数学建模-多元线性回归
文章目录
- 回归的思想
- 回归分析的使命
- 回归分析的分类
- 数据的分类
- 一元线性回归
- 内生性探究
- 核心解释变量和控制变量
- 回归系数的解释
-
- 四类模型回归系数的解释
- 特殊的自变量:虚拟变量X
- 含有交互项的自变量
- 回归实例(Stata)
-
- 描述性统计
- 回归分析
-
- 方差分析表
- 回归系数表及P值
- 标准化回归系数
回归的思想
通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
注意:相关性≠因果性
回归分析的使命
- 识别重要变量(哪些X是同Y真的相关,哪些不是)
- 判断相关性的方向
- 估计权重/回归系数(不同变量之间的相对重要性)
回归分析的分类
| 类型 | 模型 | Y的特点 | 例子 |
|---|---|---|---|
| 线性回归 | OLS、GLS(最小二乘) | 连续数值型变量 | GDP、产量、收入 |
| 0-1回归 | logistic回归 | 二值变量(0‐1) | 是否违约、是否得病 |
| 定序回归 | probit定序回归 | 定序变量 | 等级评定(优良差) |
| 计数回归 | 泊松回归(泊松分布) | 计数变量 | 每分钟车流量 |
| 生存回归 | Cox等比例风险回归 | 生存变量(截断数据) | 企业、产品的寿命 |
数据的分类
| 类型 | 含义 | 例子 | 建模方法 |
|---|---|---|---|
| 横截面数据 | 在某一时点收集的不同对象的数据 | 我们自己发放问卷得到的数据 、全国各省份2018年GDP的数据、大一新生今年体测的得到的数据 | 多元线性回归 |
| 时间序列数据 | 对同一对象在不同时间连续观察所取得的数据 | 从出生到现在,你的体重的数据(每年生日称一次)、中国历年来GDP的数据、在某地方每隔一小时测得的温度数据 | 移动平均、指数平滑、ARIMA、GARCH、VAR、协积 |
| 面板数据 | 横截面数据与时间序列数据综合起来的一种数据资源 | 2008‐2018年,我国各省份GDP的数据 | 固定效应和随机效应、静态面板和动态面板 |
一元线性回归
(参考拟合)
假设 x x x是自变量, y y y是因变量,且满足 y i = β 0 + β 1 x i + μ i y_i=\beta_0+\beta_1x_i+\mu_i yi=β0+β1xi+μi
其中, β 0 \beta_0 β0和 β 1 \beta_1 β1为回归系数, μ i \mu_i μi为无法观测的且满足一定条件的扰动项
令预测值 y i ^ = β 0 ^ + β 1 ^ x i \hat {y_i}=\hat{\beta_0}+\hat{\beta_1}x_i yi^=β0^+β1^xi
其中 β 0 ^ , β 1 ^ = a r g β 0 , β 1 m i n ( ∑ i = 1 n ( y i − y i ^ ) 2 ) \hat{\beta_0},\hat{\beta_1}=\mathop {arg}_{\beta_0,\beta_1}min(\sum_{i=1}^n(y_i-\hat{y_i})^2) β0^,β1^=argβ0,β1min(∑i=1n(yi−yi^)2)
即 β 0 ^ , β 1 ^ \hat{\beta_0},\hat{\beta_1} β0^,β1^使得 y i y_i yi与 y i ^ \hat{y_i} yi^距离之和最小
因为 β 0 ^ , β 1 ^ = a r g β 0 , β 1 m i n ( ∑ i = 1 n ( y i − y i ^ ) 2 ) = a r g β 0 , β 1 m i n ( ∑ i = 1 n ( y i − β 0 ^ − β 1 ^ x i ) 2 ) \hat{\beta_0},\hat{\beta_1}=\mathop {arg}_{\beta_0,\beta_1}min(\sum_{i=1}^n(y_i-\hat{y_i})^2)=\mathop {arg}_{\beta_0,\beta_1}min(\sum_{i=1}^n(y_i-\hat{\beta_0}-\hat{\beta_1}x_i)^2) β0^,β1^=argβ0,β1min(∑i=1n(yi−yi^)2)=argβ0,β1min(∑i=1n(yi−β0^−β1^xi)2)
所以 β 0 ^ , β 1 ^ = a r g β 0 , β 1 m i n ( ∑ i = 1 n ( μ i ^ ) 2 \hat{\beta_0},\hat{\beta_1}=\mathop {arg}_{\beta_0,\beta_1}min(\sum_{i=1}^n(\hat{\mu_i})^2 β0^,β1^=argβ0,β1min(∑i=1n(μi^)2
我们称 μ i ^ = y i − β 0 ^ − β 1 ^ x i \hat{\mu_i}=y_i-\hat{\beta_0}-\hat{\beta_1}x_i μi^=yi−β0^−β1^xi为残差
线性假定并不要求初识模型都呈现 y i = β 0 + β 1 x i + μ i y_i=\beta_0+\beta_1x_i+\mu_i yi=β0+β1xi+μi的严格线性关系,自变量与因变量可通过变量替换而转化成线性模型
y i = β 0 + β 1 ln x i + μ i y_i=\beta_0+\beta_1\ln{x_i}+\mu_i yi=β0+β1lnxi+μi
可以将 ln x i \ln{x_i} lnxi看作一个整体的自变量
ln y i = β o + β 1 ln x i + μ i \ln{y_i}=\beta_o+\beta_1\ln{x_i}+\mu_i lnyi=βo+β1lnxi+μi
可以将 ln y i \ln{y_i} lnyi看作一个整体的因变量
……
注意:使用线性回归模型进行建模前,需要对数据进行预处理。 用Excel、Matlab、Stata等软件都可以
内生性探究
假设 x x x为某产品品质评分(1-10之间), y y y为该产品的销量
如果得到 y i ^ = 3.4 + 2.3 x i \hat {y_i}=3.4+2.3x_i yi^=3.4+2.3xi
- 3.4解释为评分为0时,该产品的平均销量为3.4
- 2.3解释为评分每增加一个单位,该产品的平均销量增加2.3
假设现在有两个自变量, x 1 x_1 x1表示品质评分, x 2 x_2 x2表示该产品的价格, y y y为该产品的销量
如果得到 y i ^ = 5.3 + 0.19 x 1 i − 1.74 x 2 i \hat {y_i}=5.3+0.19x_{1i}-1.74x_{2i} yi^=5.3+0.19x1i−1.74x2i
- 5.3解释为评分为0时,该产品的平均销量为5.3
- 0.19解释为,在保持其他变量不变的情况下,评分每增加一个单位,该产品的平均销量增加0.19
- -1.74解释为,,在保持其他变量不变的情况下,评分每增加一个单位,该产品的平均销量减少1.74
可以发现,当引入新的自变量后,对于回归系数会产生较大影响
(品质评分原本的回归系数为2.3,在加入了产品价格这一变量后,品质评分的回归系数变为0.19)
产生此类现象是因为**遗漏变量导致的内生性**
假设 y = β 0 + β 1 x 1 + β 2 x 2 + … + β k x k + μ y=\beta_0+\beta_1x_1+\beta_2x_2+…+\beta_kx_k+\mu y=β0+β1x1+β2x2+…+βkxk+μ
μ \mu μ为无法观测的且满足一定条件的扰动项,包含了所有与 y y y相关,但未添加到回归模型中的变量
如果误差项 μ \mu μ和所有的自变量 x x x均不相关,则称该回归模型具有外生性,若相关则存在内生性(内生性会导致回归系数估计的不准确,不满足无偏性和一致性)
核心解释变量和控制变量
无内生性要求所有解释变量均与扰动项不想关,这个假定通常太强,因为解释变量一般很多,且需要保证他们全部外生。由此我们可以将解释变量区分为核心解释变量与控制变量两类
- 核心解释变量:我们最感兴趣的变量,因此我们特别希望得到对其系数的一致估计,因此要放入回归方程中
- 控制变量:我们可能对于这些变量本身无太大兴趣,但也将它们放入回归方程是为了“控制住”那些对被解释变量有影响的遗漏因素
实际应用中,只要保证核心解释变量与 μ \mu μ不相关即可
回归系数的解释
y = β 0 + β 1 x 1 + β 2 x 2 + … + β k x k + μ ⇒ y i ^ = β 0 ^ + β 1 ^ x 1 i + β 2 ^ x 2 i + … + β k ^ x k i y=\beta_0+\beta_1x_1+\beta_2x_2+…+\beta_kx_k+\mu\Rightarrow \hat{y_i}=\hat{\beta_0}+\hat{\beta_1}x_{1i}+\hat{\beta_2}x_{2i}+…+\hat{\beta_k}x_{ki} y=β0+β1x1+β2x2+…+βkxk+μ⇒yi^=β0^+β1^x1i+β2^x2i+…+βk^xki
β 0 ^ \hat{\beta_0} β0^的数值意义一般不考虑,因为所有的自变量一般不会同时全为0
β m ^ ( m = 1 , 2 , … , k ) \hat{\beta_m}(m=1,2,…,k) βm^(m=1,2,…,k)表示在控制其他自变量不变的情况下, x m i x_{mi} xmi每增加一个单位,对 y i y_i yi造成的变化
用数学中的偏导数来定义即: β m ^ = ∂ y i ∂ x m i \hat{\beta_m}=\frac {\partial y_i}{\partial x_{mi}} βm^=∂xmi∂yi,因此多元线性回归模型中的回归系数,也常被称为偏回归系数
回归模型 y i ^ = β 0 ^ + β 1 ^ ln x i \hat{y_i}=\hat{\beta_0}+\hat{\beta_1}\ln{x_i} yi^=β0^+β1^lnxi中的 β 1 ^ \hat{\beta_1} β1^怎么解释?
取对数的经验法则:
1、与市场价值相关的,例如,价格、销售额、工资等都可以取对数;
2、以年度量的变量,如受教育年限、工作经历等通常不取对数;
3、比例变量,如失业率、参与率等,取不取均可;
4、变量取值必须是非负数,如果包含0,则可以对 y y y取对数 ln ( 1 + y ) \ln{(1+y)} ln(1+y)
取对数的好处:
1、减弱数据的异方差性
2、如果变量本身不符合正态分布,取 了对数后可能渐近服从正态分布
3、模型形式的需要,让模型具有经济学意义
四类模型回归系数的解释
-
一元线性回归: y = a + b x + μ y=a+bx+\mu y=a+bx+μ, x x x每增加1个单位, y y y平均变化 b b b个单位

-
双对数模型: ln y = a + b ln x + μ \ln{y}=a+b\ln{x}+\mu lny=a+blnx+μ, x x x每增加 1 % 1\% 1%, y y y平均变化 b % b\% b%

-
半对数模型:
-
y = a + b ln x + μ y=a+b\ln{x}+\mu y=a+blnx+μ, x x x每增加 1 % 1\% 1%, y y y平均变化 b 100 \frac {b}{100} 100b个单位

-
ln y = a + b x + μ \ln{y}=a+bx+\mu lny=a+bx+μ, x x x每增加1个单位, y y y平均变化 ( 100 b ) % (100b)\% (100b)%

-
特殊的自变量:虚拟变量X
例如我们要研究性别**(定性变量)**对于工资的影响
y 0 = β 0 + δ 0 F e m a l e i + β 1 x 1 i + β 2 x 2 i + … + β k x k i + μ i y_0=\beta_0+\delta_0Female_i+\beta_1x_{1i}+\beta_2x_{2i}+…+\beta_kx_{ki}+\mu_i y0=β0+δ0Femalei+β1x1i+β2x2i+…+βkxki+μi
F e m a l e i = 1 Female_i=1 Femalei=1表示第 i i i个样本为女性
F e m a l e i = 0 Female_i=0 Femalei=0表示第 i i i个样本为男性
核心解释变量: F e m a l e i Female_i Femalei
控制变量: x m ( m = 1 , 2 , … , k ) x_m(m=1,2,…,k) xm(m=1,2,…,k)
E ( y ∣ F e m a l e = 1 以 及 其 他 自 变 量 给 定 ) = δ 0 ∗ 1 + C E(y|Female=1以及其他自变量给定)=\delta_0*1+C E(y∣Female=1以及其他自变量给定)=δ0∗1+C
E ( y ∣ F e m a l e = 0 以 及 其 他 自 变 量 给 定 ) = δ 0 ∗ 0 + C E(y|Female=0以及其他自变量给定)=\delta_0*0+C E(y∣Female=0以及其他自变量给定)=δ0∗0+C
E ( y ∣ F e m a l e = 1 以 及 其 他 自 变 量 给 定 ) − E ( y ∣ F e m a l e = 0 以 及 其 他 自 变 量 给 定 ) = δ 0 E(y|Female=1以及其他自变量给定)-E(y|Female=0以及其他自变量给定)=\delta_0 E(y∣Female=1以及其他自变量给定)−E(y∣Female=0以及其他自变量给定)=δ0
所以 δ 0 \delta_0 δ0可以解释为:在其他自变量给定的情况下,女性的平均工资与男性的平均工资的差异

多分类的虚拟变量设置
构建模型
S U C C E S S i = α + ∑ β n ∗ P r o v i n c e n + λ ∗ C o n t r o l s i + ϵ i SUCCESS_i=\alpha+\sum\beta_n*Province_n+\lambda*Controls_i+\epsilon_i SUCCESSi=α+∑βn∗Provincen+λ∗Controlsi+ϵi
S U C C E S S i SUCCESS_i SUCCESSi表示第 i i i个借款人是否获得借款
P r o v i n c e n Province_n Provincen是省份的虚拟变量
剔除港澳台三地后,还剩31个省份,其中设置内蒙古为对照组,其余30个省份设置为虚拟变量
(对照组如前例子中的男性,取0,则其余省份前的回归系数就表示与内蒙古的差异)
若第 i i i个样本的借款人来自第 k k k个省份,则 P r o v i n c e k = 1 Province_k=1 Provincek=1,其余 P r o v i n c e i ( i ≠ k ) Province_i(i≠k) Provincei(i=k)全部取0
(如前例子中的女性,取1,其余取0)
若第 i i i个样本的借款人来自内蒙古,则所有的 P r o v i n c e i Province_i Provincei全部取0
为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1
(如前例子,分类男和女两类,引入性别这一个虚拟变量;总共有31个省份,内蒙古为对照组,虚拟变量就引入30个)

含有交互项的自变量

回归实例(Stata)

描述性统计
-
定量数据: s u m m a r i z e 变 量 1 变 量 2... 变 量 n summarize 变量1 变量2 ... 变量n summarize变量1变量2...变量n

-
定性数据: t a b u l a t e 变 量 名 , g e n ( A ) tabulate 变量名,gen(A) tabulate变量名,gen(A)(可以省略 g e n ( A ) gen(A) gen(A))
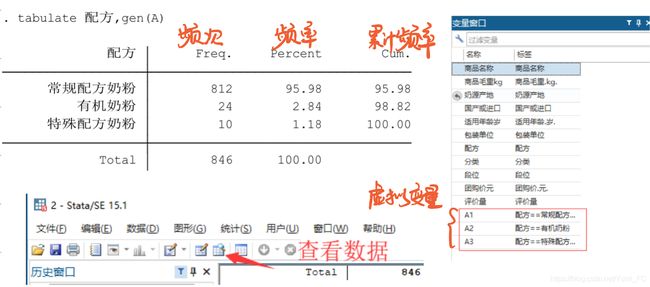
-
变量情况介绍

回归分析
- r e g r e s s y x 1 x 2 … x k regress\ y\ x_1\ x_2\ …\ x_k regress y x1 x2 … xk( S t a t a Stata Stata默认使用OLS普通最小二乘估计法)
回顾:

方差分析表
首先观察P值,判断是否通过了联合显著性检验

注意:论文中一般使用修正的 R 2 R^2 R2,理由**“我们引入的自变量越多,拟合优度会变大。但我们倾向于使用调整后的拟合优度, 如果新引入的自变量对SSE的减少程度特别少,那么调整后的拟合优度反而会减小”**
R a d j u s t e d 2 = 1 − S S E n − k − 1 S S T n − 1 R_{adjusted}^2=1-\Large \frac {\frac {SSE}{n-k-1}}{\frac {SST}{n-1}} Radjusted2=1−n−1SSTn−k−1SSE(k为自变量的个数)
回归系数表及P值
也是首先关注P值,观察有哪些回归系数是显著的,只需要分析显著的因素即可(可以灵活一些,比如若定的置信区间是95%下的,则P值需要小于0.05,;但若定的是90%的,则P值只需要小于0.1)
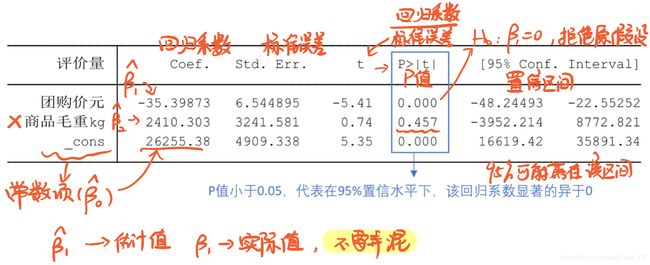
定性变量使用虚拟变量即可,比如 r e g r e s s 评 价 量 A 1 A 2 A 3 regress\ 评价量\ A1\ A2\ A3 regress 评价量 A1 A2 A3。回顾前面虚拟变量的讲解可知,为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1,因此若输入 A 1 A 2 A 3 A1 A2 A3 A1A2A3会有多重共线性问题,但Stata会自动检查并随机选择对照组。
拟合优度 R 2 R^2 R2较低怎么办?
(1)回归分为解释型回归和预测型回归。
预测型回归(可以理解为拟合)一般才会更看重 R 2 R^2 R2。(拟合的 R 2 R^2 R2就希望能够大一些)
解释型回归(即如上例所示,只是探究解释自变量和因变量之间,自变量与自变量之间的关系)更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著性即可。
(2)可以对模型进行调整,例如对数据取对数或者平方后再进行回归。
(3)数据中可能有存在异常值或者数据的分布极度不均匀。
标准化回归系数
上面步骤解决了例题的第一小问,现在解决第二小问,研究影响评价量的重要因素,使用标准化回归系数(去除量纲的影响)
原理:将原始数据减去它的均数后,再除以该变量的标准差,计算得到新的变量值,新变量构成的回归方程称为标准化回归方程,回归后相应可得到标准化回归系数。 标准化系数的绝对值越大,说明对因变量的影响就越大(只关注显著的回归系数哦)
语句: r e g r e s s y x 1 x 2 … x k , b e t a regress\ y\ x_1\ x_2\ …\ x_k,beta regress y x1 x2 … xk,beta(最后加上 b e t a beta beta)

B e t a Beta Beta列即为标准化的回归系数
(1)为什么常数项没有标准化回归系数?
常数的均值是其本身,经过标准化后变成了0.
(2)为啥和之前的回归结果完全相同,除了多了最后那一列标准化回归系数?
对数据进行标准化处理不会影响回归系数的标准误,也不会影响显著性.