Maxwell 一款简单易上手的实时抓取Mysql数据的软件
第一章 Maxwell概述
1.1、Maxwell简介
Maxwell 是由美国 Zendesk 开源,用 Java 编写的 MySQL 实时抓取软件。
实时读取MySQL 二进制日志 Binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
官网地址:
http://maxwells-daemon.io/
官网页面:

1.2、maxwell工作原理
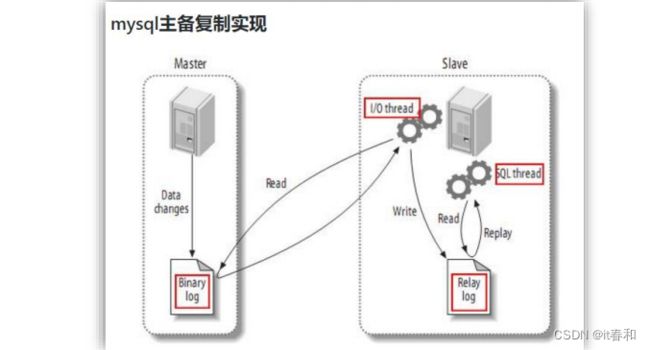
1.2.1、mysql主从复制过程
1、Master 主库将改变记录,写到二进制日志(binary log)中
2、Slave 从库向 mysql master 发送 dump 协议,将 master 主库的 binary log events 拷贝到它的中继日志(relay log);
3、Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
1.2.2、Mysql中的binlog
【1】什么是binlog
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和 DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
✅ 其一:MySQL Replication 在 Master 端开启 binlog,Master 把它的二进制日志传递给 slaves 来达到 master-slave 数据一致的目的。
✅ 其二:自然就是数据恢复了,通过使用 mysqlbinlog 工具来使恢复数据。
二进制日志包括两类文件:
二进制日志索引文件(文件名后缀为.index)用于记录所有 的二进制文件
二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
【2】binlog的开启
首先我们需要找到mysql的配置文件的位置
/etc/my.cnf
在 mysql 的配置文件下,修改配置
在[mysqld] 区块,设置/添加 log-bin=mysql-bin
这个表示 binlog 日志的前缀是 mysql-bin,以后生成的日志文件就是 mysql-bin.000001的文件后面的数字按顺序生成,每次 mysql 重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
【3】binlog的分类设置
mysql binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。
➢ 三种格式的区别:
1、statement
语句级,binlog 会记录每次一执行写操作的语句。
相对 row 模式节省空间,但是可能产生不一致性,比如 update test set create_date=now(); 如果用 binlog 日志进行恢复,由于执行时间不同可能产生的数据就不同。优点: 节省空间
缺点: 有可能造成数据不一致。
2、row
行级, binlog 会记录每次操作后每行记录的变化。
优点:
保持数据的绝对一致性。因为不管 sql 是什么,引用了什么函数,他只记录执行后的效果。缺点:占用较大空间。
3、mixed
混合级别,statement 的升级版,一定程度上解决了 statement 模式因为一些情况而造成的数据不一致问题
默认还是 statement,在某些情况下,譬如: 当函数中包含 UUID() 时; 包含 AUTO_INCREMENT 字段的表被更新时; 执行 INSERT DELAYED 语句时; 用 UDF 时; 会按照 ROW 的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要对binlog 监控的情况都不方便。
综合上面对比,Maxwell 想做监控分析,选择 row 格式比较合适
1.2.3、maxwell工作原理
Maxwell 的工作原理很简单,就是
把自己伪装成 MySQL 的一个 slave,然后以 slave的身份假装从 MySQL(master)复制数据
1.2.4、Maxwell和Canal的区别

第二章 Maxwell的安装
2.1、下载地址
(1)Maxwell 官网地址:http://maxwells-daemon.io/
(2)文档查看地址:http://maxwells-daemon.io/quickstart/
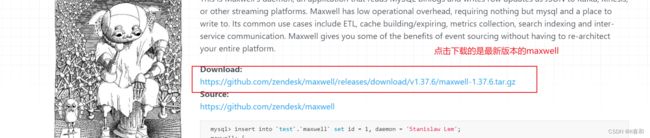
但是我们查看版本更新日志就会发现:
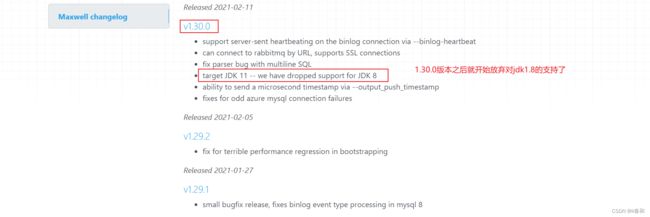
由于我的机器安装的是jdk1,8,所以这里我们使用1.30.0之前的版本
2.2、Maxwell安装部署
环境准备:
确保机器上已经安装好了kafka和mysql,zookeeper
1、将maxwell-1.29.2.tar.gz 到/opt/software 下
2、将maxwell解压到/opt/module即可
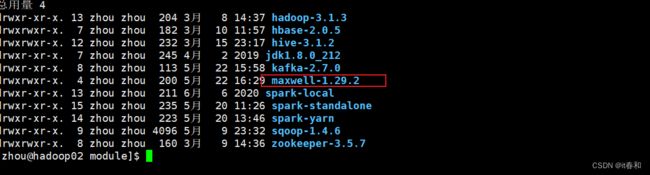
3、查看maxwell的目录结构
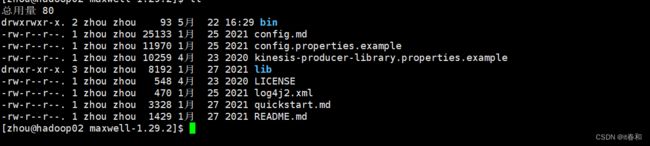
2.3、mysql环境准备
1、修改mysql的配置文件,开启mysql的binlog设置
sudo vim /etc/my.cnf
server_id=1
# 设置生成的二进制文件的前缀
log-bin=mysql-bin
# 设置binlog的二进制文件的日志级别 行级模式
binlog_format=row
# binlog的执行的库 如果不加这个参数那么mysql会对所有的库都生成对应的binlog 即对所有的库尽心binlog监控
# 设置只监控某个或某些数据库
binlog-do-db=test_maxwell
binlog-do-db=test_maxwell1

2、重启mysql服务
sudo systemctl restart mysqld
3、登录mysql并查看是否修改成功
登录进入mysql键入以下语句
show variables like '%binlog%';

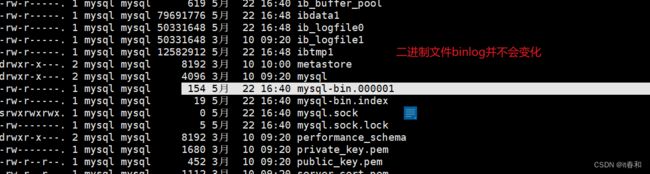
4、进入/var/lib/mysql 目录,查看 MySQL 生成的 binlog 文件

注:
MySQL 生成的 binlog 文件初始大小一定是 154 字节,然后前缀是 log-bin 参数配置的,后缀是默认从.000001,然后依次递增。\
除了 binlog 文件文件以外,MySQL 还会额外生产一个.index 索引文件用来记录当前使用的 binlog 文件。
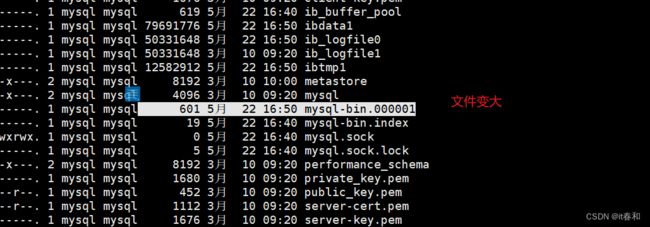
5、我们来测试一下
【1】使用sqlyog连接到mysql


再查看二进制文件
2.4、初始化Maxwell元数据库
1、在 MySQL 中建立一个 maxwell 库用于存储 Maxwell 的元数据
CREATE DATABASE maxwell;

在我们使用的时候它会自己创建对应的表,这里我们不需要自己创建表。你也不知道创建哪些表
2、设置 mysql 用户密码安全级别
set global validate_password_length=4;
set global validate_password_policy=0;
3、分配一个账号可以操作该数据库
GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY '123456';

4、分配这个账号可以监控其他数据库的权限
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';

5、刷新mysql表权限
flush privileges;
![]()
第三章 Maxwell的使用
3.1、maxwell进程的启动
maxwell进程的启动有两种方式
1、使用命令行参数启动 Maxwell 进程
bin/maxwell --user='maxwell' --password='123456' --host='hadoop02' --producer=stdout
参数解读:
--user 连接 mysql 的用户
--password 连接 mysql 的用户的密码
--host mysql 安装的主机名
--producer 生产者模式(stdout:控制台 kafka:kafka 集群)

测试:

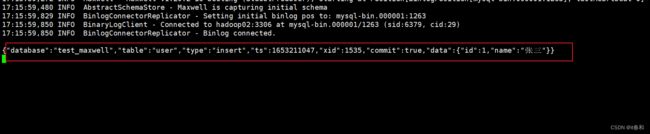
2、配置文件启动maxwell
【1】复制一份config.properties.example文件
【2】修改config.properties文件

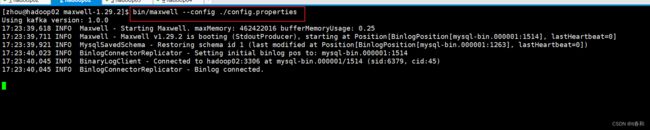
【3】启动
bin/maxwell --config ./config.properties

3.2、maxwell的案例实操
3.2.1、监控 Mysql 数据并在控制台打印
【1】运行maxwell监控mysql数据更新
bin/maxwell --user='maxwell' --password='123456' --host='hadoop02' --producer=stdout
【2】向 mysql 的 test_maxwell 库的 user表插入一条数据,查看 maxwell 的控制台输出

输出的json格式数据
{
"database": "test_maxwell",
"table": "user",
"type": "insert",
"ts": 1653211725,
"xid": 2319,
"commit": true,
"data": {
"id": 2,
"name": "李四"
}
}
秒级时间戳
【3】向 mysql 的 test_maxwell 库的 user表同时插入 3 条数据,控制台出现了 3 条 json日志,说明 maxwell 是以数据行为单位进行日志的采集的。
INSERT INTO USER VALUES (3,"张无忌"),(4,"孙悟空"),(3,"猪八戒");

【4】修改 test_maxwell 库的 user表的一条数据,查看 maxwell 的控制台输出

{
"database": "test_maxwell",
"table": "user",
"type": "update",
"ts": 1653212058,
"xid": 3061,
"commit": true,
"data": {
"id": 2,
"name": "王五"
},
"old": {
"name": "李四"
}
}
【5】删除一条数据
{
"database": "test_maxwell",
"table": "user",
"type": "delete",
"ts": 1653212134,
"xid": 3234,
"commit": true,
"data": {
"id": 3,
"name": "猪八戒"
}
}
3.2.2、监控 Mysql 数据输出到 kafka
1、启动zookeeper集群和kafka集群

2、启动 Maxwell 监控 binlog
bin/maxwell --user='maxwell' --password='123456' --host='hadoop02' --producer=kafka --kafka.bootstrap.servers=hadoop02:9092 --kafka_topic=maxwell


注意这里我们不更新数据这里的topic是不会被创建的
我们使用过kafka的图形化工具kafka tool打开
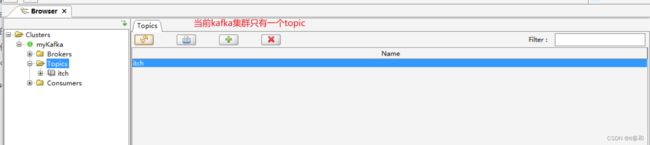
我们再来在mysql中更新数据

查看topics

一旦mysql表有了数据的更新,那么底层的binlog肯定会有变化,binlog变化那么我们·的maxwell进程就能捕捉到这个·变化,捕捉到就会将这条数据传到kafka里面。
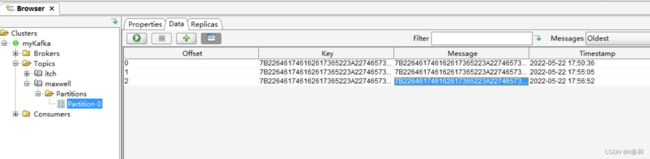
3、打开 kafka 的控制台的消费者消费 maxwell 主题
kafka-console-consumer.sh --bootstrap-server hadoop02:9092 --topic maxwell

通过 kafka 消费者来查看到了数据,说明数据成功传入 kafka
这里我们再来修改另外一个数据库,因为之前的设置我们使用binlog监控了两个数据库,一个是test_maxwell,一个是test_maxwell1,现在我们在test_maxwell1的表中插入一条数据
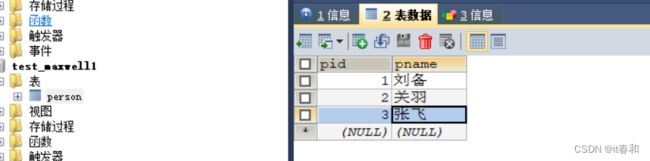
查看kafka的主题变化:

所以接下来引出定制化启动maxwell进程输出到kafka
3.2.3、Kafka主题的分区控制
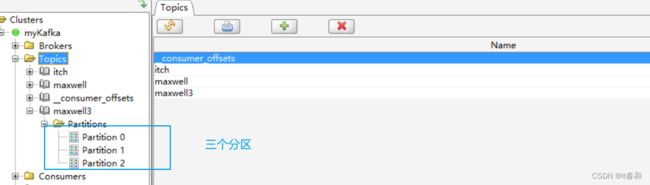
在实际生产环境中,我们一般都会用 maxwell 监控多个 mysql 库的数据,然后将这些数据发往 kafka 的一个主题 Topic,并且这个主题也肯定是多分区的,为了提高并发度。
那么如何控制这些数据的分区问题,就变得至关重要,实现步骤如下:
【1】手动创建三个分区的topic
![]()
【2】修改maxwell的配置文件,定制化启动maxwell进程
修改producer模式为kafka

指定发往的主题

设置分区参数

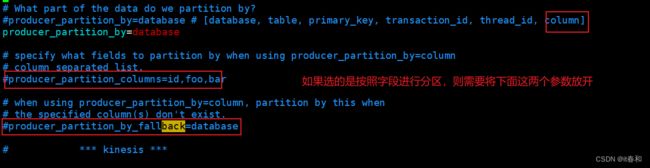
保存退出!
【3】使用配置文件的方式启动maxwell进程
bin/maxwell --config ./config.properties
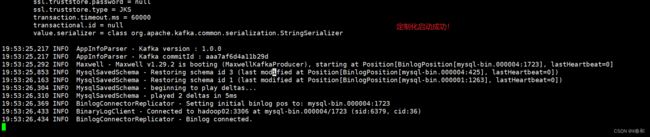
【4】向 test_maxwell 库的 test 表再次插入一条数据

【5】向 test_maxwell1 库的 test 表再次插入一条数据

再来看看topic

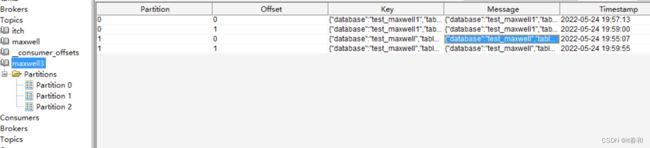
说明不同数据库的数据会发往不同的分区
3.2.4、监控mysql指定表数据输出到控制台
之前的操作我们都是监控数据库下面的所有表,那么怎么监控指定的表呢?
使用--filter参数来过滤
首先我们在test_maxwell数据库中创建一张新表 student

【1】运行 maxwell 来监控 mysql 指定表数据更新
bin/maxwell --user='maxwell' --password='123456' --host='hadoop02' --filter 'exclude: *.*, include:test_maxwell.student' --producer=stdout

这说明只会监控student表
更新user表数据:

更新student表数据:

还可以设置 include:test_maxwell.*,通过此种方式来监控 mysql 某个库的所有表,也就是说过滤整个库
3.2.5、监控mysql指定表全量数据输出到控制台
即数据初始化
Maxwell 进程默认只能监控 mysql 的 binlog 日志的新增及变化的数据,但是Maxwell 是支持数据初始化的,可以通过修改 Maxwell 的元数据,来对 MySQL 的某张表进行数据初始化,也就是我们常说的
全量同步。
需求:将 test_maxwell 库下的 test2 表的四条数据,全量导入到 maxwell 控制台进行打印。
【1】修改 Maxwell 的元数据,触发数据初始化机制,在 mysql 的 maxwell 库中 bootstrap表中插入一条数据,写明需要全量数据的库名和表名
insert into maxwell.bootstrap(database_name,table_name) values('test_maxwell','user');

【2】启动 maxwell 进程,此时初始化程序会直接打印 test2 表的所有数据
bin/maxwell --user='maxwell' --password='123456' --host='hadoop02' --producer=stdout
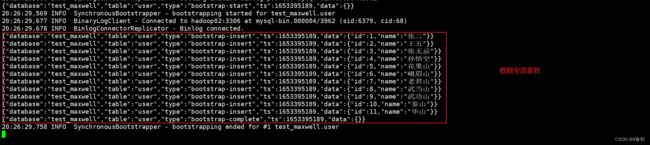
【3】当数据全部初始化完成以后,Maxwell 的元数据会变化
is_complete 字段从 0 变为 1
start_at 字段从 null 变为具体时间(数据同步开始时间)
complete_at 字段从 null 变为具体时间(数据同步结束时间)
