知识图谱(Knowledge Graph)
认识知识图谱
随着W3C在2007年发起的开放互联网数据项目(Linked Open Data)的火热,互联网上的数据正从杂乱的网页文本数据转变为包含大量描述实体之间丰富关系的数据万维网。在这个背景下,Google于2012年5月率先提出了知识图谱的概念,目的是将用户搜索的结果进行知识系统化,让每一个关键字都拥有一个完整的知识体系,从而真正意义上实现基于内容的检索,提高搜索质量。如下图,将知识图谱引入搜索引擎,用户除了得到搜索网页链接之外,还将看到与输入关键词有关的更加智能化的答案。国内互联网巨头如百度、搜狗等,也纷纷宣布了各自的“知识图谱”产品,如百度的“知心”、搜狗的“知立方”等。与基于关键词搜索的传统搜索引擎相比,知识图谱可以更好滴查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。因此,知识图谱也可以说是下一代智能搜索引擎的核心。

百度、谷歌搜索引擎的知识图谱
知识图谱的表示
知识图谱中的数据来源可以是结构化数据、半结构化数据和非结构化数据。前两者多以维基百科、百度百科为代表的大规模知识库,这些知识库中包含了大量半结构化、结构化知识,可以高效滴转化到知识图谱中。而非结构化数据多是网页文本数据,经过实体识别和实体关系抽取后,存放在关系型数据库中。知识图谱中的数据存储可以是RDF三元组(实体1、关系、实体2)的形式、也可以借助Neo4j图数据库以可视化图的方式展示。因此,知识图谱本质上是语义网络,是基于有向图的数据结构,在图中有节点(Nodes)和关系(Relationships),节点代表实体或概念,关系可以将节点连接起来,节点和关系都可以有对应的属性。
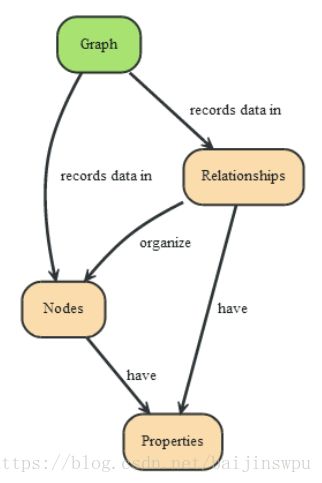
Neo4j图数据结构
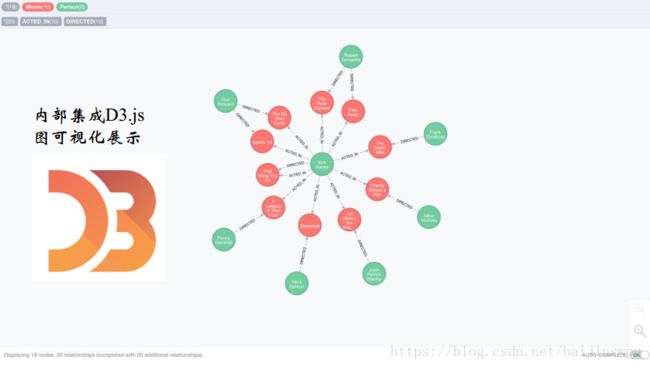
Neo4j建立的知识图谱
注:RDF和Neo4j本质上是一种数据模型,用于存放结构化数据,RDF数据是元数据,即描述数据的数据,目的是让计算机可读而非向用户展示。RDF三元组可借助Neo4j转变为图数据,RDF数据的查询语言为SPARQL,Neo4j图数据的查询语言为Cyper。
知识图谱构建涉及的主要技术
1、实体链指(Entity Linking)
互联网网页数据涉及大量实体,而大部分网页本身并未对这些实体作相关说明和背景介绍,为了帮助人们更好的理解网页内容,让网页出现的实体链接到相应的知识库词条上,为读者提供更详细的背景材料,这种将互联网网页和实体间建立链接关系的做法称为实体链指。
实体链指包含实体识别(Entity Recognition)和实体消歧(Entity Disambiguation),其中,实体消歧也有叫知识融合、实体对齐等。
实体识别旨在从文本中发现命名实体,如人名、地名和机构名等。知识图谱中不仅涉及实体,还有大量概念(Concept),因此,实体识别也包含概念的识别。
不同环境下的同一个实体名称可能对应多个实体,如“苹果”可以是某种水果,也可以是某IT公司,也可能是一部电影。这种一词多义或者歧义问题普遍存在自然语言文本中,将文档中出现的名字链接到特定实体上,这就是一个消歧的过程。实体消歧的基本思想是:考虑名字出现的上下文信息,分析不同实体可能出现在该处的概率。如文本中出现iPhone,那么“苹果”这个名字有更高的概率指向知识图谱中叫做“苹果”的IT公司。
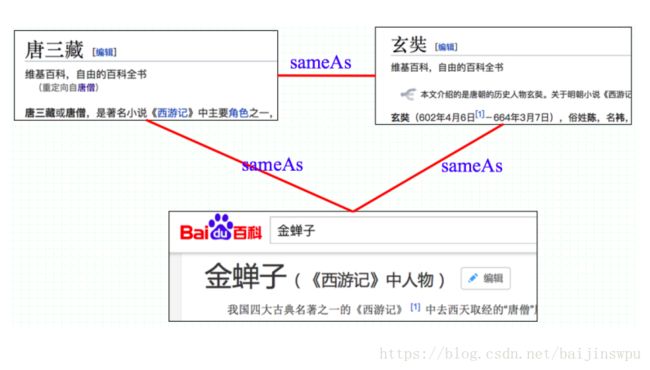
实体消歧
2、关系抽取(Relation Extraction)
关系抽取(信息抽取)指从文本中抽取实体之间的关系。
典型的信息抽取方法采用bootstrapping思想,即按照“模板生成 实例抽取”流程不断迭代直到收敛。如,“X是Y的首都”模板抽取(中国,首都,北京)三元组实例。
实例抽取”流程不断迭代直到收敛。如,“X是Y的首都”模板抽取(中国,首都,北京)三元组实例。
基于能够表达语义关系的词语(一般是以动词为核心的短语)来抽取实体关系,如,(华为,总部位于,深圳)、(华为,总部设置于,深圳)。
除上述方法外,还可以将关系抽取看做分类,即把关系抽取转换为对实体对的关系分类问题。将知识图谱三元组中每个实体对看成待分类样例,实体对关系看成分类标签。通过从出现该实体对的所有句子中抽取特征,利用机器学习分类模型构建信息抽取系统。
3、知识推理(Knowledge Reasoning)
推理能力是人类大脑智能的重要特征,即从已有知识中发现隐含知识。推理往往需要相关规则的支持,如从“配偶”+“男性”推理出“丈夫”。这些规则可以手工构建,但费时费力,人们也难以穷举所有的推理规则。目前主要利用关系之间的同现情况,利用关联挖掘技术自动发现推理规则。实体对之间存在丰富的同现信息,如(康熙,父亲,雍正)、(雍正,父亲,乾隆)、(康熙,祖父,乾隆)三个实例,根据大量类似的实体X、Y、Z之间出现的(X,父亲,Y)、(Y,父亲,Z)、(X,祖父,Z)实例,可以统计出“父亲+父亲祖父”的推理规则。
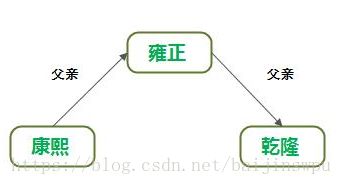
实体样例
4、知识表示(Knowledge Repreesentation)
在计算机中如何对知识图谱进行表示和存储,是知识图谱构建与应用的重要课题。正如前面所讲,知识图谱本质上是一张大规模的语义网,是基于有向图的数据结构,图中节点带有实体标签,边带有关系标签。如下是一个电影领域知识图谱。
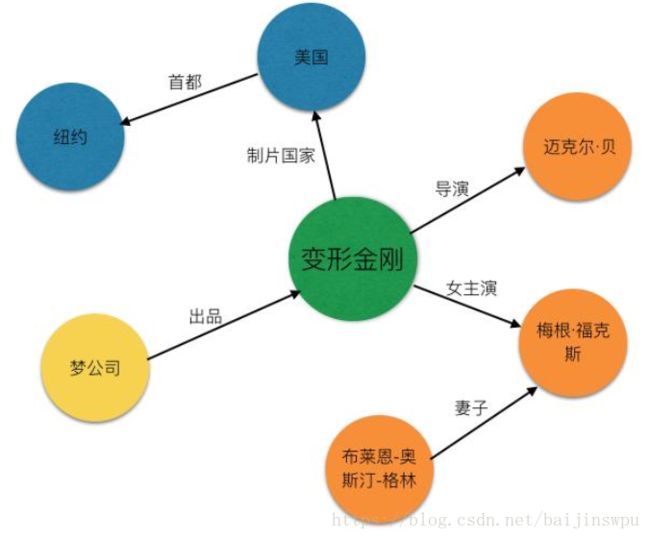
电影知识图谱示范
知识图谱是一种特殊的知识库,以往,信息检索手段更多的从“实体”角度出发,如今知识图谱使计算机能够从“关系”的角度分析、思考问题。知识图谱的应用让计算机获得一定的推理能力,使搜索引擎变得更加智能。
国内外开放的知识图谱
随着知识图谱概念的兴起,国内外许多搜索引擎公司和科研机构发布和维护了各类大规模知识库,如谷歌收购的Freebase、德国莱比锡大学等机构发起的项目DBpedia、德国马普研究所开发的链接数据库YAGO,普林斯顿大学开发的语义词典wordnet等,国内的如中文知识图谱社区OpenKG.CN等。
 国内外开放领域知识图谱
国内外开放领域知识图谱
知识图谱和本体的关系
知识图谱在本体的基础上进行了丰富和扩充,扩充主要体现在实体(Entity)层面。本体中强调的是领域内概念以及概念之间的关联关系,它是一个捕获领域知识的通用概念模型。而知识图谱则时在本体的基础上,增加了丰富的实体信息。
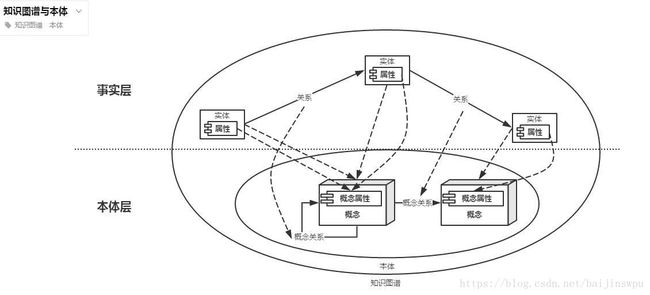 知识图谱与本体关系(图片引自知识图谱与本体 | UML图 | ProcessOn)
知识图谱与本体关系(图片引自知识图谱与本体 | UML图 | ProcessOn)
本体给知识图谱提供了“骨架”,实体填充了知识图谱。本体侧重概念层次上的表示,而知识图谱是以实体为核心,事实用实体之间的关系表示,注重实体之间的关系推理。
知识图谱的应用
1、查询理解
搜索引擎中,传统的关键词匹配技术没有理解查询词背后的语义信息,查询效果不佳。知识图谱将搜索引擎从字符串匹配推进到实体层面,利用知识图谱可以识别查询词中的实体及其属性,搜索引擎不仅能够更好地理解用户查询意图,还可以获得一定的推理能力,为用户提供更加智能、精准的信息。
2、自动问答
问答系统是知识检索更高级别的形式,支持用户以自然语言方式输入问句,返回的也是关于问句的一段文本。知识图谱可以作为问答系统的知识库,经过用户输入问句的语义解析、语义表示,以及最后进行语义匹配查询得到推理的过程,最终实现问什么答什么的智能问答系统。采用知识图谱这种数据管理手段,可以弥补机器对语言认知和概念认知的巨大障碍,让问答系统变得更加智能,提升问答系统的查全查准率。