centos7 hadoop集群搭建详细教程
参考文献:https://xiaolei.blog.csdn.net/article/details/52946840
准备工作
软件版本
centos 7
jdk : 1.8.0_211
hadoop : 3.1.2
资源可在我的博客下载
本次演示的各个主机
mu01(管理节点)
cu01
cu02
cu03 (三个工作节点)
修改主机名并记录所有节点ip
所有主机修改各自的主机名
修改/etc/hostname文件
将文件中的名字修改,如mu01
重启reboot
hostname查看主机名是否修改
所有主机修改/etc/hosts文件,在其中添加所有的ip和主机名(记住,添加所有节点的ip与主机名)
追加内容(ip+主机名)
所有主机都执行以下内容:
sudo vim /etc/hosts
192.168.**.** mu01
192.168.**.** cu01
192.168.**.** cu02
192.168.**.** cu03
创建用户
创建test用户(hadoop的使用用户)
设置集群ssh免秘钥登录
(管理节点)生成公钥
在test用户下执行:
ssh-keygen -t rsa //一路回车就好,会出现一个图形
cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
将公钥发送给各个节点
在test用户下执行(此时所有节点都在test用户下):
ssh-copy-id -i ~/.ssh/id_rsa.pub mu01
ssh-copy-id -i ~/.ssh/id_rsa.pub cu01
ssh-copy-id -i ~/.ssh/id_rsa.pub cu02
ssh-copy-id -i ~/.ssh/id_rsa.pub cu03
在此期间会让输入密码
就是mu01把自己的公钥发送给cu01、cu02、cu03
cu01把自己的公钥发送给mu01、cu02、cu03
... ...
所有主机修改配置文件(root下执行)
vim /etc/ssh/sshd_config
修改原有项:
PermitRootLogin yes
StrictModes no
AuthorizedKeysFile .ssh/authorized_keys
添加项:
RSAAuthentication yes
PubkeyAuthentication yes
重启:
systemctl restart sshd.service
连接(此时应该是test用户):
在mu01机器上输入:
ssh cu01
连接成功就Ok啦
配置hadoop
所有节点安装JDK
查看是否安装JDK:
查看是否设置了环境变量:echo $JAVA_HOME;
查看JDK版本:java -verion
安装JDK:
将jdk包内所有文件解压后放在/opt/java/(这个位置可以自己定)下:
mkdir /opt/java
mv jdk/* /opt/java/
配置JDK:
在/etc/profile内尾部追加内容:(vim /etc/profile)
# java configration
export JAVA_HOME=/opt/java
export PATH=.:$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
刷新,让配置文件生效
source /etc/profile
重复,所有节点都安装jdk.
将hadoop包解压缩后,放在/opt/hadoop/ (这个位置自己定)下
在Hadoop集群所有节点中配置Hadoop环境变量
vim /etc/profile
# hadoop
export HADOOP_HOME="/opt/hadoop"
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
别忘了让配置文件生效
source /etc/profile
配置hadoop-env.sh(hadoop主目录/etc/hadoop/)
增加如下内容:
export JAVA_HOME=/opt/java
配置workers文件,增加workers主机名
mu01
cu01
cu02
cu03
配置 core-site.xml
fs.defaultFS
hdfs://mu01:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/opt/hadoop/tmp
配置 hdfs-site.xml
dfs.namenode.secondary.http-address
mu01:50090
dfs.replication
2
dfs.namenode.name.dir
file:/opt/hadoop/hdfs/name
dfs.datanode.data.dir
file:/opt/hadoop/hdfs/data
配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
mu01:8032
yarn.resourcemanager.scheduler.address
mu01:8030
yarn.resourcemanager.resource-tracker.address
mu01:8031
yarn.resourcemanager.admin.address
mu01:8033
yarn.resourcemanager.webapp.address
mu01:8088
配置mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
mu01:10020
mapreduce.jobhistory.address
mu01:19888
以上配置的文件(.xml)每个文件只有一对
复制Hadoop配置好的包到其他Linux主机
scp -r /opt/hadoop test@cu01:/opt/hadoop/
scp -r 本机目录 用户@目标主机:目标主机的接收位置
格式化节点
在mu01(管理节点)上执行:
hdfs namenode -format
hadoop集群全部启动/停止
在mu01上执行
cd hadoop主目录/sbin
cd /opt/hadoop/sbin
./start-all.sh(启动集群)
./stop-all.sh(关闭集群)
##jps查看进程
管理节点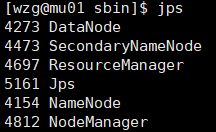
工作节点
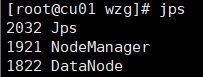
在主机上查看,博主是Windows10,直接在浏览器中输入hadoop1 集群地址即可。
启动集群后,主机访问
http://管理节点:8088/
访问不了,尝试主机与虚拟机能不能相互ping通,是相互哦!
然后关闭虚拟机防火墙就好了