2022年,我有点喜欢编程了

知乎上有一个热门问题:你的编程能力从什么时候开始突飞猛进?
初看到这个问题,我的嘴角微微上扬。记忆闪回到了 2013 年,那一年,命运给我了一点点正反馈,我有点喜欢编程了。
这篇文章,我想和大家聊聊勇哥读书,看源码,重构,解决线上问题的那些事。
1. 初心
2011 年,我服务于一家互联网彩票公司。坦率的讲,选择程序员这个职业,仅仅是为了生存。
那个时候,我对缓存 ,消息队列 ,分布式, JVM 一知半解 ,背了一些八股文,只是能非常熟练的使用 ibatis ,velocity ,编写简单的业务代码 。
我负责的是用户中心系统,提供用户注册,查询,修改等基础功能。所有的服务都以 HTTP 接口形式提供,数据传输格式是 XML 。
虽然工作看起来简单,我那个时候也不懂设计模式,写的业务代码非常臃肿,难以维护。
也发生了我的人生第一次重大 BUG ,我负责的用户中心在上线后隔一段时间变会内存溢出。我站在运维同学那里,看着他调整 tomcat jvm 参数 ,不知所措 。
后来发现我在使用 ibatis 的时候 ,使用类似的 SQLMap,前端又没有验证,数据库执行了全表查询,从而导致 JVM OOM 。
select*from t_lottery_user twhere 1 = 1user_name = #userName#id = #id#....
复制代码
这次生产环境事故之后,内心一直有一个声音折磨着我:“ 遇到技术问题的时候,能不能从容一点,不慌乱。其他人可以做到的事,为什么我做不到。”
于是我开始疯狂的买书读书 ,毕玄老师的《分布式 Java 应用》这本书对我影响至深。通过这本书,我深入学习了 JVM 内存模型 ,核心集合类原理, 并发包等知识点, 特别是 jstack , jmap 等 JVM 命令,边看书,边动手实践。
同时为了扩展视野,我在 javaeye 和 开源中国两大社区里面疯狂找热门帖子学习,一个帖子上下文都我都会反反复复的看几十遍以上 。
也时不时找运维同学,或者 DBA 聊,因为和他们聊,可以从另外一个视角审视公司系统存在的问题,他们的一句话有时候可以给我一些灵感。
2. 第一次重构
经过 2011-2012 两年的学习,2013 年彩票业务迎来了小爆发,我也迎来了技术人生第一次重构。
算奖服务是非常核心的服务,算奖服务包含若干子服务,其中竞彩算奖是用 C# 版本开发的系统。原来彩票订单量少的时候,算奖服务还算稳定,但一旦量级增大,C#版算奖服务就会 hang 住,算奖时间从半个小时变成两三小时,严重影响订单的返奖。
我当时满脑子都是想着去争一口气,去证明自己已不是两年前的弱鸡,于是主动请缨重构算奖系统。但领导说实话也是半信半疑,当时情况比较紧急,于是也就同意了。
技术团队比较草莽,没有统一的基础框架,每次新建项目都是按照研发的喜好搭架子。因为原来有接触过京东的基础框架,于是我参考京东框架第一次搭建自己的作品。
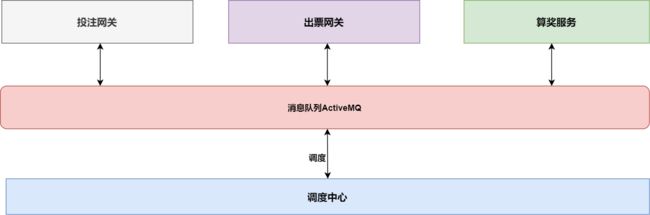
算奖整体逻辑比较简单,服务接收到竞彩赛事编号,查询彩票子订单,通过赛事结果判断彩票是否中奖,并修改子订单中奖信息,最后发送中奖信息到消息队列,最后调度中心来返奖。
至今都还记得开始写代码是双休日,两天没日没夜不知疲倦的编码,指尖敲击键盘,代码显示在屏幕上,行云流水,这种感觉美好而又奇妙。
两天就重构完了,怎么验证正确 ?在测试环境简单跑了一遍,发现没有任何问题。领导也觉得不可思议,但这个就能上线吗 ?我心里面也直打鼓,每天的竞彩算奖涉及到大几十万人民币,要是算错了,那影响也很大,我也要承担相应的责任。
领导也没有给我指导建议,于是我突发奇想:"生产环境不是有一两年的订单算奖历史数据吗 ?重构版本计算的结果和生产环境计算的结果做个对比,不就可以验证正确率吗?"。
于是,我将代码做了一些微调,将最后对数据的写操作去掉,对比重构版本计算的金额和 c# 版本计算的金额,若金额有差异,订单数据写入到文本中,发送邮件告警。
让我惊喜的是:在近千万的历史订单里,重构版本的计算结果非常精准,只出现了两例计算异常,并且计算速度非常快(快接近 10 倍)。修复完 BUG 后,和 C# 版本并行运行二十天左右后,计算结果都精准无误。于是,领导同意了下线老系统 ,上线算奖重构版本。
这一次成功重构带给我自信:在这个行业,我是可以生存下去的。
技术层面:我自己搭建了项目,接触了消息队列做为消息总线的架构模式,也认识到应用基础框架的重要性。同时,我也隐约觉得:“代码写出来是相对容易的,验证代码的正确性同样非常考验工程能力 ”。
3. 阅读源码
2013 年,是我阅读源码的起点 , 阅读了 Druid , Cobar , Xmemcached 等源码。
3.1 数据源连接池 Druid
算奖系统重构之后,有一个小插曲。我发现每天的第一次请求,数据库连接有问题,于是我向 Druid 的作者温少写了一封邮件。
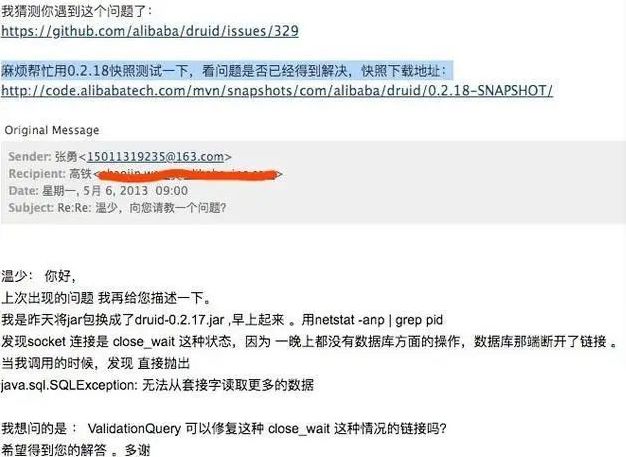
温少给我回复了邮件,我马上翻开源码,发现我配置数据库连接池的心跳有问题。核心点在于需要连接池每隔一段时间发送心跳包到 oracle 服务器,因为数据库为了节省资源, 每隔一段时间会关闭掉长期没有读写的连接。所以客户端必须每隔一段时间发送心跳包到服务端。
这次简单的探寻源码给了我长久的激励,也让我更加关注技术背后的原理。
-
精神层面:向别人请教问题是会上瘾的;
-
技能层面:理解连接池的实现原理;
-
架构层面:客户端和服务端请求需要考虑心跳。
3.2 数据库中间件 Cobar
还是在 2013 年,接触到 cobar 带给我的震撼简直无以复加。
当时互联网大潮奔涌而来 , 各大互联网公司的数据爆炸般的增长 , 我曾在 javaeye 上看到淘宝订单技术人员分享分库分表的帖子 , 如获至宝 , 想从字里行间探寻分库分表的解决方案 , 可惜受限于篇幅 , 文字总归是文字 , 总感觉隔靴搔痒。没曾想到 , cobar 开源了, 我至今都还记得用 navicat 配置 cobar 的信息,就可用像连单个 mysql 一样,而且数据会均匀的分布到多个数据库中 ,这简直像魔法一样。对于我当时孱弱的技术思维来讲 , 简直就像是三体里水滴遇到人类舰队般 ,降维打击 。
因为对分库分表原理的渴求 , 我没有好的学习方法 , 大约花了 3 个月的时间,我把整个 cobar 的核心代码抄了一次。真的是智商不够 , 体力来凑。但光有体力是真的不够的,经常会陷入怀疑,怎么这也看不懂,那也看不懂。边抄代码边学习好像进步得没有那么明显。那好 , 总得找一个突破口吧。网络通讯是非常重要的一环。
当时的我做了一个决定,我要把 cobar 的网络通讯层剥离出来 , 去深刻理解使用 原生 nio 实现通讯的模式。剥离的过程同样很痛苦 , 但我有目标了 , 不至于像没头的苍蝇,后来也就有了人生第一个 github 项目。

追 cobar 的过程中, 好像我和阿里的大牛面对面交流,虽然我资质驽钝, 但这位大牛谆谆教诲 , 对我耐心解答, 打通我的任督二脉。由是感激。说是我生命中最重要的开源项目也不为过。
“你想学啊?我教你"。

4. 实战:知行合一
2013 年下半年,我参与了很多系统的重构,解决了很多生产环境的问题。我经常思考:怎么将我学到东西用到真实场景中,也做了很多有趣的尝试。
4.1 多级缓存
彩票系统里有一个赛事分析服务,页面非常复杂,采取的方案是 nginx 页面静态化的策略,通过定时任务每天将赛事分析数据写入到 磁盘中 NFS 共享目录 ,配置 Nginx 访问。
nginx 页面静态化的优缺点都非常明显。
-
静态页面访问速度极快,性能非常好;
-
维护成本高,定时任务定期生成相关的页面,更新经常延迟,而且代码是 N 年前的古董,是用 Php 写的。
领导决定用 Java 重构,核心的指标是:性能。
看过红薯哥写了一篇文章:oschina 上的一种双缓存思路。
https://www.oschina.net/question/12_26514
我大胆的采用了 Ehcache + memcached 的双缓存架构。重构过程也很顺利,上线后性能也还不错,维护起来也相对简单。
4.2 救火队员
彩票系统的业务量增长极快, 生产环境经常遇到一些莫名其妙的问题 。每次遇到问题, 我把每个问题当作我自己的问题,全力以赴的去解决,变成了救火队员。
发生了很多的故事,举两个例子。
▍ 调度中心消费不了
某一天双色球投注截止,调度中心无法从消息队列中消费数据。消息总线处于只能发,不能收的状态下。 整个技术团队都处于极度的焦虑状态,“要是出不了票,那可是几百万的损失呀,要是用户中了两个双色球?那可是千万呀”。大家急得像热锅上的蚂蚁。
这也是整个技术团队第一次遇到消费堆积的情况,大家都没有经验。
首先想到的是多部署几台调度中心服务,部署完成之后,调度中心消费了几千条消息后还是 Hang 住了。 这时,架构师只能采用重启的策略。你没有看错,就是重启大法。说起来真的很惭愧,但当时真的只能采用这种方式。
调度中心重启后,消费了一两万后又 Hang 住了。只能又重启一次。来来回回持续 20 多次,像挤牙膏一样。而且随着出票截止时间的临近,这种思想上的紧张和恐惧感更加强烈。终于,通过 1 小时的手工不断重启,消息终于消费完了。
我当时正好在读毕玄老师的《分布式 java 应用基础与实践》,猜想是不是线程阻塞了,于是我用 Jstack 命令查看堆栈情况。 果然不出所料,线程都阻塞在提交数据的方法上。
我们马上和 DBA 沟通,发现 oracle 数据库执行了非常多的大事务,每次大的事务执行都需要 30 分钟以上,导致调度中心的调度出票线程阻塞了。
技术部后来采取了如下的方案规避堆积问题:
-
生产者发送消息的时候,将超大的消息拆分成多批次的消息,减少调度中心执行大事务的几率;
-
数据源配置参数,假如事务执行超过一定时长,自动抛异常,回滚。
▍比分直播页面卡顿
同事开发了比分直播的系统,所有的请求都是从缓存中获取后直接响应。常规情况下,从缓存中查询数据非常快,但在线用户稍微多一点,整个系统就会特别卡。
通过 jstat 命令发现 GC 频率极高,几次请求就将新生代占满了,而且 CPU 的消耗都在 GC 线程上。初步判断是缓存值过大导致的,果不其然,缓存大小在 300k 到 500k 左右。
解决过程还比较波折,分为两个步骤:
-
修改新生代大小,从原来的 2G 修改成 4G,并精简缓存数据大小 (从平均 300k 左右降为 80k 左右);
-
把缓存拆成两个部分,第一部分是全量数据,第二部分是增量数据(数据量很小)。页面第一次请求拉取全量数据,当比分有变化的时候,通过 websocket 推送增量数据。
经过这次优化,我理解到:缓存虽然可以提升整体速度,但是在高并发场景下,缓存对象大小依然是需要关注的点,稍不留神就会产生事故。另外我们也需要合理地控制读取策略,最大程度减少 GC 的频率 , 从而提升整体性能。
5. 写到最后
我特别喜欢毕淑敏关于命运的解释:
渐渐地,我终于发现,命运是我怯懦时的盾牌,每当我叫嚷命运不公最响的时候,正式我预备逃遁的前奏。命运就像是一只筐,我把自己对自己的姑息,原谅以及所有的懒惰都一股脑儿地塞进去然后蒙上一块宿命的轻纱,我背着它慢慢往前走,心里有一份自欺欺人的坦然。
当我选择程序员这个职业,最开始是为了生存,我并不聪明,学什么都很慢,但我偏偏想证明自己,只能不断去学习,命运貌似给我一丢丢回馈,让我有了一点点满足感。
于是,2013 年,那个青年找到了属于他的世界。
喜欢一个人,眼神是藏不住的,喜欢编程,眼神同样是藏不住的。
小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。

版权声明: 本文为 InfoQ 作者【勇哥java实战分享】的原创文章。
原文链接:【xie.infoq.cn/article/133a272ce07280ee8209975d7】。文章转载请联系作者。