MySQL从入门到精通教程
MySQL从入门到精通笔记
来源于有道云笔记
终端操纵mysql数据库
以管理员身份运行cmd
net start mysql --------启动服务
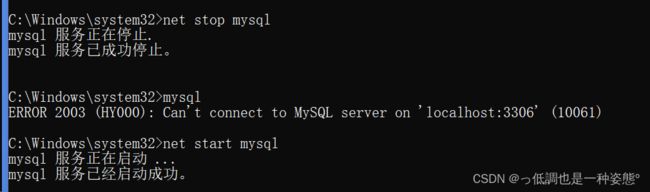
发生系统错误 5。
拒绝访问。
- 启动:service mysqld start--------------------net start mysql(管理员身份运行)
- 停止:服务 mysqld 停止
- 重启:服务 mysqld restart
- 重载配置:service mysqld reload
- mysql -uroot -p 进入本地数据库
help 帮助手册
show variables like "%char%";----查看数据库编码情况
利用标准SQL语句对数据库操作
show databases 查看所有数据库
show engines 查询存储引擎
describe 数据表名 查看表结构,简写desc 查看单列 desc 数据表名 列名
modify 修改子句定义字段
show variables like "%char%";------查看数据库编码

新建数据库
create database new_databases;
删除数据库
drop database new_database;
操作数据表
show tables;(需指定数据库,use 数据库)
show columns from 数据表 显示数据表属性,类型等其它信息
新建数据表
use new_databases; create table new_table( -> id int, -> username char(10));
if not exists 屏蔽错误
查询指定行 select * from 数据表 where 条件表达式
删除数据表
drop table new_table;
复制表
create table 数据表名
as like 源数据表名
不加as只是复制表的结构不复制内容
删除表
drop table 数据表名
删除多张数据表可用逗号“,”分隔
重命名表
rename table 源数据表名 to 新数据表名
可对多个数据表进行重命名,多个表之间用逗号“,”分隔
查看表数据
select * from 数据表
运算符
^开头
$结尾
mysql> select id=2,id,name,pwd from tb_admin;
+------+----+-----------+-----+
| id=2 | id | name | pwd |
+------+----+-----------+-----+
| 0 | 1 | mr | 111 |
| 1 | 2 | 肖承聪 | 222 |
| 0 | 3 | 张三 | 333 |
+------+----+-----------+-----+
查看id等于2的,id等于2返回值为1,否则0
插入数据
- insert into 数据表 values(值1,值2...);-----------------------(完整插入)
insert into 数据表 (列1,列2....)values(值1,值2....);------------(部分插入)
insert into 数据表 (列1,列2,列3....)
values(值1,值1,值1)
,(值2,值2,值2)
,.........
- insert into 数据表
set id=8,name='xiao',pwd=888;-------------------(指定插入)
- 插入查询结果
insert into 数据库名.插入到的表
(列1,列2....)
select 列1,列2 from 插入到的表
修改数据
update 数据表 set 列=666 where 条件表达式
查询指定行 select * from 数据表 where 条件表达式
删除数据
delete from 数据表 where 条件表达式
truncate table 数据表名--------------清空数据表内容
更新数据
update new_table -> set id=2,username="cat" -> where id =1;
数据查询
*代表所有列,可单独查列1,列2 之间用逗号隔开
查询一个数据表
select * from 数据表
查询表中的一列或多列
select 列1,列2 from 数据表
从一个表或者多个表获取数据
select 数据表1.列,数据表1.列,数据表2.列,数据表2.列 from 数据表1,数据表
查询指定数据
select * from 数据表 where 列=‘查询的内容’
select *from 表名 where 列 [not] in (元素1,元素2...)---not可选项 ,相反的意思
去空格查询
rtim
BETWEEN范围查询
select *from 数据表 where 列 [not] between 取值1 and 取值2
LIKE字符匹配查询
select * from 数据表 where 列 like ‘内容%’----------- %匹配一个或多个---------------- _匹配一个
IS NULL查询空值
select * from 数据表 where 列 is null
AND,OR多条件查询
select * from 数据表 where 条件1 and 条件2....-----需两个都满足
select * from 数据表 where 条件1 or 条件2....-----满足一个即可
DISTINCT去除结果中的重复行
select distinct 列 from 数据表
ORDER BY对查询结果排序
order by 字段名 [asc(升)|esc(降)]
GROUP BY 分组查询
in 查询(规定多值)=规定一个值
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1,value2,...);
LIMIT限制查询结果数量
select * from 数据表 order by id asc limit 3;
按照id 编号进行升序排序,显示前3条记录
select * from 数据表 order by id asc limit 1,2;
从编号1开始,查询两条记录
count()函数 查看()有多少记录
sum()函数 计算字段数值总和
avg( )函数 求表中某个字段取值的平均值
max()函数 求最大值
min()函数 最小值
连接查询
EXISTS 子查询 ,返回一个真假值,判断括号内的子查询是否真,真就执行外层查询
select *from 数据表 where exists (select * from 数据表 where id =27)
查询表中是否存在id值为27,存在则执行括号外层数据表内容
当exists与其它查询条件一起使用时,需使用and或者or来连接表达式exists关键字
UNION合并查询
select user from数据表1
union
select user from 数据表2---------------合并表1和表2user的内容去除重复值
union all 不去除重复项
定义表和字段的别名
为表取别名
select * from tb_program p where p.talk='PHp';
tb_program表的别名为p;p.talk表示tb_program表中的talk字段
为字段取别名
select talk AS new from tb_program
正则表达式
字段名 regexp '匹配方式'
* 任意多少个
^开头
$结尾
. 匹配任意字符包括回车换行符
[字符集合] 匹配字符集中任意一个字符
[^字符集合] 匹配除字符集合以外的任意一个字符
s1|s2|s3 匹配s1,s2和s3中的任意一个字符串
+ 匹配多个该字符之前的字符,包括一个-----------'j+a';查询字段中a字符前面至少一个j字符的记录
字符串{n}匹配字符串出现n次
字符串{m,n}匹配字符串出现至少m次,最多n次
CREATE TABLE 时的 SQL PRIMARY KEY 约束
下面的 SQL 在 "Persons" 表创建时在 "P_Id" 列上创建 PRIMARY KEY 约束:
MySQL:CREATE TABLE Persons
( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (P_Id) )
SQL Server / Oracle / MS Access:CREATE TABLE Persons
( P_Id int NOT NULL PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
ALTER TABLE 时的 SQL PRIMARY KEY 约束
当表已被创建时,如需在 "P_Id" 列创建 PRIMARY KEY 约束,请使用下面的 SQL:
MySQL / SQL Server / Oracle / MS Access:
ALTER TABLE Persons
ADD PRIMARY KEY (P_Id)
如需命名 PRIMARY KEY 约束,并定义多个列的 PRIMARY KEY 约束,请使用下面的 SQL 语法:
MySQL / SQL Server / Oracle / MS Access:
ALTER TABLE Persons
ADD CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName)
注释:如果您使用 ALTER TABLE 语句添加主键,必须把主键列声明为不包含 NULL 值(在表首次创建时)。
撤销 PRIMARY KEY 约束
如需撤销 PRIMARY KEY 约束,请使用下面的 SQL:
MySQL:
ALTER TABLE Persons
DROP PRIMARY KEY
SQL Server / Oracle / MS Access:
ALTER TABLE Persons
DROP CONSTRAINT pk_PersonID
常用函数
备份数据库
备份一个数据库(终端操作无需进入mysql)
mysqldump -uroot -p dbname table1 table2....>BackuoName.sql
dbname:数据库的名称
table1和table2参数表示表的名称,没有该参数时将备份整个数据库
BackNme.sql 参数表示备份文件的名称,文件名前可加一个绝对路径
使用rot用户备份tes数据库下的studen表
mysqldump -uroot -p test student >D:\student.sql
备份多个数据库
mysqldump -u username -p --databases dbname1 dbname2 >BackName.sql
加上databases这个选项,后面可以加上很多数据库的名称
备份所有数据库
mysqldump -u root -p --all -databases >D:\all.sql
数据恢复
mysql -uroot -p [dbname]
dbname 参数表示数据库名称
指定数据库名,表示还原该数据库下的数据表,不指定数据库名时,表示还原特定一个数据库
mysql -u root -p
表的导入与导出
musqldump
mysqldump -u root -p --xml dbname table >D:/name.xml
将website数据库下的jsj表导出为xml格式到D盘,文件名为xsgl.xml
mysqldump -u root -p --xml website jsj >D:/xsgl.xml
mysql
mysql -u root -p -e "select * from 语句" dbname >D:/sfzh.txt
使用-e选项就可执行sql语句,select用来查询记录
mysql -u root -p -e "select * from sfzh" website >D:/sfzh.txt

可用mysql导出xml文件和htnl文件
mysql -u root -p --xml或html -e "select * from sfzh" website >D:/sfzh.txt
存储过程与存储函数
创建存储过程
create procedure proc_name ([proc_parameter[....]])
[characteristic.....] routine_body
sp_name参数时存储过程的名称;proc_parameter 表示存储过程的参数列表;characteristic参数指定存储过程的特性;routine_body 参数时sql代码的内容,可以用begin.....end来标识sql代码的开始和结束。
proc_parameter中的参数由3部分组成,它们分别时输入输出类型,参数名称和参数类型。其中形式为[in | out | inout ]param_name type。param_name 参数时存储过程的参数名称;type参数指定存储过程的参数类型,可以为mysql数据库的任意类型。
mysql存储过程的语句块以begin开始,以end结束。内部以分号结束,分号“;”应更改为其它字符,更改结束标志可以用关键字delimiter定义,例如:将myql结束符设置为//
- mysql>delimiter //
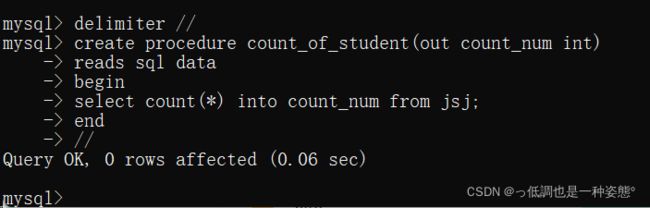
定义一个输出变量count_num,存储过程应用select语句从jsj表中获取记录总数,最后将结果传递给变量count_num。
show create count_of_student 查看存储过程
创建存储函数
create function sp_name ([proc_parameter[,....]])
returns type
[characteristic.....] routine_body
| 参数 |
说明 |
| sp_name |
存储函数的名称 |
| fun_parameter |
存储函数的参数列表 |
| returns type |
指定返回值的类型 |
| characteristic |
指定存储过程的特性 |
| routine_body |
sql代码的内容 |
变量的应用
1.局部变量
declare a int
使用default为变量指定默认值
declare a int default 10
2全局变量(会话变量)
会话变量名以字符’@‘作为起始符
光标的应用
创建触发器
create trigger 触发器名 before | after 触发事件
on 表名 for each row 执行语句
for each row 表示任何一条记录上的操作满足触发事件都会触发该触发器(包括插入,更新,删除)
执行语句指触发器被触发后执行的程序
例:
创建一个由插入命令insert触发的触发器auto_save_time
(1)创建一个名称为timelog的表格
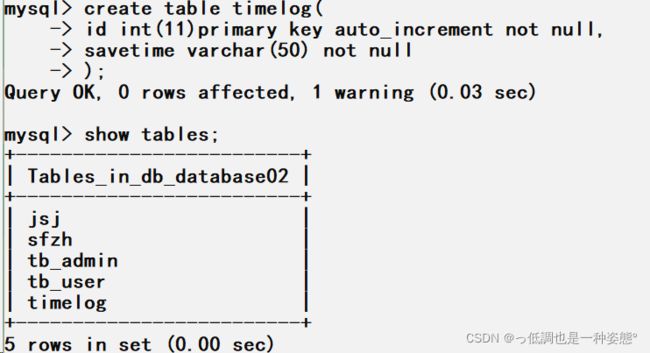
(2)创建名称为auot_save_time的触发器
定义了结束符为//

接下来通过向jsj表插入一条信息来查看触发器的作用

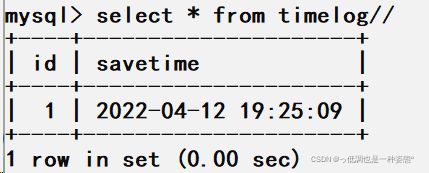
创建具有多条执行语句的触发器
create trigger 触发器名 before | after 触发事件
on 表名 for each row 执行语句
begin
执行语句列表
end
begin与end之间的多条执行语句需以结束分隔符“;”分开
创建一个delete触发多条执行语句的触发器delete_time_info
------创建timeinfo数据表
create table timeinfo( id int(11) primary key auto_increment, info varchar(50) not null )//
-------创建由delete触发多条执行语句的触发器 delect_time_info
create trigger delect_time_info after delete on jsj for each row begin insert into timelog(savetime)values(now()); insert into timeinfo(info)values('deleteact'); end //
---------执行delete并查看触发结果

查看触发器
show triggers;-------选择xsgl数据库查看该数据库中存在的触发器
select * from information_schema.triggers;-------查看数据库中所有触发器的详细信息
information_schema是mysql中默认存在的库
select * from information_schema.reiggers where trigger_name='触发器名称';---------查看指定触发器内容
删除触发器
drop trigger 触发器名称;
事务的应用
MyISAM类型的数据表不能支持事务,只有InnoDB或BDB
create table table_name(field_defitions)type=innodb/bdb
table_name为表名,而field_defitions为表内定义的字段等属性,type指定数据表的类型,既可以是inodb也可以是bdb类型
alter table table_name type=innodb/bdb;----------在原有的数据表中可以更改支持的事务处理的类型
初始化事务
start transaction
创建事务
向名称为jsj的数据表插入一条记录,讲解事务的从创建。首先打开数据库,选定某个数据库,然后初始化事务,最后创建事务,向指定的数据表中添加记录
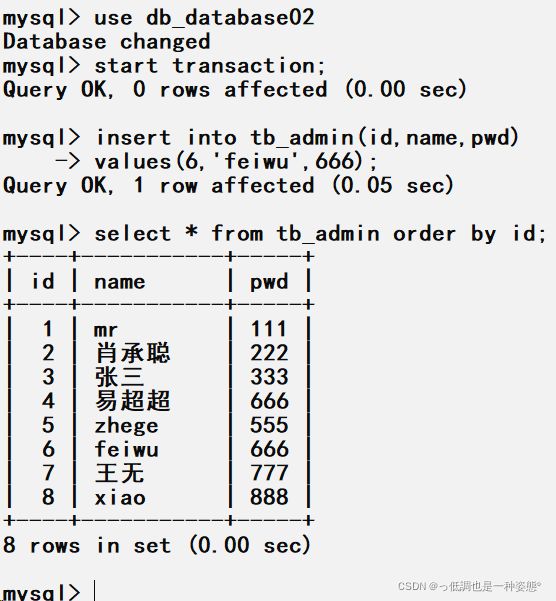
在用户插入新表为innodb类型或更新原来表类型为innodb时,输入命令却提示“The InnoDB feature is disabled;you need 'InnoDB' to have it working”警告,则说明InnoDB表类型并没有被开启,用户需要在MySQL文件目录下找到my.ini文件,定位skip_innodb选项位置,改为#skip_innodb后保存文件,重新启动MySQL服务器,即可令数据库支持innodb类型表。
提交事务
commit
因为事务具有孤立性,并未把结果写入磁盘中
撤销事务
rollback
如果执行一个回滚操作,则在start transction(初始化事务)命令后的所有SQL语句都将执行回滚操作。如果用户开启事务后,没有提交事务,则默认为自动回滚状态,既不保留用户之前的任何操作
事务的存在周期
从start transction指令开始直到用户输入commit结束
事务不支持嵌套,在多个事务中,它自动默认会提交前一个事务,在MySQL中很多命令都隐藏执行commit命令
自动提交
set autocommit=0;
关闭自动提交参数

事务的孤立级
1.serializable(序列号)
2.repeatable read(可重读)
3.read committed(提交后读)
4.read uncommitted(未提交读)
修改事务的孤立级,必须首先获取super优先权

获取当前事务孤立级变量的值
select @@tx_isolation;
伪事务
对MyISAM表进行锁定操作,以次过程代替事务型表InnoDB,即应用表锁来实现伪事务
用表锁定代替事务
在MySQL的MyISMAM类型数据表中,并不支持commit和rollback(回滚)命令,当用户对数据库执行插入更新删除等操作时,这些变化的数据都被立即保存在磁盘中。
(1)为指定数据表添加锁定
lock tables table_name lock_type1,lock_type2....
其中,table_name为被锁定的表名,lock_type为锁定类型,该类型包括以读方式(read)锁定表;以写方式(write)锁定表
(2)解锁操作,释放该表的锁定状态
unlock tables;使用之后,所有处于锁定状态都会被释放
1.以读方式锁定数据表
lock table tb_admin read;
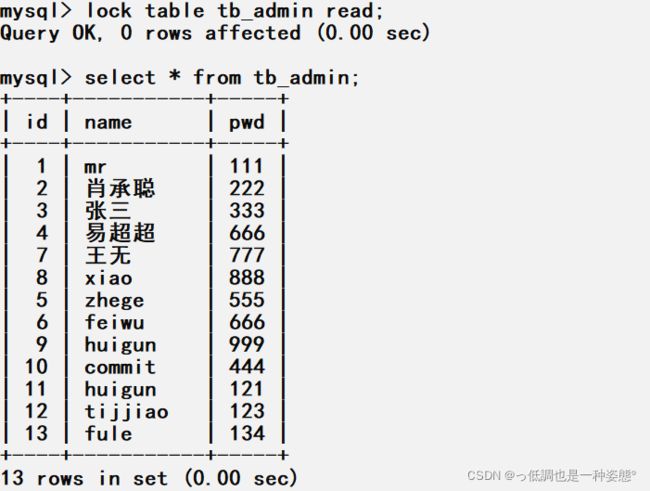
当以读锁定数据表时插入记录时会出错

解锁

lock_type参数中,除了read锁定,其它的参数可以执行insert操作,或者select,但结果却不径相同
2.以写方式锁定数据表
lock_tables tb_admin write;
该表是写锁定,并不能限制当前锁定用户的查询操作,而再打开一个新用户会话,重新mysql连接,执行上诉过程查询,并没有结果显示,而释放锁定后,其它访问数据库的用户都可以查看数据表的内容。
事件
查看事件是否开启
show variables like 'event_scheduler'; select @@event_scheduler; show processlist;
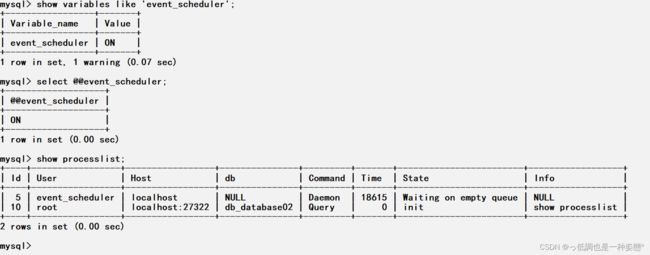
开启事件
1.通过设置全局参数修改(重启会恢复原来状态)
set global event_scheduler=on;
2.更改配置文件(始终设置)
在MySQL的配置文件my.ini(window系统)/my.cng(linux系统)中,找到【mysql】,然后在下面添加event_scheduler=on
保存并重新启动mysql服务器

创建事件
在 MySQL 中,可以通过 CREATE EVENT 语句来创建事件,其语法格式如下:
CREATE EVENT [IF NOT EXISTS] event_name ON SCHEDULE schedule [ON COMPLETION [NOT] PRESERVE] [ENABLE | DISABLE | DISABLE ON SLAVE] [COMMENT 'comment'] DO event_body;
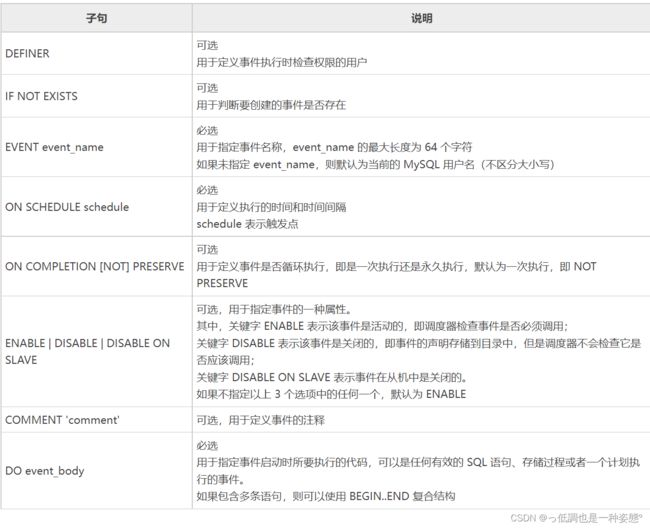
在 ON SCHEDULE 子句中,参数 schedule 的值为一个 AT 子句,用于指定事件在某个时刻发生,其语法格式如下:
AT timestamp [+ INTERVAL interval]... | EVERY interval [STARTS timestamp [+ INTERVAL interval] ...] [ENDS timestamp[+ INTERVAL interval]...]
参数说明如下:
- timestamp:一般用于只执行一次,表示一个具体的时间点,后面加上一个时间间隔,表示在这个时间间隔后事件发生。
- EVERY 子句:用于事件在指定时间区间内每隔多长时间发生一次,其中 STARTS 子句用于指定开始时间;ENDS 子句用于指定结束时间。
- interval:一般用于周期性执行,表示一个从现在开始的时间,其值由一个数值和单位构成。例如,使用“4 WEEK”表示 4 周,使用“'1:10'HOUR_MINUTE”表示 1 小时 10 分钟。间隔的长短用 DATE_ADD() 函数支配。
interval 参数可以是以下值:
YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE |
WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE |
DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND一般情况下,不建议使用不标准(以上未加粗关键字)的时间单位。
例 1
在 test 数据库中创建一个名称为 e_test 的事件,用于每隔 5 秒向表 tb_eventtest 中插入一条数据。
创建 tb_eventtest 表,SQL 语句和运行结果如下:
mysql> CREATE TABLE tb_eventtest( -> id INT(11) PRIMARY KEY AUTO_INCREMENT, -> user VARCHAR(20), -> createtime DATETIME); Query OK, 0 rows affected (0.07 sec)
创建 e_test 事件,SQL 语句和运行结果如下:
mysql> CREATE EVENT IF NOT EXISTS e_test ON SCHEDULE EVERY 5 SECOND -> ON COMPLETION PRESERVE -> DO INSERT INTO tb_eventtest(user,createtime)VALUES('MySQL',NOW()); Query OK, 0 rows affected (0.04 sec)
创建事件后,查询 tb_eventtest 中的数据,SQL 语句和运行结果如下:
mysql> SELECT * FROM tb_eventtest; +----+-------+---------------------+ | id | user | createtime | +----+-------+---------------------+ | 1 | MySQL | 2020-05-21 10:41:39 | | 2 | MySQL | 2020-05-21 10:41:44 | | 3 | MySQL | 2020-05-21 10:41:49 | | 4 | MySQL | 2020-05-21 10:41:54 | +----+-------+---------------------+ 4 rows in set (0.01 sec)
从结果可以看出,系统每隔 5 秒插入一条数据,这说明事件创建执行成功了。
修改事件
在 MySQL 中,事件创建之后,可以使用 ALTER EVENT 语句修改其定义和相关属性。
修改事件的语法格式如下:
ALTER EVENT event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;ALTER EVENT 语句中的子句与创建事务一节中讲解的基本相同,这里不再赘述。另外,ALTER EVENT 语句还有一个用法就是让一个事件关闭或再次让其活动。
例 1
修改 e_test 事件,让其每隔 30 秒向表 tb_eventtest 中插入一条数据,SQL 语句和运行结果如下所示:
mysql> ALTER EVENT e_test ON SCHEDULE EVERY 30 SECOND -> ON COMPLETION PRESERVE -> DO INSERT INTO tb_eventtest(user,createtime) VALUES('MySQL',NOW()); Query OK, 0 rows affected (0.04 sec) mysql> TRUNCATE TABLE tb_eventtest; Query OK, 0 rows affected (0.04 sec) mysql> SELECT * FROM tb_eventtest; +----+-------+---------------------+ | id | user | createtime | +----+-------+---------------------+ | 1 | MySQL | 2020-05-21 13:23:49 | | 2 | MySQL | 2020-05-21 13:24:19 | +----+-------+---------------------+ 2 rows in set (0.00 sec)
由结果可以看出,修改事件后,表 tb_eventtest 中的数据由原来的每 5 秒插入一条,变为每 30 秒插入一条。
使用 ALTER EVENT 语句还可以临时关闭一个已经创建的事件。
例 2
临时关闭事件 e_test 的具体代码如下所示:
mysql> ALTER EVENT e_test DISABLE;
Query OK, 0 rows affected (0.00 sec)查询 tb_eventtest 表中的数据,SQL 语句如下:
SELECT * FROM tb_eventtest;
为了确定事件已关闭,可以查询两次(每次间隔 1 分钟)tb_eventtest 表的数据,SQL 语句和运行结果如下所示:
mysql> TRUNCATE TABLE tb_eventtest;
Query OK, 0 rows affected (0.05 sec)
mysql> SELECT * FROM tb_eventtest;
Empty set (0.00 sec)
mysql> SELECT * FROM tb_eventtest;
Empty set (0.00 sec)由结果可以看出,临时关闭事件后,系统就不再继续向表 tb_eventtest 中插入数据了。
删除事件
在 MySQL 中,可以使用 DROP EVENT 语句删除已经创建的事件。语法格式如下:
DROP EVENT [IF EXISTS] event_name;
例 3
删除事件 e_test,SQL 语句和运行结果如下:
mysql> DROP EVENT IF EXISTS e_test; Query OK, 0 rows affected (0.01 sec) mysql> SELECT * FROM information_schema.events \G Empty set (0.00 sec)
MySQL性能优化
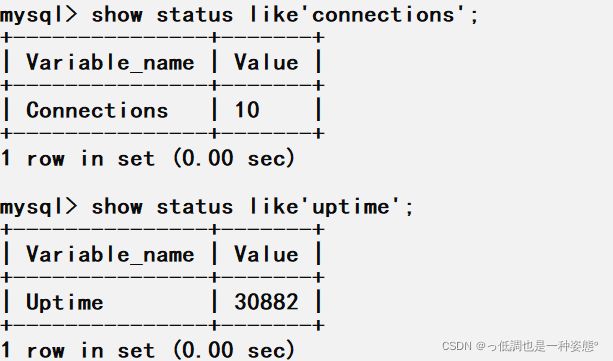
查询mysql性能
show status like 'value';
- connection:连接mysql服务器的次数
- uptime:mysql服务器上线时间
- slow_queries:慢查询的次数
- com_select:查询操作的次数
- com_insert:插入操作的次数
- com_delete:删除操作的次数
mysql中存在查询InnoDB类型的表的一些参数。例如,Innodb_row_read参数表示select语句查询的记录数;Innodb_row_insert参数表示insert语句插入的记录数等。
优化查询
explain select 语句;
explain select * from jsj; 或describe select * from sfzh;可缩写desc

各字段所代表的意义:
- id 列:指出在整个查询中select的位置。
- table 列:存放所查询的表名。
- type 列:连接类型,该列中存储很多值,范围从const到all。
- possible_keys 列:指出为了提高查找速度,在mysql中可以使用的索引。
- key 列:指出实际使用的键。
- rows 列:该表的总行数。
- extra 列:包含一些其它信息,设计mysql如何处理查询。
索引对查询速度的影响
mysql> select * from tb_admin; +----+-----------+-----+ | id | name | pwd | +----+-----------+-----+ | 1 | mr | 111 | | 2 | 肖承聪 | 222 | | 3 | 张三 | 333 | | 4 | 易超超 | 666 | | 7 | 王无 | 777 | | 8 | xiao | 888 | | 5 | zhege | 555 | | 6 | feiwu | 666 | | 9 | huigun | 999 | | 10 | commit | 444 | | 11 | huigun | 121 | | 12 | tijjiao | 123 | | 13 | fule | 134 | +----+-----------+-----+ 13 rows in set (0.00 sec) mysql> explain select * from tb_admin where pwd=666; +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | tb_admin | NULL | ALL | NULL | NULL | NULL | NULL | 13 | 10.00 | Using where | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) ------------------------创建索引前rows是13,意味着数据库存在的13条数据读别查询了一遍 mysql> create index index_name on tb_admin(pwd);------创建索引 Query OK, 13 rows affected (0.09 sec) Records: 13 Duplicates: 0 Warnings: 0 mysql> explain select * from tb_admin where pwd='666'; +----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | tb_admin | NULL | ref | index_name | index_name | 137 | const | 2 | 100.00 | NULL | +----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.05 sec) --------------------------创建索引后查询从7行减少到2行,减少了服务器的开销
使用索引查询
1.用关键字like优化索引查询
explain select * from tb_admin where pwd='6%'; ------- %在6前就起不到优化作用
2.查询语句中使用多列索引
create index index_name on tb_admin(name,pwd); ----应用set时,索引不能正常使用,意味着索引并未在mysql优化中起到作用必须使用第一字段name,索引才可以正常使用
3.查询语句中使用关键字or
explain select * from tb_admin where name='张三 or pwd='666';
优化数据库结构
将字段很多的表分解成多个表
mysql> desc tb_admin1; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | pwd | varchar(30) | NO | | NULL | | +-------+-------------+------+-----+---------+----------------+
联表查询:
select * from tb_admin,tb_admin1 where tb_admin.id=tb_admin1.id;
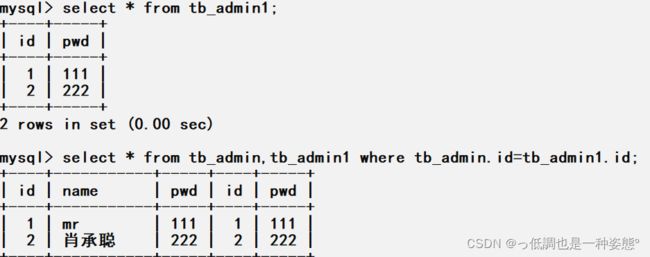
增加中间表
优化插入记录的速度
1.禁用索引
alter table 表名 disable keys; 重新开启 alter table 表名 enable keys;
新创建的表可等记录导入以后再创建索引可提高导入数据的速度
2.禁用唯一性检查
set unique_checks=0; 重新开启 set unique_checks=1;
3,优化insert语句
当插入大量数据时,建议使用一个select语句插入多条记录的方式
1.分析表
analyze table 表名1[表名2...];
在分析过程中,数据库系统会对表加一个只读锁。

上面结果显示了4条信息
- table:表示表的名称。
- op:表示执行的操作。analyze表示分析操作,check表示进行检查查找,optimize表示进行优化操作
- msg_type:表示信息类型,其显示的值通常为状态,警告,错误或信息。
- msg_text:显示信息。
2.检查表
check table 表名1[表名2...];
3.优化表
optimize table 表名1[表名2...];
查询高速缓存
检查高速缓存是否开启
show variables like '%query_cache%';
参数说明:
- have_query_cahce:表名服务器在默认安装条件下,是否已经配置查询高速缓存。
- query_cache_size:高速缓存分配空间,如果该空间为86,则分配给高速缓存空间的大小为86MB。如果为0,则表名高速缓存关闭
- query_cache_type:判断高速缓存开启状态,范围为0-2,如果为0或0ff时,表名高速缓存已经关闭;当该值为1或on时表名高速缓存已经打开
使用高速缓存
select sql_cache * from 表名;
* 一旦表由变化,使用这个表的高速缓存就会失效