Python爬虫高手爬爬爬(各种案例更新中。。。)
文章目录
- 一、爬虫简介
-
- 1.1 爬虫在使用场景中的分类
- 1.2 robots.txt协议
- 1.3 网站知识
- 二 、基础模块requests
-
- 2.1介绍
- 2.2作用
- 2.3如何使用
- 2.4 内置属性或者函数
- 2.5 cookies 和 session
- 爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
- 三、数据解析
-
- 3.1 正则表达式
-
- 爬30页糗事百科的video图片
- 3.2 bs4
-
- 爬取三国演义所有章节
- 3.3 xpath⭐⭐⭐
-
- 58二手房房源信息以及面积
- 4k美女图
- 获取全国城市
- 爬取 http://www.51pptmoban.com/的ppt模板
- 四 验证码冲冲冲
-
-
- 验证码识别方法
- 云打码识别,效果良好,金钱的力量!!
- 斐斐打码自掏腰包实测很好用
- tesseract-ocr识别效果细碎。。。
- 百度AI平台识别,通用文字识别(高精度版),精度还行偶尔缺失。。。。
- 账号密码验证码模拟登录,古诗文网,使用斐斐打码
- 登录成功了!就可以拿cookie了!
-
- 五 代理模式
-
- 代理相关的网站:
- 百度查询ip验证代理是否成功
- 六 异步爬虫
- 七 selenium模块
-
-
- 使用超级鹰模拟登录12306
-
- 八 scrapy框架⭐⭐⭐
-
- 8.1 环境的安装:
- 8.2 创建工程终端
- 8.4 数据持久化存储
-
- 8.4.1 基于终端指令
- 8.4.2 基于管道存储
-
- 例子1,管道存储到txt文件
- 例子2:管道存储到数据库
- 8.6 五大核心组件
- 8.7 请求传参,深度爬取
-
- 爬取阿里校园招聘的岗位名称,岗位描述
- 8.8 图片爬取
-
- 爬取站长素材的图片
一、爬虫简介
1.1 爬虫在使用场景中的分类
- 通用爬虫:
抓取系统重要组成部分。抓取的是一整张页面数据。 - 聚焦爬虫:
是建立在通用爬虫的基础之上。抓取的是页面中特定的局部内容。 - 增量式爬虫:
检测网站中数据更新的情况。只会抓取网站中最新更新出来的数据。
1.2 robots.txt协议
君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。url后面直接访问。
1.3 网站知识
http协议
- 概念:就是服务器和客户端进行数据交互的一种形式。
常用请求头信息 - User-Agent:请求载体的身份标识
- Connection:请求完毕后,是断开连接还是保持连接
常用响应头信息
- Content-Type:服务器响应回客户端的数据类型
https协议:
- 安全的超文本传输协议
加密方式
- 对称秘钥加密
- 非对称秘钥加密
- 证书秘钥加密
二 、基础模块requests
2.1介绍
python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
2.2作用
模拟浏览器发请求
2.3如何使用
(requests模块的编码流程)
- 指定url
- UA伪装
- 请求参数的处理
- 发起请求
- 获取响应数据
- 持久化存储
2.4 内置属性或者函数
参数一般封装成字典
response = requests.post(url= ,data= ,headers =)
###url 参数 UA伪装 代理
response = requests.get(url = , params= ,headers = ,proxies=)
返回值response的属性⭐
- response.text 获取str类型(Unicode编码)的响应、html
- response.json Content-Type为json时,可以直接获取json
- response.content 获取bytes类型的响应、图片视频二进制文件
- response.status_code 获取响应状态码
- response.headers 获取响应头
- response.request 获取响应对应的请求
- response.cookies 获取ciookies
2.5 cookies 和 session
- 使用的cookie和session好处:很多网站必须登录之后(或者获取某种权限之后)才能能够请求到相关数据。
- 使用的cookie和session的弊端:一套cookie和session往往和一个用户对应.请求太快,请求次数太多,容易被服务器识别为爬虫,从而使账号收到损害。
- 不需要cookie的时候尽量不去使用cookie。为了获取登录之后的页面,我们必须发送带有cookies的请求,此时为了确保账号安全应该尽量降低数据
采集速度。
爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
import json
import requests
if __name__ == '__main__':
# 索引页
id_list = []
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
for page in range(1,6):
page = str(page)
data={
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
# UA
headers ={
'***********************'
}
respone = requests.post(url=url,data=data,headers=headers).json()
for dic in respone['list']:
id_list.append(dic['ID'])
print(id_list)
print(page+'页爬取成功')
# 详情页
url2 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
all_detail= []
for id in id_list:
data2={
'id':id
}
respone2 = requests.post(url=url2, data=data2, headers=headers).json()
all_detail.append(respone2)
filename ='./detail.json'
with open(filename,'w',encoding='utf-8') as fp:
json.dump(all_detail,fp=fp,ensure_ascii=False)
print('爬取成功')
三、数据解析
聚焦爬虫
正则
bs4
xpath
3.1 正则表达式
通过正则表达式匹配需要抓取的链接
爬30页糗事百科的video图片
import requests
import re
import os
# 正则表达式
if __name__ == '__main__':
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs')
count = 0
ua={
'User-Agent':'*****'
}
url = 'https://www.qiushibaike.com/8hr/page/%d/'
for pageNum in range(1,30):
new_url =format(url%pageNum)
response = requests.get(url = new_url,headers = ua).text
# print(response)
# 空格也要打出来 '开始 省略 取值前中间括号取值,取值后 省略 结尾'
ex = ''
img_src_list = re.findall(ex,response,re.S)
# print(img_src_list)
for img in img_src_list:
src = 'https:'+img
imag_data = requests.get(src,headers = ua).content
# 地址获取图片名字
img_name = img.split('/')[-6].split('?')[-2]
# print(img_name)
imgPath = './qiutuLibs/'+img_name
with open(imgPath,'wb')as fp:
# 写入二进制
fp.write(imag_data)
print(img_name,'下载成功!')
count+=1
print(str(count),'条新数据已更新')
3.2 bs4
Python特有,需要的包:bs4、lxml
步骤:
- 实例化BeautifulSoup对象,加载页面源码
- 使用BeautifulSoup对象中的方法或属性定位标签和提取数据
对象的实例化:
- 1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
- 2.将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeatifulSoup(page_text,'lxml')
提供的用于数据解析的方法和属性:
| soup.tagName | 返回的是文档中第一次出现的tagName对应的标签 |
|---|---|
| soup.find() | find(‘tagName’):等同于soup.div |
| select | select(‘某种选择器(id,class,标签…选择器)’),返回的是一个列表 |
| soup.a.text/string/get_text() | 获取文本 |
| soup.a[‘href’] | 获取a标签中属性值href |
-
详解find属性定位: -soup.find('div',class_/id/attr='song') - soup.find_all('tagName'):返回符合要求的所有标签(列表) -
详解select: - select('某种选择器(id,class,标签...选择器)'),返回的是一个列表。 - 层级选择器: - soup.select('.tang > ul > li > a'):>表示的是一个层级 - soup.select('.tang > ul a'):空格表示的多个层级 - 获取标签之间的文本数据*: - soup.a.text/string/get_text() - text/get_text():可以获取某一个标签中~~所有~~ 的文本内容 - string:只可以获取该标签下面~~直系~~ 的文本内容
爬取三国演义所有章节
# python特有
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
# 加载本地
# with open('***.html','r',encoding='utf-8') as fp:
# soup = BeautifulSoup(fp,'lxml')
ua = {
'User-Agent':'********************'
}
url = 'http://mathfunc.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=ua).text
soup = BeautifulSoup(page_text,'lxml')
li_list = soup.select('.book-mulu > ul > li')
# print(li_list)
fp = open('./sanguoyanyi.txt','w',encoding='utf-8')
for lis in li_list:
title = lis.a.string # a标签下的直系内容 string 所有内容content
print(lis.a['href']) # lis是soup对象,[]选择属性
detail_url = 'http://mathfunc.com'+lis.a['href']
detail_page_text = requests.get(url = detail_url,headers = ua).text
# bs解析 find 标签属性, text获取全部内容
detail_soup = BeautifulSoup(detail_page_text,'lxml').find('div', class_ ='chapter_content').text
# print(detail_soup)
fp.write(title+':'+detail_soup+'\n')
print(title,'爬取成功!')
# fp.write(detail_soup)
3.3 xpath⭐⭐⭐
xpath解析原理:
- 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
- 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
如何实例化一个etree对象:from lxml import etree
- 1.将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
- 2.可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text')
xpath(‘xpath表达式’)
xpath表达式:
| / | 表示的是从根节点开始定位。表示的是一个层级 |
|---|---|
| // | 表示的是多个层级。可以表示从任意位置开始定位。 |
| 属性定位 | //div[@class=‘song’] tag[@attrName=“attrValue”] |
| 索引定位 | //div[@class=“song”]/p[3] 索引是从1开始的。 |
| 取文本: | /text() 获取的是标签中直系的文本内容、 //text() 标签中非直系的文本内容(所有的文本内容) |
| 取属性: | img/@src |
58二手房房源信息以及面积
# 58二手房
from lxml import etree
import requests
if __name__ == '__main__':
url='https://tj.58.com/ershoufang/'
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36 Edg/86.0.622.43'
}
response = requests.get(url=url, headers=ua).text
tree = etree.HTML(response)
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
fp =open('./58ershoufang.txt','w',encoding='utf-8')
for li in li_list:
li_content = li.xpath('./div[2]/h2/a/text()')[0] ##第一个文本 房源标题
li_mianji = li.xpath('./div[2]/p/span/text()')[1] ##面积大小
print(li_content,li_mianji)
fp.write(li_content+'___的面积大小为---->'+li_mianji+'\n')
4k美女图
注意中文的乱码问题,一般解决方法
- 1.直接response.encoding = ‘utf-8’ 看是否支持直接编码成utf-8
- 2.img_name.encode(‘iso-8859-1’).decode(‘gbk’) 编码再解码
#需求:解析下载图片数据 http://pic.netbian.com/4kmeinv/
import requests
from lxml import etree
import os
if __name__ == "__main__":
url = 'http://pic.netbian.com/4kmeinv/'
headers = {
'User-Agent':'*******************'
}
response = requests.get(url=url,headers=headers)
#手动设定响应数据的编码格式
# response.encoding = 'utf-8'
page_text = response.text
#数据解析:src的属性值 alt属性
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
#创建一个文件夹
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'http://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
#通用处理中文乱码的解决方案
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
#请求图片进行持久化存储
img_data = requests.get(url=img_src,headers=headers).content
img_path = 'picLibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!!')
获取全国城市
注意tree.xpath的书写,按位或 | 获取所有符合的列表数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
#项目需求:解析出所有城市名称https://www.aqistudy.cn/historydata/
if __name__ == "__main__":
headers = {
'User-Agent': '*******'
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# //div[@class="bottom"]/ul/li/ 热门城市a标签的层级关系
# //div[@class="bottom"]/ul/div[2]/li/a 全部城市a标签的层级关系
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
all_city_names = []
for a in a_list:
city_name = a.xpath('./text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))
爬取 http://www.51pptmoban.com/的ppt模板
注意网站的跳转
import requests
from lxml import etree
import os
if __name__ == "__main__":
if not os.path.exists('./pptjianli'):
os.mkdir('./pptjianli')
url = 'http://www.51pptmoban.com/ppt/'
headers = {
'User-Agent':'*********'
}
response = requests.get(url=url,headers=headers).text
# print(response)
#数据解析:src的属性值 alt属性
tree = etree.HTML(response)
li_list = tree.xpath('//div[@class="pdiv"]')
# print(li_list)
# #创建一个文件夹
if not os.path.exists('./jianli'):
os.mkdir('./jianli')
for li in li_list:
img_src = 'http://www.51pptmoban.com'+li.xpath('./a/@href')[0]
img_name = './pptjianli/'+li.xpath('./a/img/@alt')[0]+'.zip'
# 通用处理中文乱码的解决方案
img_name = img_name.encode('iso-8859-1').decode('GBK')
print(img_name,img_src)
response2 = requests.get(img_src,headers).text
downLaddr = 'http://www.51pptmoban.com'+etree.HTML(response2).xpath('//div[@class ="ppt_xz"]/a/@href')[0]
print(downLaddr)
response3 = requests.get(downLaddr,headers).text
downLaddr_true = 'http://www.51pptmoban.com/e/DownSys'+etree.HTML(response3).xpath('//div[@class ="down"]/a/@href')[0].split('..')[-1]
print(downLaddr_true)
# 下载二进制zip
data = requests.get(downLaddr_true,headers).content
with open(img_name,'wb') as fp:
fp.write(data)
print(img_name,'下载成功!!!')
四 验证码冲冲冲
验证码识别方法
- 人眼
- 第三方专业平台(云打码、超级鹰、斐斐打码等)
- tesseract-ocr实测效果差!智能识别英文
- 百度AI平台
- 自己orc训练识别模型,给接口使用
- 设置方法规避验证码
云打码识别,效果良好,金钱的力量!!
古诗文网验证码登录,主程序
import requests
from lxml import etree
from CodeClass import YDMHttp
#封装识别验证码图片的函数
def getCodeText(imgPath,codeType):
# 普通用户用户名
username = '**'
# 普通用户密码
password = '**'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = **
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = '**'
# 图片文件:即将被识别的验证码图片的路径
filename = imgPath
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = codeType
# 超时时间,秒
timeout = 20
result = None
# 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print('cid: %s, result: %s' % (cid, result))
return result
#将验证码图片下载到本地
headers = {
'User-Agent': '******'
}
url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
page_text = requests.get(url=url,headers=headers).text
#解析验证码图片img中src属性值
tree = etree.HTML(page_text)
code_img_src = 'https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = requests.get(url=code_img_src,headers=headers).content
#将验证码图片保存到了本地
with open('./code.jpg','wb') as fp:
fp.write(img_data)
#调用打码平台的示例程序进行验证码图片数据识别
code_text = getCodeText('code.jpg',1004)
print('识别结果为:',code_text)
YDMHttp类
import http.client, mimetypes, urllib, json, time, requests
######################################################################
class YDMHttp:
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = ''
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['balance']
else:
return -9001
def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['uid']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
file = {'file': filename}
response = self.request(data, file)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['cid']
else:
return -9001
def result(self, cid):
data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'cid': str(cid)}
response = self.request(data)
return response and response['text'] or ''
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != ''):
return cid, result
else:
time.sleep(1)
return -3003, ''
else:
return cid, ''
def report(self, cid):
data = {'method': 'report', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'cid': str(cid), 'flag': '0'}
response = self.request(data)
if (response):
return response['ret']
else:
return -9001
def post_url(self, url, fields, files=[]):
for key in files:
files[key] = open(files[key], 'rb');
res = requests.post(url, files=files, data=fields)
return res.text
斐斐打码自掏腰包实测很好用
# coding=utf-8
import os,sys
import hashlib
import time
import json
import requests
FATEA_PRED_URL = "http://pred.fateadm.com"
def LOG(log):
# 不需要测试时,注释掉日志就可以了
print(log)
log = None
class TmpObj():
def __init__(self):
self.value = None
class Rsp():
def __init__(self):
self.ret_code = -1
self.cust_val = 0.0
self.err_msg = "succ"
self.pred_rsp = TmpObj()
def ParseJsonRsp(self, rsp_data):
if rsp_data is None:
self.err_msg = "http request failed, get rsp Nil data"
return
jrsp = json.loads( rsp_data)
self.ret_code = int(jrsp["RetCode"])
self.err_msg = jrsp["ErrMsg"]
self.request_id = jrsp["RequestId"]
if self.ret_code == 0:
rslt_data = jrsp["RspData"]
if rslt_data is not None and rslt_data != "":
jrsp_ext = json.loads( rslt_data)
if "cust_val" in jrsp_ext:
data = jrsp_ext["cust_val"]
self.cust_val = float(data)
if "result" in jrsp_ext:
data = jrsp_ext["result"]
self.pred_rsp.value = data
def CalcSign(pd_id, passwd, timestamp):
md5 = hashlib.md5()
md5.update((timestamp + passwd).encode())
csign = md5.hexdigest()
md5 = hashlib.md5()
md5.update((pd_id + timestamp + csign).encode())
csign = md5.hexdigest()
return csign
def CalcCardSign(cardid, cardkey, timestamp, passwd):
md5 = hashlib.md5()
md5.update(passwd + timestamp + cardid + cardkey)
return md5.hexdigest()
def HttpRequest(url, body_data, img_data=""):
rsp = Rsp()
post_data = body_data
files = {
'img_data':('img_data',img_data)
}
header = {
'User-Agent': 'Mozilla/5.0',
}
rsp_data = requests.post(url, post_data,files=files ,headers=header)
rsp.ParseJsonRsp( rsp_data.text)
return rsp
class FateadmApi():
# API接口调用类
# 参数(appID,appKey,pdID,pdKey)
def __init__(self, app_id, app_key, pd_id, pd_key):
self.app_id = app_id
if app_id is None:
self.app_id = ""
self.app_key = app_key
self.pd_id = pd_id
self.pd_key = pd_key
self.host = FATEA_PRED_URL
def SetHost(self, url):
self.host = url
#
# 查询余额
# 参数:无
# 返回值:
# rsp.ret_code:正常返回0
# rsp.cust_val:用户余额
# rsp.err_msg:异常时返回异常详情
#
def QueryBalc(self):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign
}
url = self.host + "/api/custval"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("query succ ret: {} cust_val: {} rsp: {} pred: {}".format( rsp.ret_code, rsp.cust_val, rsp.err_msg, rsp.pred_rsp.value))
else:
LOG("query failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 查询网络延迟
# 参数:pred_type:识别类型
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg: 异常时返回异常详情
#
def QueryTTS(self, pred_type):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
"predict_type":pred_type,
}
if self.app_id != "":
#
asign = CalcSign(self.app_id, self.app_key, tm)
param["appid"] = self.app_id
param["asign"] = asign
url = self.host + "/api/qcrtt"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("query rtt succ ret: {} request_id: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.err_msg))
else:
LOG("predict failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 识别验证码
# 参数:pred_type:识别类型 img_data:图片的数据
# 返回值:
# rsp.ret_code:正常返回0
# rsp.request_id:唯一订单号
# rsp.pred_rsp.value:识别结果
# rsp.err_msg:异常时返回异常详情
#
def Predict(self, pred_type, img_data, head_info = ""):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp": tm,
"sign": sign,
"predict_type": pred_type,
"up_type": "mt"
}
if head_info is not None or head_info != "":
param["head_info"] = head_info
if self.app_id != "":
#
asign = CalcSign(self.app_id, self.app_key, tm)
param["appid"] = self.app_id
param["asign"] = asign
url = self.host + "/api/capreg"
files = img_data
rsp = HttpRequest(url, param, files)
if rsp.ret_code == 0:
LOG("predict succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("predict failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg))
if rsp.ret_code == 4003:
#lack of money
LOG("cust_val <= 0 lack of money, please charge immediately")
return rsp
#
# 从文件进行验证码识别
# 参数:pred_type;识别类型 file_name:文件名
# 返回值:
# rsp.ret_code:正常返回0
# rsp.request_id:唯一订单号
# rsp.pred_rsp.value:识别结果
# rsp.err_msg:异常时返回异常详情
#
def PredictFromFile( self, pred_type, file_name, head_info = ""):
with open(file_name, "rb") as f:
data = f.read()
return self.Predict(pred_type,data,head_info=head_info)
#
# 识别失败,进行退款请求
# 参数:request_id:需要退款的订单号
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg:异常时返回异常详情
#
# 注意:
# Predict识别接口,仅在ret_code == 0时才会进行扣款,才需要进行退款请求,否则无需进行退款操作
# 注意2:
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
#
def Justice(self, request_id):
if request_id == "":
#
return
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
"request_id":request_id
}
url = self.host + "/api/capjust"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("justice succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("justice failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 充值接口
# 参数:cardid:充值卡号 cardkey:充值卡签名串
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg:异常时返回异常详情
#
def Charge(self, cardid, cardkey):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
csign = CalcCardSign(cardid, cardkey, tm, self.pd_key)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
'cardid':cardid,
'csign':csign
}
url = self.host + "/api/charge"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("charge succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("charge failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
##
# 充值,只返回是否成功
# 参数:cardid:充值卡号 cardkey:充值卡签名串
# 返回值: 充值成功时返回0
##
def ExtendCharge(self, cardid, cardkey):
return self.Charge(cardid,cardkey).ret_code
##
# 调用退款,只返回是否成功
# 参数: request_id:需要退款的订单号
# 返回值: 退款成功时返回0
#
# 注意:
# Predict识别接口,仅在ret_code == 0时才会进行扣款,才需要进行退款请求,否则无需进行退款操作
# 注意2:
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
##
def JusticeExtend(self, request_id):
return self.Justice(request_id).ret_code
##
# 查询余额,只返回余额
# 参数:无
# 返回值:rsp.cust_val:余额
##
def QueryBalcExtend(self):
rsp = self.QueryBalc()
return rsp.cust_val
##
# 从文件识别验证码,只返回识别结果
# 参数:pred_type;识别类型 file_name:文件名
# 返回值: rsp.pred_rsp.value:识别的结果
##
def PredictFromFileExtend( self, pred_type, file_name, head_info = ""):
rsp = self.PredictFromFile(pred_type,file_name,head_info)
return rsp.pred_rsp.value
##
# 识别接口,只返回识别结果
# 参数:pred_type:识别类型 img_data:图片的数据
# 返回值: rsp.pred_rsp.value:识别的结果
##
def PredictExtend(self,pred_type, img_data, head_info = ""):
rsp = self.Predict(pred_type,img_data,head_info)
return rsp.pred_rsp.value
def TestFunc():
# pd账号秘钥,请在用户中心页获取
pd_id = "******"
pd_key = "*****"
app_id = "******"
app_key = "*******"
# 具体类型可以查看官方网站的价格页选择具体的类型,不清楚类型的,可以咨询客服
pred_type = "30400"
api = FateadmApi(app_id, app_key, pd_id, pd_key)
# 查询余额
balance = api.QueryBalcExtend() # 直接返余额
# api.QueryBalc()
# 通过文件形式识别:
file_name = "b.jpg"
# 多网站类型时,需要增加src_url参数,具体请参考api文档: http://docs.fateadm.com/web/#/1?page_id=6
# result = api.PredictFromFileExtend(pred_type,file_name) # 直接返回识别结果
rsp = api.PredictFromFile(pred_type, file_name) # 返回详细识别结果
'''
# 如果不是通过文件识别,则调用Predict接口:
# result = api.PredictExtend(pred_type,data) # 直接返回识别结果
rsp = api.Predict(pred_type,data) # 返回详细的识别结果
'''
just_flag = True
if just_flag :
if rsp.ret_code == 0:
#识别的结果如果与预期不符,可以调用这个接口将预期不符的订单退款
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
api.Justice( rsp.request_id)
#card_id = "123"
#card_key = "123"
#充值
#api.Charge(card_id, card_key)
LOG("print in testfunc")
print('识别结果为:',rsp.pred_rsp.value)
if __name__ == "__main__":
TestFunc()
tesseract-ocr识别效果细碎。。。
import tesserocr
from PIL import Image
image=Image.open(r'a.jpg')
image=image.convert("L") #转灰度
threshold=200 #阈值可以调整测试
table=[]
for i in range(256):
if i <threshold:
table.append(0)
else:
table.append(1)
image=image.point(table,'1') #转二值化
# image.show()
res = tesserocr.image_to_text(image)
print(res)
百度AI平台识别,通用文字识别(高精度版),精度还行偶尔缺失。。。。
四个字母只能识别出两三个,哭了
# encoding:utf-8
import requests
import base64
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=****&client_secret=***'
response = requests.get(host)
session_key = None
if response:
session_key = response.json().get('access_token')
print(session_key)
else:
print('为获取')
# '''
# 通用文字识别(高精度版)
# '''
#
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('getimage.jpg', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = str(session_key)
print(access_token)
request_url = request_url + "?access_token=" + access_token
print(request_url)
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
账号密码验证码模拟登录,古诗文网,使用斐斐打码
主程序
#编码流程:
#1.验证码的识别,获取验证码图片的文字数据
#2.对post请求进行发送(处理请求参数)
#3.对响应数据进行持久化存储
import requests
from lxml import etree
from lesson5验证码登录志愿者.fateadm_api_py3 import FateadmApi,LOG
#封装识别验证码图片的函数
def TestFunc(filename,codetype = "30400"):
# pd账号秘钥,请在用户中心页获取
pd_id = "***"
pd_key = "***"
app_id = "**"
app_key = "***"
# 具体类型可以查看官方网站的价格页选择具体的类型,不清楚类型的,可以咨询客服
pred_type = codetype ##"30400"
api = FateadmApi(app_id, app_key, pd_id, pd_key)
# 查询余额
balance = api.QueryBalcExtend() # 直接返余额
# api.QueryBalc()
# 通过文件形式识别:
file_name = filename
# 多网站类型时,需要增加src_url参数,具体请参考api文档: http://docs.fateadm.com/web/#/1?page_id=6
# result = api.PredictFromFileExtend(pred_type,file_name) # 直接返回识别结果
rsp = api.PredictFromFile(pred_type, file_name) # 返回详细识别结果
'''
# 如果不是通过文件识别,则调用Predict接口:
# result = api.PredictExtend(pred_type,data) # 直接返回识别结果
rsp = api.Predict(pred_type,data) # 返回详细的识别结果
'''
just_flag = True
if just_flag :
if rsp.ret_code == 0:
#识别的结果如果与预期不符,可以调用这个接口将预期不符的订单退款
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
api.Justice( rsp.request_id)
#card_id = "123"
#card_key = "123"
#充值
#api.Charge(card_id, card_key)
LOG("print in testfunc")
print('识别结果为:',rsp.pred_rsp.value)
return rsp.pred_rsp.value
#1.对验证码图片进行捕获和识别
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url ='https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
# 解析验证码的axjx请求获取数据
page_text = requests.get(url=url,headers=headers).text
# 志愿者网对获取的数据进行解析地址,有一定的反扒机制
# iamge_url = page_text.split("linkurl")[-1].split('"')[-2].replace("\/","/")
response = etree.HTML(page_text)
image_url = 'https://so.gushiwen.org/'+response.xpath('//*[@id="imgCode"]/@src')[0]
print(image_url)
code_img_data = requests.get(url=image_url,headers=headers).content
with open('./gugushishicici.jpg','wb') as fp:
fp.write(code_img_data)
# # #使用云打码提供的示例代码对验证码图片进行识别
result = TestFunc('gugushishicici.jpg',"30400")
print(result)
# 获取验证码识别结果
#get请求的发送(模拟登录)
login_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx'
data = {
'VIEWSTATE': 'tiz/tqUP+AQeU30gLgevylShSEEU7AEywA19OL+t7SabDCtxga+CMtTt+xGz1fDaBMWgXk4sUvQhAATQHSnhTy5oWHbvc2AgaJ3sZXCzakVO5yRo7Uud6WWgvsQ=',
'__VIEWSTATEGENERATOR': 'C93BE1AE',
'from': 'http://so.gushiwen.org/user/collect.aspx',
'email': '18892222**',
'pwd': 'zk11011**',
'code': result,
'denglu': '登录'
}
response = requests.post(url=login_url,headers=headers,data=data)
print(response.text)
# 200请求成功
print(response.status_code)
login_page_text = response.text
with open('gushici.html','w',encoding='utf-8') as fp:
fp.write(login_page_text)
fateadm_api_py3
# coding=utf-8
import os,sys
import hashlib
import time
import json
import requests
FATEA_PRED_URL = "http://pred.fateadm.com"
def LOG(log):
# 不需要测试时,注释掉日志就可以了
print(log)
log = None
class TmpObj():
def __init__(self):
self.value = None
class Rsp():
def __init__(self):
self.ret_code = -1
self.cust_val = 0.0
self.err_msg = "succ"
self.pred_rsp = TmpObj()
def ParseJsonRsp(self, rsp_data):
if rsp_data is None:
self.err_msg = "http request failed, get rsp Nil data"
return
jrsp = json.loads( rsp_data)
self.ret_code = int(jrsp["RetCode"])
self.err_msg = jrsp["ErrMsg"]
self.request_id = jrsp["RequestId"]
if self.ret_code == 0:
rslt_data = jrsp["RspData"]
if rslt_data is not None and rslt_data != "":
jrsp_ext = json.loads( rslt_data)
if "cust_val" in jrsp_ext:
data = jrsp_ext["cust_val"]
self.cust_val = float(data)
if "result" in jrsp_ext:
data = jrsp_ext["result"]
self.pred_rsp.value = data
def CalcSign(pd_id, passwd, timestamp):
md5 = hashlib.md5()
md5.update((timestamp + passwd).encode())
csign = md5.hexdigest()
md5 = hashlib.md5()
md5.update((pd_id + timestamp + csign).encode())
csign = md5.hexdigest()
return csign
def CalcCardSign(cardid, cardkey, timestamp, passwd):
md5 = hashlib.md5()
md5.update(passwd + timestamp + cardid + cardkey)
return md5.hexdigest()
def HttpRequest(url, body_data, img_data=""):
rsp = Rsp()
post_data = body_data
files = {
'img_data':('img_data',img_data)
}
header = {
'User-Agent': 'Mozilla/5.0',
}
rsp_data = requests.post(url, post_data,files=files ,headers=header)
rsp.ParseJsonRsp( rsp_data.text)
return rsp
class FateadmApi():
# API接口调用类
# 参数(appID,appKey,pdID,pdKey)
def __init__(self, app_id, app_key, pd_id, pd_key):
self.app_id = app_id
if app_id is None:
self.app_id = ""
self.app_key = app_key
self.pd_id = pd_id
self.pd_key = pd_key
self.host = FATEA_PRED_URL
def SetHost(self, url):
self.host = url
#
# 查询余额
# 参数:无
# 返回值:
# rsp.ret_code:正常返回0
# rsp.cust_val:用户余额
# rsp.err_msg:异常时返回异常详情
#
def QueryBalc(self):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign
}
url = self.host + "/api/custval"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("query succ ret: {} cust_val: {} rsp: {} pred: {}".format( rsp.ret_code, rsp.cust_val, rsp.err_msg, rsp.pred_rsp.value))
else:
LOG("query failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 查询网络延迟
# 参数:pred_type:识别类型
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg: 异常时返回异常详情
#
def QueryTTS(self, pred_type):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
"predict_type":pred_type,
}
if self.app_id != "":
#
asign = CalcSign(self.app_id, self.app_key, tm)
param["appid"] = self.app_id
param["asign"] = asign
url = self.host + "/api/qcrtt"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("query rtt succ ret: {} request_id: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.err_msg))
else:
LOG("predict failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 识别验证码
# 参数:pred_type:识别类型 img_data:图片的数据
# 返回值:
# rsp.ret_code:正常返回0
# rsp.request_id:唯一订单号
# rsp.pred_rsp.value:识别结果
# rsp.err_msg:异常时返回异常详情
#
def Predict(self, pred_type, img_data, head_info = ""):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp": tm,
"sign": sign,
"predict_type": pred_type,
"up_type": "mt"
}
if head_info is not None or head_info != "":
param["head_info"] = head_info
if self.app_id != "":
#
asign = CalcSign(self.app_id, self.app_key, tm)
param["appid"] = self.app_id
param["asign"] = asign
url = self.host + "/api/capreg"
files = img_data
rsp = HttpRequest(url, param, files)
if rsp.ret_code == 0:
LOG("predict succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("predict failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg))
if rsp.ret_code == 4003:
#lack of money
LOG("cust_val <= 0 lack of money, please charge immediately")
return rsp
#
# 从文件进行验证码识别
# 参数:pred_type;识别类型 file_name:文件名
# 返回值:
# rsp.ret_code:正常返回0
# rsp.request_id:唯一订单号
# rsp.pred_rsp.value:识别结果
# rsp.err_msg:异常时返回异常详情
#
def PredictFromFile( self, pred_type, file_name, head_info = ""):
with open(file_name, "rb") as f:
data = f.read()
return self.Predict(pred_type,data,head_info=head_info)
#
# 识别失败,进行退款请求
# 参数:request_id:需要退款的订单号
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg:异常时返回异常详情
#
# 注意:
# Predict识别接口,仅在ret_code == 0时才会进行扣款,才需要进行退款请求,否则无需进行退款操作
# 注意2:
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
#
def Justice(self, request_id):
if request_id == "":
#
return
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
"request_id":request_id
}
url = self.host + "/api/capjust"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("justice succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("justice failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
#
# 充值接口
# 参数:cardid:充值卡号 cardkey:充值卡签名串
# 返回值:
# rsp.ret_code:正常返回0
# rsp.err_msg:异常时返回异常详情
#
def Charge(self, cardid, cardkey):
tm = str( int(time.time()))
sign = CalcSign( self.pd_id, self.pd_key, tm)
csign = CalcCardSign(cardid, cardkey, tm, self.pd_key)
param = {
"user_id": self.pd_id,
"timestamp":tm,
"sign":sign,
'cardid':cardid,
'csign':csign
}
url = self.host + "/api/charge"
rsp = HttpRequest(url, param)
if rsp.ret_code == 0:
LOG("charge succ ret: {} request_id: {} pred: {} err: {}".format( rsp.ret_code, rsp.request_id, rsp.pred_rsp.value, rsp.err_msg))
else:
LOG("charge failed ret: {} err: {}".format( rsp.ret_code, rsp.err_msg.encode('utf-8')))
return rsp
##
# 充值,只返回是否成功
# 参数:cardid:充值卡号 cardkey:充值卡签名串
# 返回值: 充值成功时返回0
##
def ExtendCharge(self, cardid, cardkey):
return self.Charge(cardid,cardkey).ret_code
##
# 调用退款,只返回是否成功
# 参数: request_id:需要退款的订单号
# 返回值: 退款成功时返回0
#
# 注意:
# Predict识别接口,仅在ret_code == 0时才会进行扣款,才需要进行退款请求,否则无需进行退款操作
# 注意2:
# 退款仅在正常识别出结果后,无法通过网站验证的情况,请勿非法或者滥用,否则可能进行封号处理
##
def JusticeExtend(self, request_id):
return self.Justice(request_id).ret_code
##
# 查询余额,只返回余额
# 参数:无
# 返回值:rsp.cust_val:余额
##
def QueryBalcExtend(self):
rsp = self.QueryBalc()
return rsp.cust_val
##
# 从文件识别验证码,只返回识别结果
# 参数:pred_type;识别类型 file_name:文件名
# 返回值: rsp.pred_rsp.value:识别的结果
##
def PredictFromFileExtend( self, pred_type, file_name, head_info = ""):
rsp = self.PredictFromFile(pred_type,file_name,head_info)
return rsp.pred_rsp.value
##
# 识别接口,只返回识别结果
# 参数:pred_type:识别类型 img_data:图片的数据
# 返回值: rsp.pred_rsp.value:识别的结果
##
def PredictExtend(self,pred_type, img_data, head_info = ""):
rsp = self.Predict(pred_type,img_data,head_info)
return rsp.pred_rsp.value
登录成功了!就可以拿cookie了!
- 手动处理:通过抓包工具获取cookie值,将该值封装到headers中。(不建议)
- 自动处理:新建session对象,session去请求之后,session里面包含cookie
sessions = requests.Session()
response = sessions.post(url=login_url,headers=headers,data=data)
五 代理模式
代理的作用:
- 突破自身IP访问的限制。
- 隐藏自身真实IP
代理相关的网站:
- 快代理
- 西祠代理
- www.goubanjia.com
- 代理ip的类型:
- http:应用到http协议对应的url中
- https:应用到https协议对应的url中
代理ip的匿名度:
- 透明:服务器知道该次请求使用了代理,也知道请求对应的真实ip
- 匿名:知道使用了代理,不知道真实ip
- 高匿:不知道使用了代理,更不知道真实的ip
百度查询ip验证代理是否成功
# 本机ip115.24.229.31
import requests
url = 'https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': '****'
}
page_text = requests.get(url=url,headers=headers,proxies={"https":'123.55.98.193:9999'}).text
with open('ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
六 异步爬虫
有点难,,,稍后总结
七 selenium模块
selenium模块:便捷实现模拟登录,基于浏览器自动化的一个模块
使用流程
- 环境安装:pip install selenium
- 下载一个浏览器的驱动程序 (谷歌浏览器)
- 下载路径:http://chromedriver.storage.googleapis.com/index.html
- 驱动程序和浏览器的映射关系:http://blog.csdn.net/huilan_same/article/details/51896672 - 实例化一个浏览器对象
- 编写基于浏览器自动化的操作代码
- 发起请求:get(url)
- 标签定位:find系列的方法
- 标签交互:send_keys(‘xxx’)
- 执行js程序:excute_script(‘jsCode’)
- 前进,后退:back(),forward()
- 关闭浏览器:quit() - selenium处理iframe
- 1.如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id)
- 2.动作链(拖动):from selenium.webdriver import ActionChains
- action = ActionChains(bro):实例化一个动作链对象
- click_and_hold(div):长按且点击操作
- move_by_offset(x,y)
- perform() 让动作链立即执行
- action.release() 释放动作链对象
使用超级鹰模拟登录12306
bro.save_screenshot当前页面截图
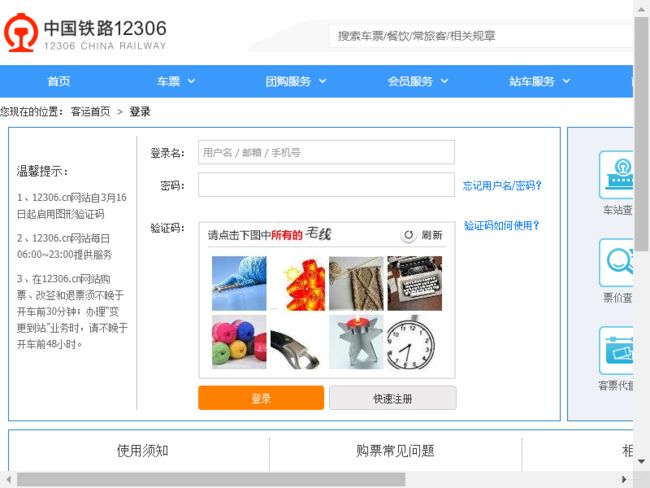
crop根据指定区域进行图片裁剪结果

代码
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
chaojiying = Chaojiying_Client('bobo328410948', 'bobo328410948', '899370') #用户中心>>软件ID 生成一个替换 96001
im = open('12306.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 9004)['pic_str'])
上述代码为超级鹰提供的示例代码
使用selenium打开登录页面
from selenium import webdriver
import time
from PIL import Image
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from selenium.webdriver import ActionChains
#实现无可视化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
bro = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options,options=option)
bro.get('https://kyfw.12306.cn/otn/login/init')
time.sleep(1)
#save_screenshot就是将当前页面进行截图且保存
bro.save_screenshot('aa.png')
#确定验证码图片对应的左上角和右下角的坐标(裁剪的区域就确定)
code_img_ele = bro.find_element_by_xpath('/html/body/div[6]/div/form/div/ul[2]/li[4]/div/div/div[3]/img')
location = code_img_ele.location # 验证码图片左上角的坐标 x,y
print('location:',location)
size = code_img_ele.size #验证码标签对应的长和宽
print('size:',size)
#左上角和右下角坐标
rangle = (
int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
#至此验证码图片区域就确定下来了
i = Image.open('./aa.png')
code_img_name = './code.png'
#crop根据指定区域进行图片裁剪
frame = i.crop(rangle)
frame.save(code_img_name)
#将验证码图片提交给超级鹰进行识别
chaojiying = Chaojiying_Client('bobo328410948', 'bobo328410948', '899370') #用户中心>>软件ID 生成一个替换 96001
im = open('code.png', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 9004)['pic_str'])
result = chaojiying.PostPic(im, 9004)['pic_str']
all_list = [] #要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]
if '|' in result:
list_1 = result.split('|')
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = int(list_1[i].split(',')[0])
y = int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
#遍历列表,使用动作链对每一个列表元素对应的x,y指定的位置进行点击操作
for l in all_list:
x = l[0]
y = l[1]
ActionChains(bro).move_to_element_with_offset(code_img_ele, x, y).click().perform()
time.sleep(0.5)
bro.find_element_by_id('username').send_keys('[email protected]')
time.sleep(2)
bro.find_element_by_id('password').send_keys('bobo_15027900535')
time.sleep(2)
bro.find_element_by_id('loginSub').click()
time.sleep(30)
bro.quit()
八 scrapy框架⭐⭐⭐
本章节写自成一篇,包含以下内容,移步爬虫高手——scrapy框架