分布式事务——分布式事务简介、分布式事务框架 Seata(AT模式、Tcc模式、Tcc Vs AT)、分布式事务—MQ
分布式事务——分布式事务简介、分布式事务框架 Seata(AT模式、Tcc模式、Tcc Vs AT)、分布式事务——MQ
一、分布式事务简介
如果不是分布式环境的话一般不会接触到这种,一旦是微服务这种,分布式事务是必须要处理的一个问题。
1、分布式事务引言和介绍
a、什么是分布式事务

b、分布式事务架构
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数据库资源的访问。

当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。
对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:

如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。

2、分布式相关理论
a、CAP 定理


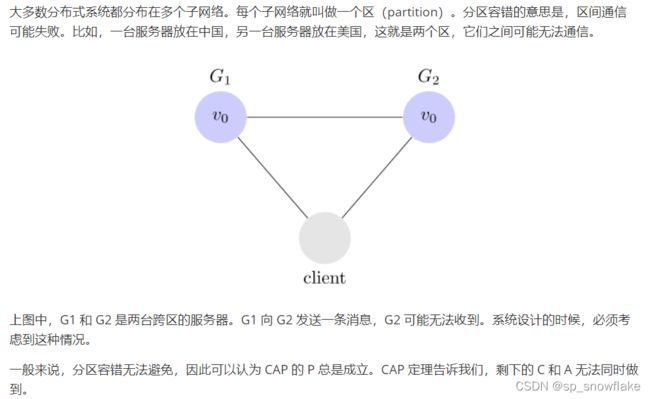
b、分区容错性
分布式系统集群中, 一个机器坏掉不应该影响其他机器
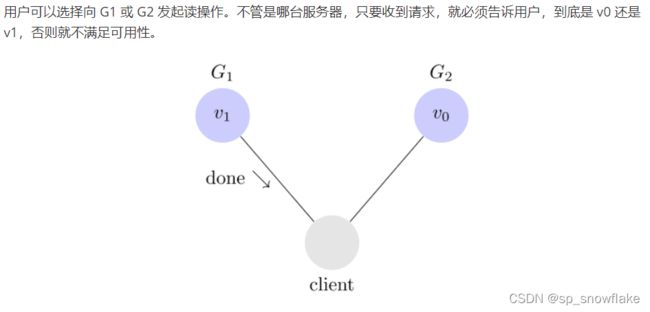
b、可用性
一个请求, 必须返回一个响应, 意思是只要收到用户的请求,服务器就必须给出回应
c、一致性
一定能读取到最新的数据, 意思是,写操作之后的读操作,必须返回该值。

d、 一致性和可用性的矛盾

3、BASE 理论

a、基本可用

b、软状态

c、最终一致性

4、分布式事务解决方案
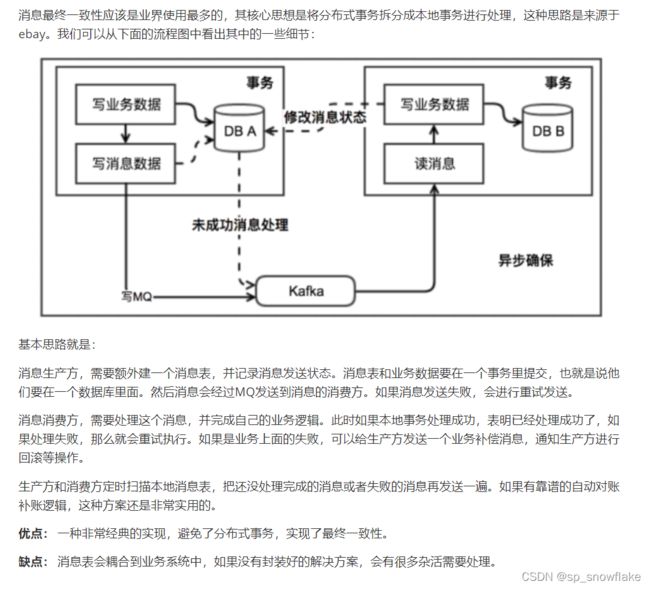
1、通过消息中间件,将分布式事务转为本地事务(技术比较简单,业务比较复杂)
2、Seata:AT、TCC、XA、Saga
对上面的 1 举例子:

在 MQ 搞一个成功队列和失败队列,失败了就回滚。用户服务需要调用到物流服务和订单服务时,就向 MQ 发送一个消息,物流服务和订单服务则监听,有消息了就去消费,成功或者失败都去告诉 MQ。这么一来,用户服务即便要调用到另外两个服务,也不需要在同一个项目中,因为有消息中间件负责传输消息;意味着用户服务无需亲自去调用到数据库即可获取到数据。
a、基于XA协议的两阶段提交(2PC方案)

b、TCC补偿机制

c、消息最终一致性(最多使用)
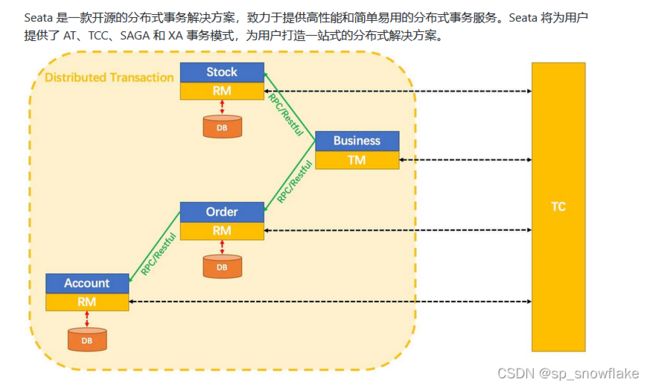
二、分布式事务框架 Seata
1、Seata 介绍


四种模式,
下载地址:https://github.com/seata/seata/releases

下载 Seata Server Docker 镜像和 NacOS Server Docker 镜像令如下 :
[root@localhost ~]# docker pull seataio/seata-server:1.4.0
[root@localhost ~]# docker pull nacos/nacos-server:1.2.0
Seata是什么?
2、Seata 理论概念

三、分布式框架——AT模式
1、AT模式介绍
AT 模式适用前提:
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
.两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
2、前期准备
首先需要修改配置文件:


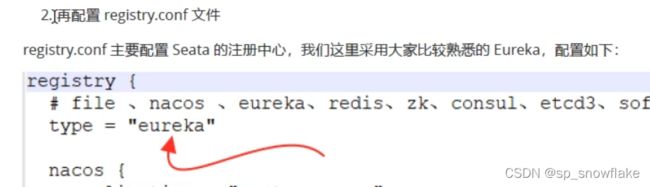
3、了解案例和启动
这个例子就是用户下单的例子,这个例子讲得这些:


启动服务:


4、代码 / 业务理解
由于代码比较多和篇幅关系,这里只作关键部分的代码便于理解,
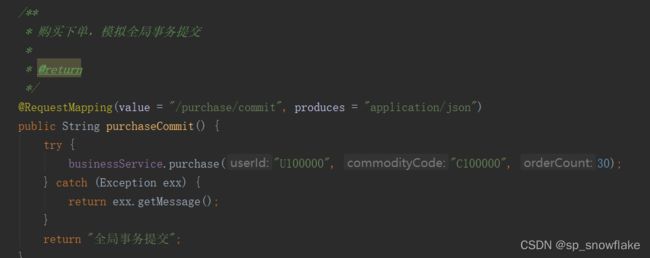
这块代码主要是体现模拟全局事务提交:
这块代码主要是体现模拟全局事务回滚:

全局事务 / 分布式事务 开始:

不记得 TM 的看前面的架构图。
初始化:

判断余额和检查库存:

扣除库存的接口:

但是上图跟上面其他代码不属于同一个项目,意思是调用这个接口,使用了其他项目里面的代码。那么这里是怎么做到的呢?这里使用到了 SpringCloud 里面的工具,这个后面博客再说。这里来看下:

这是一个接口。可以看到这个工具有指定接口和 url,很明显猜得到是通过这个工具,A 项目才能使用到 B项目里面的代码,再来看看:
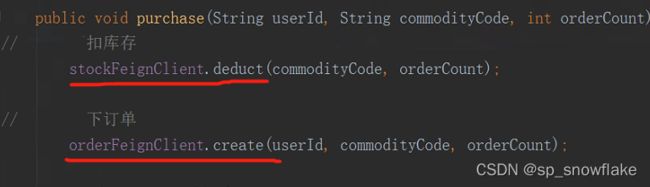
这两个调用就是调用到了其他项目的代码了。关于这块地方就不详细讲了,只需要大概了解到是通过这些方式调用了其他项目的功能即可。详细的后面的博客介绍到 SpringCloud 的时候会说到。
到此为止就基本介绍完了,其实还是互相调用。
5、反向补偿
在执行插入或者更新操作以前,会先把这条记录记下来,看看数据库:

这里会把修改前和修改后的记录都记下来,如果成功提交了,会把刚才记录下来的日志给删除了。如果要回滚,会自动根据之前的状态,生成语句,再把数据改回去。所以这里所说的回滚其实是又执行了一条语句,把数据再改回去。而不是以前讲的那种回滚,把数据复原。这种回滚就叫反向补偿。
这里来尝试查看这里的日志是什么:
先看这两个 id:这里 xid 代表的是全局事务 ID,前面的 branch_id 代表的是分支事务 ID,代表各自事务的 ID。那么这里的 xid 是同一个,说明这三个分支事务是同属于同一个全局事务的。

再看下 rollback_info,其实里面都是 json 数据,来解析看看里面的数据:
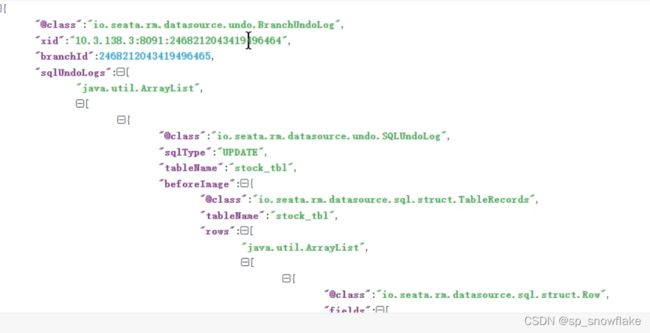
主要看这两处:
before_image :修改前的镜像

after_image :修改后的镜像:
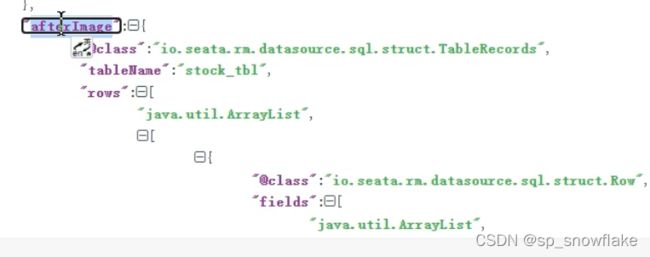
这里面的数据记录了改之前和改之后的数据,就是根据这些数据生成的语句,来完成回滚。
6、实现原理
稍微来说下 Seata 中这个分布式事务的原理,先来看一张图:
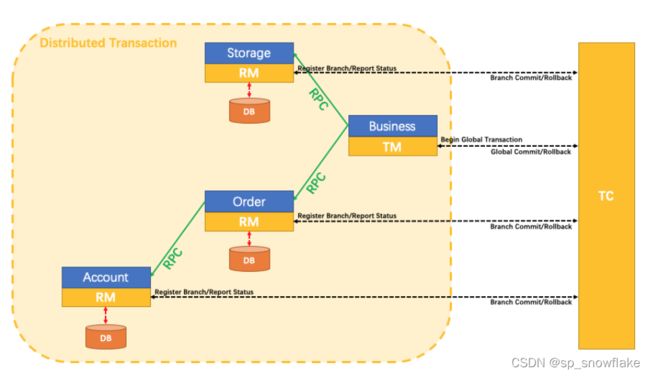
这张图非常清晰的描述了上面的案例,大致流程如下:
- 有三个概念:TM、RM、TC,这些前面已经介绍过了,这里就不再赘述。
- 首先由 Business 开启全局事务。
- 接下来 Business 在调用 Storage 和 Order 的时候,这两个在数据库操作之前都会向 TC 注册一个分支事务并提交。
- 分支事务在操作时,都会向 undo_log 表中提交一条记录,当全局事务提交的时候会清空undo_log 表中的记录,否则将以该表中的记录为依据进行反向补偿(将数据恢复原样)。具体到上面的案例,事务提交分两个阶段,过程如下:
一阶段:
- 首先 Business 开启全局事务,这个过程中会向 TC 注册,然后会拿到一个 xid,这是一个全局事务id。
- 接下来在 Business 中调用 Storage 微服务。
- 来解析 SQL:得到 SQL 的类型(UPDATE),表(storage_tbl),条件(wherecommodity_code = ‘C100000’)等相关的信息。
- 查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
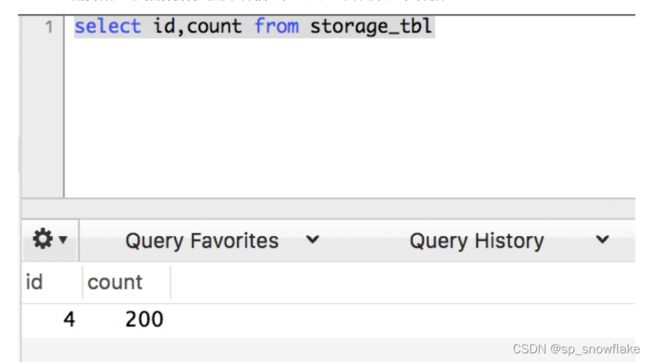
5. 执行业务 SQL,也就是做真正的数据更新操作。
6. 查询后镜像:根据前镜像的结果,通过主键定位数据

7. 插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到UNDO_LOG 表中。
![]()
branch_id 和 xid 分别表示分支事务(即 Storage 自己的事务)和全局事务的 id,rollback_info 中保存着前后镜像的内容,这个将作为反向补偿(回滚)的依据,这个字段的值是一个 JSON,挑出来这个 JSON 中比较重要的一部分来讲解下:
beforeImage:这个是修改前数据库中的数据,可以看到每个字段的值,id 为 4,count 的值为200。
afterImage:这个是修改后数据库中的数据,可以看到,此时 id 为 4,count 的值为 170。
7、小结
AT 模式最显著的特征就是会把数据库修改之前的状态记录下来,回滚会自动回滚。
四、分布式框架——Tcc 模式
1、了解 Tcc 模式
TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
Tcc 模式跟上面不同,主要是把转账分成了两个阶段,且数据库多了个冻结金额的字段。把扣钱作为一阶段操作,加钱作为二阶段操作。
整体机制:
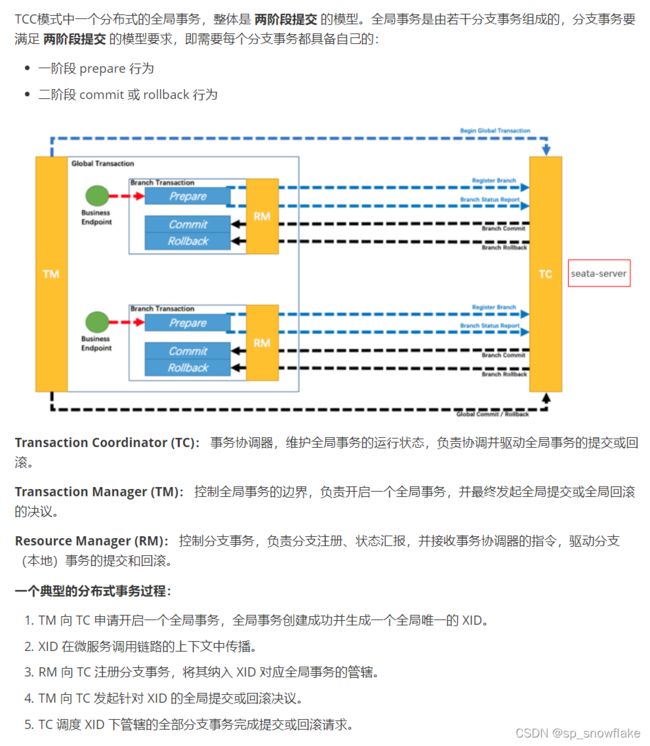
2、大致业务流程
先来说一下这个案例的业务逻辑,然后我们再来看代码,他的流程是这样的:
-
这个项目分两部分,provider 和 consumer(要是只有一个项目也就不存在分布式事务问题了)。
-
provider 中提供两个转账相关的接口,一个是负责处理扣除账户余额的接口,另一个则是负责给账户添加金额的接口。在该案例中,这两个项目中由一个 provider 提供,在实际操作中,小伙伴们也可以用两个 provider 来分别提供这两个接口。
-
provider 提供的接口通过 dubbo 暴露出去,consumer 则通过 dubbo 来引用这些暴露出来的接口。
-
转账操作分两步:首先调用 FirstTccAction 从一个账户中减除金额;然后调用 SecondTccAction给一个账户增加金额。两个操作要么同时成功,要么同时失败。有人可能会说,都是 provider 提供的接口,也算分布式事务?算!当然算!虽然上面提到的两个接口都是 provider 提供的,但是由于这里存在两个数据库,不同接口操作不同的数据库,所以依然是分布式事务。
这是这个项目大致上要做的事情。
3、官方案例解析

回滚逻辑需要自己写。
提交跟回滚的方法名可以随意取,因为并不是调用方法完成的操作,而是通过注解来完成,看下图:
FirstTccAction:
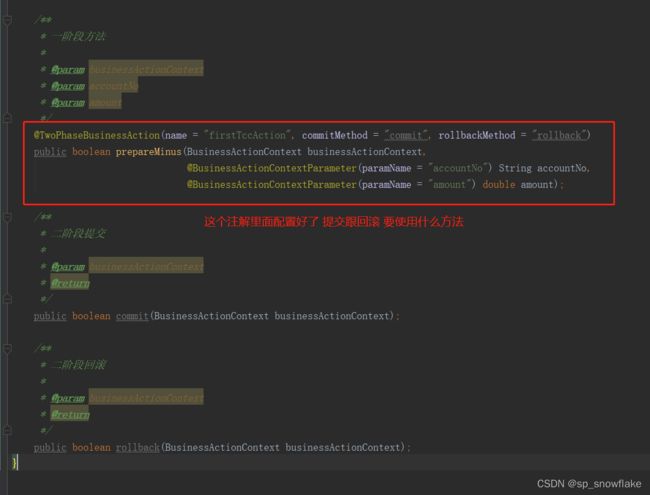
通过调用 prepareMinus 这个方法就会判断那两个转账的方法是否执行成功,成功了就自动提交,否则回滚。
接着继续往下看:
4、扣钱参与者实现

a、一阶段准备,冻结 转账资金

b、二阶段提交
首先先要提示这个地方:

再看后续代码:

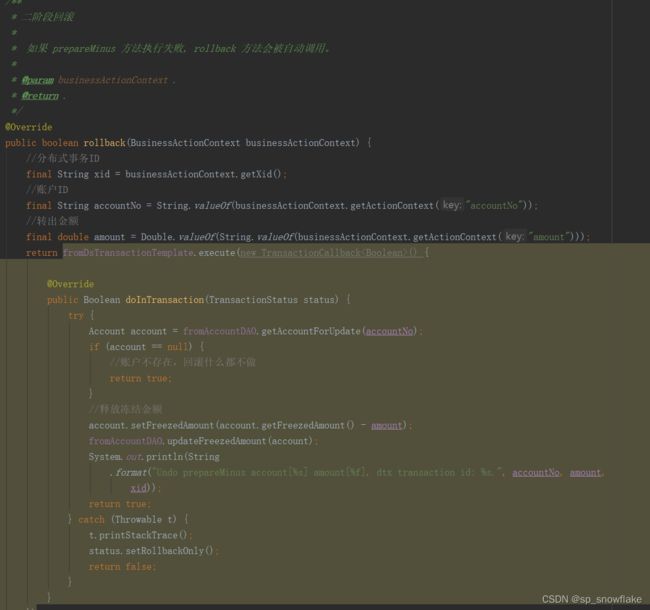
c、二阶段回滚
如果执行失败就会触发回滚方法,回滚也没有什么特别的,无非就是恢复账户:
5、加钱参与者实现
这里就跟上面差不多了。
a、一阶段准备
主要还是判断账户,然后把要转入的钱先加入到冻结金额中,然后更新账户信息;没了。

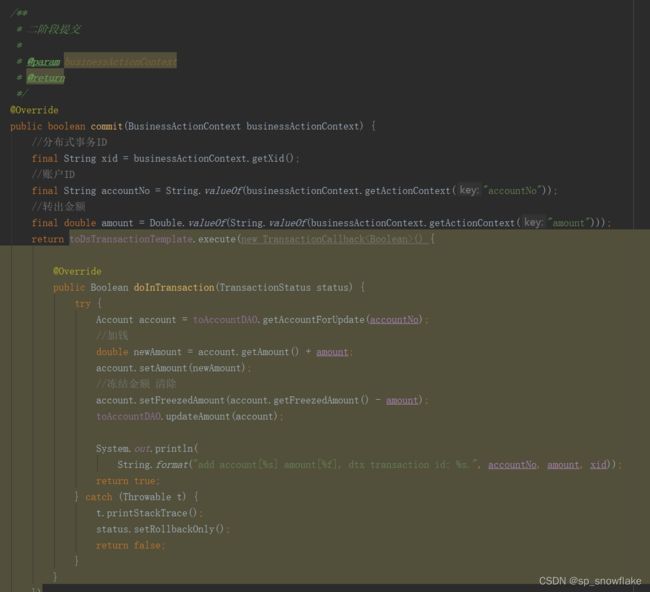
b、二阶段提交
跟扣钱的差不多:
c、二阶段回滚

6、调用流程
启动的过程就不放出来了。
接着来看怎么调用:
TransferApplication:
这里有两个 demo,先看一下执行成功的 demo:

执行转账操作:

然后来看下转账服务(可以看到方法上面有开启全局事务注解):

7、设计经验
a、允许空补偿
空补偿就是原服务未执行,结果补偿服务执行了,当原服务出现超时、丢包等情况时或者在收到原服务请求之前先收到补偿请求,就可能会出现空补偿。
因此我们在服务设计时需要允许空补偿, 即没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来,这也是案例中,无论是原服务还是补偿服务都有 businessKey 参数的原因。
b、防悬挂控制
悬挂就是补偿服务比原服务先执行,出现的原因和前面说的差不多,所以我们需要在执行原服务时,要先检查一下当前业务主键是否已经在空补偿记录下来,如果已经被记录下来,说明补偿已经先执行了,此时我们可以停止原服务的执行。
c、幂等控制
原服务与补偿服务都需要保证幂等性, 由于网络可能超时, 所以我们可能会设置重试策略,重试发生时要通过幂等控制,避免业务数据重复更新。如何保证幂等性这里就不再赘述了。
d、缺乏隔离性的应对
由于 Saga 事务不保证隔离性, 在极端情况下可能由于脏写无法完成回滚操作。
举一个极端的例子, 分布式事务内先给用户 A 充值, 然后给用户 B 扣减余额, 如果在给 A 用户充值成功,在事务提交以前, A 用户把余额消费掉了, 如果事务发生回滚, 这时则没有办法进行补偿了。这就是缺乏隔离性造成的典型的问题。
对于这种问题,我们可以通过如下方式来尝试解决:
业务流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
有些业务场景可以允许让业务最终成功, 在回滚不了的情况下可以继续重试完成后面的流程, 所以状态机引擎除了提供“回滚”能力还需要提供“向前”恢复上下文继续执行的能力, 让业务最终执行成功, 达到最终一致性的目的。
e、性能优化
配置客户端参数 client.rm.report.success.enable=false,可以在当分支事务执行成功时不上报分支状态到 server,从而提升性能。当上一个分支事务的状态还没有上报的时候,下一个分支事务已注册,可以认为上一个实际已成功
8、小结
来小结一下上面的转账逻辑:
- 首先注入刚刚的 FirstTccAction 和 SecondTccAction,如果这是一个微服务项目,那就在这里把各自的 Feign 搞进来。
- transfer 方法就执行具体的转账逻辑,该方法加上 @GlobalTransactional 注解。这个方法中主要是去调用 prepareXXX 完成一阶段的事情,如果一阶段出问题了,那么就会抛出异常,则事务会回滚(二阶段),回滚就会自动调用 FirstTccAction 和 SecondTccAction 各自的 rollback 方法(反向补偿);如果一阶段执行没问题,则二阶段就调用 FirstTccAction 和 SecondTccAction 的commit 方法,完成提交。
这就是大致的转账逻辑。
五、TCC Vs AT
经过上面的分析,相信小伙伴们对 TCC 已经有一些感觉了。
那么什么是 TCC?TCC 是 Try-Confirm-Cancel 英文单词的简写。
在 TCC 模式中,一个事物是通过 Do-Commit/Rollback 来实现的,开发者需要给每一个服务间调用的操作接口,都提供一套 Try-Confirm/Cancel 接口,这套接口就类似于我们上面的prepareXXX/commit/rollback 接口。
再举一个简化的电商案例,用户支付完成的时候由先订单服务处理,然后调用商品服务去减库存,这两个操作同时成功或者同时失败,这就涉及到分布式事务了:在 TCC 模式下,我们需要 3 个接口。首先是减库存的 Try 接口,在这里,我们要检查业务数据的状态、检查商品库存够不够,然后做资源的预留,也就是在某个字段上设置预留的状态,然后在 Confirm 接口里,完成库存减 1 的操作,在 Cancel接口里,把之前预留的字段重置(预留的状态其实就类似于前面案例的冻结资金字段freezed_amount )。
为什么搞得这么麻烦呢?分成三个步骤来做有一个好处,就是在出错的时候,能够顺利的完成数据库重置(反向补偿),并且,只要我们 prepare 中的逻辑是正确的,那么即使 confirm 执行出错了,我们也可以进行重试。
来看下面一张图:

根据两阶段行为模式的不同,我们将分支事务划分为 Automatic (Branch) Transaction Mode 和 TCC(Branch) Transaction Mode。
AT 模式基于支持本地 ACID 事务的关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用自定义的 prepare 逻辑。
- 二阶段 commit 行为:调用自定义的 commit 逻辑。
- 二阶段 rollback 行为:调用自定义的 rollback 逻辑。
所谓 TCC 模式,是指支持把自定义的分支事务纳入到全局事务的管理中。
回顾前面的案例,可以发现,分布式事务两阶段提交,在 TCC 中,prepare、commit 以及rollback 中的逻辑都是我们自己写的,因此说 TCC 不依赖于底层数据资源的事务支持。
相比于 AT 模式,TCC 需要我们自己实现 prepare、commit 以及 rollback 逻辑,而在 AT 模式中,commit 和 rollback 都不用我们去管,Seata 会自动帮我们完成。
八、分布式事务——MQ
Seata 对于分布式事务的处理,代码虽然简单,但是内部花费在网络上的时间消耗太多了,在高并发场景下,这似乎并不是一种很好的解决方案。
要说哪种分布式事务处理方案效率高,必然绕不开消息中间件!基于消息中间件的两阶段提交方案,通常用在高并发场景下。这种方式通过牺牲数据的强一致性换取性能的大幅提升,不过实现这种方式的成本和复杂度是比较高的,使用时还要看实际业务情况。
1、思路分析
先来说说整体思路。
有一个名词叫做消息驱动的微服务,相信很多小伙伴都听说过。怎么理解呢?
在微服务系统中,服务之间的互相调用,我们可以使用 HTTP 的方式,例如 OpenFeign,也可以使用RPC 的方式,例如 Dubbo,除了这些方案之外,我们也可以使用消息驱动,这是一种典型的响应式系统设计方案。
在消息驱动的微服务中,服务之间不再互相直接调用,当服务之间需要通信时,就把通信内容发送到消息中间件上,另一个服务则通过监听消息中间件中的消息队列,来完成相应的业务逻辑调用,过程就是这么个过程,并不难,具体怎么弄,我们继续往下看。
2、业务分析
先明确一点,这里的售票并不是卖一张少一张,而是卖一张票数据库就多一行记录;因为这些票的信息后续还会用到,比如票的座位等等。
首先我们来看如下一张流程图,这是一个用户购票的案例:

当用户想要购买一张票时:
- 向新订单队列中写入一条数据。
- Order Service 负责消费这个队列中的消息,完成订单的创建,然后再向新订单缴费队列中写入一条消息。
- User Service 负责消费新订单缴费队列中的消息,在 User Service 中完成对用户账户余额的划扣,然后向新订单转移票队列中写入一条消息。
- Ticket Service 负责消费新订单转移票队列,在 Ticket Service 中完成票的转移,然后发送一条消息给订单完成队列。
- 最后 Order Service 中负责监听订单完成队列,处理完成后的订单。
这就是一个典型的消息驱动微服务,也是一个典型的响应式系统。在这个系统中,一共有三个服务,分别是:
Order Service
User Service
Ticket Service
这三个服务之间不会进行任何形式的直接调用,大家有事都是直接发送到消息中间件,其他服务则从消息中间件中获取自己想要的消息然后进行处理。
具体到我们的实践中,则多了一个检查票是否够用的流程,如下图:

创建订单时,先由 Ticket 服务检查票是否够用,没问题的话再继续发起订单的创建。其他过程我就不说了。
再提醒一遍,在售票系统中,由于每张票都不同,例如每张票可能有座位啥的,因此一张票在数据库中往往是被设计成一条记录。
3、准备(只展示部分核心)
a、准备数据库
首先我们准备三个数据库,分别是:
javaboy_order:订单库,用户创建订单等操作,在这个数据库中完成。
javaboy_ticket:票务库,这个库中保存着所有的票据信息,每一张票都是一条记录,都保存在这个库中。
javaboy_user:用户库,这里保存着用户的账户余额以及付款记录等信息。
每个库中都有各自对应的表,为了操作方便,这些表不用自己创建,将来等项目启动了,利用 JPA 自动创建即可。
b、项目概览

一共有五个服务:
- eureka:注册中心
- order:订单服务
- service:公共模块
- ticket:票务服务
- user:用户服务
c、注册中心
话说,都消息驱动了,还要注册中心干嘛?
消息驱动没错,消息驱动微服务之后每个服务只管把消息往消息中间件上扔,每个服务又只管消费消息中间件上的消息,这个时候对于服务注册中心似乎不是那么强需要。不过在我们这个案例中,消息驱动主要用来处理事务问题,其他常规需求我们还是用OpenFeign 来处理,所以这里我们依然需要一个注册中心。
这里的注册中心就选择常见的 Eureka,省事一些。
服务注册中心的创建记得加上 Spring Security,将自己的服务注册中心保护起来。
这块有一个小小的细节多说两句:
Eureka 用 Spring Security 保护起来之后,以后其他服务注册都是通过 Http Basic 来认证,所以我们要在代码中开启 Http Basic 认证,如下(以前旧版本不需要下面这段代码,但是新版本需要):

4、开始走一遍代码
a、新订单处理
当用户发起一个购票请求后,这个请求发送到 order 服务上,order 服务首先会向 order:new 队列发送一条消息,开启一个订单的处理流程。代码如下:

上面设置的 UUID 是整个订单在处理过程中的一个唯一标志符,也算是一条主线。
order:new 队列中的消息将被 ticket 服务消费,ticket 服务消费 order:new 中的消息,并进行锁票操作(锁票的目的防止有两个消费同时购买同一张票),锁票成功后,ticket 服务将向 order:locked 队列发送一条消息,表示锁票成功;否则向 order:fail 队列发送一条消息表示锁票失败。这里的 OrderDTO 对象将贯穿整个购票过程。
b、锁票
锁票操作是在 ticket 服务中完成的,代码如下:

先调用 lockTicket 方法去数据库中锁票,所谓的锁票就是将要购买的票的 lock_user 字段设置为customer_id(购买者的 id)。
如果锁票成功(即数据库修改成功),设置 msg 的状态为 TICKET_LOCKED ,同时发送消息到order:locked 队列,表示锁票成功。
如果锁票失败(即数据库修改失败),设置 msg 的状态为 TICKET_LOCK_FAIL ,同时发送消息到order:fail 队列,表示锁票失败。
c、如果锁票成功
接下来,由 order 服务消费 order:locked 队列中的消息,也就是锁票成功后接下来的操作。

锁票成功后,先根据订单的 UUID 去订单数据库查询,是否已经有订单记录了,如果有,说明这条消息已经被处理了,可以防止订单的重复处理(这块主要是解决幂等性问题)。
如果订单还没有被处理,则创建一个新的订单对象,并保存到数据库中,创建新订单对象的时候,需要设置订单的 status 为 NEW。
最后设置 msg 的 status 为 NEW,然后向 order:pay 队列发送一条消息开启付款流程,付款是由user 服务提供的。user 服务中会检查用户的账户余额是否够用,如果不够用,就会发送消息到order:ticket_error 队列,表示订票失败;如果余额够用,则进行正常的付款操作,并在付款成功后发送消息到 order:ticket_move 队列,开启票的转移。
(1)缴费(包含付款失败和成功)
锁票成功后,接下来就是付费了,付费服务由 user 提供。

这里的执行步骤如下:
- 首先根据订单 id 去查找付款信息,检查当前订单是否已经完成付款,如果已经完成服务,则直接return,这一步也是为了处理幂等性问题。
- 根据顾客的 id,查找到顾客的完整信息,包括顾客的账户余额。
- 检查顾客的账户余额是否足够支付票价,如果不够,则设置 msg 的 status 为NOT_ENOUGH_DEPOSIT,同时向 order:ticket_error 队列发送消息,表示订票失败。
- 如果顾客账户余额足够支付票价,则创建一个 PayInfo 对象,设置相关的支付信息,并存入pay_info 表中。
- 调用 charge 方法完成顾客账户余额的扣款。
- 发送消息到 order:ticket_move 队列中,开启交票操作。
如果付款成功:

接着就是交票环节。
(2)交票

调用 moveTicket 方法完成交票操作,也就是设置 ticket 表中票的 owner 为 customerId。交票成功后,发送消息到 order:finish 队列,表示交票完成。
(3)订单完成
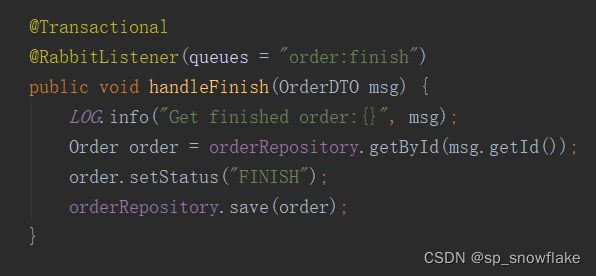
这里的处理就比较简单,订单完成后,就设置订单的状态为 FINISH 即可。
上面介绍的是一条主线,顺利的话,消息顺着这条线走一遍,一个订单就处理完成了。
不顺利的话,就有各种幺蛾子。
d、如果锁票失败
锁票是在 ticket 服务中完成的,如果锁票失败,就会直接向 order:fail 队列发送消息,该队列的消息由 order 服务负责消费。
(1)扣款失败
扣款操作是在 user 中完成的,扣款失败就会向 order:ticket_error 队列中发送消息,该队列的消息由 ticket 服务负责消费。

当扣款失败的时候,做三件事:
- 撤销票的转移,也就是把票的 owner 字段重新置为 null。
- 撤销锁票,也就是把票的 lock_user 字段重新置为 null。
- 向 order:fail 队列发送订单失败的消息
(2)下单失败
下单失败的处理在 order 服务中,有三种情况会向 order:fail 队列发送消息:
- 锁票失败
- 扣款失败(客户账户余额不足)
- 订单超时
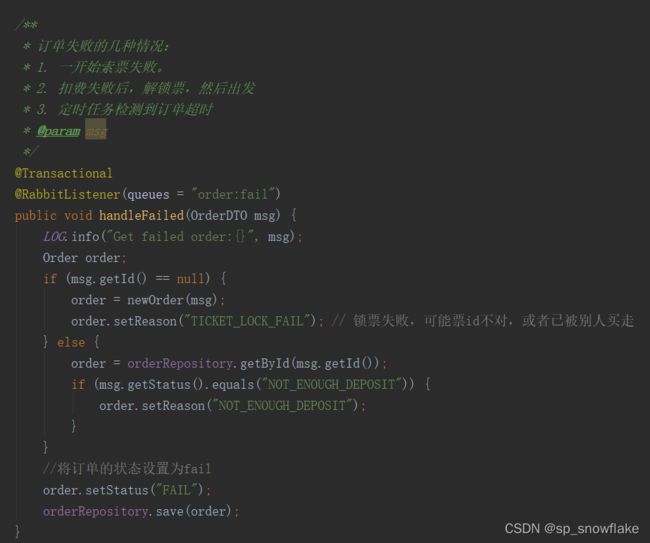
该方法的具体处理逻辑如下:
- 首先查看是否有订单 id,如果连订单 id 都没有,就说明是锁票失败,给订单设置 reason 属性的值为 TICKET_LOCK_FAIL 。
- 如果有订单 id,则根据 id 查询订单信息,并判断订单状态是否为 NOT_ENOUGH_DEPOSIT ,这个表示扣款失败,如果订单状态是 NOT_ENOUGH_DEPOSIT ,则设置失败的 reason 也为此。
- 最后设置订单状态为 FAIL,然后更新数据库中的订单信息即可。
(3)订单超时
order 服务中还有一个定时任务,定时去数据库中捞取那些处理失败的订单,如下:
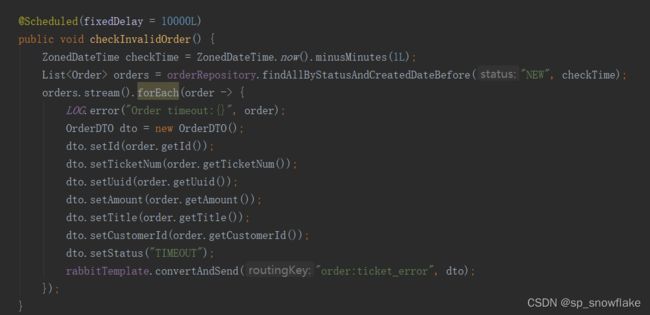 可以看到,这里是去数据库中捞取那些状态为 NEW 并且是 1 分钟之前的订单,根据前面的分析,当锁票成功后,就会将订单的状态设置为 NEW 并且存入数据库中。换言之,当锁票成功一分钟之后,这张票还没有卖掉,就设置订单超时,同时向 order:ticket_error 队列发送一条消息,这条消息在ticket 服务中被消费,最终完成撤销交票、撤销锁票等操作。
可以看到,这里是去数据库中捞取那些状态为 NEW 并且是 1 分钟之前的订单,根据前面的分析,当锁票成功后,就会将订单的状态设置为 NEW 并且存入数据库中。换言之,当锁票成功一分钟之后,这张票还没有卖掉,就设置订单超时,同时向 order:ticket_error 队列发送一条消息,这条消息在ticket 服务中被消费,最终完成撤销交票、撤销锁票等操作。
5、总结
整体上来说,上面这个案例,技术上并没有什么难的,复杂之处在于设计。一开始要设计好消息的处理流程以及消息处理失败后如何进行补偿,这个是比较考验大家技术的。
另外上面案例中,消息的发送和消费都用到了 RabbitMQ 中的事务机制(确保消息消费成功)以及Spring 中的事务机制(确保消息发送和数据保存同时成功),这些就不再赘述了。
总之,通过消息中间件处理分布式事务,这种方式通过牺牲数据的强一致性换取性能的大幅提升,但是实现这种方式的成本和复杂度是比较高的,使用时还要看实际业务情况。