SQL进阶教程 | 史上最易懂SQL教程 5小时零基础成长SQL大师(3)
【第八章】视图
创建视图
- 就是创建虚拟表,自动化一些重复性的查询模块,简化各种复杂操作(包括复杂的子查询和连接等)
- 注意视图虽然可以像一张表一样进行各种操作,但并没有真正储存数据,数据仍然储存在原始表中,视图只是储存起来的模块化的查询结果,是为了方便和简化后续进一步操作而储存起来的虚拟表。
- 创建 sales_by_client 视图
USE sql_invoicing;
CREATE VIEW sales_by_client AS
SELECT
client_id,
name,
SUM(invoice_total) AS total_sales
FROM clients c
JOIN invoices i USING(client_id)
GROUP BY client_id, name;
-- 虽然实际上这里加不加上name都一样
- 若要删掉该视图用 DROP VIEW sales_by_client 或通过右键菜单
- 创建视图后可就当作 sql_invoicing 库下一张表一样进行各种操作
USE sql_invoicing;
SELECT
s.name,
s.total_sales,
phone
FROM sales_by_client s
JOIN clients c USING(client_id)
WHERE s.total_sales > 500
- 创建一个客户差额表视图,可以看到客户的id,名字以及差额(发票总额-支付总额)
USE sql_invoicing;
CREATE VIEW clients_balance AS
SELECT
client_id,
c.name,
SUM(invoice_total - payment_total) AS balance
FROM clients c
JOIN invoices USING(client_id)
GROUP BY client_id
更新或删除视图
-
修改视图可以先DROP在CREATE(也可以用CREATE OR REPLACE)
-
视图的查询语句可以在编辑模式下查看和修改,但最好是保存为sql文件并放在源码控制妥善管理
-
想在上一节的顾客差额视图的查询语句最后加上按差额降序排列
法1. 先删除再重建
USE sql_invoicing;
DROP VIEW IF EXISTS clients_balance;
-- 若不存在这个视图,直接 DROP 会报错,所以要加上 IF EXISTS 先检测有没有这个视图
CREATE VIEW clients_balance AS
……
ORDER BY balance DESC
法2. 用REPLACE关键字,即用 CREATE OR REPLACE VIEW clients_balance AS,和上面等效,不过上面那种分成两个语句的方式要用的多一点
USE sql_invoicing;
CREATE OR REPLACE VIEW clients_balance AS
……
ORDER BY balance DESC
- 如何保存视图的原始查询语句?
法1.
(推荐方法) 将原始查询语句保存为 views 文件夹下的和与视图同名的 clients_balance.sql 文件,然后将这个文件夹放在源码控制下(put these files under source control), 通常放在 git repository(仓库)里与其它人共享,团队其他人因此能在自己的电脑上重建这个数据库

法2.
若丢失了原始查询语句,要修改的话可点击视图的扳手按钮打开编辑模式,可看到如下被MySQL处理了的查询语句
MySQL在前面加了些莫名其妙的东西并且在所有库名表名字段名外套上反引号防止名称冲突(当对象名和MySQL里的关键字相同时确保被当作对象名而不是关键字),但这都不影响
直接做我们需要的修改,如加上ORDER BY balance DESC 然后点apply就行了
CREATE
ALGORITHM = UNDEFINED
DEFINER = `root`@`localhost`
SQL SECURITY DEFINER
VIEW `clients_balance` AS
SELECT
`c`.`client_id` AS `client_id`,
`c`.`name` AS `name`,
SUM((`invoices`.`invoice_total` - `invoices`.`payment_total`)) AS `balance`
FROM
(`clients` `c`
JOIN `invoices` ON ((`c`.`client_id` = `invoices`.`client_id`)))
GROUP BY `c`.`client_id`
ORDER BY balance DESC
法2是没有办法的办法,当然最好还是将 views 保存为 sql 文件并放入源码控制
可更新视图
- 视图作为虚拟表/衍生表,除了可用在查询语句SELECT中,也可以用在增删改(INSERT DELETE UPDATE)语句中,但后者有一定的前提条件。
- 如果一个视图的原始查询语句中没有如下元素:
- DISTINCT 去重
- GROUP BY/HAVING/聚合函数 (后两个通常是伴随着 GROUP BY 分组出现的)
- UNION 纵向连接
则该视图是可更新视图(Updatable Views),可以增删改,否则只能查。
- 另外,增(INSERT)还要满足附加条件:视图必须包含底层原表的所有必须字段
- 总之,一般通过原表修改数据,但当出于安全考虑或其他原因没有某表的直接权限时,可以通过视图来修改底层数据(?),前提是视图是可更新的。
- 之后会讲关于安全和权限的内容
- 创建视图(新虚拟表)invoices_with_balance(带差额的发票记录表)
USE sql_invoicing;
CREATE OR REPLACE VIEW invoices_with_balance AS
SELECT
/* 这里有个小技巧,要插入表中的多列列名时,
可从左侧栏中连选并拖入相关列 */
invoice_id,
number,
client_id,
invoice_total,
payment_total,
invoice_date,
invoice_total - payment_total AS balance, -- 新增列
due_date,
payment_date
FROM invoices
WHERE (invoice_total - payment_total) > 0
/* 这里不能用列别名balance,会报错说不存在,
必须用原列名的表达式,这还是执行顺序的问题
之前讲WHERE和HAVING作为事前筛选和事后筛选的区别时提到过 */
该视图满足条件,是可更新视图,故可以增删改:
1.删:
删掉id为1的发票记录
DELETE FROM invoices_with_balance
WHERE invoice_id = 1
2.改:
将2号发票记录的期限延后两天
UPDATE invoices_with_balance
SET due_date = DATE_ADD(due_date, INTERVAL 2 DAY)
WHERE invoice_id = 2
3.增:
在视图中用INSERT新增记录的话还有另一个前提,即视图必须包含其底层所有原始表的所有必须字段
例如,若这个 invoices_with_balance 视图里没有 invoice_date 字段(invoices 中的必须字段),那就无法通过该视图向 invoices 表新增记录,因为 invoices 表不会接受 invoice_date 字段为空的记录
WITH CHECK OPTION 子句
- 在视图的原始查询语句最后加上 WITH CHECK OPTION 可以防止执行那些会让视图中某些行(记录)消失的修改语句。
- 接前面的 invoices_with_balance 视图的例子,该视图与原始的 orders 表相比增加了balance(invouce_total - payment_total) 列,且只显示 balance 大于0的行(记录),若将某记录(如2号订单)的 payment_total 改为和 invouce_total 相等,则 balance 为0,该记录会从视图中消失:
UPDATE invoices_with_balance
SET payment_total = invoice_total
WHERE invoice_id = 2
- 更新后会发现invoices_with_balance视图里2号订单消失。
- 但在视图原始查询语句最后加入 WITH CHECK OPTION 后,对3号订单执行类似上面的语句后会报错:
UPDATE invoices_with_balance
SET payment_total = invoice_total
WHERE invoice_id = 3
-- Error Code: 1369. CHECK OPTION failed 'sql_invoicing.invoices_with_balance'
视图的其他优点
- 三大优点:简化查询、增加抽象层和减少变化的影响、数据安全性
- 具体来讲:
1、(首要优点)简化查询 simplify queries
2、增加抽象层,减少变化的影响 Reduce the impact of changes:视图给表增加了一个抽象层2、(模块化),这样如果数据库设计改变了(如一个字段从一个表转移到了另一个表),只需修改视图的查询语句使其能保持原有查询结果即可,不需要修改使用这个视图的那几十个查询。相反,如果没有视图这一层的话,所有查询将直接使用指向原表的原始查询语句,这样一旦更改原表设计,就要相应地更改所有的这些查询。
3、限制对原数据的访问权限 Restrict access to the data:在视图中可以对原表的行和列进行筛选,这样如果你禁止了对原始表的访问权限,用户只能通过视图来修改数据,他们就无法修改视图中未返回的那些字段和记录。但注意这通常并不简单,需要良好的规划,否则最后可能搞得一团乱。
了解这些优点,但不要盲目将他们运用在所有的情形中。
【第九章】存储过程
什么是存储过程
- 存储过程三大作用:
1.储存和管理SQL代码 Store and organize SQL
2.性能优化 Faster execution
3.数据安全 Data security
导航
之前学了增删改查,包括复杂查询以及如何运用视图来简化查询。
假设你要开发一个使用数据库的应用程序,你应该将SQL语句写在哪里呢?
如果将SQL语句内嵌在应用程序的代码里,将使其混乱且难以维护,所以应该将SQL代码和应用程序代码分开,将SQL代码储存在所属的数据库中,具体来说,是放在储存过程(stored procedure)和函数中。
储存过程是一个包含SQL代码模块的数据库对象,在应用程序代码中,我们调用储存过程来获取和保存数据(get and save the data)。也就是说,我们使用储存过程来储存和管理SQL代码。
使用储存程序还有另外两个好处。首先,大部分DBMS会对储存过程中的代码进行一些优化,因此有时储存过中的SQL代码执行起来会更快。
此外,就像视图一样,储存过程能加强数据安全。比如,我们可以移除对所有原始表的访问权限,让各种增删改的操作都通过储存过程来完成,然后就可以决定谁可以执行何种储存过程,用以限制用户对我们数据的操作范围,例如,防止特定的用户删除数据。
所以,储存过程很有用,本章将学习如何创建和使用它。
创建一个存储过程
DELIMITER $$
-- delimiter n. 分隔符
CREATE PROCEDURE 过程名()
BEGIN
……;
……;
……;
END$$
DELIMITER ;
- 创造一个get_clients()过程
CREATE PROCEDURE get_clients()
-- 括号内可传入参数,之后会讲
-- 过程名用小写单词和下划线表示,这是约定熟成的做法
BEGIN
SELECT * FROM clients;
END
BEGIN 和 END 之间包裹的是此过程(PROCEDURE)的内容(body),内容里可以有多个语句,但每个语句都要以 ; 结束,包括最后一个。
为了将过程内容内部的语句分隔符与SQL本身执行层面的语句分隔符 ; 区别开,要先用 DELIMITER(分隔符) 关键字暂时将SQL语句的默认分隔符改为其他符号,一般是改成双美元符号 $$ ,创建过程结束后再改回来。注意创建过程本身也是一个完整SQL语句,所以别忘了在END后要加一个暂时语句分隔符 $ $
- 过程内容中所有语句都要以 ; 结尾并且因此要暂时修改SQL本身的默认分隔符,这些都是MySQL地特性,在SQL Server等就不需要这样
DELIMITER $$
CREATE PROCEDURE get_clients()
BEGIN
SELECT * FROM clients;
END$$
DELIMITER ;
- 调用此程序:
法1. 点击闪电按钮
法2. 用CALL关键字
USE sql_invoicing;
CALL get_clients()
或
CALL sql_invoicing.get_clients()
- 上面讲的是如何在SQL中调用储存过程,但更多的时候其实是要在应用程序代码(可能是 C#、JAVA 或 Python 编写的)中调用。
- 创造一个储存过程 get_invoices_with_balance(取得有差额(差额不为0)的发票记录)
DROP PROCEDURE get_invoices_with_balance;
-- 注意DROP语句里这个过程没有带括号
DELIMITER $$
CREATE PROCEDURE get_invoices_with_balance()
BEGIN
SELECT *
FROM invoices_with_balance
-- 这是之前创造的视图
-- 用视图好些,因为有现成的balance列
WHERE balance > 0;
END$$
DELIMITER ;
CALL get_invoices_with_balance();
使用MySQL工作台创建存储过程
也可以用点击的方式创造过程,右键选择 Create Stored Procedure,填空,Apply。这种方式 Workbench 会帮你处理暂时修改分隔符的问题
这种方式一样可以储存SQL文件
事实证明,mosh很喜欢用这种方式,后面基本都是用这种方式创建过程(毕竟不用管改分隔符的问题,能偷懒又何必自找麻烦呢?谁还不是条懒狗呢?)
删除存储过程
- 这一节学习删除储存过程,这在发现储存过程里有错误需要重建时很有用。
- 一个创建过程(get_clients)的标准模板
USE sql_invoicing;
DROP PROCEDURE IF EXISTS get_clients;
-- 注意加上【IF EXISTS】,以免因为此过程不存在而报错
DELIMITER $$
CREATE PROCEDURE get_clients()
BEGIN
SELECT * FROM clients;
END$$
DELIMITER ;
CALL get_clients();
- 最佳实践
同视图一样,最好把删除和创建每一个过程的代码也储存在不同的SQL文件中,并把这样的文件放在 Git 这样的源码控制下,这样就能与其它团队成员共享 Git 储存库。他们就能在自己的机器上重建数据库以及该数据库下的所有的视图和储存过程
如上面那个实例,可储存在 stored_procedures 文件夹(之前已有 views 文件夹)下的 get_clients.sql 文件。当你把所有这些脚本放进源码控制,你能随时回来查看你对数据库对象所做的改动。
参数
CREATE PROCEDURE 过程名
(
参数1 数据类型,
参数2 数据类型,
……
)
BEGIN
……
END
- 导航
学完了如何创建和删除过程,这一节学习如何给过程添加参数
通常我们使用参数来给储存过程传值,但我们也可以用参数获取调用程序的结果值,第二个我们之后再讲
- 创建过程 get_clients_by_state,可返回特定州的顾客
USE sql_invoicing;
DROP PROCEDURE IF EXISTS get_clients_by_state;
DELIMITER $$
CREATE PROCEDURE get_clients_by_state
(
state CHAR(2) -- 参数的数据类型
)
BEGIN
SELECT * FROM clients c
WHERE c.state = state;
END$$
DELIMITER ;
- 参数类型一般设定为 VARCHAR,除非能确定参数的字符数
- 多个参数可用逗号隔开
WHERE state = state 是没有意义的,有两种方法可以区分参数和列名:一种是取不一样的参数名如 p_state 或 state_param,第二种是像上面一样给表起别名,然后用带表前缀的列名以同参数名区分开。
CALL get_clients_by_state('CA')
不传入’CA’会报错,因为MySQL里所有参数都是必须参数
- 创建过程 get_invoices_by_client,通过 client_id 来获得发票记录
client_id 的数据类型设置可以参考原表中该字段的数据类型(进入设计模式)
USE sql_invoicing;
DROP PROCEDURE IF EXISTS get_invoices_by_client ;
DELIMITER $$
CREATE PROCEDURE get_invoices_by_client
(
client_id INT -- 为何不写INT(11)?
)
BEGIN
SELECT *
FROM invoices i
WHERE i.client_id = client_id;
END$$
DELIMITER ;
CALL get_invoices_by_client(1);
Mosh 创建和调用都直接用的点击法
带默认值的参数
- 给参数设置默认值,主要是运用条件语句块和替换空值函数
- 回顾 :
SQL中的条件类语句:
1.替换空值 IFNULL(值1,值2)
2.条件函数 IF(条件表达式, 返回值1, 返回值2)
3.条件语句块
IF 条件表达式 THEN
语句1;
语句2;
……;
[ELSE](可选)
语句1;
语句2;
……;
END IF;
-- 别忘了【END IF】
- 把 get_clients_by_state 过程的默认参数设为’CA’,即默认查询加州的客户
USE sql_invoicing;
DROP PROCEDURE IF EXISTS get_clients_by_state;
DELIMITER $$
CREATE PROCEDURE get_clients_by_state
(
state CHAR(2)
)
BEGIN
IF state IS NULL THEN
SET state = 'CA';
/* 注意别忽略SET,
SQL 里单个等号 '=' 是比较操作符而非赋值操作符
'=' 与 SET 配合才是赋值 */
END IF;
SELECT * FROM clients c
WHERE c.state = state;
END$$
DELIMITER ;
调用
CALL get_clients_by_state(NULL)
- 注意要调用过程并使用其默认值时时要传入参数 NULL ,MySQL不允许不传参数。
- 将 get_clients_by_state 过程设置为默认选取所有顾客
法1. 用IF条件语句块实现
……
BEGIN
IF state IS NULL THEN
SELECT * FROM clients c;
ELSE
SELECT * FROM clients c
WHERE c.state = state;
END IF;
END$$
……
法2. 用IFNULL替换空值函数实现
……
BEGIN
SELECT * FROM clients c
WHERE c.state = IFNULL(state, c.state)
END$$
……
若参数为NULL,则返回c.state,利用 c.state = c.state 永远成立来返回所有顾客,思路很巧妙。
- 创建一个叫 get_payments 的过程,包含 client_id 和 payment_method_id 两个参数,数据类型分别为 INT(4) 和 TINYINT(1) (1个字节,能存0~255,之后会讲数据类型,好奇可以谷歌 ‘mysql int size’),默认参数设置为返回所有记录
这是一个为你的工作预热的练习
USE sql_invoicing;
DROP PROCEDURE IF EXISTS get_payments;
DELIMITER $$
CREATE PROCEDURE get_payments
(
client_id INT, -- 不用写成INT(4)
payment_method_id TINYINT
)
BEGIN
SELECT * FROM payments p
WHERE
p.client_id = IFNULL(client_id, p.client_id) AND
p.payment_method = IFNULL(payment_method_id, p.payment_method);
-- 再次小心这种实际工作中各表相同字段名称不同的情况
END$$
DELIMITER ;
- 调用:
所有支付记录
CALL get_payments(NULL, NULL)
1号顾客的所有记录
CALL get_payments(1, NULL)
3号支付方式的所有记录
CALL get_payments(NULL, 3)
5号顾客用2号支付方式的所有记录
CALL get_payments(5, 2)
- 注意一个区别:
1.Parameter 形参(形式参数):创建过程中用的占位符,如 client_id、payment_method_id
2.Argument 实参(实际参数):调用时实际传入的值,如 1、3、5、NULL
参数验证
- 过程除了可以查,也可以增删改,但修改数据前最好先进行参数验证以防止不合理的修改
- 主要利用条件语句块和 SIGNAL SQLSTATE MESSAGE_TEXT 关键字
- 具体来说是在过程的内容开头加上这样的语句:
IF 错误参数条件表达式 THEN
SIGNAL SQLSTATE '错误类型'
[SET MESSAGE_TEXT = '关于错误的补充信息'](可选)
- 创建一个 make_payment 过程,含 invoice_id, payment_amount, payment_date 三个参数
(Mosh还是喜欢通过右键 Create Stored Procedure 地方式创建,不必考虑暂时改分隔符的问题,更简便)
CREATE DEFINER=`root`@`localhost` PROCEDURE `make_payment`(
invoice_id INT,
payment_amount DECIMAL(9, 2),
/*
9是精度, 2是小数位数。
精度表示值存储的有效位数,
小数位数表示小数点后可以存储的位数
见:
https://dev.mysql.com/doc/refman/8.0/en/fixed-point-types.html
*/
payment_date DATE
)
BEGIN
UPDATE invoices i
SET
i.payment_total = payment_amount,
i.payment_date = payment_date
WHERE i.invoice_id = invoice_id;
END
为了防止传入像 -100 的 payment_total 这样不合理的参数,要在增加一段参数验证语句,利用的是条件语句块加SIGNAL关键字,和其他编程语言中的抛出异常等类似
具体的错误类型可通过谷歌 “sqlstate error” 查阅(推荐使用IBM的那个表),这里是 ‘22 Data Exception’ 大类中的 ‘22003 A numeric value is out of range.’ 类型
注意还添加了 MESSAGE_TEXT 以提供给用户参数错误的更具体信息。现在传入 负数的 payment_amount 就会报错 'Error Code: 1644. Invalid payment amount ’
- 注意
过犹不及(“Too much of a good thing is a bad thing”),加入过多的参数验证会让代码过于复杂难以维护,像 payment_amount 非空这样的验证就不需要添加因为 payment_amount 字段本身就不允许空值因此MySQL会自动报错,。
参数验证工作更多的应该在应用程序端接受用户输入数据时就检测和报告,那样更快也更有效。储存过程里的参数验证只是在有人越过应用程序直接访问储存过程时作为最后的防线。这里只应该写那些最关键和必要的参数验证。
输出参数
- 输入参数是用来给过程传入值的,我们也可以用输出参数来获取过程的结果值
- 具体是在参数的前面加上 OUT 关键字,然后再 SELECT 后加上 INTO……
- 调用麻烦,如无需要,不要多此一举
- 创造 get_unpaid_invoices_for_client 过程,获取特定顾客所有未支付过的发票记录(即 payment_total = 0 的发票记录)
CREATE DEFINER=`root`@`localhost` PROCEDURE `get_unpaid_invoices_for_client`(
client_id INT
)
BEGIN
SELECT COUNT(*), SUM(invoice_total)
FROM invoices i
WHERE
i.client_id = client_id AND
payment_total = 0;
END
调用
call sql_invoicing.get_unpaid_invoices_for_client(3);
得到3号顾客的 COUNT(*) 和 SUM(invoice_total) (未支付过的发票数量和总金额)分别为2和286
我们也可以通过输出参数(变量)来获取这两个结果值,修改过程,添加两个输出参数 invoice_count 和 invoice_total:
CREATE DEFINER=`root`@`localhost` PROCEDURE `get_unpaid_invoices_for_client`(
client_id INT,
OUT invoice_count INT,
OUT invoice_total DECIMAL(9, 2)
-- 默认是输入参数,输出参数要加【OUT】前缀
)
BEGIN
SELECT COUNT(*), SUM(invoice_total)
INTO invoice_count, invoice_total
-- SELECT后跟上INTO语句将SELECT选出的值传入输出参数(输出变量)中
FROM invoices i
WHERE
i.client_id = client_id AND
payment_total = 0;
END
- 调用:单击闪电按钮调用,只用输入client_id,得到如下语句结果

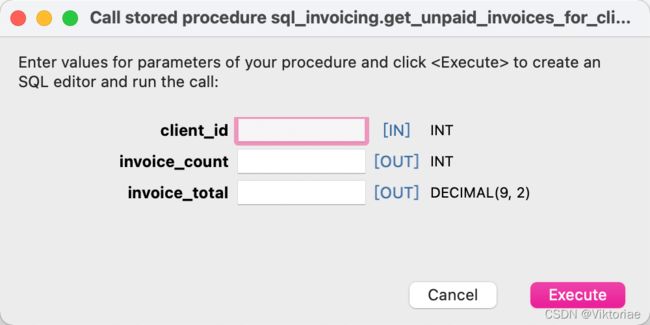
set @invoice_count = 0;
set @invoice_total = 0;
call sql_invoicing.get_unpaid_invoices_for_client(3, @invoice_count, @invoice_total);
select @invoice_count, @invoice_total;
先定义以@前缀表示用户变量,将初始值设为0。(变量(variable)简单讲就是储存单一值的对象)再调用过程,将过程结果赋值给这两个输出参数,最后再用SELECT查看。
很明显,通过输出参数获取并读取数据有些麻烦,若无充足的原因,不要多此一举。
变量
- 两种变量:
1.用户或会话变量 SET @变量名 = ……
2.本地变量 DECLARE 变量名 数据类型 [DEFAULT 默认值] - 用户或会话变量(User or session variable):
上节课讲过,用 SET 语句并在变量名前加 @ 前缀来定义,将在整个用户会话期间存续,在会话结束断开MySQL链接时才被清空,这种变量主要在调用带输出的储存过程时,作为输出参数来获取结果值。
set @invoice_count = 0;
set @invoice_total = 0;
call sql_invoicing.get_unpaid_invoices_for_client(3, @invoice_count, @invoice_total);
select @invoice_count, @invoice_total;
- 本地变量(Local variable)
在储存过程或函数中通过 DECLARE 声明并使用,在函数或储存过程执行结束时就被清空,常用来执行过程(或函数)中的计算 - 创造一个 get_risk_factor 过程,使用公式 risk_factor = invoices_total / invoices_count * 5
CREATE DEFINER=`root`@`localhost` PROCEDURE `get_risk_factor`()
BEGIN
-- 声明三个本地变量,可设默认值
DECLARE risk_factor DECIMAL(9, 2) DEFAULT 0;
DECLARE invoices_total DECIMAL(9, 2);
DECLARE invoices_count INT;
-- 用SELECT得到需要的值并用INTO传入invoices_total和invoices_count
SELECT SUM(invoice_total), COUNT(*)
INTO invoices_total, invoices_count
FROM invoices;
-- 用SET语句给risk_factor计算赋值
SET risk_factor = invoices_total / invoices_count * 5;
-- 展示最终结果risk_factor
SELECT risk_factor;
END
函数
- 创建函数和创建过程的两点不同
- 参数设置和body内容之间,有一段确定返回值类型以及函数属性的语句段
RETURNS INTEGER
DETERMINISTIC
READS SQL DATA
MODIFIES SQL DATA
……
- 最后是返回(RETURN)值而不是查询(SELECT)值
RETURN IFNULL(risk_factor, 0);
- 删除
DROP FUNCTION [IF EXISTS] 函数名
- 导航
现在已经学了很多内置函数,包括聚合函数和处理数值、文本、日期时间的函数,这一节学习如何创建函数
函数和储存过程的作用非常相似,唯一区别是函数只能返回单一值而不能返回多行多列的结果集,当你只需要返回一个值时就可以创建函数。
- 在上一节的储存过程 get_risk_factor 的基础上,创建函数 get_risk_factor_for_client,计算特定顾客的 risk_factor
还是用右键 Create Function 来简化创建
创建函数的语法和创建过程的语法极其相似,区别只在两点:
1、参数设置和body内容之间,有一段确定返回值类型以及函数属性的语句段
2、最后是返回(RETURN)值而不是查询(SELECT)值
另外,关于函数属性的说明:
1、DETERMINISTIC 决定性的:唯一输入决定唯一输出,和数据的改动更新无关,比如税收是订单总额的10%,则以订单总额为输入税收为输出的函数就是决定性的(?),但这里每个顾客的 risk_factor 会随着其发票记录的增加更新而改变,所以不是DETERMINISTIC的
2、READS SQL DATA:需要用到 SELECT 语句进行数据读取的函数,几乎所有函数都满足
3、MODIFIES SQL DATA:函数中有 增删改 或者说有 INSERT DELETE UPDATE 语句,这个例子不满足
CREATE DEFINER=`root`@`localhost` FUNCTION `get_risk_factor_for_client`
(
client_id INT
)
RETURNS INTEGER
-- DETERMINISTIC
READS SQL DATA
-- MODIFIES SQL DATA
BEGIN
DECLARE risk_factor DECIMAL(9, 2) DEFAULT 0;
DECLARE invoices_total DECIMAL(9, 2);
DECLARE invoices_count INT;
SELECT SUM(invoice_total), COUNT(*)
INTO invoices_total, invoices_count
FROM invoices i
WHERE i.client_id = client_id;
-- 注意不再是整体risk_factor而是特定顾客的risk_factor
SET risk_factor = invoices_total / invoices_count * 5;
RETURN IFNULL(risk_factor, 0);
END
有些顾客没有发票记录,NULL乘除结果还是NULL,所以最后用 IFNULL 函数将这些人的 risk_factor 替换为 0
调用案例:
SELECT
client_id,
name,
get_risk_factor_for_client(client_id) AS risk_factor
-- 函数当然是可以处理整列的,我第一时间竟只想到传入具体值
-- 不过这里更像是一行一行的处理,所以应该每次也是传入1个client_id值
FROM clients
删除,还是用DROP
DROP FUNCTION [IF EXISTS] get_risk_factor_for_client
- 和视图和过程一样,也最好存入SQL文件并加入源码控制,老生常谈了。