ACL 2022:评估单词多义性不再困扰?一种新的基准“DIBIMT”
众所周知,单词多义性给NLP领域的研究带来了诸多困难,如词义消歧(Word Sense Disambiguation)、信息检索(IR, Information Retrieval)和机器翻译(MT, Machine Translation)等等。
而词汇歧义(Lexical Ambiguity)无疑是机器翻译领域面临的最大挑战之一。
在过去的几十年里,研究者也一直致力于调查由单词的多义性引起的错误翻译。在此研究范围内,一些研究认为模型能够学习接纳训练数据中存在的语义偏差,从而产生翻译错误。
实际上,最新的研究发现,训练数据中的语义偏差与翻译中的语义错误之间存在直接关联。
但是这些发现受到以下限制:
-
并非完全基于人工制定的基准; -
严重依赖于自动生成的资源来确定翻译的准确性; -
不包含多种语言组合。
而在 DIBIMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation 这项工作中,这支研究团队解决了上述缺点,并提出了DIBIMT。据所知,这是首个完全人工制定的评估基准。
它能够广泛研究语义偏差对MT的五种不同语言组合的影响,涵盖名词和动词。这五种语言组合分别是英语和下列一种语言中的一种:汉语、德语、意大利语、俄语和西班牙语。该基准不仅可以让社区更好地探索所描述的现象,还可以设计出更好地处理词汇歧义的创新MT系统。
此外,团队还在最新测试平台上测试最前沿的MT系统(包括商业和非商业),并对测试结果进行了全面的统计和语言分析。值得一提的是,这项研究也获得了2022 ACL best resource paper。
构建过程
DIBIMT基准侧重于检测NMT中的词义消歧偏差,即某些词对其一些更常用词义的偏差。创建这样的数据集需要做到以下两点:
1)一组包含多义词且语法正确的句子;
2)将每个目标词翻译成所涵盖语言的一组正确和错误的翻译,如图1所示。

首先,与先前的研究类似,团队依赖于BabelNet,这是一个大型多语言的百科全书词典,其节点是由同义词集表示的概念,即一组同义词,包含多种语言的词汇化并且来自各种异构资源,尤其是WordNet和维基词典(Wiktionary)。并对符号作出了一系列的定义。
其次,团队详细介绍了数据集的创建过程,即句子的选择以及条目的构建和过滤。
团队从两个主要来源收集初始项:WordNet 和Wiktionary。具体地说,团队成员使用了来自WordNet Tagged Glosses的示例,其中每个句子的目标词都与其同义词集进行了手动关联,从而很容易地提供第一批初始项。研究团队对原始句子应用过滤步骤,以选择可能对模型翻译更具挑战性的例子。
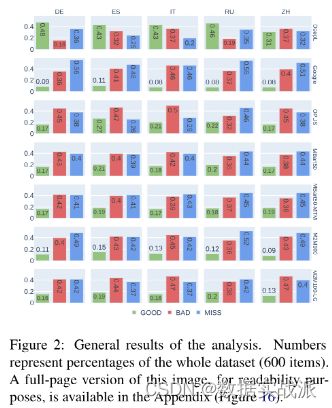
然后,开展数据集的注释任务。一旦初始项集准备好了,便可以继续进行注释阶段,将生成注释项。注释者分析了大约800个句子,丢弃了其中的200个句子,最终得到了5种语言的600个注释项。数据集统计数据如表1所示。正如预期的那样,从图2中可以注意到,注释者已经在所有语言中对图片中的词汇化进行了大量改进。
实际上,在各种语言中,平均增添了54%的好的词汇化,而现存的42%的词汇化已被删除。更重要的是,给定一个语言和两个包含相同同义词集的单词组成的句子,平均只有55%的情况下,他们也能分享这些单词的好的词汇化,从而证实假设,如果一个单词的所有同义词都是有效替换,可能会导致不正确的结果。
这些统计数据使团队得出一个简单但重要的结论:只有在有限的情况下,属于给定同义词集的词汇化才能被认为是所提供的目标词及其上下文的合适翻译等价物。


最后,是分析过程。
DIBIMT的分析过程相当简单:给定一个注释项
和翻译模型M,计算

即根据M对语言L中的S进行翻译。随后,团队成员采用Stanza对tLand进行标记、词性标注和词形还原(lemmatization)。紧接着,检查译文中的词形还原与
![]()
或
![]()
中所包含的是否匹配。如果不匹配,研究团队则将翻译标记为MISS;反之,根据与词性还原匹配的集合将其标记为GOOD或BAD。
实验结果及分析
首先,团队测试了各种商业和非商业模型,并报告了它们在DIBIMT评估指标上的表现:DeepL Translator,Google Translate,OPUS,MBart50,M2M100。
其次,图2报告了每个(模型、语言)对的分析的一般结果。考虑到被分类为MISS的分析项的比例很高,因此要求注释者对每种语言的70个随机样本进行检查,以发现原因并得出结果。在此过程中,团队发现了多种原因:
1)翻译中有单词遗漏(约19%,主要是中文和意大利语);
2)Stanza的符号化问题(约11%,主要是汉语和俄语)和词形还原问题(约12%,主要是意大利语和德语);
3)作为自身翻译的单词(约5%,通常在多语言神经模型中);
4)与源文本无关的翻译(约23%);
5)图片(约18%)或图片(约11%)中缺少术语。
随后,表3报告了non-MISS分析项目的准确性,如
![]()
除了DeepL的表现远远优于其他竞争对手之外,其他模型的得分都非常低,在20%-33%之间。更令人惊讶的是,Google翻译在跨语言中表现最差。
最后,除了准确性,DIBIMT还通过四个新的度量指标来分析翻译模型的语义偏差,结果如表4所示。有趣的是,DeepL再次证明是最好的,得分51%,远远低于其他模型平均80%的得分,大多数非商业模型的得分都≤80%。
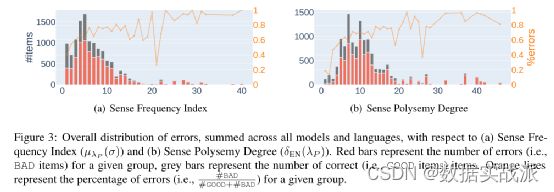
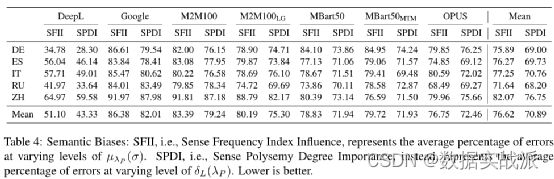
lSense Polysemy Degree Importance(SPDI):与SFII类似,团队还研究了一词多义的程度,即给定词可以有多少个含义,在多大程度上影响模型的消歧能力。图3(b)报告了所有项目的结果。不出所料,与频率指数类似,实验结果显示,多义词的程度越高,错误的可能就越大,这证实了模型仍然难以处理非常多义词。与SFII类似,SPDI被定义为不同多义程度的平均误差百分比,其值见表4。实验证明,DeepL再次表现最佳,证实了它在整体上的偏差最小。
lMost and More Frequent Senses(MFS or MFS+):为了进一步证实关于语义偏差的发现,团队研究了模型预测词义比目标更频繁的频率。分析结果如表5所示。
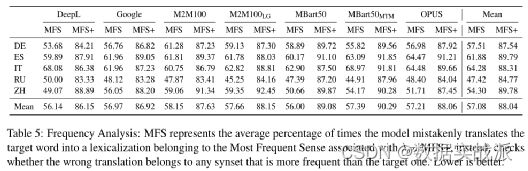
由上表可以观察到一些有趣的结果:首先,平均来说,近60%的错误反映了目标词的最常见词义(倒数第二栏);其次,几乎90%的错误是针对目标词(最后一栏)的更常见的意思进行的翻译。重要的是,无论商业与否,这些结果在不同的系统中是一致的。
虽然看起来很简单,NMT模型仍然强烈偏向于在训练过程中更可能遇到的词义;虽然这可能与神经网络的模式匹配性质有关,但它也在很大程度上取决于训练模型所依赖的训练数据,这需要在未来的研究中进一步的探索。
思考1:究竟是不是动词比名词更难理解呢?
答案是肯定的。从现有的文献来看,动词通常比名词更难理解,这主要是因为它们具有高度多义性。
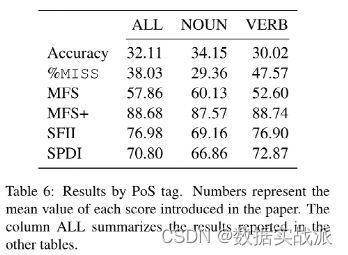
团队成员试图分析MT模型是否受到相同现象的影响:在表6中,报告了对其所有句子(全部列)以及目标词为名词或动词的句子子集运行DIBIMT得到的平均结果。总的来说,团队观察到的准确性平均下降了4个百分点,在MISS处理上有18个百分点的惊人差异。团队表示,将在未来的工作中展开更深入地研究。
思考2:编码器是否消除了歧义?
研究团队试图评估在多语言编码器-解码器架构中,编码器在生成译文之前在多大程度上确定源句子的隐式消歧。例如,问自己这样一个问题:给定源句子中存在一个模糊的单词,如果提示将其翻译成不同的语言,模型将它翻译成表示相同意思的词汇化的频率是多少?直观地说,如果编码器是模型执行的隐式消歧的唯一贡献者,那么期望看到的是意义总是相同的,而不管目标语言是什么。
思考3:DIBIMT的挑战性有多大?
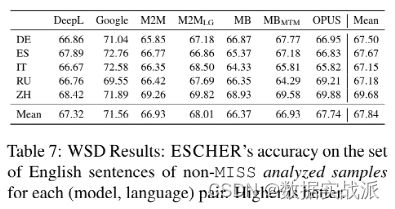
鉴于MT模型的表现欠佳,团队在DIBIMT中的英语句子上测试了WSD系统,并建立了额外的基线。研究团队在表7中报告了这些结果,其准确性得分可以直接与表3进行比较。正如预期的那样,平均MT精度明显低于ESCHER,只有DeepL例外,它在德语和俄语方面超过了ESCHER。这些结果清楚地表明,目前的NMT模式仍不能与专用的WSD系统相媲美。因此,如果将这些WSD系统纳入NMT生态系统,它们可能会受益。
思考4:这是一个解码问题吗?
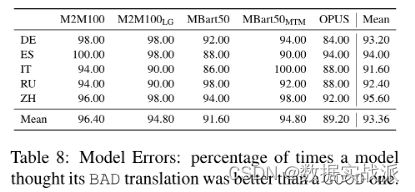
作为最后的实验,团队评估语义偏差到底是由搜索错误(即解码算法的失败)引起的,还是由模型错误(即模型认为其翻译是最好的)引起的。表8显示,模型错误平均发生的频率约为93%,因此证实了大多数语义偏差是嵌入在模型中,而不是由解码策略造成的。
https://aclanthology.org/2022.acl-long.298/