2. AdaBoost算法
AdaBoost是一个具有代表性的提升算法(Boosting)。
一、提升方法(Boosting)
(1)强可学习与弱可学习
在概率近似正确(PAC)学习的框架中,一个概念(一个类)如果存在一个多项式的学习算法能够学习它,并且正确率很高,则称为这个概念是强可学习的;如果存在一个多项式的学习算法能够学习它,并且正确率仅比随机猜想略好,那么称为这个概念是弱可学习的。可以证明,强可学习与弱可学习是等价的。通常,发现弱可学习算法通常要比发现强可学习算法容易的多。
(2)提升方法
提升方法是一种集成学习方法,其基本思想是:针对训练集,从若学习算法出发,反复学习,得到一系列地弱学习器,然后通过一定的结合策略组合这些弱分类器,形成一个强分类器。大多数提升算法都是改变训练数据的概率分布(权值分布)。针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。

提升算法的学习过程可以总结为:
① 初始化样本权重;
② 基于弱学习算法学习得到弱学习器,并基于损失函数最小化,更新样本的权值并计算弱分类器的权重系数;
③ 重复第②步操作,直到达到某个阈值;
④ 将上述得到的一系列的弱学习器按照一定的结合策略进行组合得到强学习器。
对提升算法来说,需要解决两个问题:一是如何改变训练数据的概率(权值)分布;二是如何将弱分类器组合成一个强分类器。
AdaBoost针对第一个问题,采取的策略是提高被错误分类的样本的权值,降低被争取分类的样本的权值;对于第二个问题,采用的加权多数表决方法,加大分类错误率低的弱分类器的权重,减小分类错误率高的弱分类器的权重。
二. 前向分步算法
提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。
加法模型如下:
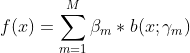
其中,![]() 表示基函数,
表示基函数,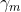 是基函数的参数,
是基函数的参数,![]() 是基函数的系数。
是基函数的系数。
在给定训练数据以及损失函数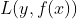 的情况下,学习加法模型
的情况下,学习加法模型 成为经验风险最小化问题即损失函数极小化问题:
成为经验风险最小化问题即损失函数极小化问题:
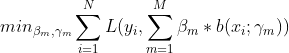
这是一个复杂的优化问题,可以采用前向分步算法进行求解。前向分步算法的思路是:因为学习的是加法模型,如果能从前向后,每一步只学习一个基函数及其系数,逐步逼近目标函数,则可以简化优化问题的复杂度。每一步只需优化如下损失函数:
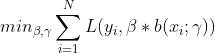
前向分步算法的学习过程如下:
输入:训练数据集![]() ,损失函数,基函数集
,损失函数,基函数集![]() ;
;
输出:加法模型。
过程如下:
① 初始化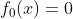 ;
;
② 对![]()
(a)极小化损失函数
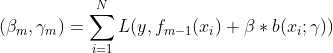
得到参数![]() 。
。
(b) 更新
![]()
③ 得到加法模型
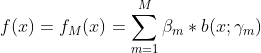
这样,前向分步算法将同时求解参数集的优化问题简化为逐次求解各个参数的优化问题。
三. AdaBoost算法
AdaBoost算法是前向分步算法的特例。可以认为是模型为基学习器组成的加法模型(弱学习器结合策略),损失函数为指数函数,学习算法为前向分步算法(损失函数最小化求解方法)的二分类学习方法。
设AdaBoost的最终分类器如下:
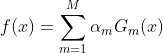
指数损失函数:
![]()
若经过![]() 轮的迭代,得到
轮的迭代,得到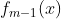 ,在第m轮时的计算公式如下:
,在第m轮时的计算公式如下:
![]()
目标是在训练数据集上的指数损失函数最小,即
其中,![]() ,即不依赖
,即不依赖 ,也不依赖
,也不依赖 ,与最小化无关,但是依赖于,随着每一轮迭代而改变。
,与最小化无关,但是依赖于,随着每一轮迭代而改变。
首先,求![]() 。对任意
。对任意![]() ,使得上式最小的
,使得上式最小的 可以有下式得到:
可以有下式得到:
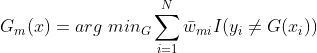
其中,![]() 。
。
此分类器![]() 即为AdaBoost算法的基本分类器,因为它是使第
即为AdaBoost算法的基本分类器,因为它是使第 轮加权训练数据分类误差率最小的基本分类器。
轮加权训练数据分类误差率最小的基本分类器。
接下来,求![]() 。
。
将求得的![]() 带入上式,对求导并使倒数为0,得到使得上式最小的,即
带入上式,对求导并使倒数为0,得到使得上式最小的,即
![]()
其中,![]() 是分类误差率。
是分类误差率。
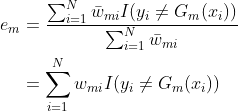
最后,看一下每一轮样本权值的更新。由
![]() 以及
以及![]() 可得
可得
![\begin{aligned} \bar{w}_{m+1,i} &= exp[-y_if_m(x_i)] \\ &= exp[-y_i(f_{m-1}(x_i) + \alpha _m G_m(x))] \\ &= \bar{w}_{m,i} exp[-y_i\alpha _m G_m(x_i)] \end{aligned}](http://img.e-com-net.com/image/info8/0f4fda1a329c4a829e70e52f87804f90.gif)
AdaBoost算法的学习过程如下:
输入:训练数据集![]() ,
,![]() ;弱学习算法;
;弱学习算法;
输出:最终分类器。
过程如下:
① 初始化训练数据的权值分布
![]()
② 对![]()
(a)使用具有权值分布![]() 的训练数据集学习,得到基本分类器
的训练数据集学习,得到基本分类器
![]()
(b)计算![]() 在训练数据集上的分类误差率
在训练数据集上的分类误差率
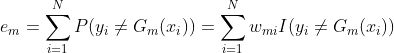
(c)计算![]() 的系数
的系数
![]()
(d)更新训练数据集的权值分布
![]()
![]()
这里![]() 是一个规范化因子
是一个规范化因子
![Z_m = \sum_{i=1}^{N} w_{mi} exp[-y_i\alpha _m G_m(x_i)]](http://img.e-com-net.com/image/info8/3ff3c0f6da204771ac3fffcad35c431c.gif)
③ 构建基本分类器的线性组合
得到最终的分类器
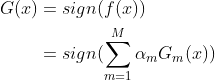
四. 自适性
AdaBoost的自适应性体现在,能根据上一轮的训练结果,自行调整训练数据的样本样本权值,加大分类错误的样本权重,减小分类正确的样本权重。
五. 优缺点
(1)AdaBoost算法优点
- 不易发生过拟合
- 由于AdaBoost并没有限制弱学习器的种类,所以可以使用不同的学习算法来构建弱分类器;
- AdaBoost具有很高的精度; 相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
- AdaBoost的参数少,实际应用中不需要调节太多的参数。
(2)AdaBoost算法缺点
- 数据不平衡导致分类精度下降;
- 训练耗时,主要由于多个弱分类器的训练耗时;
- 弱分类器的数目不好设置;
- 对异常样本敏感,由于adaboost对错误样本会增加其权值,异常样本会获得高权值,影响最终分类器的精度。
六. Q & A
1. Adaboost算法在迭代的过程中,迭代的次数怎么确定?
考虑两个指标:
(1)正确率:上一轮与本轮正确率的差值低到一定程度就可以停止,这个差值的阈值根据需要来设定;
(2)时间:理想情况下,分类器越多分类效果越好,但是这也造成了需要更多的时间。
2. 弱分类器的选择及数量
弱分类器我们可以选择很多方法选择,逻辑回归,SVM,决策树都可以。但是使用做多的就是我们之前用到的单层决策树,原因是基分类器简单好构造,且不易过拟合。迭代次数是我们手动调节的或者是模型训练到训练误差为0,与弱分类器的选择无关。
3. 为什么Adaboost不易过拟合?
Adaboost做为一个加性模型,采用了指数损失函数。理论上而言也就是说每增加一级分类器,损失函数都会减小,也就是方差会越来越大,从这个角度来理解那么adaboost其实是更容易过拟合的。但是因为我们选择的基分类器很简单,那么在实际应用中很难过拟合,这也是我们经常选择决策树桩作为基分类器的原因。但是到目前为止,还没有一个完全清楚的答案。在许多variance-bias 分解实验中也观察到,AdaBoost不仅是减少了bias,同时也减少了variance,variance的减少往往与算法容量减少有关。ECML12上有一篇文章说boosting方法中有差异的基分类集成能减小达到预计效果的模型复杂度,一定程度也起到正则化,减小variance的作用。
附录:
1. 《统计学习方法第二版》.李航
2. 机器学习之梯度提升决策树(GBDT)_谓之小一的博客-CSDN博客_梯度提升决策树
3. https://www.csdn.net/tags/MtTaAgwsOTI5MzA1LWJsb2cO0O0O.html#5Adaboost_78