MySQL——DQL(数据库查询语言)sql8.0版上
文章目录
- 查询结果的处理
- 使用函数对查询结果的处理
-
- 单行函数
-
- 字符函数
- 逻辑函数
- 数学函数
- 日期函数
- 分组函数
-
- 条件查询
- 模糊查询
- UNION 和UNION ALL语法
- 对查出的数据进行排序和数量限制
- 分组查询
- 子查询和关联查询
DQL(Data Query Language)数据查询语言
数据查询语句是使用频率最高的一个操作,是可以从一个表中查询数据,也可以从多张表中进行关联查询数据。
基础语法:
SELECT 查询列表 FROM 表名 [WHERE 条件];
特点:
查询列表可以是:表中的字段、常量、表达式、函数
查询的结果是一个虚拟出的表格。
查询结果的处理
- 查询常量值(了解一下就行了,没啥用)
SELECT 100;

- 查询表达式
在SQL中可用的表达式有: +、-、*、/
SELECT 100*2
SELECT 列+5 FROM 表;
--例如:
SELECT height+5 FROM t_student;
--给查出的每一列数据都加上一个5

- 查询函数
SELECT 函数;
-- 例如:
SELECT VERSION();
-- 查看当前SQL的版本是多少

- 特定列查询
SELECT 列名1,列名2,... FROM 表名;
- 全部列查询
SELECT * FROM 表名;
- 去除重复行查询
将查询出来的重复数据去掉,针对查询出来的结果,要求是查询出的所有列数据都要一样,才会去掉。
SELECT DISTINCT 列名1,列名2,... FROM 表名;
使用函数对查询结果的处理
函数: 类似于Java中的方法,将一组逻辑语句事先在数据库中定义好,在需要使用的时候直接调用就好了,想调用now()函数一样。
优点:
- 隐藏了实现的细节
- 提高了代码的重用性
调用方式:
SELECT 函数名(实参列表)[from 表];
分类:
- 单行函数:如concat、lengthifnull等。
就是查询出来的结果是多少行,这个函数就会对每一行的数据都进行处理操作。 - 分组函数:做统计使用,又称为统计函数、集合函数、组函数。
也叫聚合函数;多行转为一行。
单行函数
字符函数
● length():获取参数值的字节个数。
一个中文3个字节。
-- 获得当前列名的字节各处
SELECT LENGTH(列名),列名 FROM 表名;
● char_length():获取参数值的字符个数。
-- 获取当前列名的字符个数。
SELECT CHAR_LENGTH(列名),列名 FROM 表名;
● concat(str1,str2,…):拼接字符串。
它可以将两个字符接在一起,以一个列进行发送。
SELECT CONCAT(str1,str2...) FROM 表名;
-- 例如:
-- 将两个列,通过字符的连接,以一个列进行了发送。
SELECT CONCAT(列名1,':', 列名2)AS name FROM 表名;
-- AS name 是对定义了一个别名(AS也是可以省略的)
● upper():将字符串变成大写。
SELECT UPPER(列名) FROM 表名;
● lower():将字符串变为小写。
SELECE LOWER(列名) FROM 表名;
● substring(str,pos,length):截取字符串,从位置pos位置开始。
SELECT SUBSTRING(列名,开始截取位置(从1开始),截取长度) FROM 表名;
● instr(str,指定字符):返回子串第一次出现的索引,如果找不到就返回0
类似于java中的indexof();
SELECT INSTR(列名,指定的字符) FROM 表名;
-- 例子:
SELECT INSTR('abcd','a');

● trim(str):去掉字符串前后的空格或子串。trim(指定子串from字符串)
-- 去掉字符前后的空格。
SELECT TRIM(列名) FROM 表名;
-- 去掉子串
SELECT TRIM(指定的子串 FROM 列名) FROM 表名;
-- 列子
SELECT TRIM('d' FROM 'abcd');

子串和空格一样,只能去掉字符串前后的子串,中间的不行。
● lpad(str,length,填充字符):用指定的字符实现左填充将str填充为指定长度。
SELECT LPAD(列名,指定总长度,填充字符) FROM 表名;
-- 例子:
SELECT LPAD('wasd',6,'a') ;

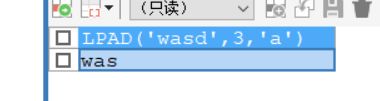
指定的总长就是最后结果的总长,若需要填充的字符串长度就高于指定总长度,就会截取这么长的字符串。
SELECT LPAD('wasd',3,'a') ;
● rpad(str,length,填充字符):用指定的字符实现右填充将str填充为指定长度。
SELECT RPAD(列名,指定总长度,填充字符) FROM 表名;
● replace(str,old,new):替换,替换所有的子串。没有的就不操作了。
SELECT REPLACE(列名,指定旧字符,新字符) FROM 表名;
-- 例子:
SELECT REPLACE('wwaa','a','w');

逻辑函数
- case when 条件 then 结果1 else 结果2 end; (可以有多个when)
当条件满足的时候就是结果1,当条件不满足的时候就是结果2。
SELECT
(CASE WHEN 列名 条件 THEN 结果1 ELSE 结果2 END)
FROM
表名;
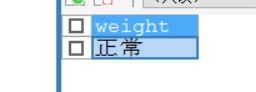
-- 例子:使用多个when来生成结果。
SELECT
(CASE WHEN 140>=180 THEN '偏胖'
WHEN 140>100 AND 140<180 THEN '正常'
ELSE '偏瘦' END)weight;
- IFNULL(被检测的值,自己设置的默认值)
ifnull函数就是检测当前字符是否为null;如果为null,就返回自己设置的默认值;若不是,则正常返回原本的值
这里要注意一下,在数据库表中:
![]() 左边的不为null,表示的是空字符串(它是有值的),右边的才为null。
左边的不为null,表示的是空字符串(它是有值的),右边的才为null。
SELECT IFNULL(列名,自己定义的默认值) FROM 表名;
举例:
SELECT IFNULL('','当前没有值') ;
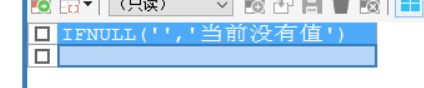
不错输出的,它是一个空字符串,而不是为null;
再举一例:(当前表名为student)
![]()
SELECT IFNULL(address,'当前没有值') FROM student WHERE id = 1

- IF函数:
像java中的if…else…的效果。
if(条件,结果1,结果2)
条件成立走结果1,不成立的话就结果2;
SELECT IF(条件,结果1,结果2) FROM 表名;
-- 举例:
SELECT IF(5>1,'true','false');

数学函数
-
round(数值): 对传入的数值进行四舍五入(四舍五入的时候只看小数点之后的第一位)
-
ceil(数值):对数值进行向上取整,返回>=该参数的最小整数
-
floor(数值):对数值进行向下取整,返回<=该参数的最大整数
-
truncate(数值,保留的小数位数):截断,小数点后截断到几位;
SELECT ROUND(3.4),ROUND(3.5),CEIL(3.5),FLOOR(3.5),TRUNCATE(3.12345,2);

- mod(被除始,除数):取余,被除数为正,则结果为正;被除数为否,则为否;与除数是无关的
SELECT MOD(6,4),MOD(-6,4),MOD(6,-4),MOD(-6,-4);

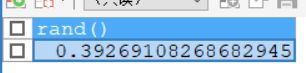
- rand():获取随机数,返回0-1之间的小数。
SELECT RAND();
日期函数
● NOW():返回当前系统的日期+时间;
● CURDATE():返回当前系统日期;(不包含时间)
● CURTIME():返回当前时间,不包含日期;
SELECT NOW(),CURDATE(),CURTIME();
![]()
也可以获取指定时间里面的具体哪一个部分,有:年,月,日,时,分,秒。
- YEAR():年
- MONTH():月
- DAY():日
- HOUR():时
- MINUTE():分
- SECOND():秒
SELECT
NOW(),YEAR(NOW()),MONTH(NOW()),DAY(NOW()),HOUR(NOW()),MINUTE(NOW()),SECOND(NOW());
![]()
● STR_TO_DATE():将日期的字符串型转换为指定格式的日期;
● DATE_FORMAT():将数据库中日期格式转换为字符串形式;
● DATEDIFF(big,small):返回两个日期相差的天数;
日期格式表
| 表达式 | 意思 |
|---|---|
| %Y | 年(4位) |
| %m | 月(00-12) |
| %d | 日(00-31) |
| %H | 时(00-23) |
| %i | 分(00-59) |
| %s | 秒(00-59) |
| %f | 微秒 |
| %T | 时间,24小时(hh:mm:ss) |
| %j | 一年中的天(001-366) |
| %w | 一周中的天(0-6:0=星期天;6-星期六) |
SELECT
STR_TO_DATE('2022-1-1','%Y-%m-%d'),DATE_FORMAT(NOW(),'%Y/%m/%d'),DATEDIFF(NOW(),'2022-1-1');
![]()
将三者结合而出一个比较准确的数据库语言
SELECT DATEDIFF(DATE_FORMAT(NOW(),'%Y-%m-%d'),STR_TO_DATE('2022-1-1','%Y-%m-%d'))
![]()
分组函数
功能:用于统计使用,又称为聚合函数或统计函数或组函数。
分类:
SUM()求和、AVG()平均值、MAX()最大值、MIN()最小值、COUNT()计数
- sum、avg一般用于处理数值型;max、min、count是可以处理任何类型的。
- 这些分组函数都是可以忽略null值的。
- count函数的一般使用count(*) 来用作统计行数(括号里也可以写主键/指定列)。
- 和分组函数一同查询的字段要求必须在group by后的字段。(GROUP BY就是要求分组是按什么进行分组)sql5.0版之前不需要加。
因为是分组函数,所以我在这先建立一个student的表:后面的演示都采用这张表进行

代码演示:
SELECT
SUM(height),AVG(height),MAX(height),MIN(height),COUNT(*)
FROM student;

按性别对表数据进行一个分组:
SELECT
sex,SUM(height),AVG(height),MAX(height),MIN(height),COUNT(*)
FROM student
GROUP BY sex;

条件查询
使用WHERE子句,将不满足条件的行过滤掉,WHERE子句在书写的时候是紧随FROM子句。
语法:
SELECT <结果> FROM <表名> WHERE <条件>
比较符:[=、!=或<>、>、<、>=、<=]
逻辑符:and(与)、or(或)、not(非)
举例:
SELECT * FROM student WHERE sex = '男';

SELECT * FROM student WHERE sex <> '男';

加逻辑符:
SELECT * FROM student WHERE sex = '男' AND height>180;

SELECT * FROM student WHERE NOT sex = '男' AND NOT weight>100;

其他的都一样,就不一 一演示了。
模糊查询
LIKE:是否匹配于一个模式,一般情况下是和统配符搭配一起使用的,可以判断字符型或者数值型。
统配符:
% 表示前或后可以有任意多个(包含0个字符);
_ 前或后只能表示一个,单个字符;(有几个下划线就只能有几个字符,多了少了都不行)
BETWEEN 条件1 AND 条件2:表示两者之间,包含临界值;(相当于条件查询中的 >= 条件1 AND <= 条件2);
IN:判断某字段的值是否值属于IN列表中的某一项
(列名 IN (条件1,条件2…) <===> 列名 = 条件1 OR 列名 = 条件2);
IS NULL(为空)或IS NOT NULL(不为空)
表示当数据表中的数据为空(注意区分空和空字符的两者区别。空字符意为它是有值的,空意为没有任何数据。空字符可以理解它为只输入了一个空格);
举例:
SELECT * FROM student WHERE weight LIKE '%1%'

SELECT
* FROM student WHERE weight LIKE '_2___'; #这里前有1个下划线,后有3个

between…and…
SELECT * FROM student WHERE height BETWEEN 178.6 AND 185;

IN(类似or)
SELECT * FROM student WHERE NAME IN('张三','zhangsan');

SELECT * FROM student WHERE NAME NOT IN('张三','zhangsan');

IS NULL
给student表中再加一条数据

使用IS NULL进行查询:
SELECT * FROM student WHERE weight IS NULL;

SELECT * FROM student WHERE weight IS NOT NULL;

UNION 和UNION ALL语法
UNION语法就是将两个表中的数据合二为一,并且会将结果中的重复数据进行删除。
[查询语句1] UNION [查询语句2]
UNION ALL语法也是将两个表中的数据合二为一,但不会再对这些数据做任何的操作。也可以看出UNION ALL的效率是高于UNION的效率的。
[查询语句1] UNION ALL [查询语句2]
在使用的时候要注意两条查询到返回的数据类型和个数必须完全一样。
举例:
SELECT * FROM student WHERE sex = '女'
UNION
SELECT * FROM student WHERE weight > 100;
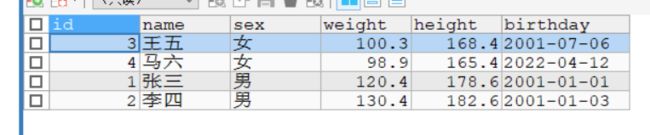
SELECT * FROM student WHERE sex = '女'
UNION ALL
SELECT * FROM student WHERE weight > 100;

对查出的数据进行排序和数量限制
- 排序
就是对结果进行排序,使用ORDER BY对子句进行排序。
语法:ORDER BY 列名 ASC/DESC
ASC代表的是升序,DESC表示降序,如果不写,默认的是进行升序。
ORDER BY子句中可以支持单个字段、多个字段、表达式、函数、别名。
举例:
SELECT * FROM student WHERE weight > 100 ORDER BY height ASC;
SELECT * FROM student WHERE weight > 100 ORDER BY height DESC;

当一个列排序的时候,应为重复性不能做出明确排序,可以再加一个字段进行排序:
(就是先用第一个排,当第一个遇到相同的时候,再用第二个排)
SELECT
*
FROM student WHERE weight > 100
ORDER BY height DESC,weight DESC;
函数同理;
- 数量限制
limit子句:可以理解为就是对查询出来的数据进行一个行数限制
(书写在SQL语句的最末尾位置)。
语法:SELECT * FROM 表名 LIMIT 初始位置,几行数据
初始位置默认最初为0
举例:
查询身高最高的两名同学:
这条语句正常数据是由三条,使用了limit 设置语句,表示它从头开始,查出两行数据。
SELECT
*
FROM
student
WHERE weight > 100
ORDER BY height DESC
LIMIT 0, 2;

分组查询
语法:
SELECT 分组函数,列名(所要分组的要求列) FROM 表名 [WHERE 分组前的筛选条件] GROUP BY 分组的列名 [HAVING 分组后的筛选]
查询条件 WHERE和HAVING的区别:
| 关键字 | 数据来源 | 书写位置 | |
|---|---|---|---|
| 分组前筛选 | WHERE | 原始表数据 | GROUP BT前面 |
| 分组后筛选 | HAVING | 对分组后的数据 | GROUP BY后面 |
举例:
-- 意为将数据在student表内按sex进行分组,然后对没一组进行就数据量、数据求和、最大值。
SELECT sex,COUNT(*),SUM(height),MAX(height) FROM student GROUP BY sex;

SELECT
sex,
COUNT(*)
FROM
student
WHERE height IS NOT NULL #分组前将height为空的信息去除
GROUP BY sex #按照sex对数据进行分组
HAVING sex = '男' #分组后只要sex为‘男’的数据
ORDER BY COUNT(*) #对数据进行一个排序 默认为升序
LIMIT 0,1 #对查出的数据进行数量限制

子查询和关联查询
下一篇: ====> MySQL——DQL(数据库查询语言)sql8.0版下(子查询和关联查询)
总篇: ====》 数据库——MySQL概述
上篇: ====》 MySQL——DML(数据库操纵语言)