多线程编程——基础语法篇
多线程编程
文章目录
- 多线程编程
-
- 一、Thread
-
- 1.1 Thread用法一
- 1.2、Thread用法二 (Runnable)
- 1.3、Thread用法三
- 1.4、Thread用法四
- 1.5、Thread用法五(lambda)
- 二、run 和 start 的区别
- 三、并发编程有何用?
- 四、Thread的方法和属性
- 五、控制线程的具体操作
-
- 5.2、中断线程(让线程结束):
- 5.3、等待线程(join)
- 5.4、获取当前线程的应用
- 5.5、线程的休眠 sleep
- 五、线程的状态
一、Thread
Thread类是java标准库里面的类,表示的是线程,每个创建的Thread实例都是和系统中的一个线程是对应的。
Thread的用法有很多,接下来一一介绍:
1.1 Thread用法一
创建一个子类,继承自Thread,重写Thread中的run方法,run方法内部就包含了这个线程要执行的代码(每个线程都是独立的生产线,要执行一些代码)
// 标准库里提供了一个 Thread 这个类. 就使用这个类来表示线程.
// 这个样子没有真正创建出线程来
class MyThread1 extends Thread {
@Override
public void run() {
System.out.println("hello Thread!!");
}
}
public class Demo1 {
public static void main(String[] args) {
// 真正创建出这个线程要做两步:
// 1、创建 Thread 实例,此处是MyThread1这个实例对象;
MyThread1 t = new MyThread1();
// 2、调用Thread里面的.start() 方法,才是真正在系统内部创建出线程!!
t.start();
}
}
.start() 的方法就会在系统中创建出新的线程出来,新的线程就是会执行子类里面的 run() 方法中的代码。
main 方法本身默认也是会执行出一个线程的(一个进程中不可能有一个线程都没有,至少得有一个线程),以往的代码中,每个代码的main方法,都对应出一个线程来,现在通过 t.start(),又创建出一个新的线程出来。

我们这里也可以在main方法中打印日志看一看他们是否是并发执行的。
class MyThread2 extends Thread {
@Override
public void run() {
while (true) {
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo2 {
public static void main(String[] args) {
// 主线程
MyThread2 t =new MyThread2();
t.start();
while(true) {
System.out.println("hello main!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Thread.sleep(1000); 我们这里用到了sleep这个方法,这里面的方法单位是 ms,sleep操作也可以叫做“休眠”,调用了sleep,该线程就暂时 relax ,不干活,在这休息期间线程也不会占用CPU,不会继续执行后续命令。
为什么使用 sleep 因为 while(true)死循环太快了,电脑吃不消,让两个线程同时休息1秒,再执行,相对来说对电脑要好一点。

有图可知,这两个线程的打印是交替进行的,交替进行也可说明,两个线程是并发执行的。

但是这里面的并发,并不是完全是“交替”,偶尔也会出现,我两条,你一条的情况,或者我一条,你两条的情况。
多线程之间执行的先后顺序,是不能完全确定的。当1秒过后,系统到底该执行那个线程,是不确定的。(这取决于操作系统内部调度代码的具体实现)。如果多个线程之间没有手动的控制先后顺序,那么就会认为多个线程之间执行的是“随机顺序”。这个“随机顺序”特别不稳定,容易出现BUG。
- 给大家推荐一个JDK自带的 jconsole 工具,这个工具更直观的看到两个代码中的线程,在自己的安装的 JDK 的bin目录下。
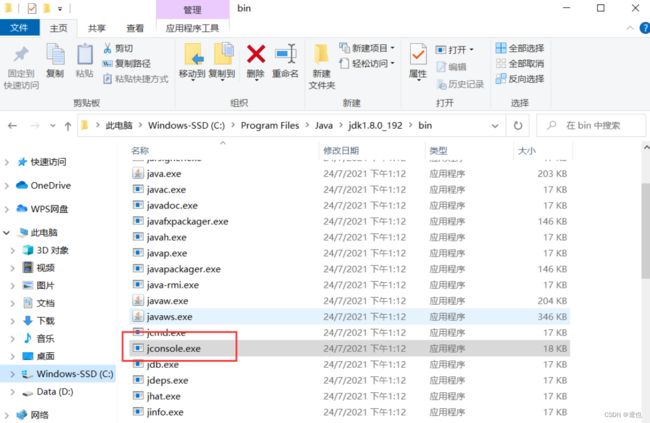
- 用法

1.2、Thread用法二 (Runnable)
创建类,实现 Runnable 接口。Runnable接口也是标准库中自带的一个接口,也是要重写run()方法。
创建 Thread 实例,然后把刚才的 Runnable 实例给 设置进去。
package thread;
class MyRunnable implements Runnable {
@Override
public void run() {
// 描述了任务具体要执行的任务
while (true) {
System.out.println("hello thread!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo3 {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
while(true) {
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
这种写法,是通过 实现 Runnable 实现的,(通过 Runnable 这种方式,相当于把 “要执行的任务” 和 Thread 类,进行分离(解耦合);用法一的写法是 继承 Thread 实现的。
1.3、Thread用法三
这种写法是匿名内部类;
package thread;
public class Demo4 {
// 匿名内部类的方法
public static void main(String[] args) {
// 父类引用指向了子类的对象 -------- 多态
// 创建一个匿名的子类,继承自 Thread 父类
Thread t = new Thread() {
@Override
public void run() {
while(true) {
System.out.println("hello thread!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
while(true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
1.4、Thread用法四
创建了一个Runnable的匿名内部类,匿名内部类中实现 run()方法,描述任务,Thread并创建出实例,直接交给 Thread 来进行使用。
public class Demo5 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
while(true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
1.5、Thread用法五(lambda)
使用 lambda 表达式来使用
public class Demo6 {
public static void main(String[] args) {
// 重写的run()无参
Thread t = new Thread(()->{
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
总结:
1、描述清楚要执行的任务是啥(run()方法)
2、把这个任务给加到一个Thread 实例中,并调用 start 方法。
二、run 和 start 的区别
run() 方法是一个普通的方法,只是会当做普通的方法执行,不会创建出新的线程出来,所以此时就只有一个 main线程,只有等到main线程中的run()方法调用执行完,才会执行第二个循环。
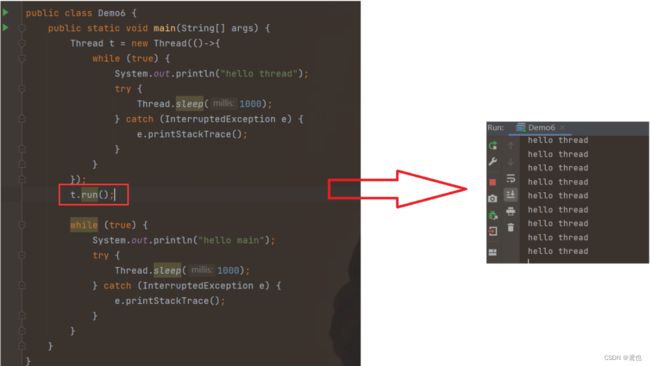
1、start()这个方法,只要一执行就会创建出一个新的线程出来,新线程就会执行run()方法,
2、run()方法自身不具备创建新线程的能力,仍然在旧的线程中执行。
三、并发编程有何用?
并发编程(多线程)最明显的优势,就是针对 ”CPU密集型“ 的程序,能提高效率。
1、”CPU密集型“:程序进行大量的运算
可以理解两个人干活的效率,总比一个人干活的效率高,但是提升的效率也不一定正好是减少 50% ,因为系统中不能保证两个线程是完全 并发 执行的。(尤其是系统资源本身比较紧张的情况下)
所以想要提升速度的话,可以考虑使用多线程进行任务拆分,提高效率。
并发编程追求目标,也就是通过多线程,可以更充分的利用多核CPU的计算资源。
四、Thread的方法和属性
一、 Thread(String name) ,通过 name 是可以给线程取名字的,方便程序员调试,

可以打开 jconsole.exe 工具 confirm 一下,如果不取名字,JVM 默认会给指定的名字,形如 Thread-0,Thread-1…
关于进程的结束:
1、创建出来的是一个 非后台 线程,此时及时 main 线程执行完了,java的进程仍然要继续进行执行,等到所有的 非后台线程执行完,java的进程才会退出。
2、如果一个线程是 后台线程 ,此时后台线程就不会影响到 Java 进程的结束。
二、IsAlive
1、这个属性和方法表示,Thread 变量 t,和操作系统内核中的线程,生命周期不是完全相同的;t被创建出来了,内核里面不一定有对应的线程,必须要通过 t.start() 来调用,才有对应的线程。
2、内核中的线程被销毁了(执行结束),t 不一定销毁, 内核线程的 run 方法执行完,也就结束了,t 要等到 GC 来进行释放。
拿到 t 变量,不能断言出内核里的对应线程也是同样存在的,只有通过 `IsAlive` 就是来判断:
a、true,说明内核的线程在
b、false,内核的线程已经执行完了,或者还没开始执行。
五、控制线程的具体操作
1、创建线程;.start()方法,这个之前就已经讲过了,不再赘述,主要掌握,.start() & run() 方法之间的区别就行。
5.2、中断线程(让线程结束):
run 方法执行完,线程随之就结束了。
方法:(1)、强行终止进程,线程随之也就结束了;(特殊手段)
(2)、手动设置标志位,作为循环判断的条件;
public class Demo7 {
// 通过一个变量来控制线程是否结束
private static boolean isQuit = false;
public static void main(String[] args) {
Thread t = new Thread(()->{
while (!isQuit) {
System.out.println("hell thread!!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isQuit = true;
}
}
这里的 isQuit 是在t 线程读取,main线程修改。
(3)、借助 Thread 实例中自己提供的一个标志位 interrupt() ,不能直接引用标志位的变量,但是可以通过一些方法来进行 读和写的操作
a、通过 Thread 中的 isIntrrupted 方法来判定标志位是否为 true;(true表示线程应该退出)----读操作
b、通过 Thread 中的 interrupt 方法,来把这个标志位设为 true;(表示中断)--------写操作
public class Demo8 {
public static void main(String[] args) {
Thread t = new Thread() {
@Override
public void run() {
// 默认为false
while (!this.isInterrupted()) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
// catch 只是打印出异常,会继续执行,需要break跳出循环,来修改 interrupt 的值
break;
}
}
}
};
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 进行修改,改成true,表示线程中断。
t.interrupt();
}
}

由图可知如果没有加break,只会打印出异常,线程继续执行;
调用 interrupt 方法的时候,如果线程是“就绪状态”,此时是直接修改 线程中的标志位。如果是“阻塞状态”,此时会引起 InterruptedException 异常。
在 t 线程代码中,存在两种情况:
1、执行打印和 while 循环判定。(线程处于“就绪状态”)
2、进行sleep(线程处于“阻塞状态”)
5.3、等待线程(join)
等待指定的线程执行完。
such as:在main线程中,调用 t.join(),那么就是让main来等待 t 这个线程执行完毕。
当调用join() 的时候,就会“阻塞等待”。效果类似于 sleep 。
public class Demo9 {
public static void main(String[] args) {
Thread t = new Thread(()->{
for (int i = 0; i< 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
System.out.println("main方法中 t 线程还没有执行完");
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t 线程执行完了");
}
}
代码执行到join就不再继续往下走了,会进入等待,直到 t 线程执行完 (t线程中的run方法结束),然后join才会继续。

作用:通过 join 可以控制线程结束的先后顺序 (手动控制,谁先谁后),在多线程之间调度的顺序是不确定的(抢占式),这种的不确定性会给代码添加很多的偶然性和随机性,就会让代码出现奇怪的bug。这里的 join 就是手动控制线程执行顺序的一种办法,join 主要是用来控制结束的顺序。
| 方法 | 说明 |
|---|---|
| public void join() | 等待线程结束 |
| public void join(long millis) | 等待线程结束,最多等 millis 毫秒 |
| public void join(long millis, int nanos) | 同理,但可以更高精度 |
这里是带参数和不带参数的 join 方法,不带参数就是“死等”,带参数就是通过参数设置一个等待时间(ms),这个等待时间就表示join最多等多久(超时时间)。
5.4、获取当前线程的应用
在某个线程的代码中,拿到当前这个线程对应的 Thread 对象的引用;拿到这个引用才能做一些后续的操作,很多和线程相关的操作,都是依赖这样的引用。
| 方法 | 说明 |
|---|---|
| public static Thread currentThread(); | 返回当前线程对象的引用 |
1、如果是继承了 Thread 来创建了线程,此时直接在 run 方法中通过 this,就能拿到这个线程的实例。
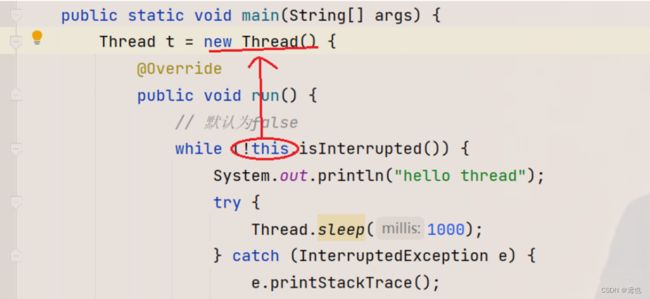
2、但是我们有一个跟常键的方法是使用 Thread 里面的静态方法,currentThread(),上面也有提及,那个线程调用了这个静态的方法,就能够返回那个线程的 Thread 实例引用,这样的获取方法可以在任何方法中使用。
注意:

这里为什么会变红,因为我们是在Runnable方法里面调用的,因此此刻 this 这里指向的是 Runnable,所以就没有 Thread 类里面的方法和属性了
切记自己到底是引用的什么类,不管怎么说都要引用的是 Thread 的实例。
但是我们也有更好的解决方法,那就是使用我们的静态类,currentThread()!!!

此时,虽然run是 Runnable 方法,但是通过 Thread 的 currenThread() 来获取到线程的实例;
Thread.currentThread()
这个方法是在那个线程调用的,就返回那个线程的实例。
5.5、线程的休眠 sleep
调用线程的sleep方法,线程就会进行阻塞等待,等待的时间取决于 sleep 中指定的时间。
在一个进程中会有多个线程,每个线程都对应着一个PCB(不知道PCB是啥,点击这个链接了解),此时进程中就会有一组 PCB,操作系统就是以 PCB 为单位进行调度执行的。
而我们的 PCB 在进程中是以双向链表组织管理的,操作系统调度 PCB 的时候,就是从 就绪队列 中挑出一个 PCB 去CPU 上执行。
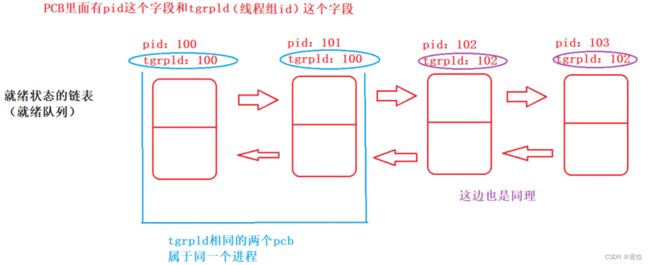
但是 sleep 相当于阻塞了,那么阻塞队列这边就会把就绪队列里面的一个PCB(链表)给移动到阻塞队列里面来,等到sleep等待的时间到了实际成熟了,这个PCB再回到就绪队列中。
区分:
像通过 sleep 产生的阻塞的操作,时机成熟 => 时间到了;
通过 join 产生的阻塞操作,时机成熟 => 对应的线程结束了
这里当sleep的时间到了 PCB 回到就绪队列里面并不会立即在 CPU 上面执行,那么什么时候 CPU 会调用回到就绪队列里面的PCB 就说不准了,因为操作系统调度线程是存在一定的随机性)。
五、线程的状态
线程里面的状态会更详细一些,java也是对线程进行了封装,并且也给出了一些具体的描述,多了解线程的状态是有用的,主要是调试一些多线程程序的时候,会用的上。
public class ThreadState {
public static void main(String[] args) {
for (Thread.State state : Thread.State.values()) {
System.out.println(state);
}
}
}
这段代码就是把java线程里面的所有状态都打印出来, Thread.State 这是一个枚举类型。
- NEW: 安排了工作, 还未开始行动
- RUNNABLE: 可工作的. 又可以分成正在工作中和即将开始工作.
- BLOCKED: 这几个都表示排队等着其他事情
- WAITING: 这几个都表示排队等着其他事情
- TIMED_WAITING: 这几个都表示排队等着其他事情
- TERMINATED: 工作完成了
虽然这上面有很多种状态,但是最关键的还是只有两种 就绪和阻塞 ,java线程的这些状态只是把这两个大类型的状态给细分了,
NEW:把 Thread 对象创建出来了,但是内核里面线程还没有创建出来 (没调用 start 方法)。
TERMINATED:内核里面的线程结束了,然而 Thread 对象还在。
RUNNABLE:就绪状态 (重要的一种状态)
TIMED_WAITING: 通过 sleep 产生的。
BLOCKED:等待锁产生的状态。(这也是阻塞,只不过是锁的阻塞,重要)
WAITING:通过 wait 方法触发,与锁有着密切的联系。(重要)
线程状态之间转换关系图:
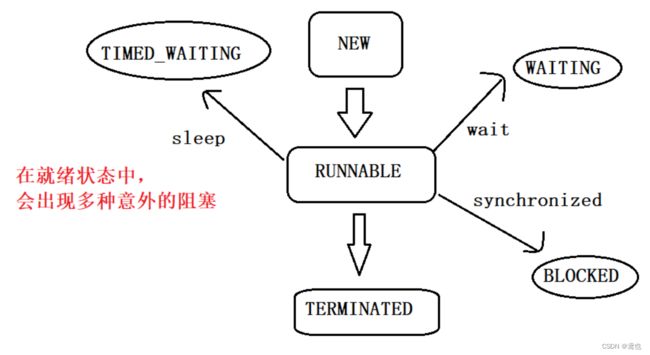
这篇帖子介绍了多线程编程的基本用法和基础概念,都是必掌握,下一篇帖子更重要,关于”线程的安全“ ,这是整个多线程中最重要的关键点!!!
铁汁们,觉得笔者写的不错的可以点个赞哟❤,收藏关注呗,你们支持就是我写博客最大的动力!!!!