在pandas 基础操作大全之数据读取&清洗&分析 以及 pandas基础操作大全之数据合并 中介绍了pandas常见的数据处理操作以及常用的数据合并操作,本文继续对pandas数据可视化操作做下介绍,便于大家快速了解,也方便后续需要时快速查询。
一、概述
1.1 plot函数参数
数据可视化,一般用Matplotlib库,该库可与MATLAB作图相媲美,允许完全按照自己的意愿自定义图表的展示方式,但相较于日常快速进行数据分析和可视化,用起来相对繁琐,故pandas基于该库,重新封装了plot方法,该方法还对Series和DataFrame数据格式进行了特定的优化,本文主要讲解pandas的数据可视化工具,首先讲解plot函数常用参数的含义。
#pandas主要使用plot函数进行数据可视化绘图,完整表达式如下,本文仅罗列常见的参数,其他参数待用到时,可自行学习
df.plot(
x='A',#即绘图x轴用的数据列标签,如果不指定,则默认为index
y='B',#即绘图y轴用的数据列标签,可指定一个,也可指定多个,指定多个使用列表格式['A', 'B']
use_index=True,#设置是否用DF的index行索引作为x轴,默认是True,当x不传入值时,便用index
kind='line',#即绘图用的图表类型,枚举有line(折线)、bar(条形图)、barh(横向条形图)、hist(柱状图)、box(箱线图或蜡烛图)、area(面积图)、pie(饼图)、scatter(散点图)等
subplots=True,#子图,即如果y指定的是多列,则将每列分为一个子图,与layout一起使用
layout=(2,2),#2*2布局,即4个子图
sharex=True,#如果有子图,子图共x轴刻度,标签,默认True
sharey=False,#如果有子图,子图共y轴刻度,标签,默认False,即不共享
figsize=(12,8),#设置图表大小,横纵方向,单位英尺
title='title',#设置图表的标题
grid=True,#设置图表的格子,默认False,即不添加格子
legend=True,#即设置是否添加图例,默认True
color=['r', 'g', 'b'],#设置不同序列或不同组对应展示的图表颜色,序列格式(列表或元组),默认none,一般不需要显示指定,系统会自动分配
xticks=[],#设置x轴刻度,序列形式(列表或元组),可自定义横轴的刻度,默认none,一般不需要
yticks=[],#设置y轴刻度,序列形式(列表或元组),可自定义纵轴的刻度,默认none,一般不需要
rot=0,#设置轴刻度旋转角度,默认是0,即水平展示
fontsize=12,#设置横纵坐标刻度字体大小
xlim=[0,100],#设置x轴刻度区间,序列形式(列表或元素),默认不设置,由系统自动判断
ylim=(0,100),#设置y轴刻度区间,序列形式(列表或元素),默认不设置,由系统自动判断
ax,#设置此次绘图的目标axes(坐标系),在本文最后会详细展开,可以理解为,其是pandas暴露的与matplotlib无缝衔接的接口
)
#df.plot()函数返回值为此次绘图所生成的坐标系,可以是1个,也可以是多个,视subplots是True或False而定
#pandas的plot绘图后,还可结合Matplotlib,对生成的图表的属性进一步定制和设置
plt.grid(linewidth=0.2, alpha=0.5)
1.2 本文用到的数据源说明
#为了让该篇文章更加易懂,这次会使用真实数据进行数据分析及可视化的演示 #网上获取公开数据源的平台比较多,比如AkShare、Tushare、BaoStock等 #其中Tushare使用时较为便捷,但使用接口获取数据时还需要积分达到一定的值,而AkShare数据则完全公开,调用时没有任何限制,故本文内均会使用AKShare的数据 #获取数据方法如下: import akshare as ak #如果没有安装akshare,请自行pip安装 df=ak.macro_cnbs() #每一个接口获取的数据不一样,此处只使用历年中国宏观杠杆率数据 #AKShare详细教程和数据可访问以下链接 https://www.akshare.xyz/zh_CN/latest/index.html
二、折线图--kind='line'
#折线图,一般用来分析某数据指标(列)随着index或另外一个数据序列的变化趋势,也是最常见的图表 #数据源,以下使用AkShare 数据平台的 中国宏观杠杆率 作为数据源 import akshare as ak import pandas as pd import matplotlib.pyplot as plt df=ak.macro_cnbs() #获取中国历史各部门的杠杆率 #df.head() 年份 居民部门 非金融企业部门 政府部门 中央政府 地方政府 实体经济部门 金融部门资产方 金融部门负债方 0 1993-12 8.311222 91.658000 4.249689 3.572548 7.822237 107.791459 8.896441 7.128428 1 1994-12 7.808230 82.411703 4.989987 3.144351 8.134338 98.354271 9.808787 6.796868 2 1995-12 8.200000 81.000000 5.700000 3.000000 8.700000 97.900000 10.000000 7.000000 3 1996-03 8.400000 81.700000 6.100000 3.000000 9.100000 99.200000 10.200000 7.200000 4 1996-06 8.600000 82.100000 6.000000 3.000000 9.000000 99.700000 10.400000 7.400000 df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='line', figsize=(10,8),fontsize=12,title='金融杠杆率') #运行后,生成图表如下,可见基本来说,杠杆率在逐年增加,其中居民部门的杠杆率,在2008年以后出现骤增的趋势,可能与房价快速上涨有关

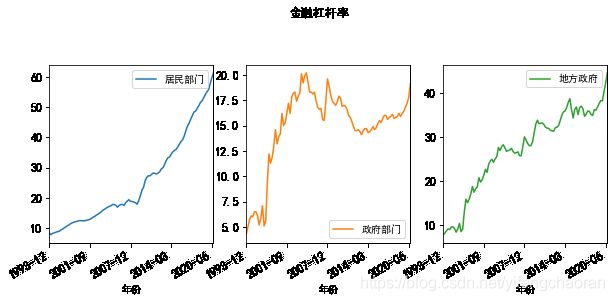
#如果使用子图,对各个经济部门的杠杆率分开展示,则如下 df.plot(x='年份',y=['居民部门','政府部门','地方政府'], subplots=True, layout=(1,3),kind='line', figsize=(10,8),fontsize=12,title='金融杠杆率') #运行后图表如下,可见如果拆成子图之后,会更加清晰些
三、柱状图--kind='bar'
3.1 各组数据(列)分开展示
#柱状图(条形图)一般用来分析某指定时间段内,不同指标之间的对比,同时还可以分析变化趋势 #相较于折线图,会表现的更加直观,条形图,或者叫柱状图,一般用于分析不同时间段不同指标或组别的表现对比,但如果要判断趋势,最好还是用折线图会更加直观 #数据源,仍然以中国各经济部门宏观杠杆率为准,但是只取前20行数据,因数据量太大 df.iloc[range(20)].plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='bar',figsize=(10,8),fontsize=12,title='金融杠杆率')#运算后,生成的图标如下

3.2 各组(列)数据合并展示--stacked
#柱状图还有一种变种,即堆叠柱状图,相当于将需要对比的不同组别的指标值加和,并展示在一个柱内,用不同颜色区分 #该种图表既可以体现同一时期或区间不同组别的指标占比大小(根据数值),还可以观察不同时期对应组别累加值的变化趋势 #比如不同季度4个销售团队的销售业绩,那么堆叠柱状图即可以对比不同季度各个销售团队的业绩,还可以观察4个销售团队在不同季度业绩总和的变化趋势 df.iloc[range(20)].plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='bar', stacked=True,figsize=(10,8),fontsize=12,title='金融杠杆率') #运行后图表如下

3.3 横向柱状图--kind='barh'
#横向柱状图,基本就是将bar图给横过来,没有其他区别,有横向柱状图的原因,主要是长短相较于高低会更加直观些,大概可能是因为人类的视觉习惯吧 #还是以中国宏观杠杆率数据为数据源 df.iloc[range(20)].plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='barh', stacked=True,figsize=(10,8),fontsize=12,title='金融杠杆率') #运行后图表如下,为叠加效果

#以下为不叠加数据的效果 df.iloc[range(20)].plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='barh',figsize=(10,8),fontsize=12,title='金融杠杆率') #运行后图表如下

四、直方图--kind='hist'
4.1 概述
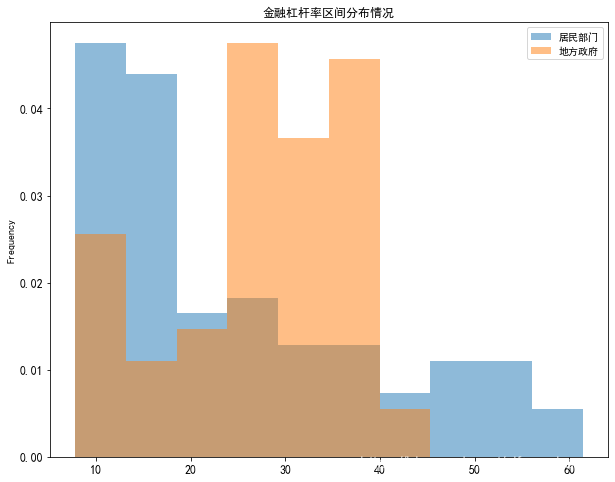
#直方图一般用在统计数据可视化领域,类似概率分布,即数据序列在不同值区间内分布的情况 #默认情况下,plot会将序列数据值分为10个数值区间并统计数值在不同区间的个数,即频数图,如果要展示的是频率图,则设置density = True即可。 #仍以中央宏观杠杆率数据为例,我们想看下不同经济部门历年杠杆率区间分布情况 df.plot(y=['居民部门','地方政府'],kind='hist',figsize=(10,8),fontsize=12,title='金融杠杆率区间分布情况') #运行后,图表如左图,为频数图 df.plot(y=['居民部门','地方政府'],kind='hist',density = True, figsize=(10,8),fontsize=12,title='金融杠杆率区间分布情况') #运行后,图表如中图,为频率图 df.plot(y=['居民部门','地方政府'],kind='hist',density = True, figsize=(10,8),fontsize=12,title='金融杠杆率区间分布情况') #运行后,图表如右图,为频率图,且设置透明度


4.2 自定义直方图横向区间数量
#如果对系统自动划分的10个区间不太满意,比如感觉太多或者太少,也可以自定义区间值,一般有两种方式
#1、使用bins参数,直接指定需要划分的区间数量,默认是10,可设置比如15或5等
#2、使用xticks参数,直接指定横轴的坐标刻度值
#1、使用bins参数
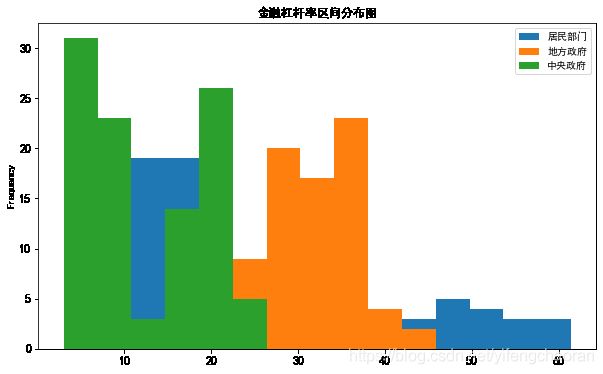
df.plot(y=['居民部门','地方政府','中央政府'],kind='hist',figsize=(10,6),fontsize=12,title='金融杠杆率区间分布图',bins=15) #指定将区间划分为15个,如下左图所示
#2、使用xticks参数
xtick=[5,10,15,20,25,30,35,40,45,50,55,60]
colormap=('r','g','b')
df.plot(y=['居民部门','地方政府','中央政府'],kind='hist',figsize=(10,6),fontsize=12,title='金融杠杆率区间分布图',xticks=xtick)#指定将区间按照指定刻度划分,如下右图所示

4.3 多子图展示多序列数据
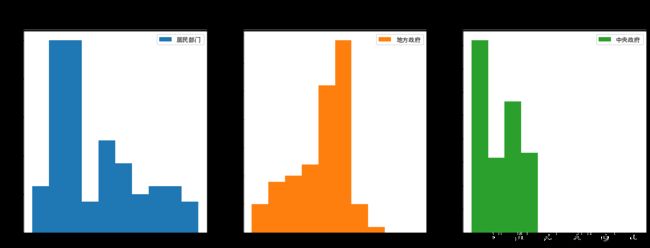
#也可将不同序列数据在不同的子图上进行展示,这个是一个通用方法,所有的绘图方法均可对多序列数据分几个子图进行绘图展示 #以下使用3个子图,对不同的序列数据直方图进行绘制 df.plot(y=['居民部门','地方政府','中央政府'],kind='hist',figsize=(18,6),subplots=True,layout=(1,3),fontsize=12,title='金融杠杆率区间分布图')#运行后效果如下
4.4 一维数据密度图--kind='kde'
#kde是直方图的另外一种变种,相对于直方图,可以认为其区间数量不限,是连续性的,可以更加直观的观察序列数据在不同数值下的概率分布图,看数值主要集中于哪个数值区间范围内 df.plot(y=['居民部门','地方政府','中央政府'],kind='kde',figsize=(18,6),fontsize=12,title='金融杠杆率区间分布图',subplots=True,layout=(1,3))#运行后图表如下

4.5 累积直方图--cumulative = True
#如果希望几个数据序列,在同一区间内的频次或者频率相加,则可以使用累积直方图,相当于将频数或频率在同一区间内叠加展示 df.plot(y=['居民部门','地方政府'],kind='hist',cumulative = True,figsize=(10,8),alpha=0.5,fontsize=12,title='金融杠杆率区间分布情况') #运行后如下图所示

五、箱线图--kind='box'
5.1 默认用法--垂直箱线图
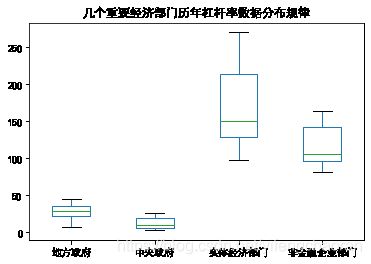
#box箱线图一般用来直观研究一组或多组数据分布特征的统计图,要求所分析的列数据必须是数值格式 #box图会计算出每一组数据的上四分位数、下四分位数、上边缘、下边缘、中位数以及异常值等6个值,并以箱状绘制出来 #箱线图还有其他较多变体 #仍以中国宏观杠杆率数据为例,我们分析下几个关键的部门历年杠杆率数据的分布情况 df.plot(y=['地方政府','中央政府', '实体经济部门','非金融企业部门'],kind='box') #运行后如下图所示,可见地方政府和中央政府的杠杆率整体偏低,而实体经济的杠杆率则最高,但中国整体实体经济又整年缺乏现金流,数据表现比较奇怪
5.2 水平箱线图--vert = False
#如果希望箱线图水平展示,则直接设置 vert=False即可 df.plot(y=['地方政府','中央政府', '实体经济部门','非金融企业部门'], vert=False, kind='box')#运行后效果如下

六、饼图--kind='pie'
6.1 概述
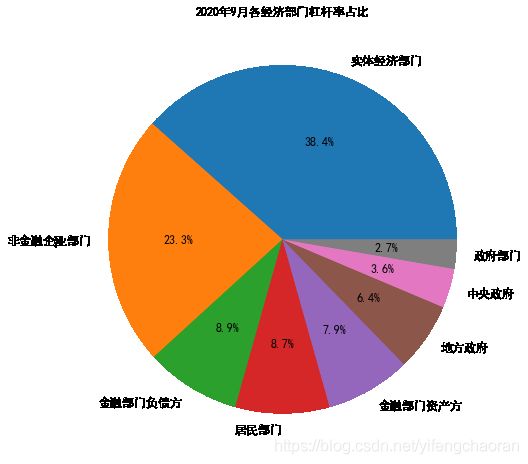
#饼图一般研究在同一时期或数据点下,不同指标列数值的百分比占比情况,比如同一个月内,不同销售团队销售额占比情况 #还是以中国宏观杠杆率数据,我们取2020年9月份的数据,研究下不同经济部门杠杆率占比情况,看哪个部门占比最多,即杠杆率最高,以及其占比情况 #以下s,为从df中抽出2020年9月份数据,然后去掉月份列,并转为Series格式,因为pie一般使用Series格式的数据进行绘图 s.plot(kind='pie',autopct='%1.1f%%',figsize=(10,8),fontsize=12,title='2020年9月各经济部门杠杆率占比') #绘图效果如下,可见实体经济部门的杠杆率占比最大
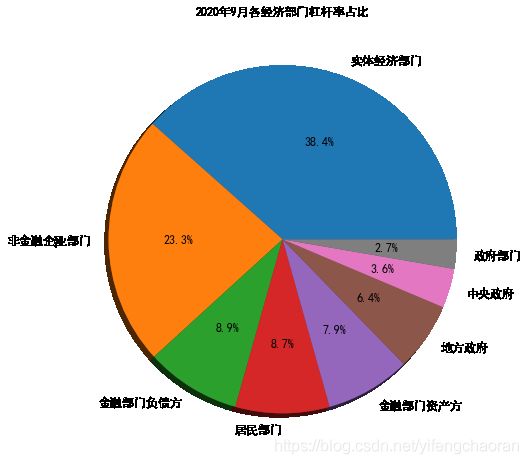
6.2 设置阴影--shadow=True
#为了增强生成的图表的可读性,可对pie图的每个slice添加阴影,不过本人不太喜欢阴影 s.plot(kind='pie',autopct='%1.1f%%',startangle=90, figsize=(10,8), fontsize=12,title='2020年9月各经济部门杠杆率占比') #运行生成的图表如下所示
6.3 设置不同饼区域偏离中心区域的距离--explode
#有时候为了突出展示某几个slice,希望这些slice可以脱离出饼图圆心一定距离,这样就从饼图分离出一部分,可以通过设置explode参数实现 explode_list = [0, 0, 0, 0, 0, 0.2,0.1,0.1] #此处按照数据序列顺序,指定对应silce偏离饼图中心的距离,以半径为单位1,如果是0,则代表不批那里 s.plot(kind='pie',autopct='%1.1f%%',figsize=(10,15),startangle=90,explode=explode_list, shadow=True,fontsize=12,title='2020年9月各经济部门杠杆率占比') #运行后,效果如下,突出体现了最小的三个部门杠杆率占比

6.4 设置自动产生的百分比文案偏离中心区域的距离--pctdistance
#可能pie图自动生成的百分比文案位置不太满意,此时可以通过pctdistance参数设置其位置偏差 #默认是在饼图半径的一半位置,即pctdistance=0.5,如果设置为1,则会在饼图外边缘位置 #以下将百分比文案位置设置在半径的0.8位置 explode_list = [0, 0, 0, 0, 0, 0.1,0.1,0.1] s.plot(kind='pie',autopct='%1.1f%%',figsize=(10,15),startangle=90,pctdistance=0.8,explode=explode_list, shadow=True,fontsize=12,title='2020年9月各经济部门杠杆率占比') #运行后效果如下

6.5 去掉列标签,用图例展示
#如果觉得将对应slice的数据名称直接展示在pie图内,整体会显得拥挤,则可以去掉,并添加图例 explode_list = [0, 0, 0, 0, 0, 0.1,0.1,0.1] s.plot(kind='pie',autopct='%1.1f%%',figsize=(10,15),startangle=90,labels=None,pctdistance=0.8,explode=explode_list, shadow=True,fontsize=12,title='2020年9月各经济部门杠杆率占比') plt.legend(labels=s.index, loc='upper left') #添加图例

七、散点图--kind='scatter'
7.1 概述
#散点图,一般用于分析两列(组)二维数据的相关性规律,折线图的x轴一般是线性变化,所以折线图一般只能研究某一指标列的变化趋势,而散点图则可以研究两列数据的相关性,比如是否有线性变化关系等,且两列数据本身已经相对于同一个线性数据进行了对齐(以下例子中即均与年份对齐)
#一般用法
df.plot(
x='', #设置x轴的数据序列
y='',#设置y周的数据序列
s=100,#设置散点的大小
c='r',#设置散点的颜色,也可传入列名,传入的列名必须是数值化的,那么散点会根据列名的数值大小自动着色
marker='*',#设置散点的形状
)
#数据源还是中国各个经济部分宏观杠杆率,现在想观察下中央政府和地方政府杠杆率是否有相关性,则
df.plot(x='中央政府',y='地方政府',kind='scatter',figsize=(10,8),fontsize=12,title='中央政府和地方政府杠杆率相关性分析') #绘图结果如下,可发现中央政府和地方政府杠杆率呈现一定程度的正相关

7.2 分类散点图--增加另一个维度的数据变量
#一般散点图是分析二维码数据(两个数据序列)之间的关系,也是数据分析最主要的任务,但是如果希望分析三维数据,即三个数据序列之间的变化关系,也可以用散点图实现 #此时将第三个数据序列(必须是数值化的)传给c参数,用第三个数据序列的大小,对散点进行自动着色,颜色越黑,代表第三个数据序列越大 #还是以中国宏观杠杆率数据为例,我们不仅希望知道中央政府和地方政府之间杠杆率变化规则,还希望知道实体经济部门与这两者数据的关系(用颜色深浅代表数值大小),则可以使用分类散点图 df.plot(x='中央政府',y='地方政府',kind='scatter',figsize=(10,8),fontsize=12,c='实体经济部门' ,title='中央政府、地方政府即实体经济部门杠杆率相关性分析') #运行后如下图所示,可见中央政府和地方政府杠杆率越大,实体经济部门杠杆率也越大(因为对应的颜色越深)

7.3 气泡图--散点图变种--以气泡大小代表数值大小
#分类散点图是以颜色深浅来判断第三个数据序列与指定的x和y数据序列之间的数值变化关系 #气泡图则是用气泡的大小,来判断,气泡图较为适用于数据点不太多的情况,因为数据太多的话,各个气泡重叠在一起,可视化效果范围不好 df.plot(x='中央政府',y='地方政府',kind='scatter',figsize=(10,8),fontsize=12,c='c' ,alpha=0.5,s=2*df['实体经济部门'], title='中央政府、地方政府即实体经济部门杠杆率相关性分析') #运行后,效果如下,还是分析实体经济部门与中央政府、地方政府杠杆率数值变化的趋势关系 #其中s为三点的大小,大小直接使用实体经济部门杠杆率数值设置

八、面积图--kind='area'
8.1 默认用法--不同序列数据不叠加值
#面积图,融合了折线图和柱状图的优点,既可以分析不同指标(列标签)随同一个列或index的变化趋势,同时也可以直观的看到大小。如果单纯只是想对比不同指标在同一列下不同大小和变化趋势,则使用折线图最理想。 #如果希望即看不同指标的变化趋势,又希望看不同指标在同一时期内叠加值的变化趋势,且数据点较多,则使用面积图最理想,比如希望看5年内,每个月不同销售团队的销售额的大小对比和变化趋势,又希望看每个月不同销售团队总销售额的变化趋势,使用面积图最理想 df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='area', stacked=False,figsize=(10,8),fontsize=12,title='金融杠杆率')#不同列值不堆叠,绘图效果如下:

8.2 不同序列数据叠加值--stacked
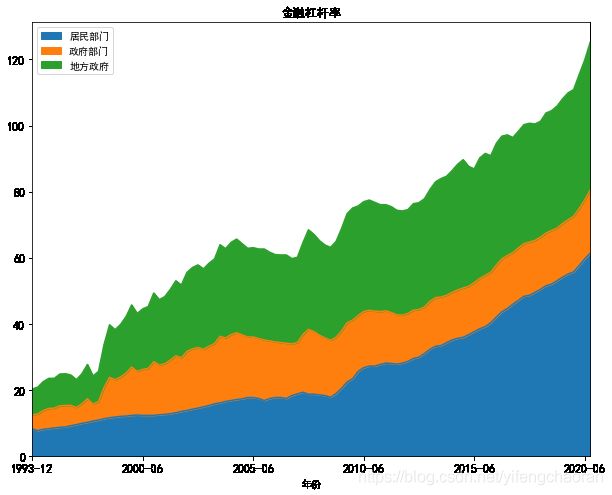
df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='area', stacked=True,figsize=(10,8),fontsize=12,title='金融杠杆率') #堆叠时绘图效果如下,可见整体叠加杠杆率,近几年上升较快
九、六边图--kind='hexbin'
9.1 概述
六边图又叫六边箱图,主要分析二维(即两个数据序列)数据点数值分布情况,类似二维的直方图,它展示了每个小六边形中观测点的数量,这种图在大数据集上可视化效果最佳。
直方图针对每个数据序列,是单独展示其沿着x周数值区间的频数或频次分布,而六边图则展示了x和y两个数据序列关联起来后的频数分布图,同时还可以展示x和y两个数据序列之间的关联变化关系
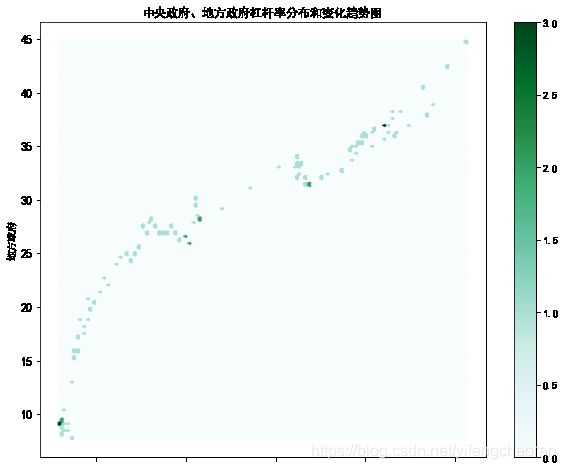
#还是以分析中国宏观杠杆率数据,我们想了解中央政府和地方政府杠杆率数值的分布情况,且最好还可以体现两者之间的变化关系 df.plot(x='中央政府',y='地方政府',kind='hexbin',figsize=(10,8),fontsize=12,title='中央政府、地方政府杠杆率分布和变化趋势图') #运行效果如下,其中最右侧的标尺,代表分布频数,即每个六边形状内分布的数据点数,图表中用频数代表颜色深浅,频数越大,颜色越深
9.2 调整x轴六边形数量--类似增加密度--gridsize
如果数据点太多时,希望增大统计的区间长度,以更加直观的观察分布情况,则可以调大gridsize的数值
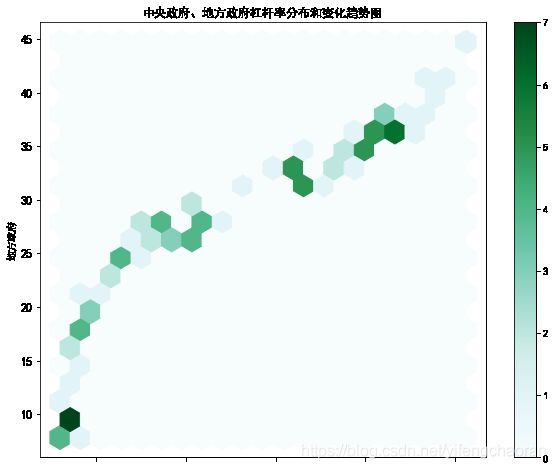
#gridsize默认大小是100,即会将数据归集到100个区间范围内,包括x轴和y轴,但是一般情况下,100比较多,设置个比如20个相对可视化效果会比较好 df.plot(x='中央政府',y='地方政府',kind='hexbin',figsize=(10,8),fontsize=12, gridsize=20,title='中央政府、地方政府杠杆率分布和变化趋势图') #运行后效果如下,可见中央政府和地方政府的杠杆率分布比较不均匀,在最小值、中间值、最大值处分布较多
十、常用绘图时设置参数
以下演示的方式,对所有的图表类型均通用
10.1 将不同数据,绘制到同一个图表的不同子图内,且不同子图单独绘图
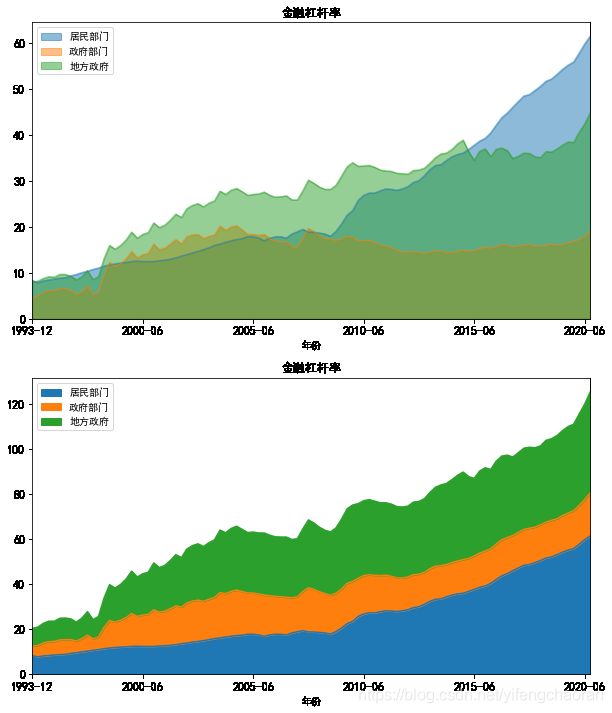
#比如上面的面积图,希望看下stacked参数不同时,绘图效果,则可分别将数据绘制在指定的子图内 fig, (ax1, ax2) = plt.subplots(2) #首先创建2个子图 df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='area', ax=ax1,stacked=False,figsize=(10,12),fontsize=12,title='金融杠杆率') #将图表1绘制到子图1内 df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='area',ax=ax2, figsize=(10,12),fontsize=12,title='金融杠杆率')#将图表1绘制到子图1内,数据和x轴数据也可完全不相同
10.2 设置数据序列颜色
#可通过color参数指定在绘制不同数据序列时,对应的颜色,或者pie图中不同slice的颜色,序列格式,一般用列表格式 colors=['r','g','b'] df.plot(x='年份',y=['居民部门','政府部门','地方政府'], color=colors, subplots=True, layout=(1,3),kind='line', figsize=(15,8),fontsize=12,title='金融杠杆率') #运行后如下图所示,指定了居民部门、政府部门、地方政府相应的折线的颜色

10.3 设置x和y坐标轴label
#可通过matplotlib库中的xlabel和ylabel设置x和y坐标轴的标签名,一般这些pandas的plot函数会根据实际情况自动添加,不过也可以根据自己需要自行设置
df.plot(x='年份',y=['居民部门','政府部门','地方政府'],kind='line', figsize=(15,8),fontsize=12,title='金融杠杆率')
plt.xlabel('年份')
plt.ylabel('杠杆率')
#运行后如下图所示,指定了居民部门、政府部门、地方政府相应的折线的颜色

10.4 其他参数设置
| 参数 | 说明 |
|---|---|
| title | 设置图表的标题,字符串格式 |
| linestyle | 设置不同折线的线型,序列格式(列表或元组),默认实线 |
| legend | 设置图表的图例是否展示,布尔,默认True,即展示 |
| marker | 设置散点图等点的形状 |
| alpha | 数值,设置透明度,默认为1,即不透明,0.5,即50%透明度 |
| secondary_y | 设置第二个y轴,只有当绘制的数据序列大于等于2时,设置才生效,可设置为True,或直接指定使用哪个数据序列作为第二个y轴的刻度 |
| linewidth | 设置线宽,数值 |
| table | 图下添加表,如果为True,则使用DataFrame中的数据绘制表格,并且数据将被转置以满足matplotlib的默认布局,一般不要添加,并且添加时性能较差 |
| logx | 设置x轴坐标刻度是否取对数,布尔,默认False,即不取 |
| logy | 设置y轴坐标刻度是否取对数,布尔,默认False,即不取 |
| loglog | 设置x轴和y轴坐标刻度是否均取对数,布尔,默认False,即不取 |
10.5 ax参数专门讲解
10.5.1 概述
DataFrame.plot()函数中,ax参数如果使用得当,则即可以享受pandas的plot函数带来的便捷性,同时又可以拥有matplotlib的灵活性,如文章以上介绍,其实plot函数给我们提供的参数,只是可以满足日常快速绘图的需求,并可以定义常见的一些绘图属性,但是如果需要定制比如x和y坐标轴的label,坐标轴,或者想隐藏坐标轴、指定坐标轴标签的字体和颜色等等,便无能为力。
而ax则是plot函数暴露出来,直接与matplotlib直接衔接的接口,ax可以认为是一个坐标系,每个图表的绘制,均需要在指定坐标系内完成,而ax参数则指定了此次df.plot调用,绘图的坐标系对象。
其实df.plot()函数本身,返回的便是此次绘图生成的坐标系,如果希望后续df.plot函数也绘制到之前df.plot返回的坐标系内,则可以将ax参数赋值成之前的坐标系值,不过一般不建议使用df.plot返回的坐标系,大部分情况下,一次df.plot即绘制一个
#可以使用ax参数指定此次绘图对应的坐标系(axes)对象 #1、用plt生成的axes赋值给ax #这种方法最为灵活,一般用于希望将多种(kind)图表拼接展示在一起的时候,如下左图所示 fig,axes=plt.subplots(1,2,figsize=(16,8)) #生成一个1行2列的绘图区,并返回图表本身和对应的2个坐标系 df.plot(x='年份',y='居民部门',ax=axes[0],title='居民部门杠杆率') #将图表绘制到第1个坐标系内 df.plot(x='年份',y=['非金融企业部门','政府部门'],ax=axes[1],title='非金&政府部门杠杆率')#将图表绘制到第2个坐标系内 #2、用上次plot函数返回的ax赋值给ax #这种方法,一般不常用,因为原则性一次plot调用,就是一次完整的绘图动作,相当于此次在之前的坐标系内进行绘图,如下右图所示 ax1=df.plot(x='年份',y='居民部门',title='居民部门杠杆率') #首先绘图并返回ax1坐标系 df.plot(x='年份',y=['非金融企业部门','政府部门'],ax=ax1)#指定在ax1坐标系继续绘图,就是追加绘图
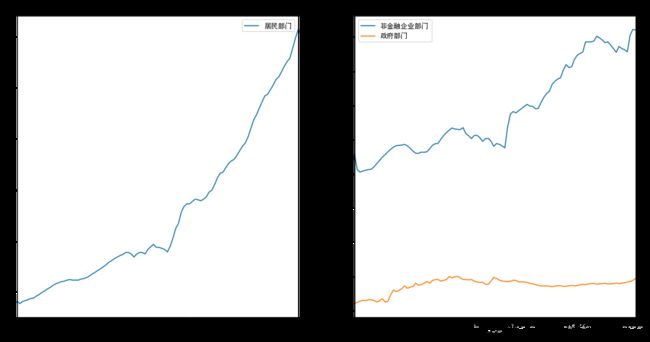

10.5.2 使用ax参数设置具体绘图对象--指定坐标系绘图
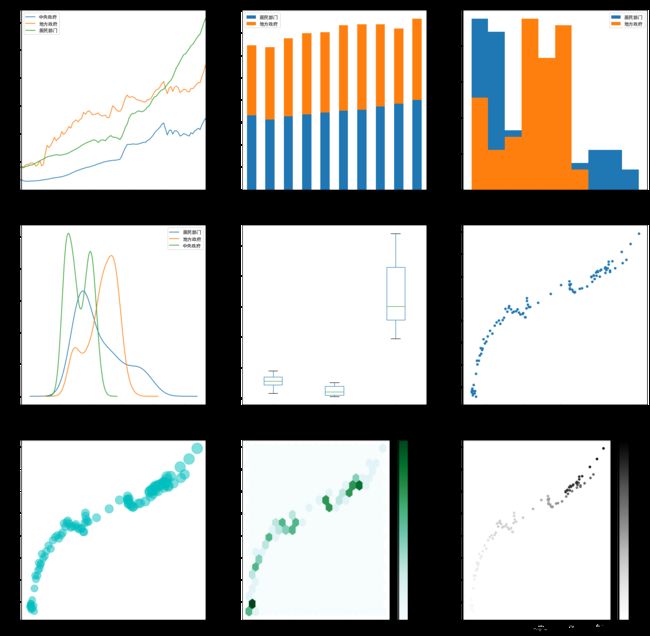
一般用的最多的,是先使用plt绘制一个比如3×3的绘图区域,包含9个坐标系,然后使用df.plot()分别在对应坐标系内进行绘图,以达到将不同类型的图表拼接到一起的效果
#使用时,原则性,一次df.plot()就是一次完整的绘图动作,如果希望将多次df.plot绘图动作生成的图表集中展示,则使用下面的方法 fig,axes=plt.subplots(3,3,figsize=(24,24)) #首先生成一个3×3的绘图区,共9个坐标系 df.plot(x='年份',y=['中央政府','地方政府','居民部门'],kind='line',ax=axes[0,0],title='各部门杠杆率') #将图绘制到第1行第1列的坐标系 df.iloc[range(10)].plot(x='年份',y=['居民部门','地方政府'],kind='bar',ax=axes[0,1] ,stacked=True,title='金融杠杆率') #将图绘制到第1行第2列的坐标系 df.plot(y=['居民部门','地方政府'],kind='hist',density = True,ax=axes[0,2] ,title='金融杠杆率区间分布情况') #将图绘制到第1行第3列的坐标系 df.plot(y=['居民部门','地方政府','中央政府'],kind='kde',ax=axes[1,0],title='金融杠杆率区间分布图') #将图绘制到第2行第1列的坐标系 df.plot(y=['地方政府','中央政府', '实体经济部门'],kind='box',ax=axes[1,1],title='各部门杠杆率箱线图')#将图绘制到第2行第2列的坐标系 df.plot(x='中央政府',y='地方政府',kind='scatter',ax=axes[1,2] ,title='中央政府和地方政府杠杆率相关性分析')#将图绘制到第2行第3列的坐标系 df.plot(x='中央政府',y='地方政府',kind='scatter',ax=axes[2,0] ,c='c' ,alpha=0.5,s=2*df['实体经济部门'], title='中央政府、地方政府即实体经济部门杠杆率相关性分析')#将图绘制到第3行第1列的坐标系 df.plot(x='中央政府',y='地方政府',kind='hexbin', ax=axes[2,1], gridsize=20,title='中央政府、地方政府杠杆率分布和变化趋势图') #将图绘制到第3行第2列的坐标系 df.plot(x='中央政府',y='地方政府',kind='scatter',ax=axes[2,2] ,c='实体经济部门' ,title='中央政府、地方政府即实体经济部门杠杆率相关性分析')#将图绘制到第3行第3列的坐标系
10.5.3 设置x和y坐标轴标签
可以根据df.plot返回的ax来设置坐标轴标签,也可以根据plt生成的坐标系下标来设置坐标轴标签
#1、根据df.plot函数返回的ax直接设置x和y坐标轴label,效果如下左图所示
ax=df.plot(x='年份',y=['中央政府','地方政府','居民部门'],kind='line',title='各部门杠杆率')
ax.set_xlabel('年月')
ax.set_ylabel('各部门杠杆率')
#2、先由plt生成坐标系,然后使用plt生成的坐标系设置x和y坐标轴label,效果如下右图所示
fig,axes=plt.subplots(1,2,figsize=(10,5)) #生成一个1×2的2个坐标系绘图区
df.plot(x='年份' ,y='居民部门',ax=axes[0],title='居民部门杠杆率') #绘制到第1个坐标系
df.plot(x='年份' ,y='政府部门',ax=axes[1],title='政府部门杠杆率')#绘制到第2个坐标系
axes[0].set_xlabel('年月')
axes[0].set_ylabel('居民部门杠杆率')
axes[1].set_xlabel('年月')
axes[1].set_ylabel('政府部门杠杆率')


10.5.4 matplotlib子图和subplots指定的子图之前关系
- 如果对某次df.plot设置了ax参数,则该次df.plot返回的ax,即指定的ax,因为既然已经指定了绘图ax坐标系,返回的肯定也是指定的坐标系
- df.plot如果将subplots设置为True,则其返回的ax是一个矩阵,矩阵的shape即layout指定的shape
- matplotlib中的plt.subplots其实生成的也是一个指定shape的绘图区域,类似以上的layout
- 如果df.plot设置了subplots为True,且此时指定了ax为plt生成的某个ax,此时会将df.plot生成的子图,分别依次绘制到plt对应的子图区域
- 比如df.plot,将subplots设置为True,且layout=(2,2),而plt生成的也是一个(2,2)的绘图区域,然后把df.plot的ax指定到了plt绘图区域内的第一个坐标系,则系统会自动将df.plot绘制的4个子图,依次绘制到plt生成的四个绘图坐标系内。
#以下演示当df.plot设置subplots=True时的效果 fig,axes=plt.subplots(1,2) df.plot(x='年份',y=['居民部门','政府部门'],subplots=True,layout=(1,2),ax=axes)
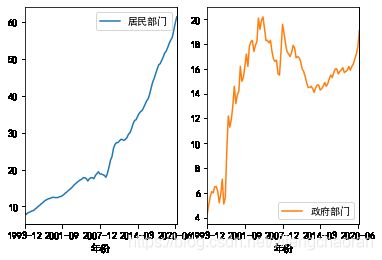
10.5.5 保存图表
#当图表绘制好之后,一般可能希望将其保存到本地留作他用,需要用fig对象进行保存,fig对象的获取一般有以下两种方式,本质道理一样
#1、使用plt.subplots方法返回的fig并保存
fig,axes=plt.subplots(1,1)
df.plot(x='年份',y='居民部门',ax=axes)
fig.savefig('filename.png')
#2、使用df.plot函数返回的ax简介获取fig并保存
ax=df.plot(x='年份',y='居民部门')
ax.get_figure().savefig('filename.png')
十一、不同图表类型的区别
一维数据分析
- 即分析一个数据序列的数值变化趋势、分布情况(频数、频率)、占比情况
- 一般line(数值变化)、bar(数值变化)、barh(数值变化)、hist(数值分布)、kde(数值分布)、box(数值分布)、pie(占比)、area(变化趋势、占比)适用于进行以上一维数据分析
二维数据分析
- 即分析两个数据序列之间的数值关联变化趋势、分布情况、占比情况等
- 一般scatter、hexbin适用于进行以上二维数据分析
其他数据分析和可视化工具
- 后续可学习matplotlib库以及seaborn库,而seaborn库最为推荐,因为做出来的图表颜值非常高,并且很容易上手
- Plotly库也是强雷建议学习的,因为其有很多非常惊艳的可视化工具
到此这篇关于pandas实现数据可视化的示例代码的文章就介绍到这了,更多相关pandas 数据可视化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!