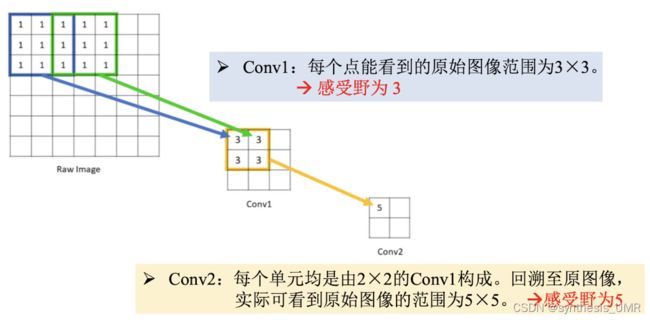
卷积层数越深,相应神经元的感受野越大。
最后我们来对比一下,如果是全连接神经网络处理这个问题的话:
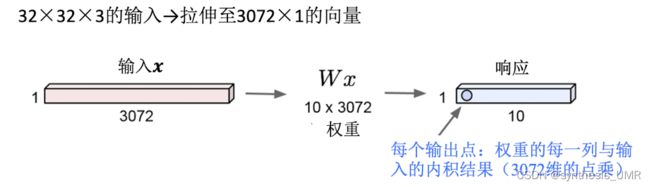
每个神经元都看到了输入的全部。
5.2.2 激活层

5.2.3 池化层
定义:使用某一位置的相邻区域总体统计特性代替网络在该位置的输出
人话:就是一种降采样方法啦。
用途:保留有用信息的同时,减少特征图的空间大小。增大网络的感受野,减少后续层的参数量。
常用方法:最大池化,平均池化
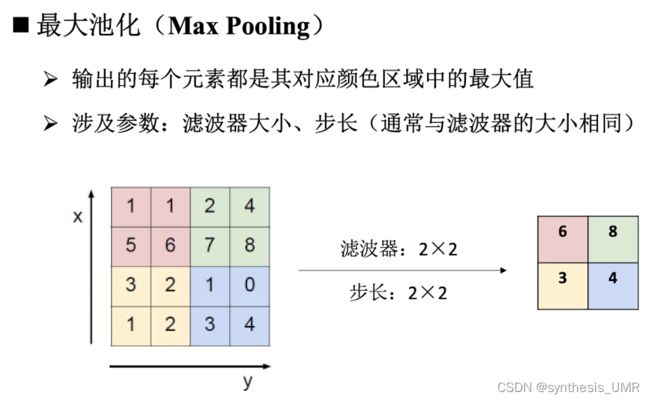
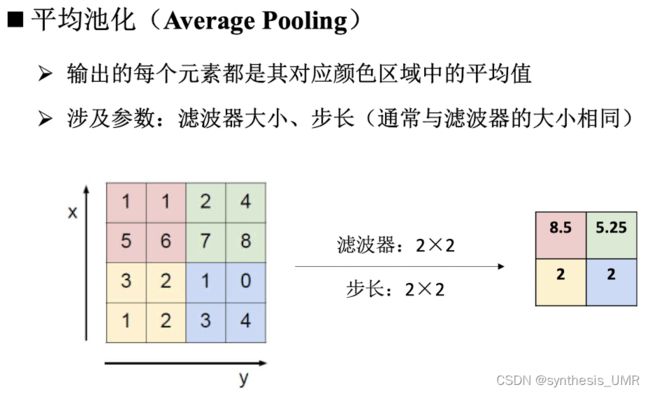
池化层小结:

综合起来就是一道计算题了。
5.2.4 其他网络层
批标准化层、反卷积层、上池化层、空洞卷积层等。
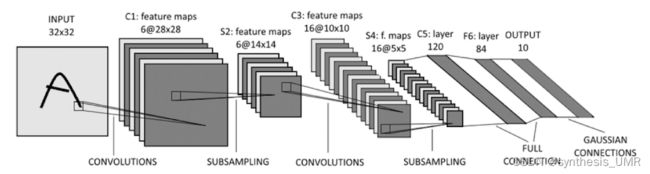
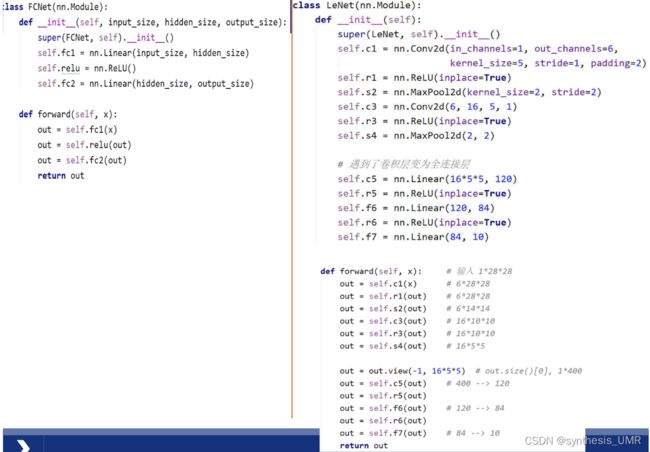
5.3 搭建卷积神经网络
以LeNet-5为例,其实就是看网络结构写代码的过程:
第七章 常用CNN架构介绍

7.1 CNN backbones
图像分类比赛ILSVRC是最重要的计算机视觉挑战赛之一,我们今天介绍的各个网络都是这个比赛的第一第二名。
7.1.1 AlexNet
第一个现代深度卷积网络模型
特色:
使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度消失问题。
使用DropOut忽略一部分神经元避免过拟合。
使用重叠最大池化,采用重叠技巧可以提升特征的丰富性。
提出LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,抑制其他反馈较小的神经元,增强了模型的泛化能力。

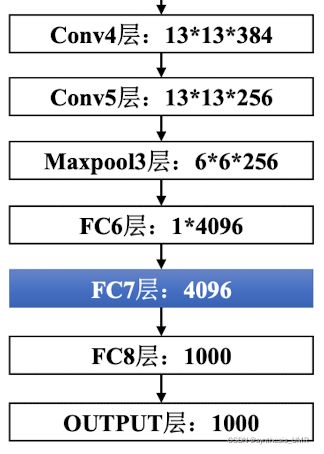
缺点:参数量太多
7.1.2 VGG 牛津大学视觉几何组
采用连续的几个3*3的卷积核,提升了网络深度,减小网络参数量,从而提升了神经网络性能。

优点:
卷积组提高感受野范围,增强网络学习能力和特征表达能力。
可以减小网络参数。
7.1.3 GoogleNet
2014年的winner,VGG是老二。但是Oxford计算量不够只提交了VGG一个模型,GoogleNet是模型组,VGG也是很强的。
提出了Inception的模块。同时使用多个不同大小的卷积操作,有不同的感受野,并将得到的特征在通道维度上进行拼接,最终输出不同尺度特征的融合。
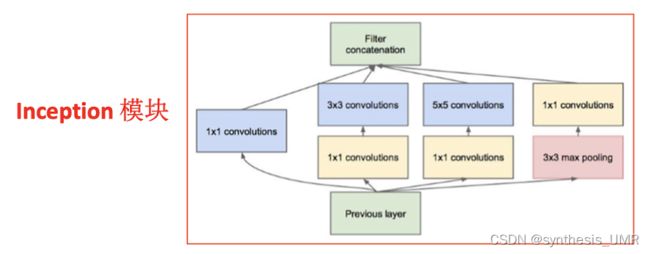
Inception模块有很多的改进空间,我们来看几个:
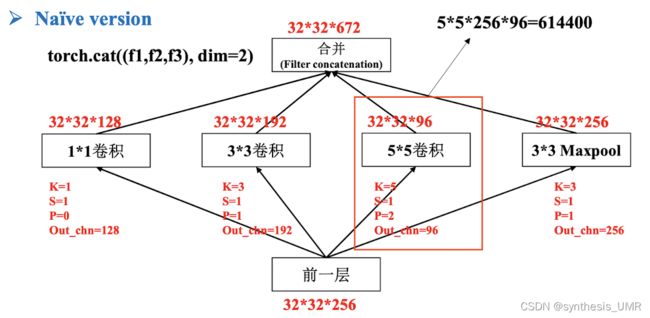
5*5的计算量太大了,不如先用1*1进行下降维: 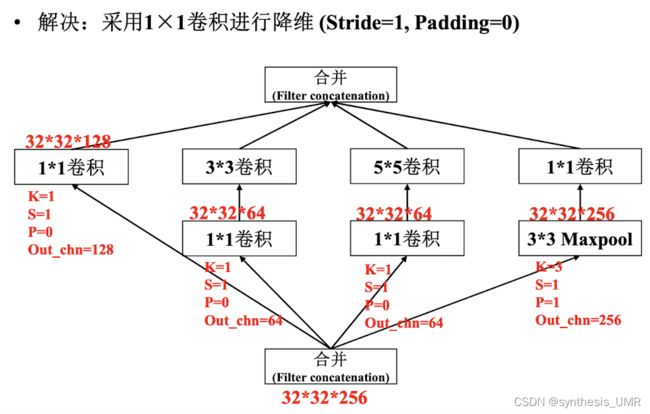
(后面补一下v2,v3几种inception)
7.1.4 ResNet 15年的冠军
解决了网络深度增加的问题。网络深度增加会产生两个问题:1、梯度爆炸or梯度消失 2、网络性能退化。
梯度爆炸和消失可以通过Normalizaion initializtion和Batch normalization解决。
网络退化可以通过残差网络的跳连机制和残差单元解决。
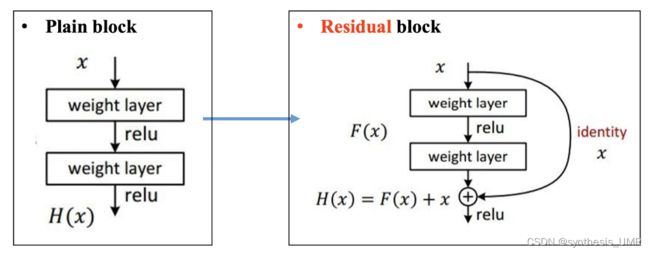
具体这个是怎么操作的呢?csdn在深入理解一下。
resnet有两种残差单元,bottleneck residual和普通的residual。

152层的ResNet居然比19层的VGG还要快,太不可思议了Orz
7.1.5 DenseNet
本质上是对于Residual Net的进一步
前面所有层与后面层均密集连接。通过特征在Channel上的连接来实现特征重用。
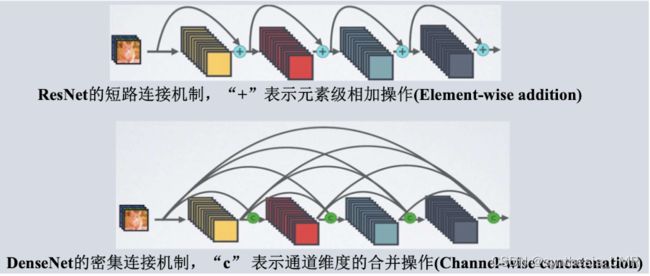
但实际上我们还是用ResNet多,因为DenseNet太慢了。
7.2 卷积网络可视化
不同层级的滤波器提取到的feature maps不同
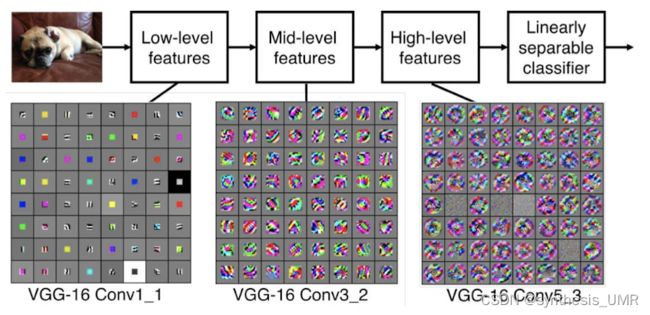
不同层级的卷积层所学习到的图像特征具有分层的特性
浅层的卷积层学习到图像的低级特征:颜色,边缘,纹理
深层的卷积层学习到图像的高级特征:物体位置,语义类别
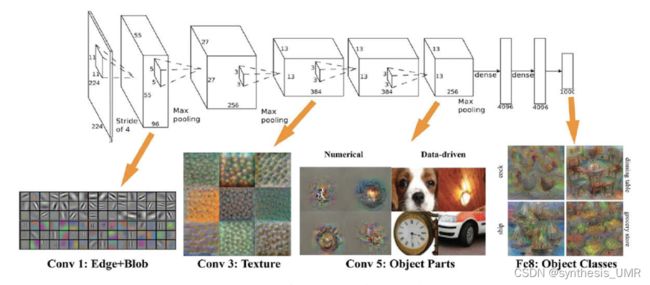
7.3 预训练与微调
给定目标任务,搭建的网络为:f(x;W)

使用已在大数据集上经过训练的模型,可直接使用相应的结构和权重,将他们应用到新任务上。
为什么要微调:卷积神经网络的核心在于提取特征。浅层网络提取基础特征,深层网络提取抽象特征,最后由全连接层根据特征组合进行评分分类。
但是要注意,预训练并非是必要的!!因为更大的训练数据比从一个相关任务模型上微调更加有效。
第八章 通用物体检测
学过了卷积神经网络,接下来很重要的一个任务就是进行通用物体检测的工作。(正在进行中,完成后会加上github连接)
8.1 卷积网络应用概述
图像领域:去雾去雨去噪抠图
自然语言:语言模型,文本图像合成
cv领域:人脸识别,目标检测
8.2 图像分类与检测
图像的常见挑战:视角变换,背景杂乱,光照变换,遮挡,类内差异
8.2.1 图像分类
Pipeline:
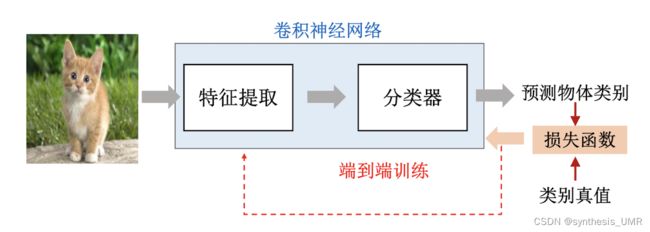
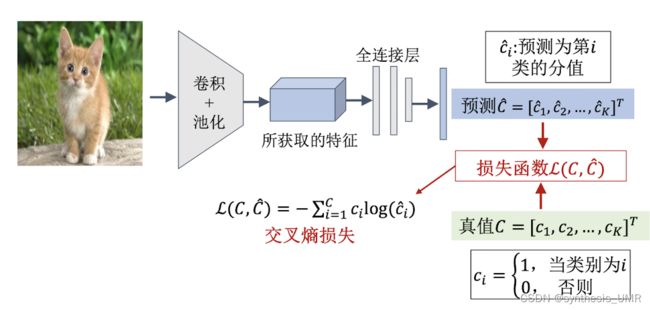
训练阶段:
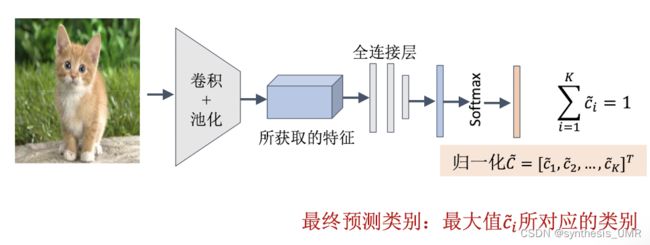
常用的图像分类数据集:
ImageNet,MNIST,CIFAR-10&CIFAR-100,PASCAL VOC
8.2.2 图像目标检测
对于目标检测任务,首先我们要在图像中框定出可能的目标,随后对框内进行分类任务。
1、目标定位
目的:预测图中物体的位置与大小 有监督学习
评估指标:并交比
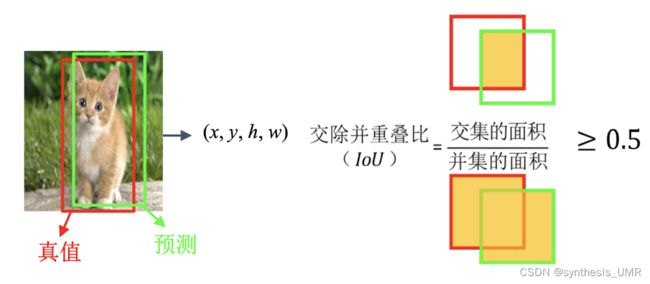
将定位视为目标框的回归问题:
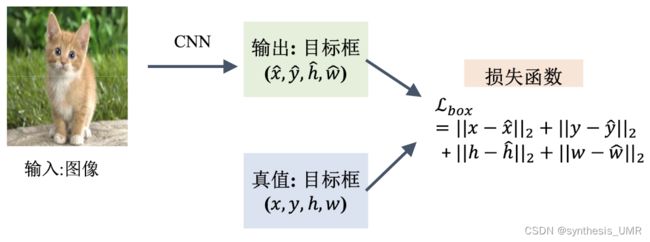
另外再加上分类任务的类别的话,图像的真值就包括类别+目标框(xyhw)
给定一张图片,网络预测5个值,1:类别 4:目标框
预测正确:类别预测正确&目标框的预测和真值的交叉比大于0.5
实际操作起来的话特征是可以复用的,所以网络结构长这样的: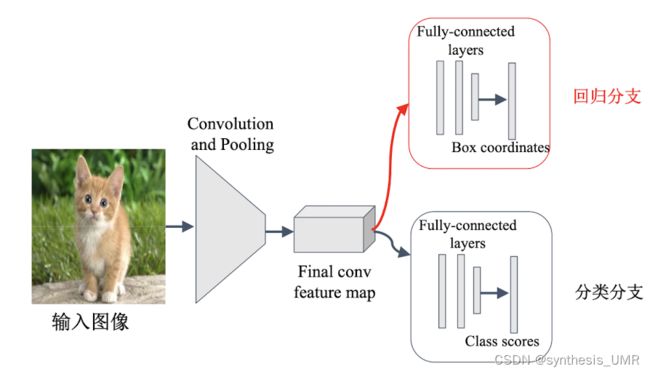
下面8.3我们将详细讲述如何进行图像检测
8.3 图像检测框架
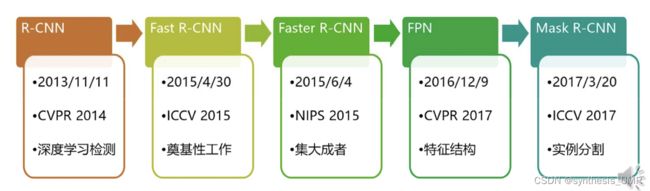
上一节中我们讲了图像检测的框架,也就是把任务分成定锚框的回归问题和一个锚框内的分类问题。下面我们就来看看历史上合目前常用的框架:2013的R-CNN 2015的Faster R-CNN。
在此之前我先解决一个问题,对于锚框任务,有两种思路:视为分类问题or回归问题。视为分类问题的话需要用不同尺度大小的框在所有的位置进行遍历测试,计算量巨大。这个过程也叫做Region Proposals。
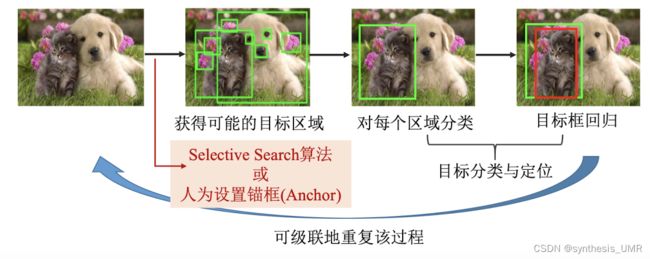
Selective Search SS算法
利用图像分割得到初始的分割区域,利用相似度进行区域拟合
如何计算两个区域的相似度?计算颜色、纹理、大小和形状交叠的差异,用不同的权重相加。
好的,下面我们就可以来看R-CNN了。
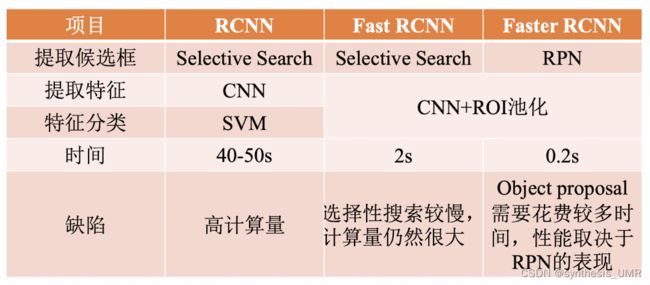
8.3.1 R-CNN
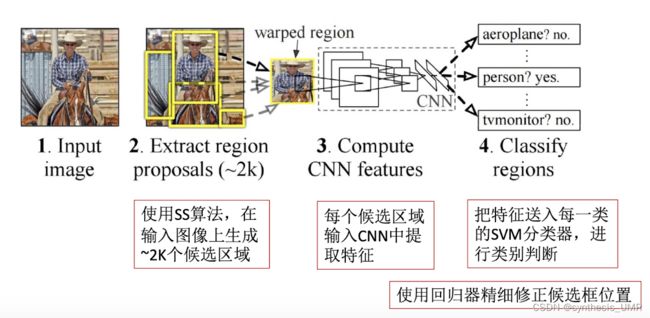
缺点:
使用SS算法生成候选区域非常耗时间
一张图片提取2k个候选区域,需要2k次CNN提取特征,存在大量的重复计算(Fast R-CNN)
特征提取,图像分类,边框回归是三个独立步骤,需要分别训练,测试效率低。
8.3.2 基于CNN的目标检测算法:SPP-Net
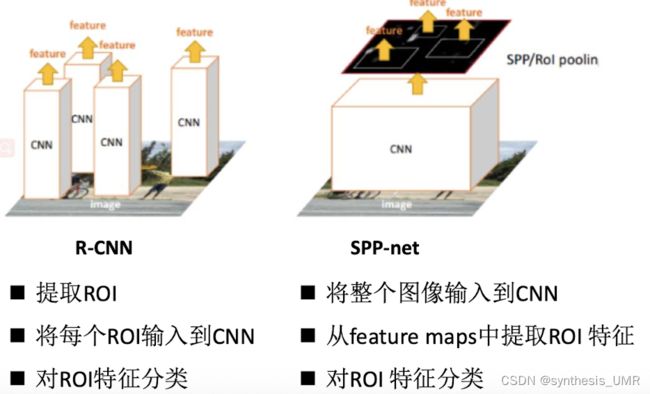
ROI:region of interest感兴趣的区域
所以可以看出SPP-net不需要第一步提取ROI
但是因为全连接层需要输入特征尺寸相同,所以需要对输入的图像做图像扭曲。在这个过程中巡视了原始图像信息。

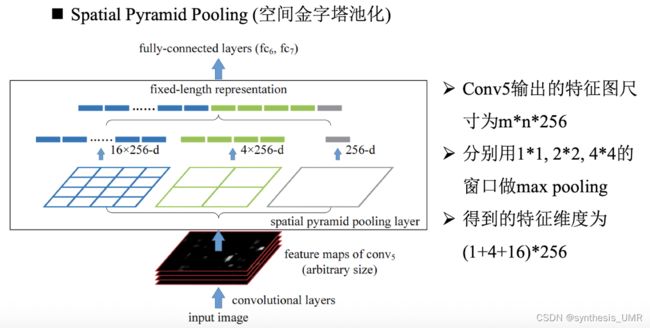
SPP-net所使用的一种卷积到全连接的过程中的过渡方式叫空间金字塔池化,何凯明等人提出,有效地解决了卷积神经网络对于输入图像尺寸的限制:
8.3.3 Fast R-CNN算法
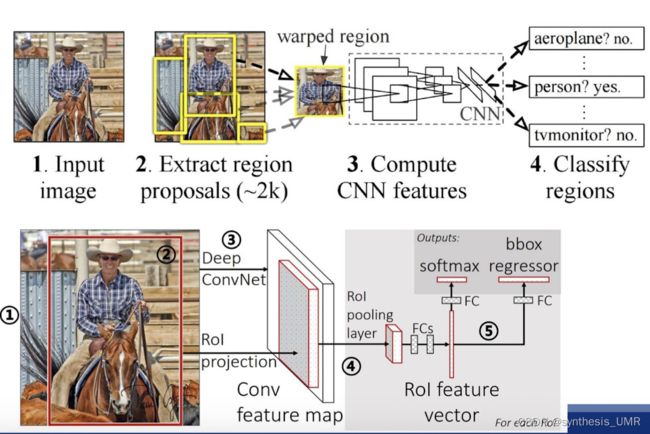
候选区域生成:使用SS算法,在输入图像上生成2k个候选区域
候选区域特征:利用RolPooling分别生成每个候选区域的特征
候选区域分类和回归:利用提取的特征,对每个候选区域进行分类和回归
这里我们要特别注意RolPooling的过程:
RolPolling
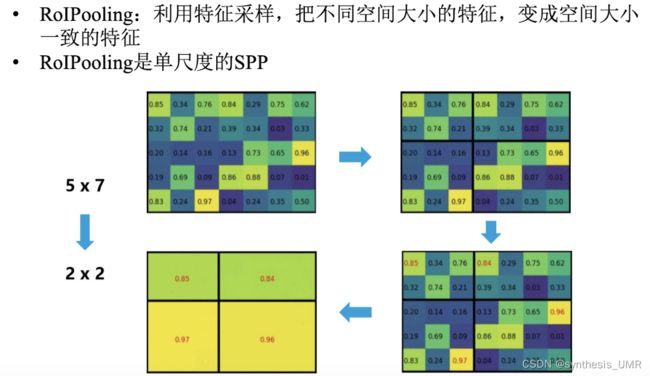
问什么要用RolPooling把不同大小的特征变成固定大小?
因为网络后面是全连接层,要求输入有固定的维度。
各个候选区域的特征大小一致,可以组成batch进行处理。
相比R-CNN
Fast可以进行端到端的多任务训练,快了200多倍且精度更高。
8.3.4 Faster R-CNN
Fast R-CNN还是没能省掉耗时2s的SS算法,所以我们换成RPN网络进行Region Proposal
Pipeline:
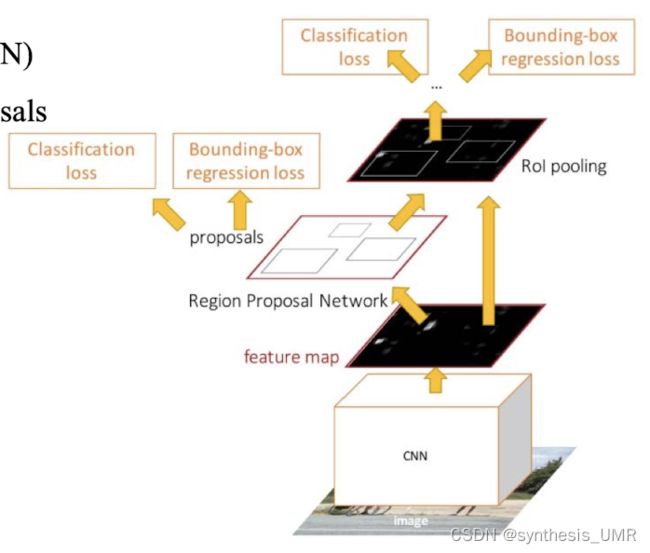
所以可以看出大家都是使用卷积层提供的共同特征。
RPN的具体操作:
RPN 解析_懒人元的博客-CSDN博客_rpn
本质上是一种基于锚框的目标检测
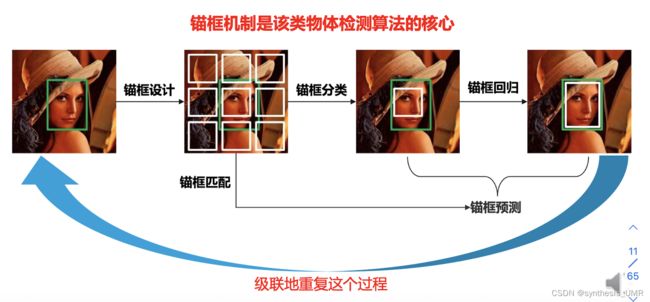
Region Proposal过程: 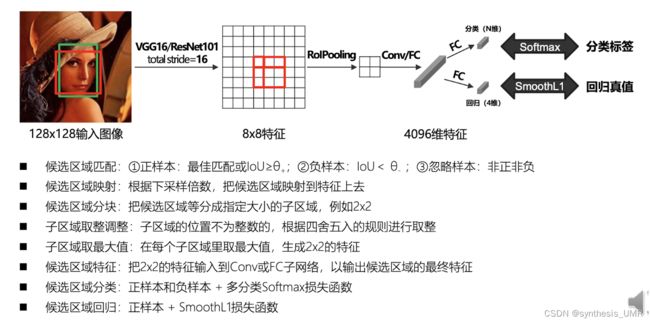
Fast R-CNN算法的整体过程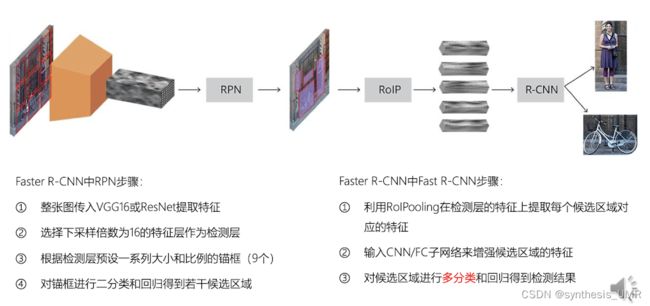
优势:1、RPN替代了耗时的SS过程
2、共享卷积层得到的特征
3、计算量小,耗时少
4、可以端到端训练
更加尖端的改进包括加入多个检测层,控制锚框范围等。(这个开一个新的讲)
8.3.5 YOLO You Only Look Once
这是一个单阶段算法,前面的RCNN都是双阶段:目标检测—分类。
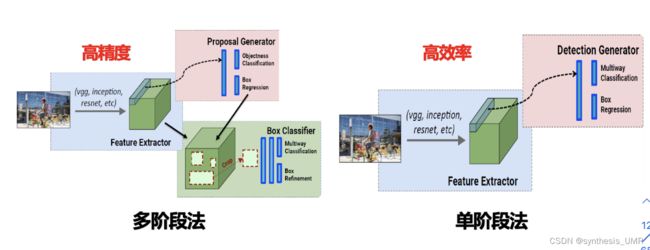
网络结构和输出如下:
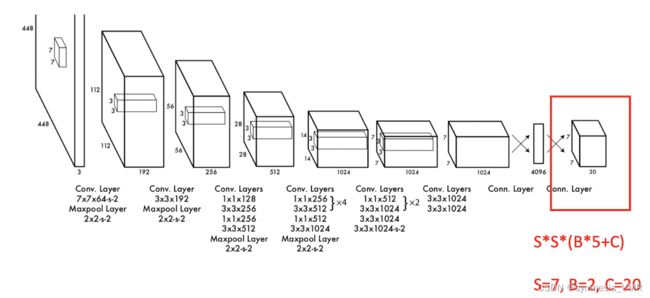

8.4 目标检测竞赛和数据库
通用物体检测数据库 Pascal Voc 2005
人脸检测数据库 Wider face 最大最权威的人脸数据集
行人检测数据库 WiderPerson
第九章 循环神经网络Recurrent Neural Network
9.1 基本循环神经网络
目标:用于处理序列数据(时序)
应用:语音识别,音乐声称,情感分类,机器翻译,视频行为识别,NER,触发字检测
我们让前馈神经网络处理这样一个任务:
Arrive Dalian on 1st Dec
任务:预测目的地在哪儿?时间是?
输入:每次输入一个单词(特征表述)
输出:属于目的地或时间的概率
训练好了以后再输入:Leave Dalian on 1st Dec 这时候dalian是出发地,所以FNN不能分析语义信息。输入是固定的,输出就是固定的。
另外,前馈网络的输入长度要求相同,文本序列不同位置学习到的特征不共享。对应的不一样的参数所以不会考虑其他单词的信息。
为了对前馈网络的这些缺陷进行改进,我们提出循环神经网络。他需要有以下能力:
1、需要记忆功能,捕获历史时刻的信息
2、将t时刻隐藏层的输出重新输入到隐藏层中,作为t+1时刻的输入。
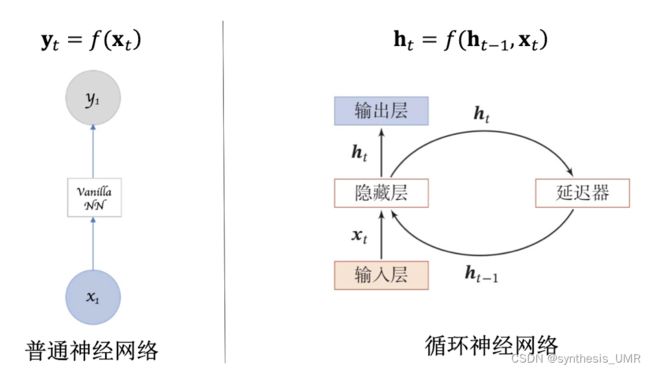
ht-1是前面t-1个字符的特征的总和,所以这样得到的特征很全面。这依赖于延迟器的结构。
比如我们现在要做命名实体识别任务

判断是不是人名,是的话输出1,不是就输出0。Xi是第几个样本的意思,Txi是ti时刻的单词。
我们可以使用one-hot编码:
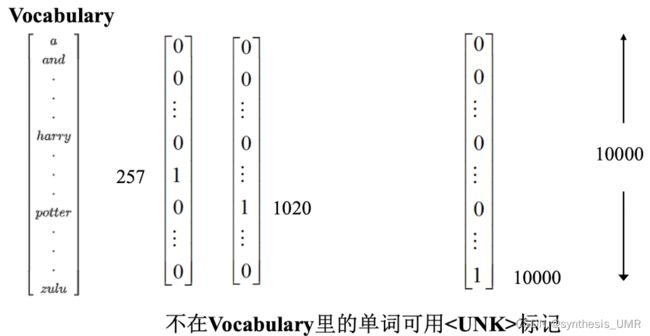
好滴,特征编码的问题解决了,现在就可以进行训练了:
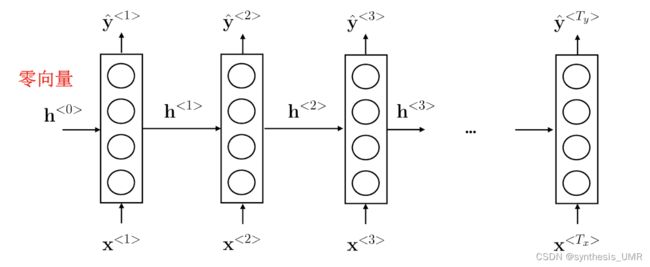
从左到右扫描序列数据;每个时间步共享参数。

层内公式为:
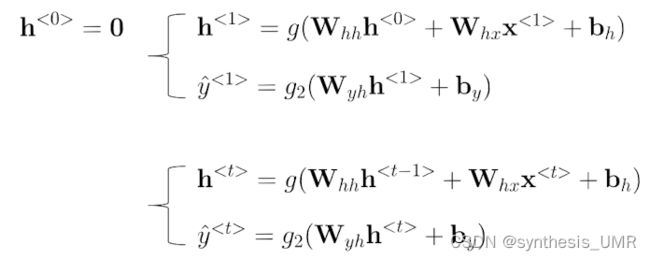
我们来分析这个公式。h1是第一层之前的所有特征和,它是由两个全连接部分:hh特征之间的参数与hx特征和输入外加一个偏置得出来结果。因为最后是要判断这个名词是不是人名,所以激活函数使用二分类sigmoid或者二分类softmax。
然后来分析公式的维度情况,假设xt是10000个词典,hx隐藏层单元是100*10000,得到一个100*1的输出。也就是ht的维度是100*1.Whh也设定为100*100,这样第一项得到的也是100*1的向量。最后再加上一个偏置就得到了100*1的ht。
所以进一步简化,把Whh和Whx合并在一起,就是一个10100维度的矩阵。把ht-1和xt也放在一起就可以得到我们需要的公示了。
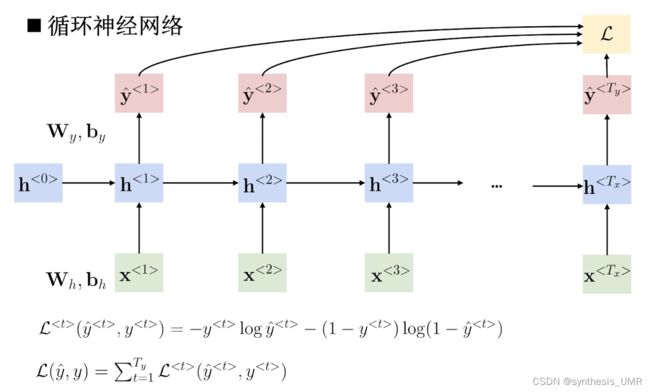
然后再使用分类激活函数和交叉熵损失函数就可以了。
那么为什么RNN可以做这个任务呢?我们给出循环神经网络的通用近似定理:

g是激活函数,o是分类函数。
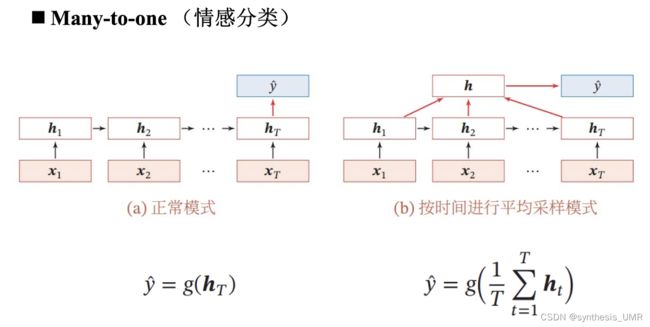
NLP可以大致分one to one的问题,单个输入单个输出。剩下还有Many to many的问题,也就是我输入进来是多个东西,输出也是多个东西。比如我们刚才解决的NER问题。m2m还有一种情况,Tx不等于Ty的情况:比如说翻译,一个英文词汇可能对应着2个中文词。这样我们就要进行编码网络和解码网络。
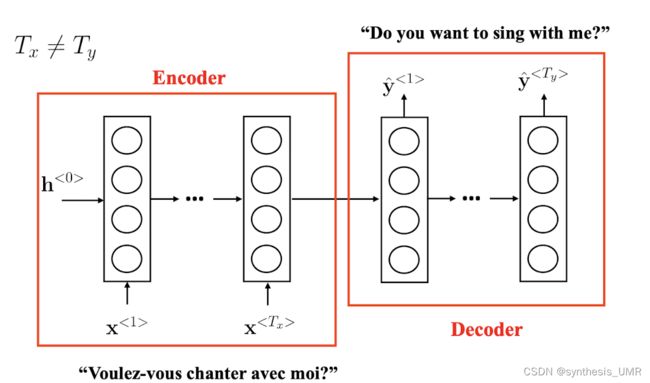
编码器的最后一层包含前面所有词的特征,解码层没有输入,只是计算最后输出的词。
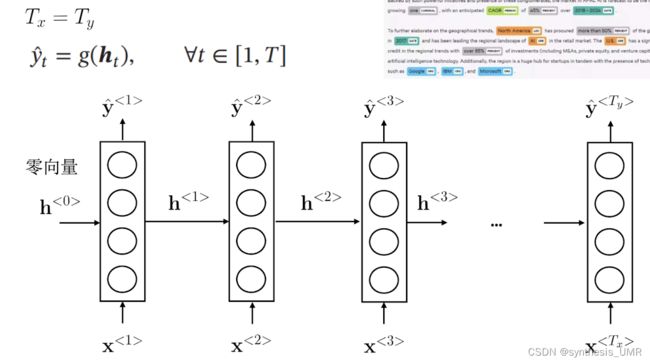
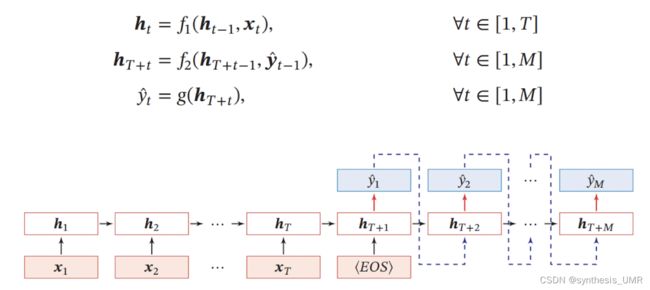
Many to one,比如情感分类问题:
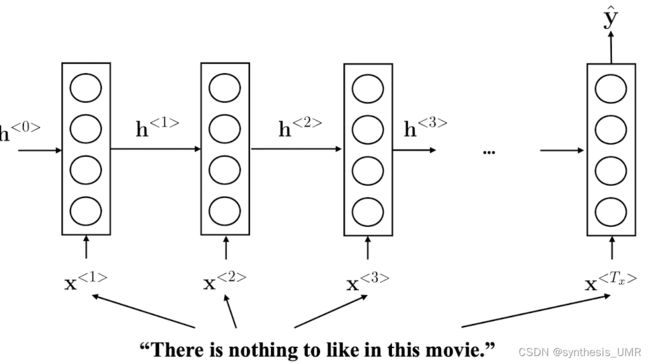
One to many,音乐生成,图像加字幕
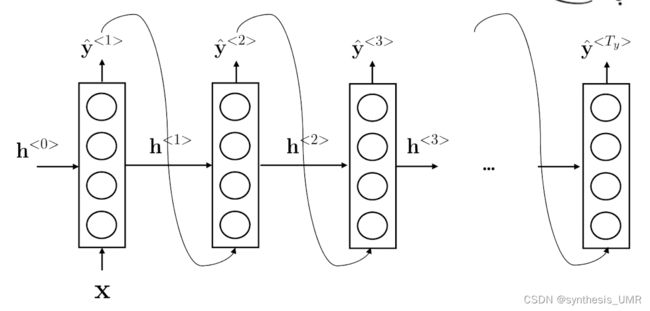
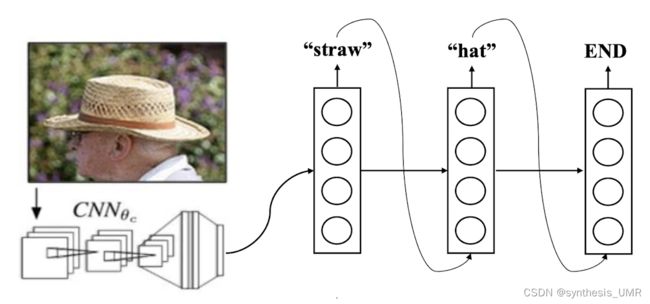
所以RNN有很多不同的结构:
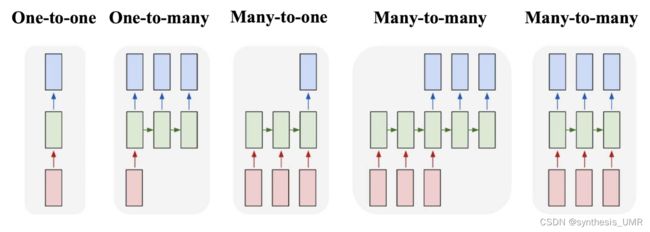
One2One是RNN的特殊形式,就是全连接网络。
接下来,我们要研究一个非常重要的模型:语言模型
9.1.1 语言模型
常用于语音识别和机器翻译,给出一个句子的分配概率,找出其中最可能出现的词序列。

比如说我语音识别生成了以上的两个句子,但是哪个才是对的呢?我们用语言模型生成两个句子的概率,取高的那一个。
构建语言模型
训练集:大型文本语料库
特征表示:one-hot向量
用RNN构建词序列的概率模型。
训练语言模型:

我们在学语言模型的时候就是学习如何生成这句话。第一个time我们让他预测cat出现的概率。其实就是预测词典中每个单词出现的概率。第二个time就是条件概率cats的条件下average出现的概率是最高的,后面也是如此。根据条件概率公式,其实不断做乘法就可以了。不断用交叉熵损失函数进行条件概率更新。
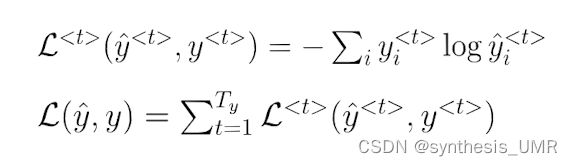
每个概率算交叉熵损失函数,最后加在一起获得总损失函数。优化总损失函数就可以了。
测试语言模型生成句子
在每个时间步下,根据输出的概率分布进行采样。但是这样只能输出学习出来的那句话。所以将采样(也就是cats概率最高很容易摸到cats,其他的单词也有可能被采样到)得到的单词作为下一个时间步的输入。
刚才我们是通过词典定义的,但是随时有新的词汇被声称出来,所以可以使用字符级的语言模型:
Vocabulary=[a,b,c...,z,..?...,0,1,2,3...]
语言模型的评价指标:困惑度

最佳情况下,模型总是把标签类别的概率预测为1,困惑度为1
最坏为正无穷,基线情况下每个类别都相同,这时困惑度就是类别个数N
所以我们要让困惑度在1~N之间是最好的
9.1.2 更多结构的RNN
循环神经网络可以不断将历史信息传递到后面,但是有些时候光有历史信息是不够用的。
1、双向循环神经网络
获取历史数据的信息+获取未来数据的信息

看上面这句话,如果做命名实体识别,很容易就把Teddy识别成实体。但是其实要看teddy bear吧,所以需要把未来的数据也传递给他才能识别到名字信息呀定语之类的。
缺陷:需要得到完整的句子以后才能进行预测,不能实时处理
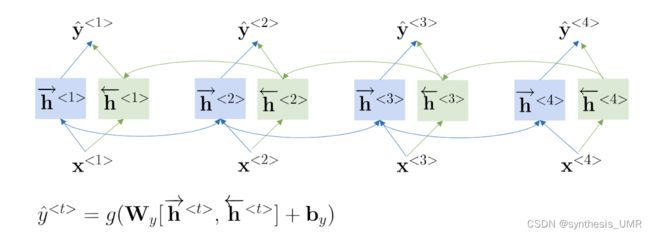
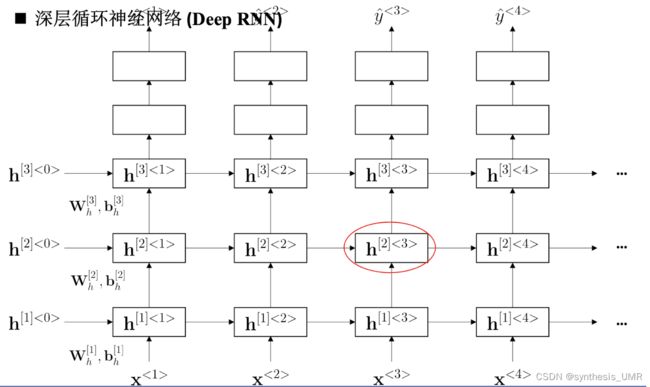
2、深层循环神经网络Deep RNN
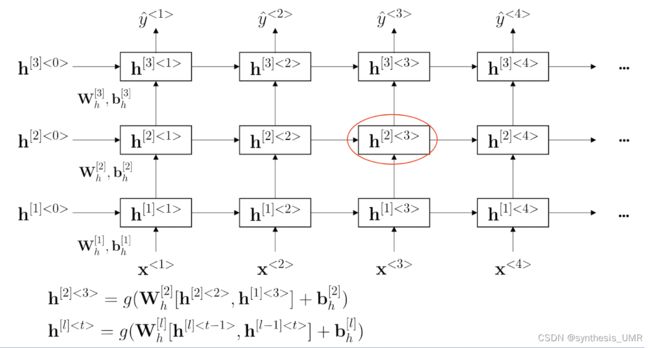
每一行上是循环神经网络,每一列上是全连接网络。到了深层以后就可以不用行循环了,直接堆全连接就可以。
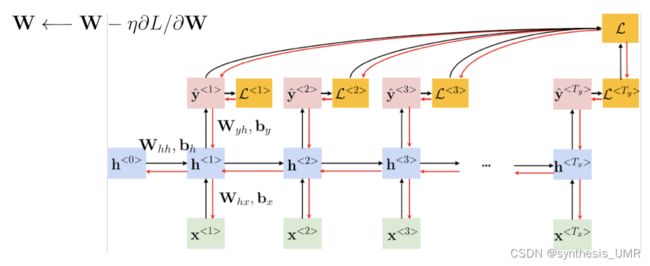
9.2 循环神经网络训练
在循环神经网络中,不同时间下是共享参数的,算出中间一层的梯度,前面的梯度也需要使用,所以不能停在那一层还需要继续往前算。
BPTT:随时间反向传播
与BP实验法不同,Whh和Whx参数在寻找优化的过程中需要追溯之前历史数据,所以RNN有记忆功能。
训练RNN通常比较困难,因为优化曲面存在大幅度陡峭的地方。
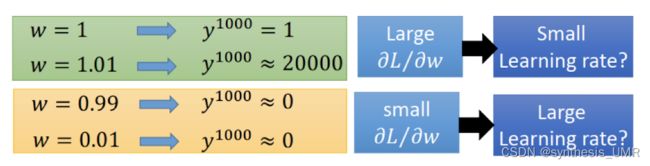
看上图,绿框对应的是陡峭的地方,一点点变换就造成了极大地不同。所以这种地方我们希望使用比较小的学习率。而橘色框对应的是非常平坦的地方,更新太缓慢了我们希望学习率大一些从而加快更新。但是我们在训练的时候又不能进行实时调节,所以很容易造成梯度爆炸or消失的情况。
下面我们进入推到部分,首先是简单的Wyh,直接求偏导就可以。

然后是Whh,因为要考虑历史的情况,所以:
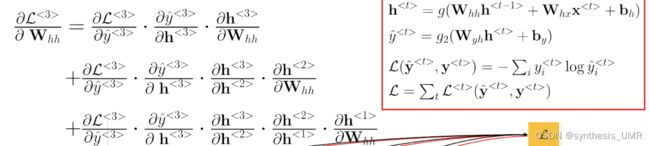
这个偏导中的复合链非常的多,越到后面越多。
最后是Whx:
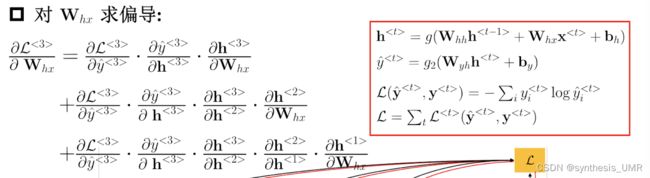
再加入考虑激活函数得到:

看一下导数图像:都是在0~1之间,容易造成梯度消失。而连乘容易导致梯度爆炸。
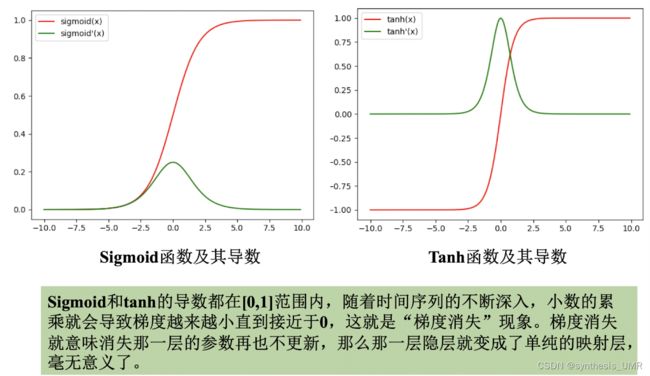
解决方法:
对于梯度爆炸问题:很好解决梯度削减(设置threshold如果超过就砍断)
对于梯度消失问题:1、选择更好的激活函数 2、改变传播结构
还有一个很致命的问题:记忆容量问题 因为一直累加不可能保留所有信息的。
如何解决:
引入门控机制来控制信息的累计速度,包括有选择地加入新信息并且有选择地遗忘之前累积的信息:
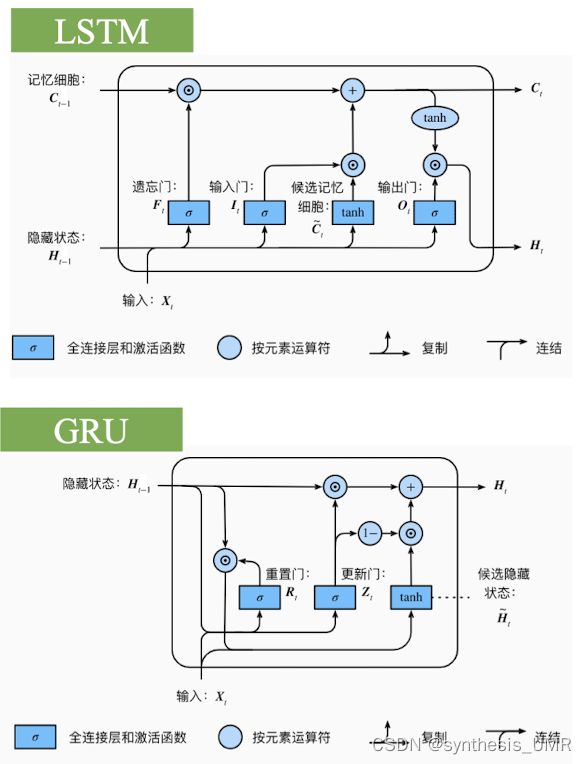
这两种结构都可以有效解决梯度消失的问题。
9.3 长短时记忆网络 LSTM
我们现在工程中首选LSTM long short-term memory,普通的RNN现在都很少用了。
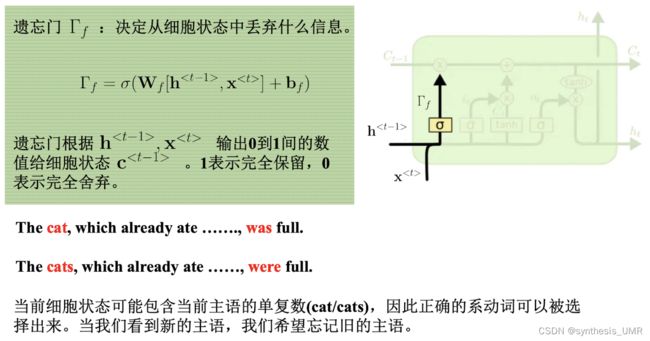
我们看下面这种情况:

动词需要根据主语选择三单与否。这就需要分析间隔较大的信息了。因为存在记忆容量的问题,所以在序列长的时候解决起来比较困难。另外序列长时参数优化过程中还会发现梯度爆炸or消失的问题。这时就需要我们引入长短时记忆网络了。
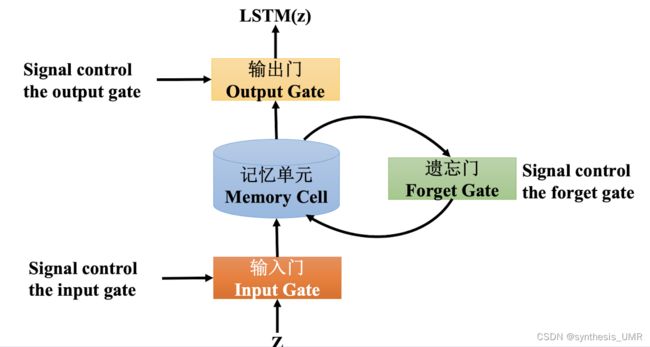
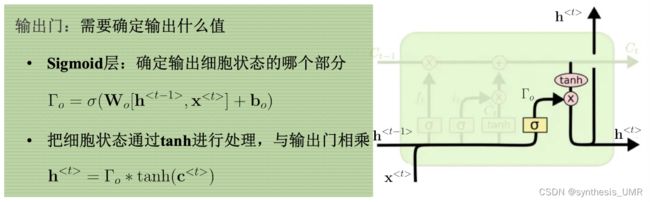
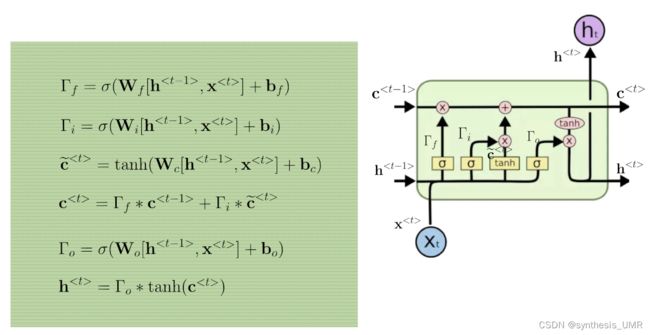
三个门都是使用sigmoid函数完成的
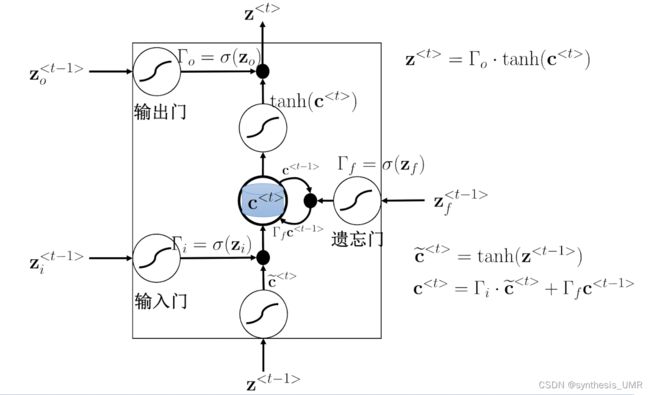
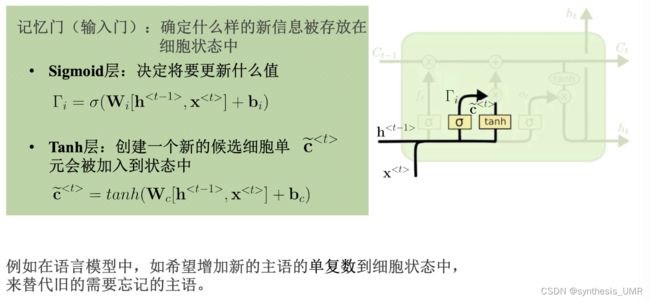
zt-1输入进来,经过一个编码得到候选细胞单元ct。候选细胞单元继续向前传递经过一个输入门,输入门根据zit-1来确定门开多大(用sigmoid函数)
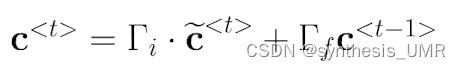
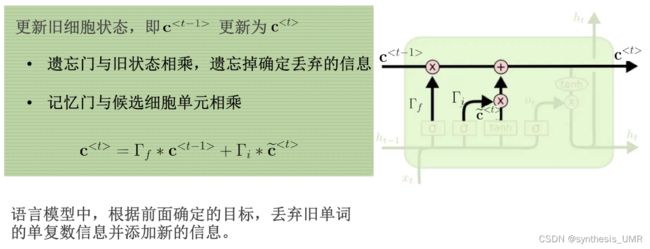
用c波浪t乘上gamai,如果等于1的话就放开,反之就没了。信号继续往前传遇上一个遗忘门,信号zft-1会控制遗忘门开多大。别忘了这个单元里面还有以前的c,所以和gamaj一起加权再和获得的ct相加就可以得到最终的输入了。gamaj会选择性的遗忘一些以往的信息,如果gamaj为1的话所有以前的信息都会被保留,0的话都会被遗忘。
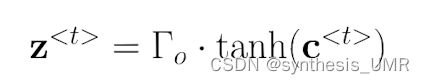
接着对该数据做tanh激活,最后根据z0t-1来控制输出门开多大,得到最终的输出。
LSTM是一种RNN的特殊形式,可以学习长期依赖信息。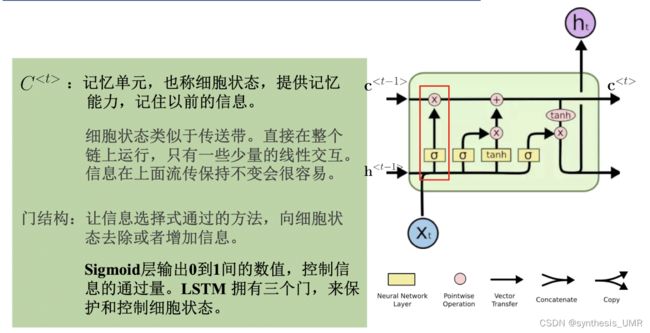
最后总结一下:
还是非常简单的。
最后,为什么LSTM能够处理梯度消失的情况呢?
计算步骤中存在相加操作,不像RNN一直累乘,一直有东西存进来,不至于梯度消失。
遗忘门基本一致开启,一直在遗忘,一直在保存。
9.4 门控循环单元GRN
GRN是一种特殊的RNN类型,可以学习长期依赖信息。
l里面只包含两个门:重置门,更新门
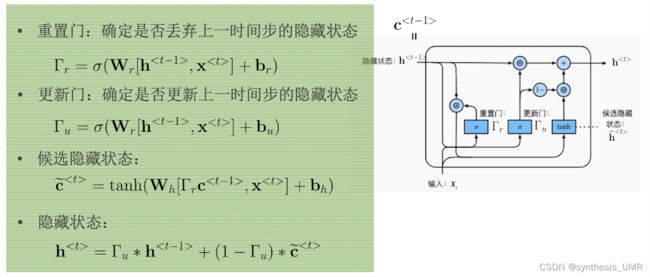
看最后一个隐藏状态,两项是互相抑制的。
对比LSTM和GRU:

ht就想当于ct,GRU节省了记忆单元。ht一部分来自上一次的ht-1,和候选细胞单元ct。所以说GRU是简化版的一般化的LSTM。
建议在实践的时候都试一下。一般来说用LSTM比较多。
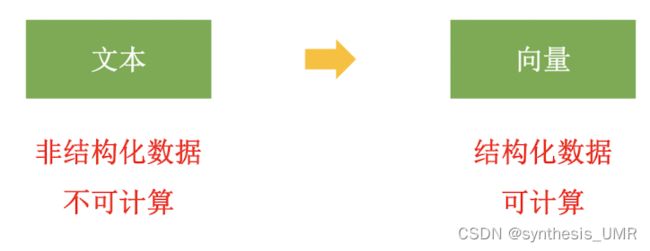
9.5 词嵌入 embedding
词嵌入:NLP中语言模型和表征学习技术的统称。指把一个维度数为所有词的数量的高维空间嵌入到一个低维连续向量空间中。每个单词或词组被映射为实数域上的向量。
文本表示:整数编码 One-hot编码 词嵌入
9.5.1 整数编码
猫1 狗2 牛3
缺点:无法表达词语之间的关系,对于模型解释而言,整数编码可能具有挑战性。
9.5.2 One-hot编码

缺点:无法表示词语之间的关系,相关词汇之间的泛化能力不强
过于稀疏,计算和存储效率都不高。
9.5.3 特征化词嵌入
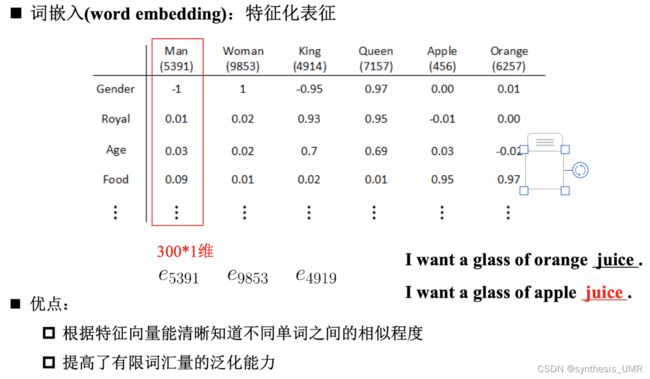
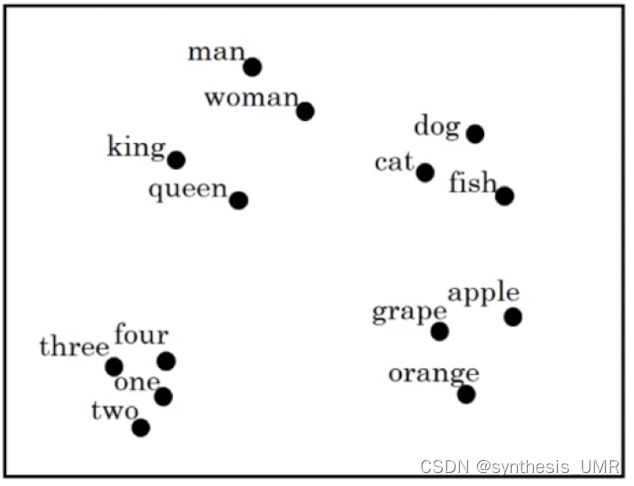
把它们投入到map上面或者连续向量空间,可以发现:
对于相近的概念,学习的特征比较相似
使用词嵌入做迁移学习:将大量文本中学习的知识嵌入到命名实体识别中
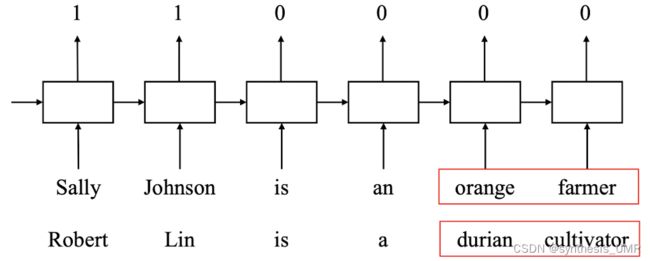
训练词嵌入模型的时候一般是在大型语料库上训练的,一般是通过语言模型(生成一句话)来学习不同词和词之间的关系的。
比如上面这个,到了durian这个词,我们的训练集中没有学过durian,但是大型语料库上训练过,知道durian和orange是水果。所以接下来我们的模型就很有可能输出和farmer类似的cultivator。
从海量词汇库中学习词嵌入,or从网上下载预训练好的词嵌入
在新任务中(样本量少)使用词嵌入模型。
在新任务数据上微调词嵌入模型。
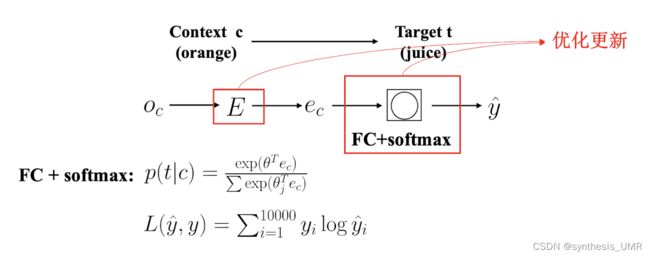
如何训练词嵌入模型?实际上是学习一个嵌入矩阵
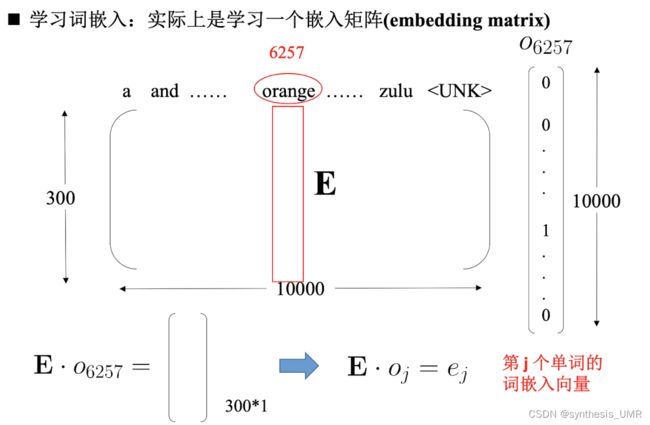
orange是6257这个位置上的,词嵌入就是要嵌入到一个300*1的矩阵上。用学习到的矩阵和o6257做内积就可以得到结果了。
一般是通过语言模型学习的。
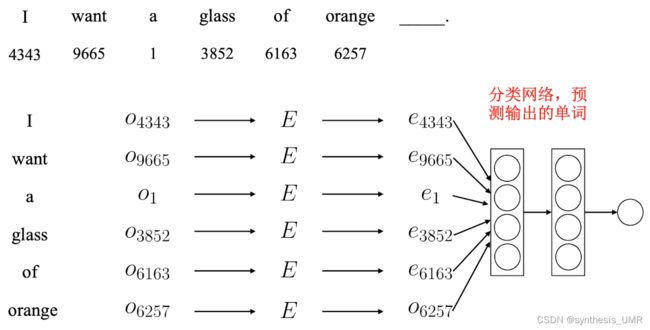
如何克服全连接网络要求输入长度固定的问题?采用固定窗口(只考虑最后四个)
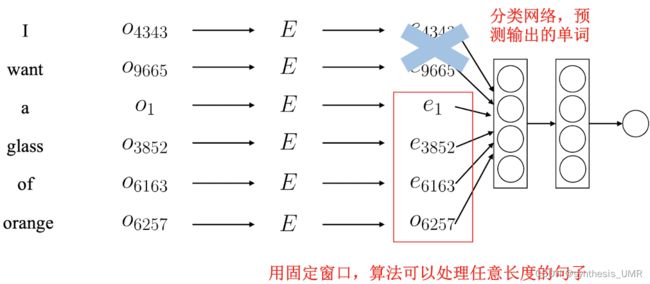
这样的话就可以保证同类的词的嵌入方式是相似的。
除了语言模型之外我们还经常用的是上下文信息:考虑前n个单词,后n个词or前1个单词orSkip-Gram目标单词附近的某一个单词。
比如我们现在固定context是orange,然后在他的附近找target:

这样泛化能力更强,可以通过一个单词预测附近的单词。
9.6 循环神经网络应用
给出一个应用,你能用什么神经网络解决呢?
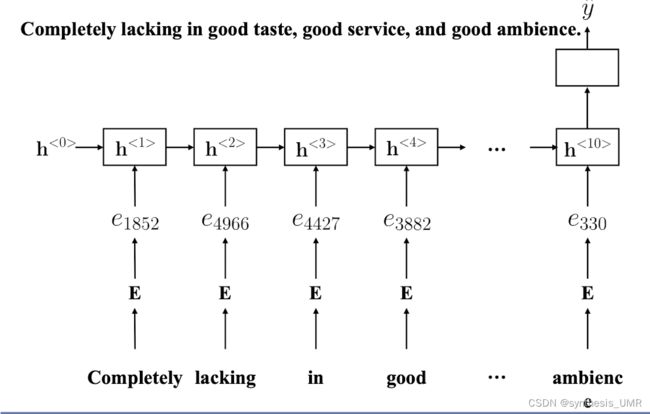
9.6.1 情感分类
9.6.2 语音识别
输入输出都是长度不一样的sequence
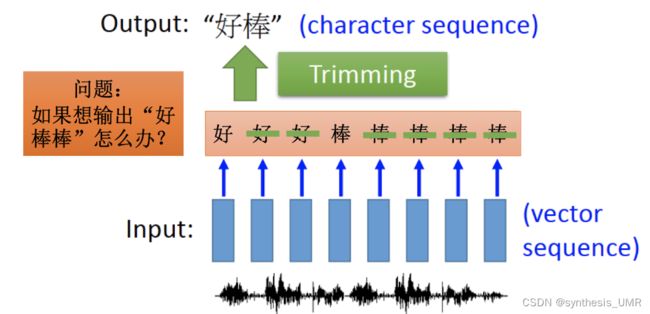
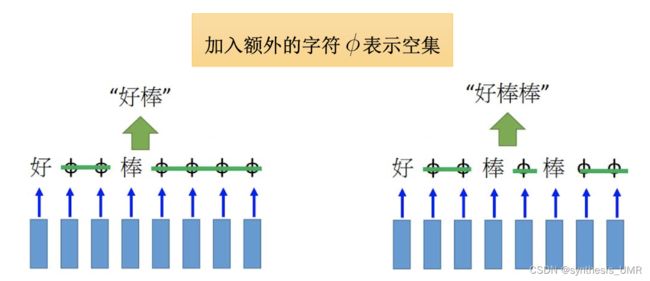

这个是非常经典的CTC模型的策略,假设好棒是6个特征,他们中间具有几个空集的情况都作为训练样本。最后把空集抹掉,这样就可以成功划分了。比如:
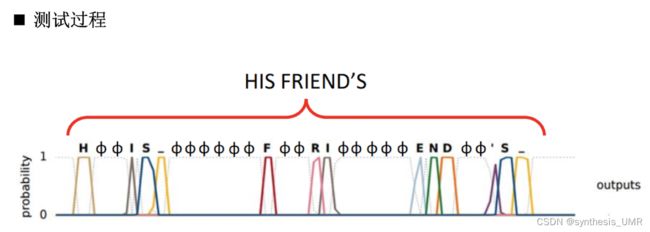
9.6.3 机器翻译
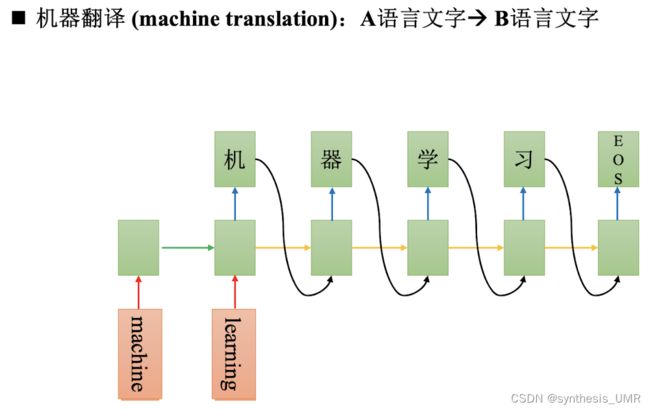
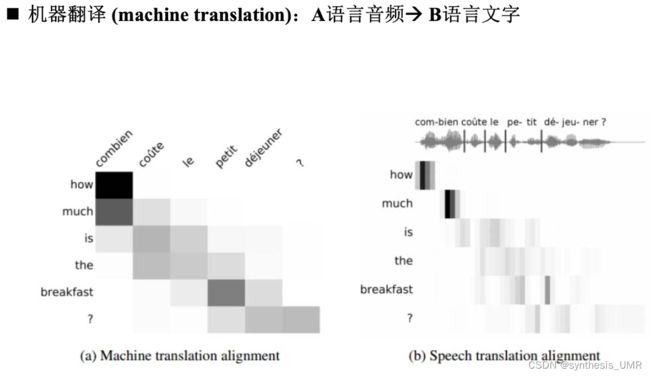
9.6.4 Auto-Encoder自动编码
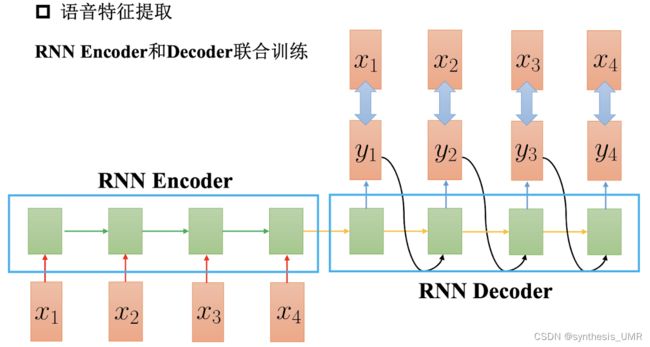
提取文本特征。用RNN编码将文本编码成向量,再用RNN解码成原文本。
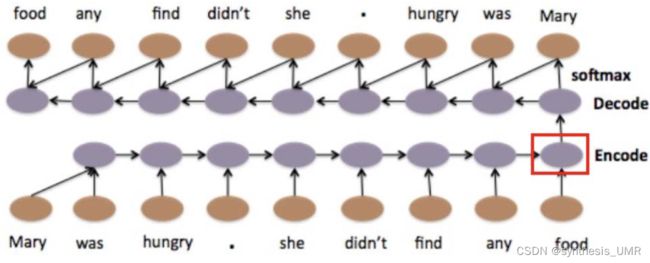
我们想要进行文本匹配的任务,那么首先我们需要有文本的数据库,转化为机器学习的任务就是要提取文本的特征。我们以前进行的都是监督,无监督,回归,分类任务,对于文本任务怎么提取特征呢?我们是这样考虑的:我们对输入文本进行编码。如果编码完后我们进行decode又能把整个句子重新生成,那么就完事儿了,编码特征就认为是特征就可以了。
在实际链路中,整个文本会非常的长,所以可以使用Hierarchical的策略:
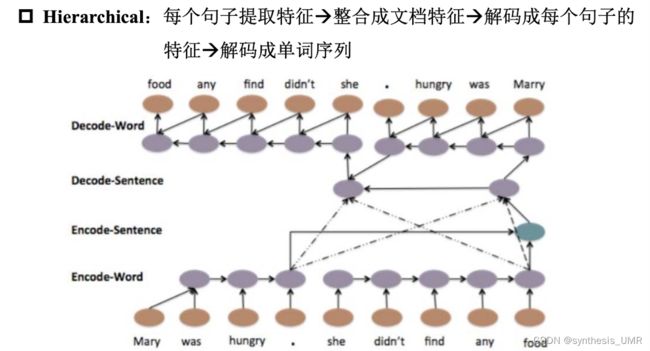
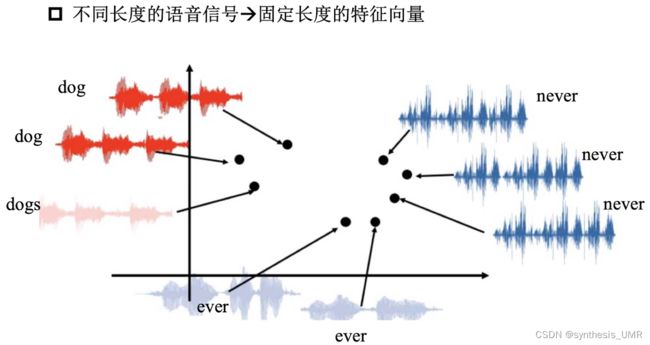
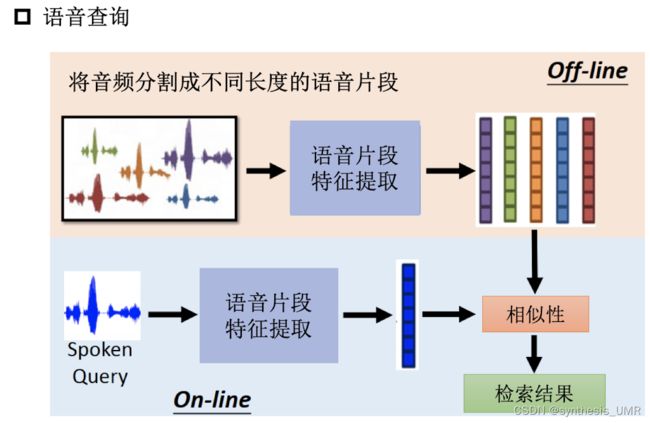
同样的也可以做语音特征的提取:

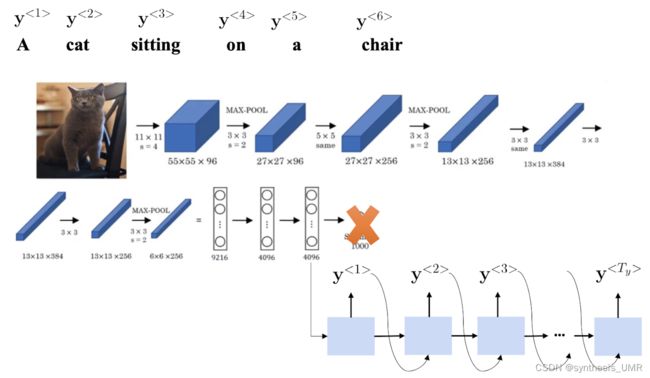
9.6.5 图像加字幕
9.6.6 音乐生成

9.7 循环神经网络小结列表

第十章 无监督深度学习
10.1 无监督深度学习
无监督学习:从无标签的数据中学习出一些有用的模式。
无监督特征学习:从无标签的训练数据中挖掘有效的特征或表示。用来进行降维,数据可视化,或监督学习前期的数据预处理。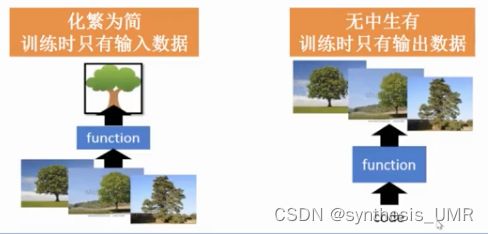
概率密度估计:又称密度估计,根据一组训练样本来估计样本空间的概率密度。参数密度估计是假设数据服从某个已知概率密度函数形式的分布(比如高斯分布)然后根据训练的样本去估计概率密度函数的参数。非参数密度估计(可以用训练数据的密度分布去生成一个分布)是不假设数据服从某个已知分布,只利用训练样本对密度进行估计,可以进行任意形状密度的估计。
聚类是一组样本根据一定的准则划分到不同的组。一个比较通用的准则是组内样本的相似性要高于组件样本的相似性。
无监督学习的三要素:模型、学习准则、优化算法
无监督特征学习:最小重构误差
√ 对特征进行独立性,非负性或者稀疏性约束等
概率密度估计:就是做最大似然估计
10.2 无监督特征学习
10.2.1 降维,AE与PCA
聚类 K-Means

应该由几个簇 HAC hierarchical Agglomerative Clustering
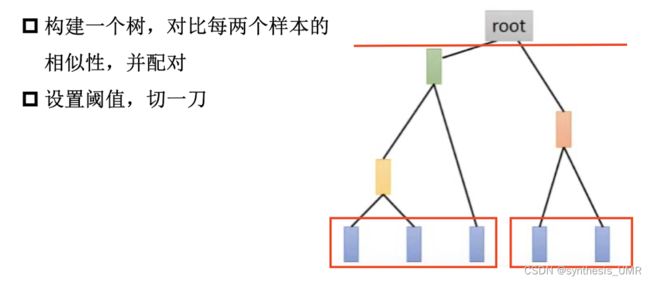
聚类也算是一种极端的降维表示方法,我们还是希望通过分布式的表示。
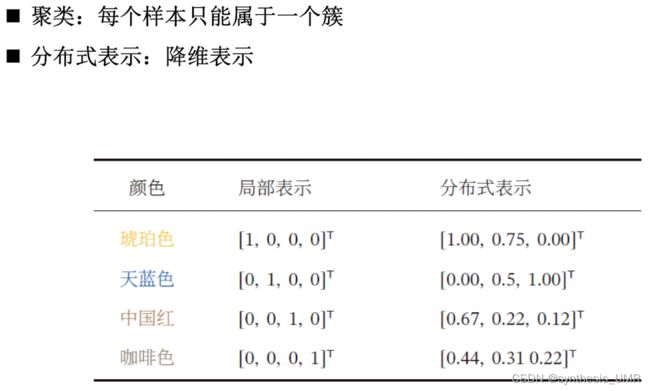
聚类和降维可以做一些可视化的工作:
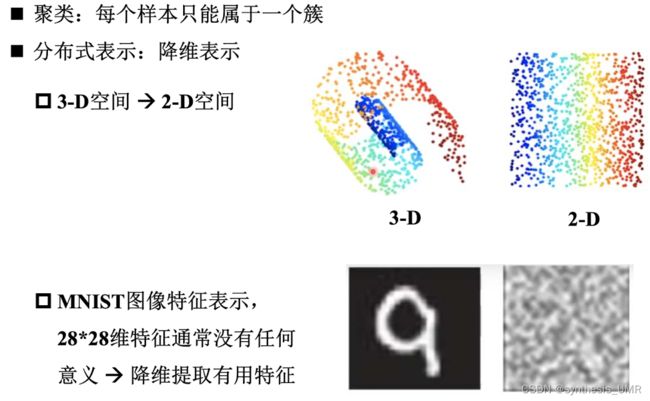
降维表示:
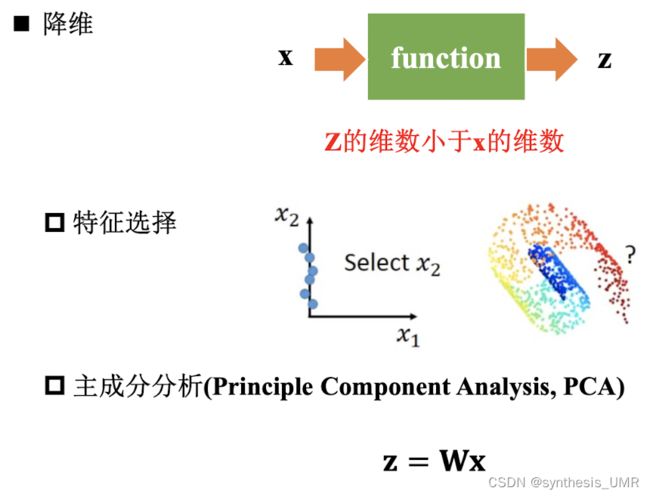
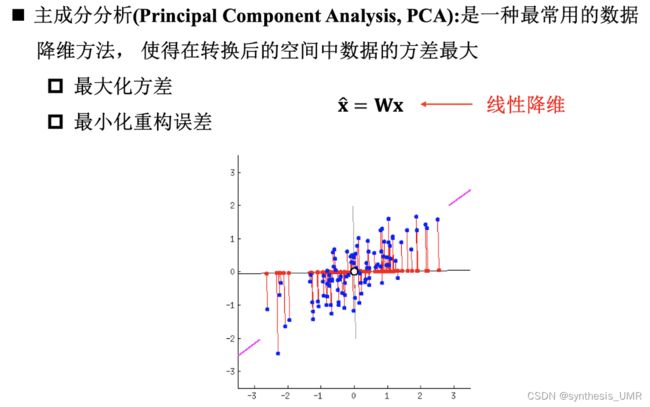
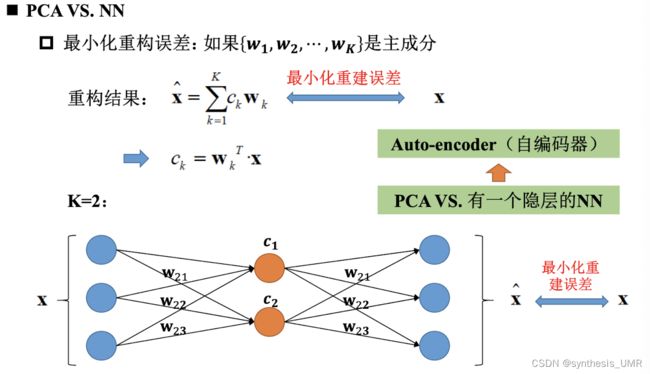
本来的PCA降维方法是通过w21降维成c1,c2,然后可以重构回右边的蓝色圆圈。如果我们把它看做一个神经网络,就想当于有一个隐层的神经网络,但是没有激活层,只是一个线性映射。
但是如果我们通过可视化提取主成分得到下面这些图:
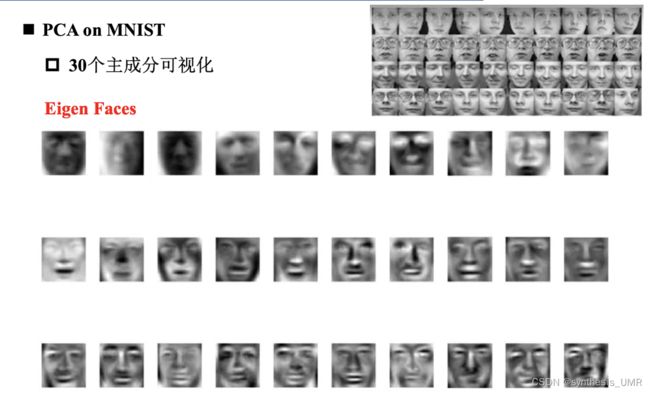

PCA可以提取图像各个角度的特征。
主成分分析相当于单层的,没有激活函数的线性变换。
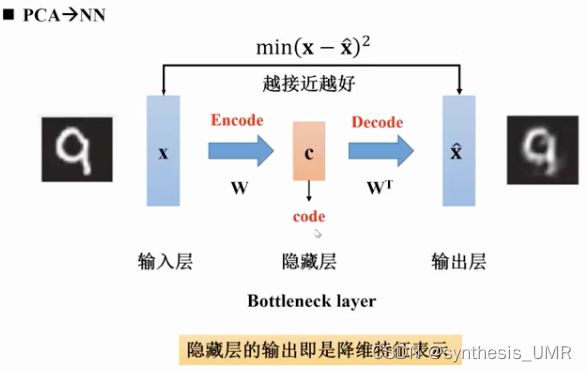
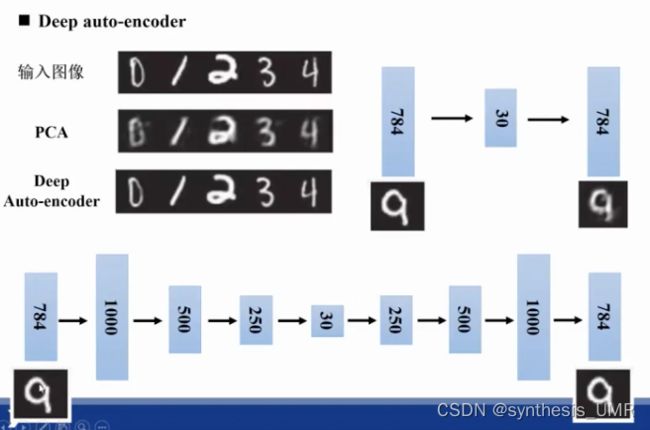
训练Auto-encoder最后只要看他是否能重构出原始图像就可以了。
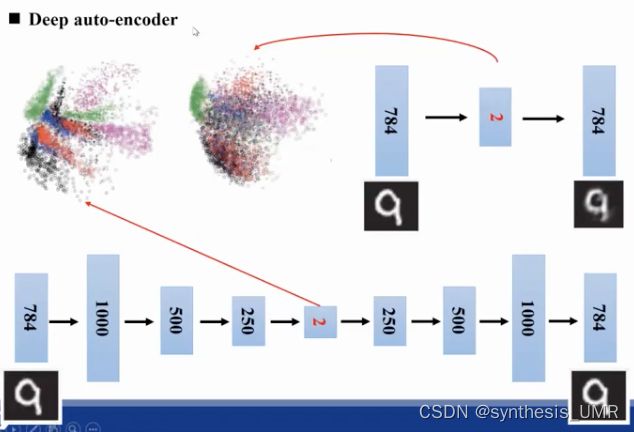
特征投影到空间中可以发现PCA提取出的特征比较混乱,而AE提取出的有聚类特征,说明AE的提取特征的能力更强。
这样我们就可以进行各种工作:
10.2.2 DAE应用
1 Deep auto-encoder 文本检索

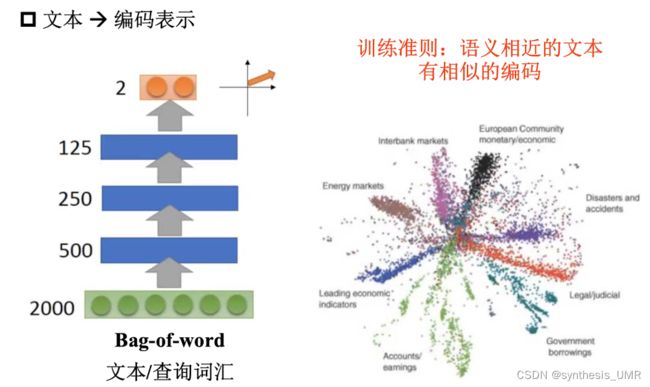
我们可以发现使用AE编码出来的信息同类之间更加接近。这是词袋模型解决不了的。
2 Deep auto-encoder 图像检索
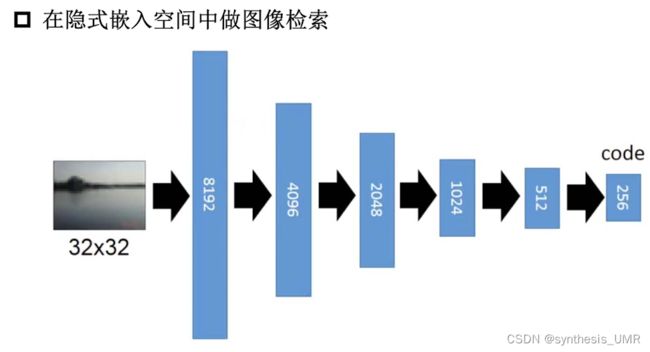

3 Deep auto-encoder 预训练DNN
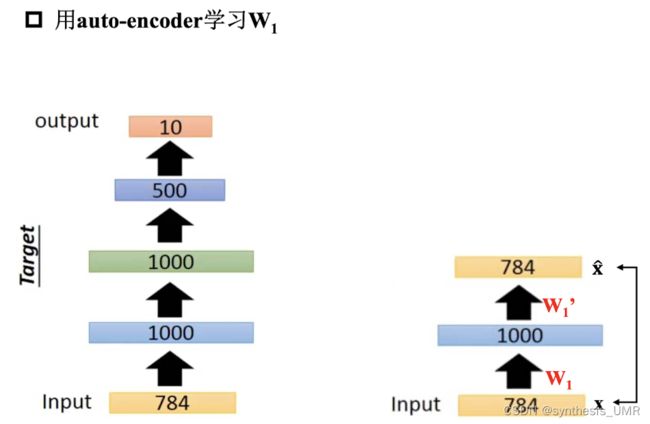
接下来固定学习到的w1,然后学习w2
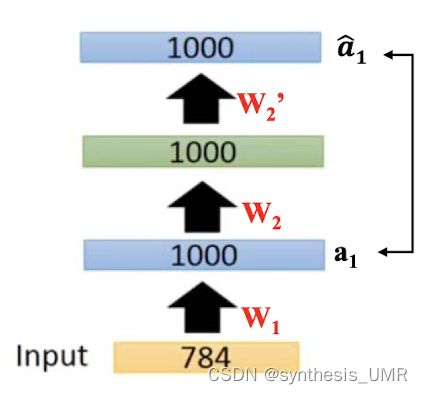
w3也一样,最后随机初始化w4,再进行SGD。
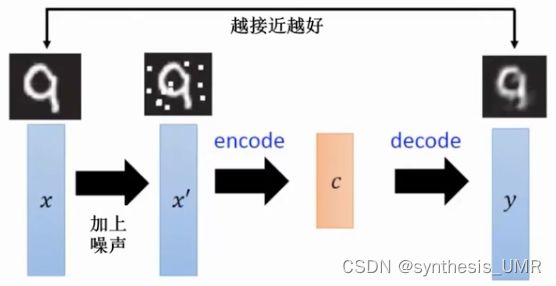
4 Deep auto-encoder 去噪自编码
学习特征嵌入,学习过滤噪声
10.2.3 反卷积与上池化
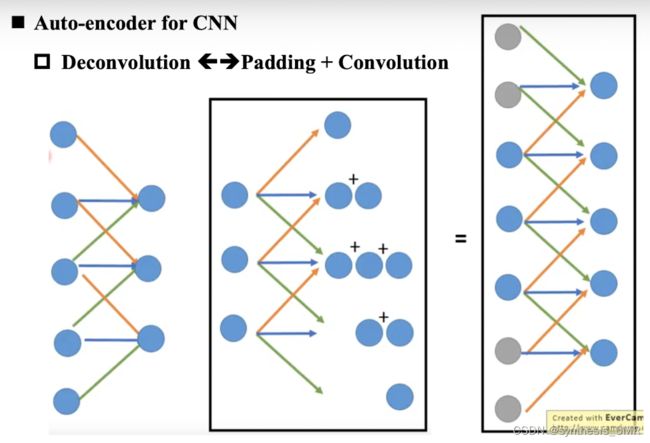
5 Auto-encoder for CNN
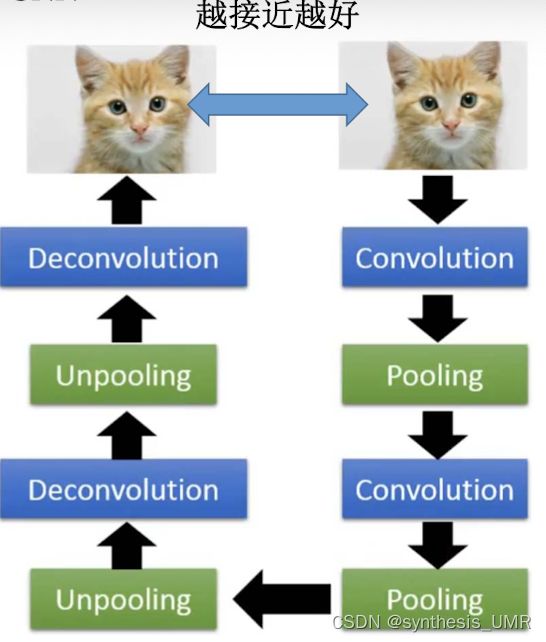
我们接下来就看看反卷积和上采样是什么:
做池化的时候需要保留一些信息,否则不好反池化:

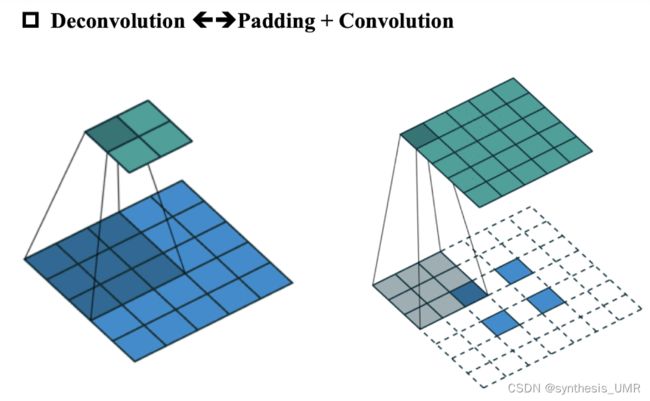
反卷积=padding+convolution
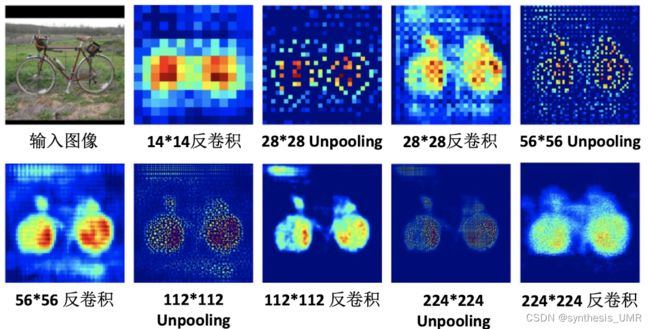
最后我们来看看反卷积和unpooling的效果(反卷积更加清晰)
在图像处理中有很多auto-encoder的结构,比如说FPN U-NET
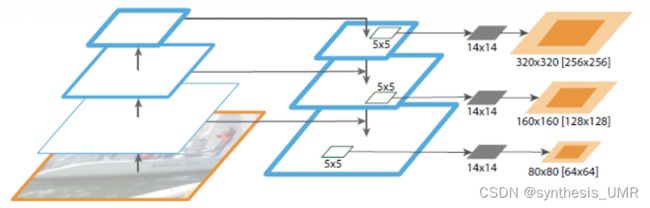
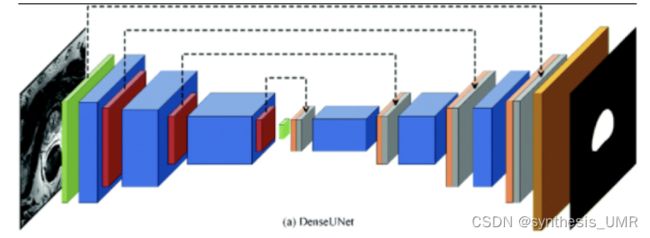
10.2.4 深入理解AE

它能够学到图像的特征从而匹配一些关系 ,如果图片不具备这种特征就没有这种关系。
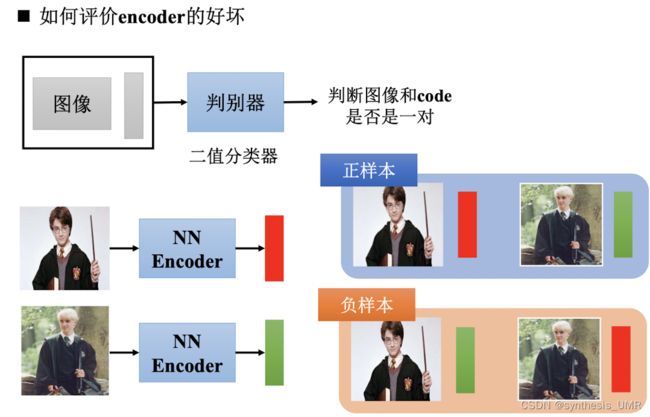
图像和code是否是一类,比较他们的概率分布差异就可以。用交叉熵。
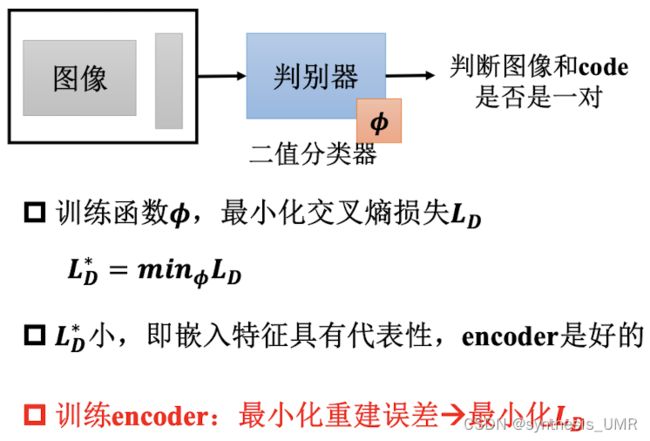
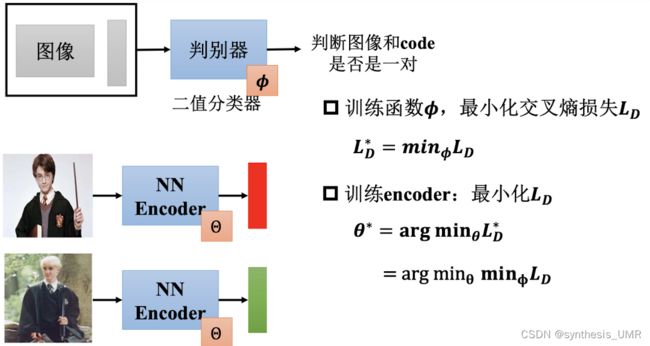
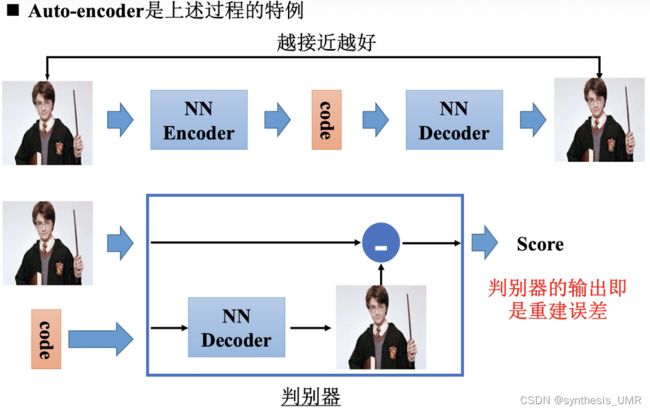
注意:在训练auto-encoder的时候没有使用负样本。
接下来再来看auto-encoder一些有趣的应用:
1、让嵌入特征具有可解释性
比如说我们分析一段音频,里面有语音信息,说话人音色信息等等。如果直接进行编码,那么这些信息都混在一起了。这样不好。我们对encoder进行拆分成2个,来解释语音信息和说话者信息。
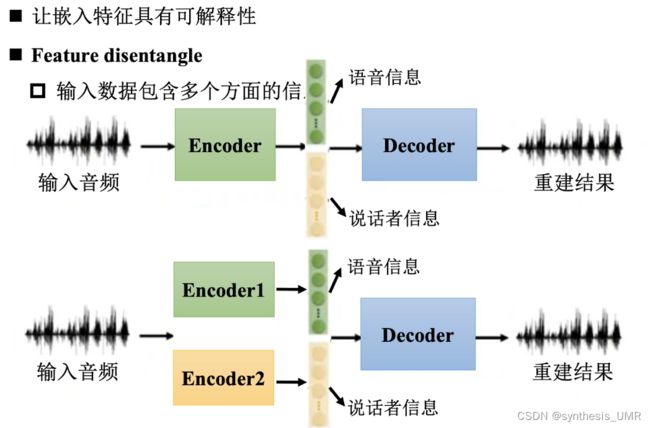
这样我们就可以进行Feature disentangle——语音转换
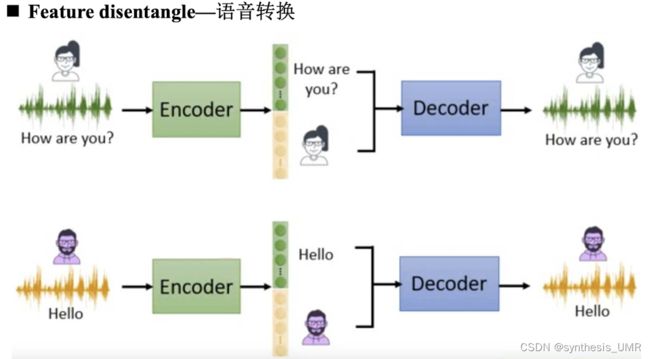
还可以转化说话的内容:
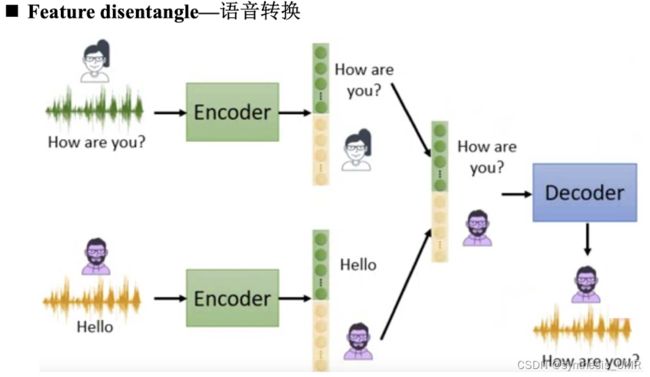
如何进行学习和判别呢?

Encoder和speaker classifier交替训练,可以先固定判别器再训练encoder。训练了一段时间后固定encoder再训练判别器。
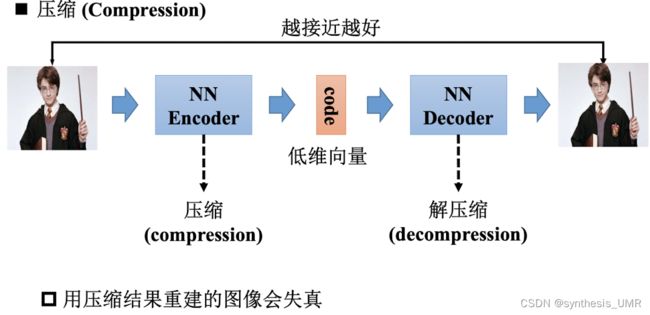
另外还可以用AE进行压缩操作:
以及异常检测操作:

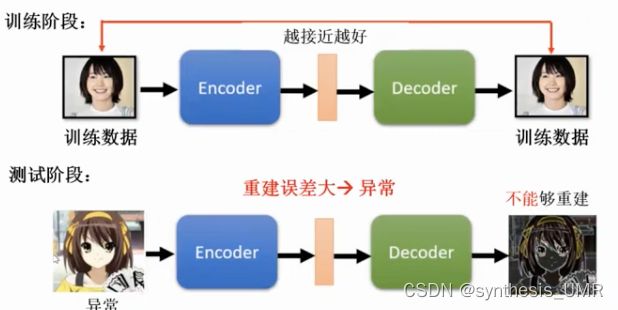
在人脸数据集上输入的,如果输入一张gakki,输出也是gakki说明这张图片ok。如果输入团长就会发现无法重建,说明团长不是真实人脸图片。这张图片是异常的。

异常检测可以用来做以下工作:

第十一章 深度生成模型 GAN
11.1 引言
无监督模型的生成模型:

我们训练的是一个概率密度,所以生成模型也叫做概率密度估计的方法
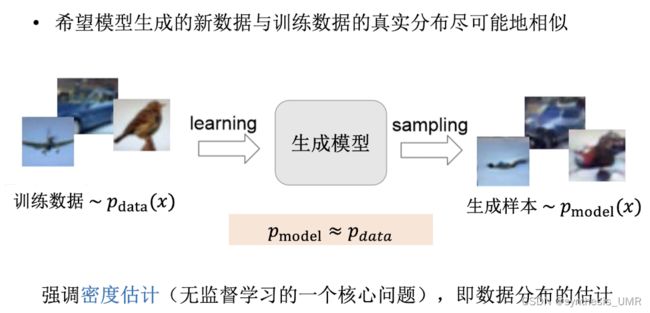
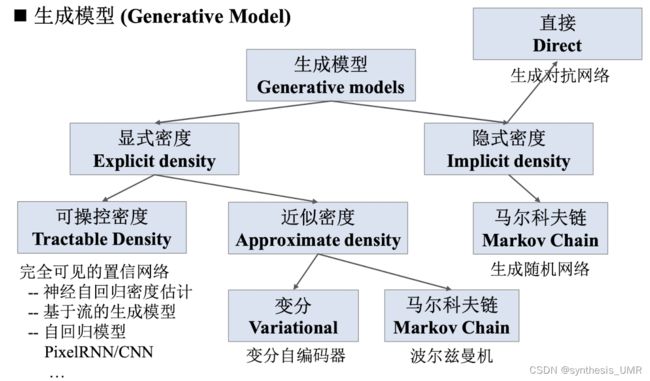
密度估计有两种:显式密度估计和隐式密度估计
显式:明确定义概率分布模型
隐式:不需要直接估计概率分布,通过拟合模型来生成符合数据分布pdata的样本
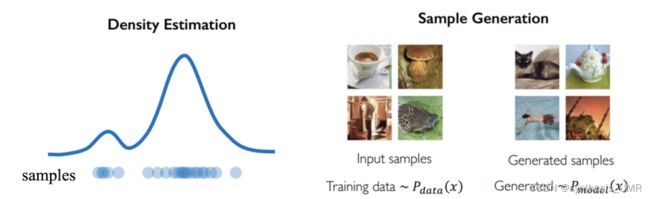
整体的方法一览:
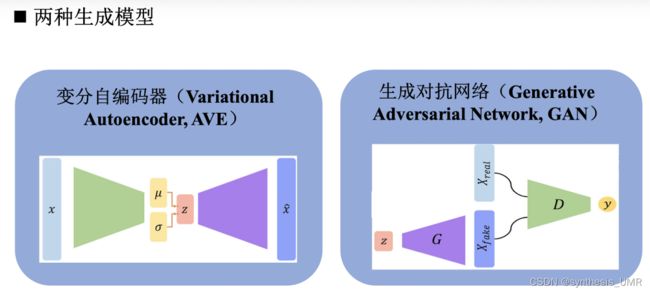
我们本次主要研究GAN和VAE。
生成模型有什么用呢?

很多情况下训练样本不够,使用生成模型可以提高数据样本的获取能力。
生成物理世界中的时序数据,用于机器人仿真和规划(强化学习)
学习有效的隐含特征,为下游任务提供服务
更有效表征和操控高维概率分布的数据
再来看一下GAN-ZOO提供的:
11.2 生成对抗网络GAN
问题描述:
从复杂的高维数据分布空间进行采样,生成新样本。——没有直接可行的方法
解决思路:
从一个容易获取的简单部分中进行采样,并学习该分布和真实训练数据分布之间的转换
借助什么来表征这种复杂的转换?神经网络!
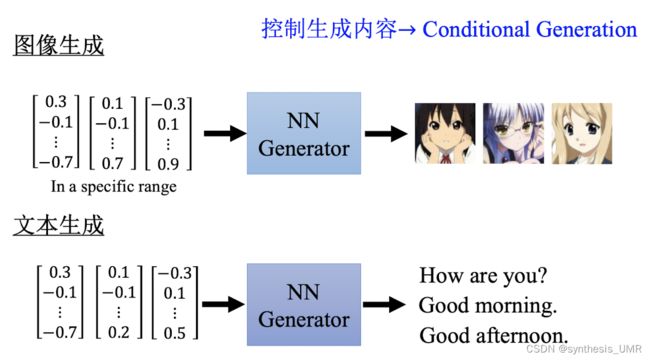
11.2.1 GAN的基本思想
生成网络:
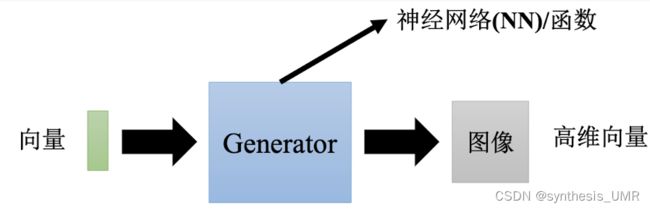
我们说 输入的向量的每个维度都代表着图像的某种属性。
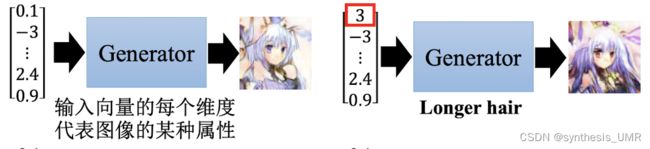

判别网络:
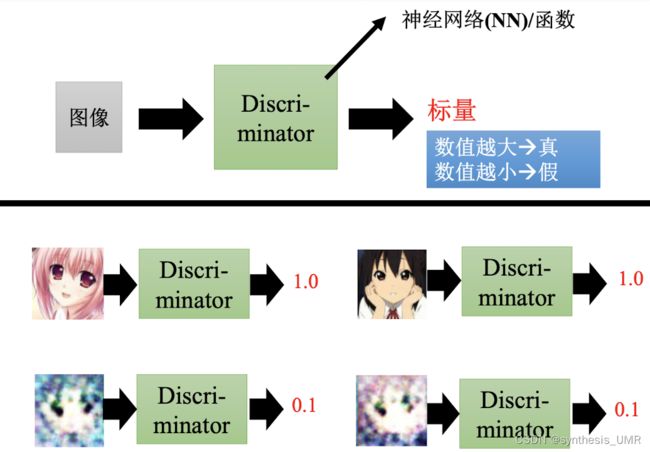
对抗过程:
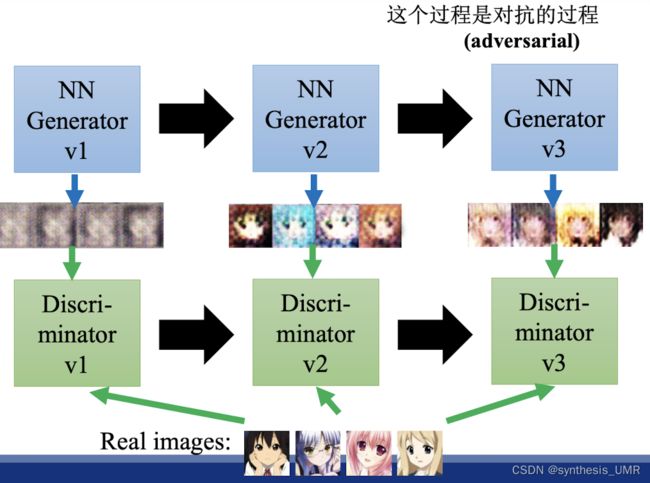
刚开始generator生成的被打了低分;第二代generator生成的就稍微好一点儿,再重复。
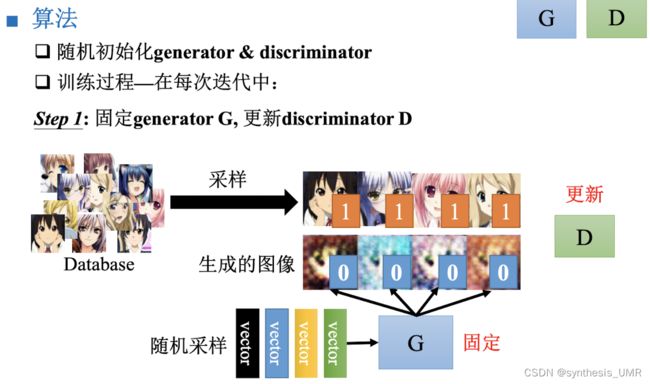
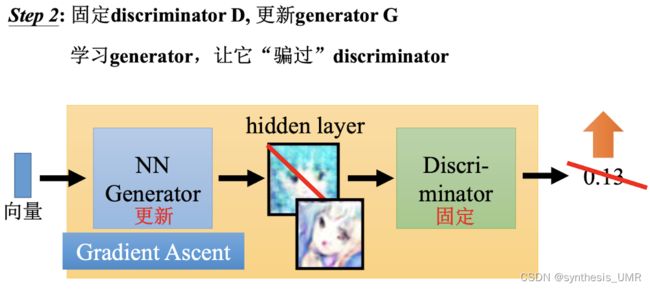
生成的图片我们希望判别器给他打高分,这样就可以进行SGD更新了。

11.3 CGAN 条件GAN
普通GAN网络生成图像和采样图像并不是一一对应关系的。而条件GAN网络会服从于条件train的分布。
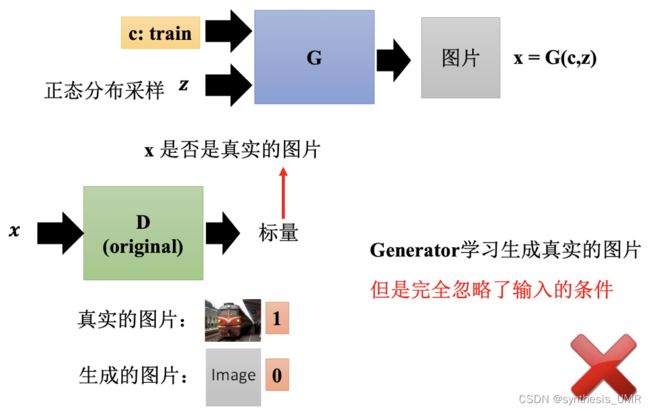
CGAN在训练的时候进行了改进,需要对图片进行文字描述:
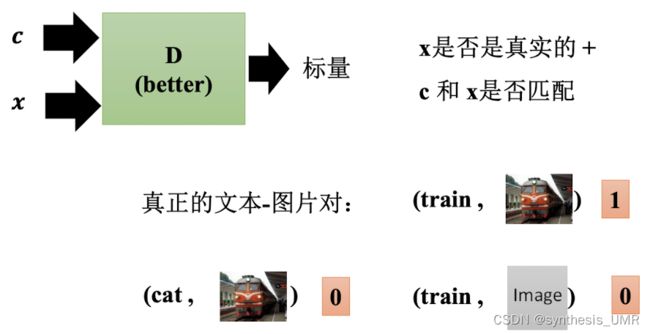
图片和文字对应都是train的才给他1,否则就是0 (train和生成图像;真实火车图像和cat)

对比两种GAN:
因为我们想让损失函数最大化,所以这里用的是梯度上升而非下降。

11.4 变分自编码器VAE
刚才我们学习的GAN是隐式生成模型,接下来是显式的变分自编码器。
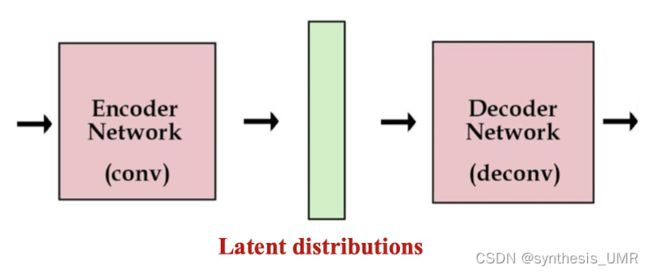
他和自编码器的做法非常相似,首先我们复习一下AE:

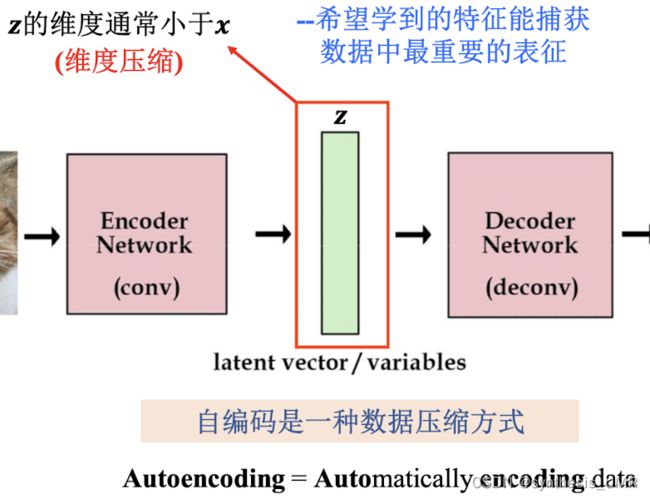
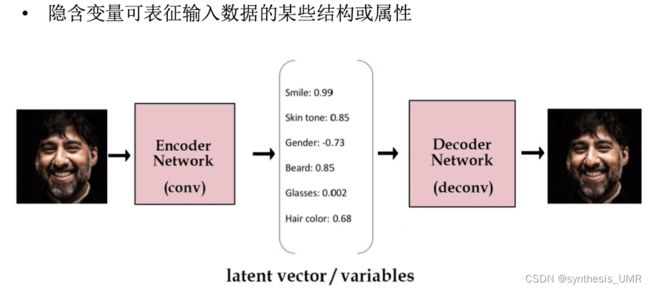
隐含变量z可以表征输入数据的某些结构或者属性:
训练好后,Encoder可以将训练数据映射到一个有效的隐含空间中
我们可以抛开Decoder,将学好的Encoder迁移到其他的任务中。
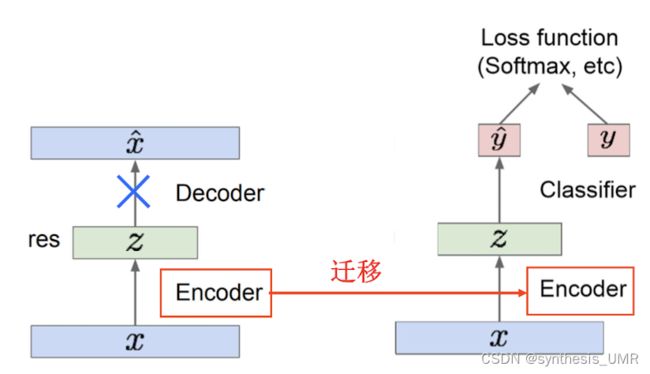
如果我们像GAN一样,能不能通过输入一个随机噪声,让AE自己生成一张图像呢?其实是不行的。因为我们不知道如何创建需要输入的隐变量。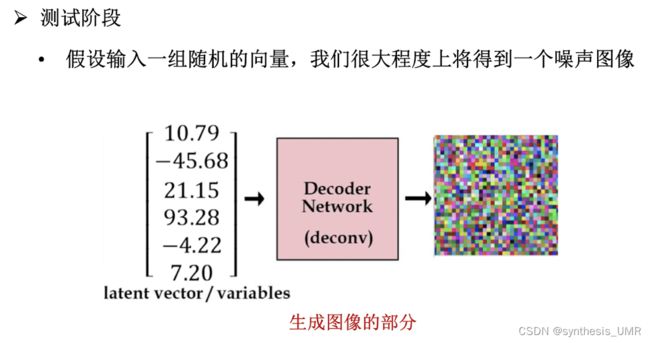
解决方案:我们只要得到一个好的隐变量就可以生成了。
变分自编码器
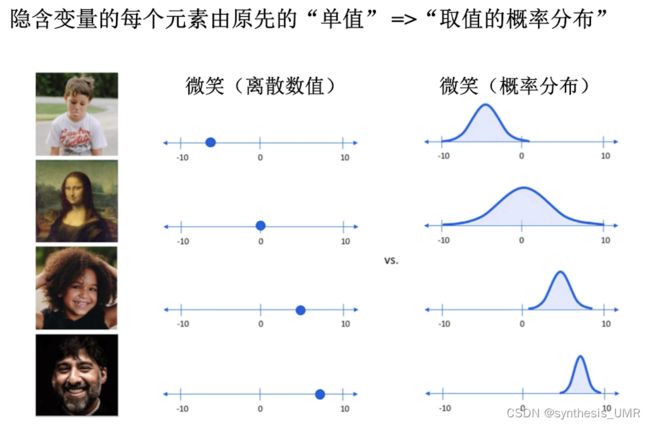
对Encoder增加约束,强制其产生的隐含变量基本服从某种分布。
我们假设隐变量数据服从高斯分布,然后学这些高斯分布的均值和方差。每一个维度都有一组高斯分布:
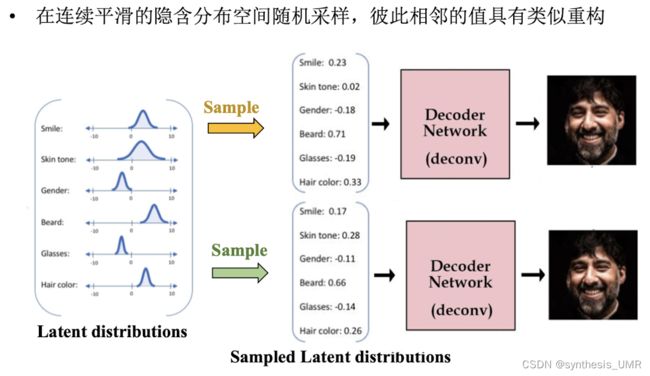
通过调整采样值就可以得到不同图像了。接下来我们看一下具体结构和如何操作: 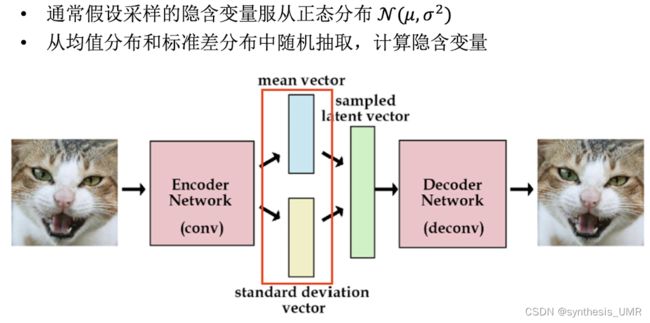
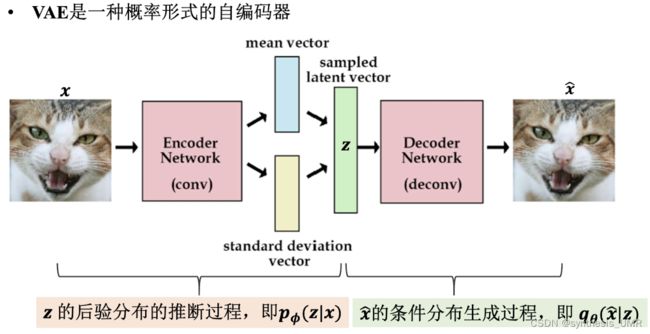
encoder的过程是一个后验概率的过程,给定一个x,算出z的分布。
decoder的情况hi在给定z的条件下x的可能值。
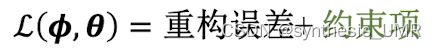
我希望我建模出来的后验概率encoder项尽可能接近先验p(z) 通常假设p(z)服从于0-1高斯分布
这就引出了模型优化的过程:

KL散度度量两个概率分布之间的距离
但是现在又出现了问题,随机采样使得我们的梯度无法向后传递更新(也就是不能进行端到端训练)
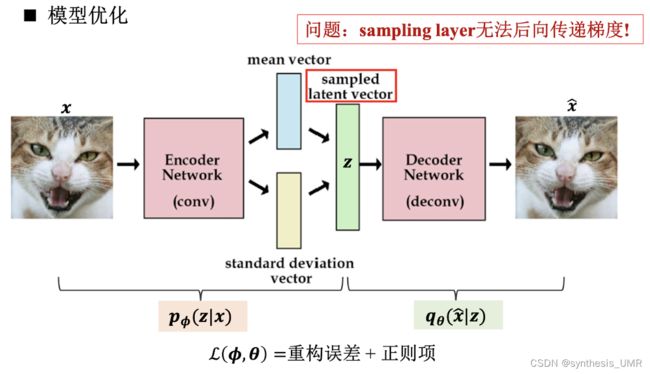
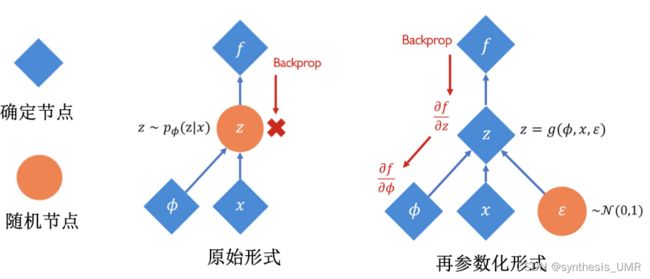
解决方案:进行再参数化Reparameterization Trick
也就是将不连续的过程连续化。用学到的均值和方差对0-1高斯分布进行变换。

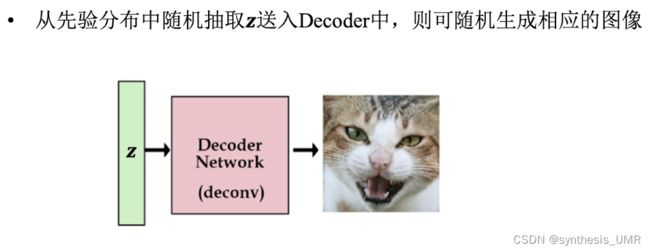
训练完以后就可以进行生成了。我们对于初始的z从一个固定的分布(0-1高斯分布)中采样送入decoder里面就可以生成相应的图像。
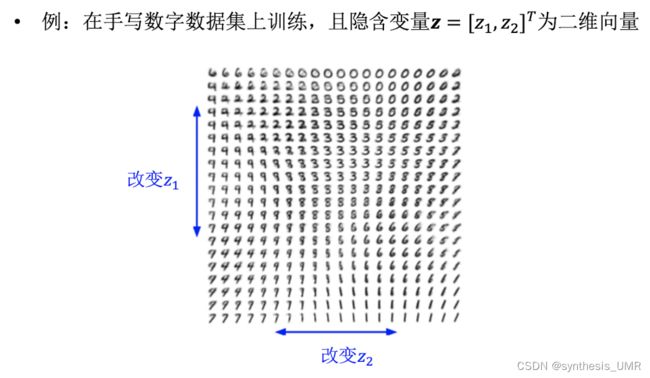
最后来看一下应用:
小结:
隐含变量是对可观测数据的一种压缩表征
通过重构的方法进行无监督学习,可以降低对于数据标注的要求
隐含变量的各维度都对应着可解释的物理含义
自编码器+概率分布估计=生成模型,用于生成新的数据 

深度学习课程到此结束√还有一些自注意力机制之类的以后就要自己学习啦~